UltraQuant: 4-bit KV Caching for Context-Heavy Agents
Pith reviewed 2026-06-26 17:46 UTC · model grok-4.3
The pith
4-bit KV caching cuts time-to-first-token by 3.47x in late rounds of multi-turn agent workloads over an FP8 baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
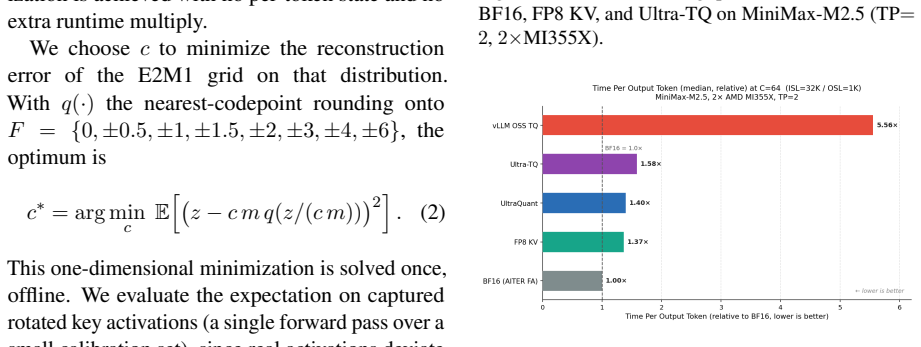
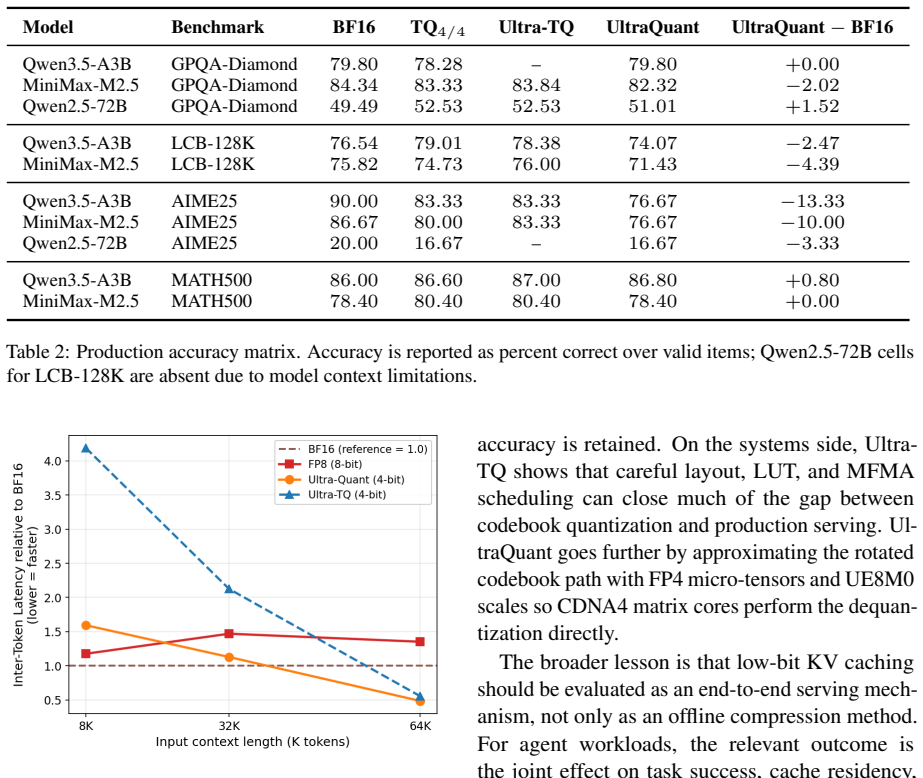
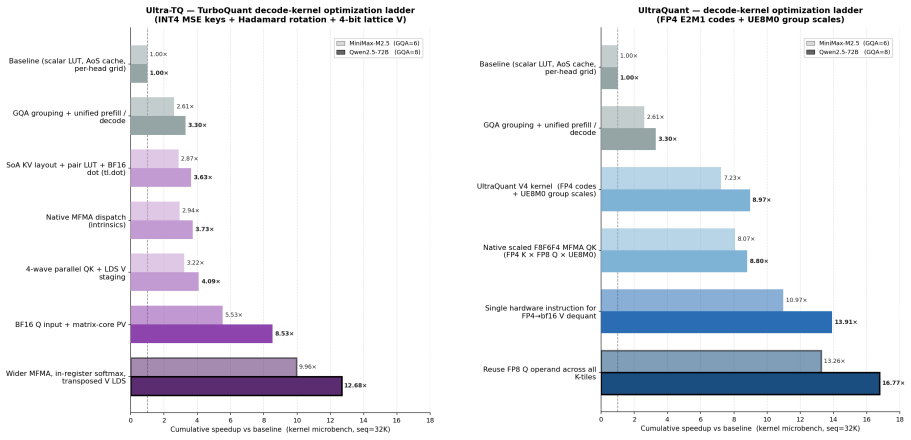
By combining TurboQuant-style rotation and codebook quantization with asymmetric K/V treatment, Walsh-Hadamard rotation, QJL removal, and block-scale variants, and by implementing optimized decode-attention kernels plus an FP4 path that uses FP8 queries, FP4 KV tensors, UE8M0 group scales, and native scaled-MFMA instructions on CDNA4 GPUs, the system delivers a 3.47x reduction in P50 time-to-first-token in cache-pressured late rounds (2.3x across all rounds) and a 1.63x increase in output throughput while task quality stays comparable to the FP8 KV baseline.
What carries the argument
UltraQuant, the FP4 approximation path that pairs FP8 queries with FP4 KV tensors, UE8M0 group scales, and native scaled matrix-multiply support.
If this is right
- Higher concurrency becomes possible because each agent occupies less KV cache memory.
- Longer context prefixes can be retained without increasing total memory footprint.
- Output generation rate rises, shortening overall response time in interactive agent sessions.
- Joint tracking of quality, cache residency, and throughput becomes necessary when evaluating any KV compression method.
Where Pith is reading between the lines
- The same design pattern could be tested on non-AMD hardware that offers low-precision matrix units to check whether the speedups generalize.
- Lower memory per token might reduce overall power draw in large agent fleets, an effect not measured here.
- If quality holds under the current rotation and scaling choices, further reductions below 4 bits could be explored on the same workload.
Load-bearing premise
Task quality on the tested multi-round agent workload stays comparable to the FP8 baseline once the listed 4-bit design choices are applied.
What would settle it
Measure task success rate or quality score on the same long-context multi-turn workload with UltraQuant 4-bit KV caching and check whether it falls below the FP8 baseline level.
Figures


read the original abstract
Context-heavy agents place unusual pressure on the key-value (KV) cache: long prefixes are reused across many short turns, while concurrency determines whether the serving system can keep GPUs utilized. We study 4-bit KV-cache compression for this setting, using TurboQuant-style rotation and codebook quantization as a quality anchor and vLLM FP8 KV caching as the deployment anchor. We report three contributions. First, we frame 4-bit KV caching around multi-round agent workloads where task quality, cache residency, and serving throughput must be measured jointly. Second, we describe the practical design choices needed to make the 4-bit path robust, including asymmetric K/V treatment, Walsh-Hadamard rotation, QJL removal, and block-scale variants. Third, we present serving optimizations on AMD GPUs, including optimized decode-attention kernels and UltraQuant, an FP4 approximation path that uses FP8 queries, FP4 KV tensors, UE8M0 group scales, and native scaled-MFMA support on CDNA4. On a long-context, multi-turn agentic workload, UltraQuant cuts P50 time-to-first-token by 3.47x in the cache-pressured late rounds (2.3x across all rounds) and raises output throughput by 1.63x over the FP8 KV baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UltraQuant, a 4-bit KV-cache compression technique for context-heavy, multi-turn agent workloads. It anchors quality on TurboQuant-style rotation and codebook quantization while using vLLM FP8 KV caching as the deployment baseline. The three stated contributions are: (1) framing 4-bit KV caching around joint measurement of task quality, cache residency, and throughput; (2) practical design choices including asymmetric K/V treatment, Walsh-Hadamard rotation, QJL removal, and block-scale variants; and (3) AMD-GPU serving optimizations (optimized decode-attention kernels, an FP4 approximation path using FP8 queries, FP4 KV tensors, UE8M0 group scales, and native scaled-MFMA on CDNA4). On a long-context multi-turn agentic workload the method is reported to deliver 3.47× P50 TTFT reduction in cache-pressured late rounds (2.3× overall) and 1.63× output throughput versus the FP8 baseline.
Significance. If the omitted quality results confirm that task performance remains comparable to the FP8 baseline, the work would be significant for memory-constrained serving of long-context agents. The explicit joint-evaluation framing and the concrete AMD-GPU kernel optimizations (especially the FP4 path leveraging native hardware support) address a practically important regime that is currently underserved by existing 8-bit KV methods.
major comments (2)
- [Abstract] Abstract: The manuscript states that “task quality, cache residency, and serving throughput must be measured jointly,” yet reports only the latter two quantities. No quality metric, numerical quality results, dataset description, agentic task definitions, or success criteria are supplied, so the central claim that the 4-bit path (asymmetric K/V, Walsh-Hadamard rotation, QJL removal, block scales, TurboQuant-style codebook) preserves quality cannot be evaluated.
- [Abstract] Abstract, third contribution: The headline speedups (3.47× P50 TTFT late rounds, 2.3× overall, 1.63× throughput) are presented without experimental details, error bars, workload characterization, or ablation results on the listed design choices. This absence makes it impossible to determine whether the reported gains are robust or workload-specific.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We address each major comment below and will revise the manuscript accordingly to improve the presentation of our joint-evaluation framing and results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript states that “task quality, cache residency, and serving throughput must be measured jointly,” yet reports only the latter two quantities. No quality metric, numerical quality results, dataset description, agentic task definitions, or success criteria are supplied, so the central claim that the 4-bit path (asymmetric K/V, Walsh-Hadamard rotation, QJL removal, block scales, TurboQuant-style codebook) preserves quality cannot be evaluated.
Authors: We agree the abstract does not include explicit quality metrics or task details due to length constraints. The full manuscript defines the agentic tasks, reports quality metrics (task success rates) showing the 4-bit path preserves performance comparable to FP8, and uses TurboQuant-style quantization as the quality anchor. We will revise the abstract to add a brief statement noting quality preservation on the evaluated workloads. revision: yes
-
Referee: [Abstract] Abstract, third contribution: The headline speedups (3.47× P50 TTFT late rounds, 2.3× overall, 1.63× throughput) are presented without experimental details, error bars, workload characterization, or ablation results on the listed design choices. This absence makes it impossible to determine whether the reported gains are robust or workload-specific.
Authors: Abstracts present headline results at a high level; the manuscript body provides the long-context multi-turn agentic workload characterization, error bars, and ablations on choices such as asymmetric K/V treatment, Walsh-Hadamard rotation, and block scales. We will partially revise the abstract to include a short workload description for additional context. revision: partial
Circularity Check
No circularity; empirical measurements against external baseline
full rationale
The paper reports performance numbers (TTFT and throughput gains) as direct empirical measurements on a multi-round agentic workload against an external FP8 KV baseline from vLLM. Design choices (asymmetric K/V, Walsh-Hadamard rotation, block scales) are described as practical engineering decisions anchored to TurboQuant-style methods, with no equations, derivations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claims to inputs by construction. The abstract and contributions contain no mathematical steps that could exhibit self-definitional or fitted-input circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advanced Micro Devices, Inc. 2024. https://www.amd.com/content/dam/amd/en/documents/instinct-tech-docs/instruction-set-architectures/amd-instinct-cdna4-instruction-set-architecture.pdf AMD Instinct CDNA4 Instruction Set Architecture
2024
-
[2]
AMD ROCm . 2025. https://rocm.blogs.amd.com/software-tools-optimization/aiter-ai-tensor-engine/README.html AITER : AI tensor engine for ROCm . AMD ROCm Blogs
2025
-
[3]
Inesh Chakrabarti, David Limpus, Aditi Ghai Rana, Bowen Bao, Spandan Tiwari, Thiago Crepaldi, and Ashish Sirasao. 2026. https://rocm.blogs.amd.com/artificial-intelligence/turboquant-vllm-agentic/README.html Productionizing TurboQuant on AMD GPU s for KV -cache-bound LLM inference . AMD ROCm Blogs
2026
-
[4]
Paolo D'Alberto. 2026. https://arxiv.org/abs/2605.08114 Statistical inference and quality measures of KV cache quantisations inspired by TurboQuant . Preprint, arXiv:2605.08114
Pith/arXiv arXiv 2026
-
[5]
Tri Dao and Albert Gu. 2024. https://arxiv.org/abs/2405.21060 Transformers are SSM s: Generalized models and efficient algorithms through structured state space duality . Preprint, arXiv:2405.21060
Pith/arXiv arXiv 2024
-
[6]
DeepSeek-AI . 2024 a . https://arxiv.org/abs/2405.04434 DeepSeek-V2 : A strong, economical, and efficient mixture-of-experts language model . Preprint, arXiv:2405.04434
Pith/arXiv arXiv 2024
-
[7]
DeepSeek-AI . 2024 b . https://arxiv.org/abs/2412.19437 DeepSeek-V3 technical report . Preprint, arXiv:2412.19437
Pith/arXiv arXiv 2024
-
[8]
Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. 2024. https://arxiv.org/abs/2402.13753 LongRoPE : Extending LLM context window beyond 2 million tokens . Preprint, arXiv:2402.13753
Pith/arXiv arXiv 2024
-
[9]
Gemini Team . 2024. https://arxiv.org/abs/2403.05530 Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context . Preprint, arXiv:2403.05530
Pith/arXiv arXiv 2024
-
[10]
Albert Gu and Tri Dao. 2023. https://arxiv.org/abs/2312.00752 Mamba: Linear-time sequence modeling with selective state spaces . Preprint, arXiv:2312.00752
Pith/arXiv arXiv 2023
-
[11]
Han Guo, William Brandon, Radostin Cholakov, Jonathan Ragan-Kelley, Eric P.\ Xing, and Yoon Kim. 2024. https://aclanthology.org/2024.findings-emnlp.724/ Fast matrix multiplications for lookup table-quantized LLM s . In Findings of the Association for Computational Linguistics: EMNLP 2024 , pages 12419--12433
2024
-
[12]
Jacques Hadamard. 1893. R\' e solution d'une question relative aux d\' e terminants. Bulletin des Sciences Math\' e matiques , 17:240--246
-
[13]
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W.\ Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. 2024. KVQuant : Towards 10 million context length LLM inference with KV cache quantization. In Advances in Neural Information Processing Systems ( NeurIPS )
2024
-
[14]
Eldar Kurti\' c , Michael Goin, and Alexandre Marques. 2026. https://vllm.ai/blog/2026-05-11-turboquant A first comprehensive study of TurboQuant : Accuracy and performance . vLLM Blog. Red Hat AI
2026
-
[15]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E.\ Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with PagedAttention . In Proceedings of the 29th Symposium on Operating Systems Principles ( SOSP )
2023
-
[16]
Fan Li, Siyuan Feng, Chen Huang, Dake Wang, Hongbin Yang, Peng Sun, and Emad Barsoum. 2026. https://rocm.blogs.amd.com/software-tools-optimization/flydsl-python-native/README.html FlyDSL : Expert GPU kernel development with the ease of MLIR P ython native DSL on AMD GPU s . AMD ROCm Blogs
2026
-
[17]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. KIVI : A tuning-free asymmetric 2bit quantization for KV cache. In International Conference on Machine Learning ( ICML )
2024
-
[18]
Stuart P. Lloyd. 1982. https://doi.org/10.1109/TIT.1982.1056489 Least squares quantization in PCM . IEEE Transactions on Information Theory, 28(2):129--137
-
[19]
Joel Max. 1960. https://doi.org/10.1109/TIT.1960.1057548 Quantizing for minimum distortion . IRE Transactions on Information Theory, 6(1):7--12
-
[20]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess\` i , Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. https://arxiv.org/abs/2302.04761 Toolformer: Language models can teach themselves to use tools . Preprint, arXiv:2302.04761
Pith/arXiv arXiv 2023
-
[21]
TheTom . 2026. https://github.com/TheTom/turboquant_plus TurboQuant+ : community llama.cpp port and exploration of TurboQuant . GitHub repository
2026
-
[22]
Joseph L. Walsh. 1923. https://doi.org/10.2307/2387224 A closed set of normal orthogonal functions . American Journal of Mathematics, 45(1):5--24
-
[23]
John Yang, Carlos E.\ Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024 a . https://arxiv.org/abs/2405.15793 SWE -agent: Agent-computer interfaces enable automated software engineering . Preprint, arXiv:2405.15793
Pith/arXiv arXiv 2024
-
[24]
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. 2024 b . https://arxiv.org/abs/2412.06464 Gated delta networks: Improving Mamba2 with delta rule . Preprint, arXiv:2412.06464
Pith/arXiv arXiv 2024
-
[25]
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. 2024 c . https://arxiv.org/abs/2406.06484 Parallelizing linear transformers with the delta rule over sequence length . Preprint, arXiv:2406.06484
arXiv 2024
-
[26]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. https://arxiv.org/abs/2210.03629 ReAct : Synergizing reasoning and acting in language models . Preprint, arXiv:2210.03629
Pith/arXiv arXiv 2022
-
[27]
Amir Zandieh, Majid Daliri, Mojtaba Hadian, and Vahab Mirrokni. 2026. https://openreview.net/forum?id=tO3ASKZlok TurboQuant : Online vector quantization with near-optimal distortion rate . In International Conference on Learning Representations ( ICLR )
2026
-
[28]
Amir Zandieh, Majid Daliri, and Insu Han. 2024. https://arxiv.org/abs/2406.03482 QJL : 1-bit quantized JL transform for KV cache quantization with zero overhead . Preprint, arXiv:2406.03482
arXiv 2024
-
[29]
Yichi Zhang, Bofei Gao, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, Wen Xiao, and 1 others. 2024. PyramidKV : Dynamic KV cache compression based on pyramidal information funneling. arXiv preprint arXiv:2406.02069
Pith/arXiv arXiv 2024
-
[30]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E.\ Gonzalez, Clark Barrett, and Ying Sheng. 2023. https://arxiv.org/abs/2312.07104 SGLang : Efficient execution of structured language model programs . Preprint, arXiv:2312.07104
Pith/arXiv arXiv 2023
-
[31]
Shuyan Zhou, Frank F.\ Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2023. https://arxiv.org/abs/2307.13854 WebArena : A realistic web environment for building autonomous agents . Preprint, arXiv:2307.13854
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.