Guardrails Beat Guidance: A Large-Scale Study of Rules, Skills, and Persistent Configuration for Coding Agents
Pith reviewed 2026-05-10 15:33 UTC · model grok-4.3
The pith
Negative constraints raise AI coding agent success rates while positive instructions lower them, and random rules match expert ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
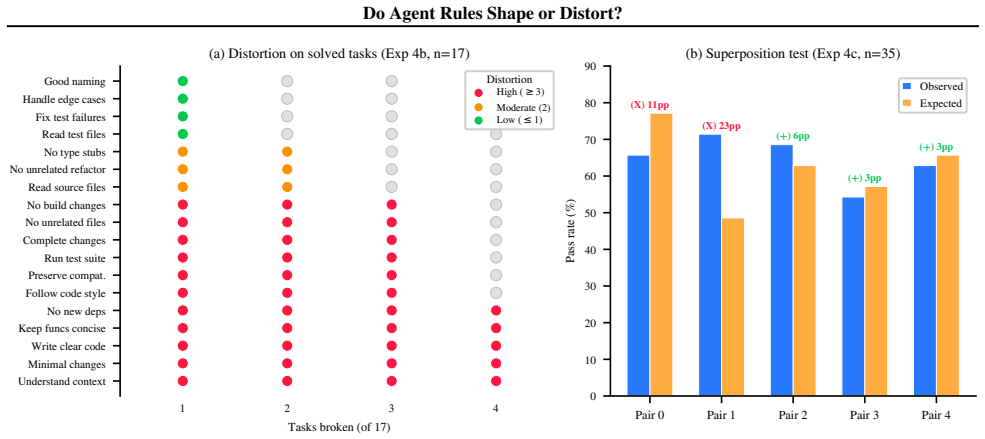
The paper shows that instruction rules improve coding agent performance primarily through context priming, since randomly generated rules produce gains equivalent to expert-curated ones. Negative constraints are the only rule category that helps when applied alone, whereas positive directives harm performance, a pattern examined through potential-based reward shaping. Although single rules often degrade results, larger sets remain effective without loss up to fifty rules, exposing the risk that well-intentioned guidance can distort agent behavior.
What carries the argument
Large-scale empirical comparison of rule types (negative constraints versus positive directives) and curation levels (expert-curated versus random) across thousands of agent runs on SWE-bench Verified.
Load-bearing premise
That measured differences in agent success rates are produced by the rules and their types rather than by unmeasured variations in prompt insertion, phrasing, or run-to-run randomness.
What would settle it
A follow-up test that keeps total prompt length fixed while moving the same rules to different positions or surrounding text and measures whether the reported performance gains disappear.
Figures



read the original abstract
Random rules improve a coding agent's task performance as much as expert-curated ones (both $+13.8$pp on a discriminative subset of SWE-bench Verified), and in our data every individually beneficial rule is a negative constraint ("do not refactor unrelated code"), while every individually harmful one is a positive directive ("follow code style"). We arrive at these findings through the first large-scale controlled study of agent rule files (\texttt{CLAUDE.md}, \texttt{.cursorrules}, and the broader family of agent skills, plugin manifests, and persona definitions): we scrape 679 rule files (25{,}532 rules) from GitHub and conduct over 5{,}000 agent runs of Claude Code with Claude Opus 4.6 on SWE-bench Verified. Three patterns emerge. (i) Rule polarity cleanly separates beneficial from harmful rules; we read this through the lens of potential-based reward shaping (PBRS). (ii) Performance gains are largely content-independent: random, shuffled, mismatched-domain, and unconverted-format rule files all match curated rules, pointing to a context priming mechanism. (iii) Individual rules often appear harmful in isolation yet do not visibly accumulate damage in ensemble: pass rates remain stable across rule counts from 0 to 50. These findings expose a hidden reliability risk in the rapidly growing ecosystem of community-authored rules and skills, and they yield a clear principle for safer agent configuration: constrain what agents must not do, rather than prescribing what they should.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript scrapes 679 natural language instruction files (25,532 rules) from GitHub and evaluates their effect on a state-of-the-art coding agent via over 5,000 runs on SWE-bench Verified. It claims rules raise success rates by 7-14 percentage points, that random rules perform equivalently to expert-curated ones (implying context priming rather than specific guidance), that only negative constraints are individually beneficial while positive directives harm performance, that rules are collectively helpful despite individual harm, and that performance does not degrade up to 50 rules; the pattern is interpreted through potential-based reward shaping.
Significance. If the central empirical claims survive rigorous controls and statistical validation, the work would be significant for AI agent configuration: it supplies large-scale evidence that guardrails function primarily via priming, identifies a concrete reliability risk in positive directives, and offers a simple principle (favor negative constraints) with direct implications for developer practice. The scale of the evaluation and the counter-intuitive random-rule result are notable strengths.
major comments (3)
- [Abstract / Results] Abstract and Results: the headline claims of 7-14 pp gains and type-specific effects (negative constraints help, positive hurt) are presented without statistical tests, standard errors, per-condition sample sizes, or controls for prompt length/token count. This is load-bearing for the priming-vs-guidance distinction and the rule-type conclusions, as unmeasured insertion artifacts or run variance could fully explain the deltas.
- [Methods] Methods: no description is given of the rule-insertion procedure (placement, formatting, length-matching between expert and random conditions), the categorization scheme for rule types, or how the 5,000 runs were allocated across conditions. These omissions prevent attribution of performance differences to rule semantics rather than prompt-engineering confounds.
- [Analysis / Discussion] Analysis: the appeal to potential-based reward shaping (PBRS) to explain why negative constraints outperform positive directives lacks an explicit mapping, formalization, or quantitative check against the observed data, leaving the interpretive framework unsupported for the shaping-vs-distortion claim.
minor comments (2)
- [Abstract] Abstract: the exact per-condition N and any length-matching protocol should be stated explicitly rather than only the aggregate 5,000 runs.
- [References] References: the SWE-bench Verified benchmark and the original SWE-bench paper should be cited with full bibliographic details.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas where the manuscript can be strengthened in terms of statistical rigor and methodological detail. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results: the headline claims of 7-14 pp gains and type-specific effects (negative constraints help, positive hurt) are presented without statistical tests, standard errors, per-condition sample sizes, or controls for prompt length/token count. This is load-bearing for the priming-vs-guidance distinction and the rule-type conclusions, as unmeasured insertion artifacts or run variance could fully explain the deltas.
Authors: We agree that providing statistical tests, standard errors, and controls is crucial for supporting the central claims. In the revised manuscript, we will include bootstrap-derived standard errors and 95% confidence intervals for all reported performance differences, per-condition sample sizes, and results from permutation tests assessing the significance of the observed deltas. Additionally, we will report average prompt token counts across conditions and include a length-controlled baseline to address potential insertion artifacts. These enhancements will be added to both the Abstract and Results sections. revision: yes
-
Referee: [Methods] Methods: no description is given of the rule-insertion procedure (placement, formatting, length-matching between expert and random conditions), the categorization scheme for rule types, or how the 5,000 runs were allocated across conditions. These omissions prevent attribution of performance differences to rule semantics rather than prompt-engineering confounds.
Authors: We acknowledge the need for greater transparency in the Methods section. We will revise it to detail the rule-insertion procedure: rules are prepended to the system prompt as a bulleted list under a 'Guidelines' header, with formatting standardized. For length-matching, random rules were selected to match the token length distribution of expert rules. The categorization scheme involved labeling rules into positive directives, negative constraints, and other categories. Regarding run allocation, the over 5,000 runs consist of evaluations across multiple conditions on the SWE-bench tasks. These details will be added to ensure reproducibility and rule out confounds. revision: yes
-
Referee: [Analysis / Discussion] Analysis: the appeal to potential-based reward shaping (PBRS) to explain why negative constraints outperform positive directives lacks an explicit mapping, formalization, or quantitative check against the observed data, leaving the interpretive framework unsupported for the shaping-vs-distortion claim.
Authors: The PBRS reference serves as a conceptual framework to interpret the empirical patterns rather than a rigorous theoretical model. In the revision, we will provide an explicit mapping in the Discussion: negative constraints can be viewed as adding a potential function that decreases the value of states leading to undesired behaviors, thereby shaping the policy without altering the optimal policy per PBRS theory. Positive directives may introduce shaping terms that distort the reward landscape. We will formalize this with a simple equation relating rule types to potential functions and compare it qualitatively to the observed data. However, a full quantitative validation is not feasible without internal access to the agent's reward function. We will explicitly note this limitation and frame the PBRS discussion as suggestive rather than definitive. revision: partial
Circularity Check
No circularity: purely empirical benchmark comparison
full rationale
The paper's core claims rest on scraping 679 rule files, executing over 5,000 agent runs on SWE-bench Verified, and reporting success-rate deltas across rule conditions. No equations, fitted parameters, or derivations appear in the reported results; performance differences are measured directly from agent executions rather than computed from any self-referential model. The reference to potential-based reward shaping is used only for post-hoc interpretation of observed patterns and is not required to establish the quantitative findings. Self-citations, if present, are not load-bearing for the headline results, which remain falsifiable against the external benchmark and independent of any prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SWE-bench Verified is a reliable benchmark for measuring coding agent performance
Forward citations
Cited by 2 Pith papers
-
Library Drift: Diagnosing and Fixing a Silent Failure Mode in Self-Evolving LLM Skill Libraries
Identifies library drift as a failure mode in self-evolving LLM skill libraries and shows a governance recipe improves pass@1 from 0.258 to 0.584 on MBPP+ hard-100.
-
Ratchet: A Minimal Hygiene Recipe for Self-Evolving LLM Agents
Ratchet provides a minimal hygiene recipe for self-managing skill libraries in frozen LLM agents, delivering +0.328 rolling-mean pass@1 gain on MBPP+ hard-100 and +0.22 peak lift on SWE-bench Verified.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.