FlashTTS: Fast Streaming TTS with MTP Acceleration and X-pred Mean Flow Distillation
Pith reviewed 2026-06-27 15:13 UTC · model grok-4.3
The pith
FlashTTS reaches 325 ms first-packet latency in streaming TTS through a lagged multi-track design paired with multi-token prediction and two-step flow matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlashTTS introduces a lagged multi-track architecture that natively processes streaming text and speech inputs without sentence-level buffering, integrates parallel Multi-Token Prediction with an X-pred mean flow matching decoder to achieve high-fidelity token-to-mel generation in two function evaluations, and thereby reduces first-packet latency to 325 ms while preserving zero-shot voice cloning and cross-lingual performance.
What carries the argument
The lagged multi-track architecture that processes streaming inputs, accelerated by parallel Multi-Token Prediction (MTP) and an X-pred mean flow matching decoder that completes acoustic generation in two function evaluations.
If this is right
- Real-time speech dialogue systems can operate with sub-second response times without sentence buffering.
- Streaming TTS becomes compatible with zero-shot voice cloning and cross-lingual generation in a single model.
- End-to-end latency drops by removing multi-stage pipelines and multi-step flow matching.
- Open-source release of model code and checkpoints allows direct integration into dialogue applications.
Where Pith is reading between the lines
- The two-evaluation flow matching step may extend to other token-to-continuous generation tasks that currently require many denoising steps.
- Joint optimization of input buffering and decoder speed could reduce memory footprint on resource-constrained devices.
- The same lagged multi-track pattern might apply to streaming generation in other modalities such as music or video.
- If the 2-NFE decoder generalizes, it offers a route to lower compute budgets for on-device TTS.
Load-bearing premise
The lagged multi-track architecture together with multi-token prediction and the X-pred mean flow matching decoder can be jointly trained to generate high-fidelity mel-spectrograms without quality loss detectable in listening tests or downstream ASR metrics.
What would settle it
A side-by-side listening test or ASR word-error-rate comparison on the same zero-shot voices that shows clear degradation in naturalness or intelligibility relative to non-streaming baselines.
Figures

read the original abstract
Recent progress in speech dialogue systems requires Text-to-Speech (TTS) models to be faster and more responsive. Modern speech dialogue systems impose two primary requirements on TTS models: low latency and support for streaming inputs and outputs. However, most existing single-codebook LLM-based TTS methods rely on multi-stage pipelines that lack native streaming capabilities. These systems typically suffer from high end-to-end latency due to slow autoregressive prediction and multi-step flow matching. To address these limitations, we propose FlashTTS, an open-source and low-latency streaming TTS framework. FlashTTS introduces a lagged multi-track architecture that natively processes streaming text and speech inputs, thereby eliminating the need for sentence-level buffering. To accelerate acoustic generation, we integrate parallel Multi-Token Prediction (MTP) with an X-pred mean flow matching decoder. This configuration achieves high-fidelity token-to-mel generation in exactly two function evaluations (2-NFE). By jointly optimizing input processing and decoding efficiency, FlashTTS offers a practical foundation for real-time speech dialogue systems. Experiments show that FlashTTS substantially reduces First-Packet Latency to 325ms compared to robust streaming baselines, all while preserving strong zero-shot voice cloning and cross-lingual intelligibility. Speech samples are available. The model code and checkpoints will be released as open source.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlashTTS, an open-source streaming TTS framework using a lagged multi-track architecture for native processing of streaming text and speech inputs, combined with parallel Multi-Token Prediction (MTP) and an X-pred mean flow matching decoder restricted to exactly 2 function evaluations (2-NFE). It claims this yields high-fidelity mel-spectrogram generation, reducing First-Packet Latency to 325 ms versus robust streaming baselines while preserving zero-shot voice cloning and cross-lingual intelligibility, with code and checkpoints to be released.
Significance. If the latency and quality claims are substantiated with rigorous experiments, the work could offer a practical contribution to real-time speech dialogue systems by enabling lower end-to-end latency without multi-stage pipelines. The explicit commitment to open-sourcing the model code and checkpoints is a strength that supports reproducibility.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim of a 325 ms First-Packet Latency reduction is presented without any quantitative tables, error bars, dataset specifications, baseline configurations, or ablation results on the 2-NFE regime, making it impossible to verify whether the comparison to streaming baselines is robust or affected by post-hoc selection.
- [§3] §3 (Method): The assertion that the lagged multi-track architecture, MTP, and X-pred mean flow matching decoder can be jointly trained to produce high-fidelity mels without quality degradation (required for the downstream zero-shot cloning and intelligibility claims) lacks any training procedure details, loss curves, MOS scores, WER metrics, or ablation on the distillation process.
minor comments (2)
- The abstract states that 'Speech samples are available' and code will be released, but no URLs or repository links are provided in the text.
- [§3] Notation for 'X-pred mean flow distillation' is introduced without a clear definition or equation relating it to standard flow matching.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We appreciate the emphasis on rigorous experimental validation and will revise the manuscript to strengthen the presentation of results and methods.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim of a 325 ms First-Packet Latency reduction is presented without any quantitative tables, error bars, dataset specifications, baseline configurations, or ablation results on the 2-NFE regime, making it impossible to verify whether the comparison to streaming baselines is robust or affected by post-hoc selection.
Authors: We agree that the current version of the abstract and §4 would benefit from expanded quantitative support. In the revised manuscript we will add tables reporting First-Packet Latency with error bars obtained from multiple runs, explicit dataset specifications, baseline configurations (including their streaming parameters), and dedicated ablations isolating the 2-NFE regime. These additions will make the 325 ms comparison fully transparent and reproducible. revision: yes
-
Referee: [§3] §3 (Method): The assertion that the lagged multi-track architecture, MTP, and X-pred mean flow matching decoder can be jointly trained to produce high-fidelity mels without quality degradation (required for the downstream zero-shot cloning and intelligibility claims) lacks any training procedure details, loss curves, MOS scores, WER metrics, or ablation on the distillation process.
Authors: We acknowledge that §3 currently omits sufficient training and evaluation details. The revised version will expand this section with the full joint-training procedure, loss curves, MOS and WER results, and ablations on the X-pred mean-flow distillation process to demonstrate that high-fidelity mel generation is preserved for the downstream zero-shot and cross-lingual claims. revision: yes
Circularity Check
No circularity; performance claims are measured outcomes, not reductions to fitted inputs
full rationale
The paper presents an architectural proposal (lagged multi-track + parallel MTP + X-pred mean-flow decoder at 2 NFE) whose headline metrics (325 ms FPL, preserved zero-shot cloning and intelligibility) are reported as experimental results rather than quantities derived by construction from the same fitted parameters or self-citations. No equations, loss definitions, or parameter-fitting steps are shown that would make the latency or quality numbers tautological with the model definition itself. The central claims therefore remain externally falsifiable via listening tests or ASR WER and do not reduce to the inputs by the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of lagged tracks
- MTP prediction horizon
axioms (1)
- domain assumption Flow matching can be distilled to exactly two function evaluations while retaining mel-spectrogram fidelity sufficient for downstream vocoding.
invented entities (1)
-
X-pred mean flow distillation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introduction Building on the generative capacity of large language models (LLMs), modern text-to-speech (TTS) systems have reached a stage where synthesized speech is nearly indistinguishable from human speech. By imitating the timbre, prosody, and speaking style of reference audio, these systems achieve high naturalness and strong zero-shot voice cloning...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Model Architecture In this section, we present FlashTTS, a low-latency TTS model explicitly designed for streaming input scenarios
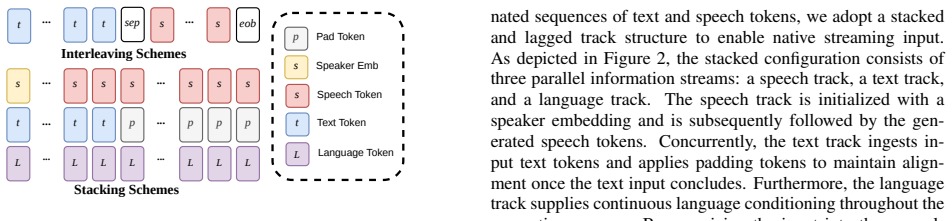
FlashTTS 2.1. Model Architecture In this section, we present FlashTTS, a low-latency TTS model explicitly designed for streaming input scenarios. As illus- trated in Figure 1, the model architecture and training pipeline are structured into two primary stages. Stage 1 (Figure 1a) establishes the core generation pathway, wherein a trainable decoder-only tr...
-
[3]
Datasets FlashTTS is trained on approximately 300,000 hours of open- source speech data, comprising Emilia, Emilia-Yodas [29, 30, 31], LibriHeavy, and WenetSpeech4TTS
Experimental Setup 3.1. Datasets FlashTTS is trained on approximately 300,000 hours of open- source speech data, comprising Emilia, Emilia-Yodas [29, 30, 31], LibriHeavy, and WenetSpeech4TTS. We evaluate zero-shot performance on the Seed-TTS3 and MiniMax4 multilingual test sets. 3https://github.com/BytedanceSpeech/seed-tts-eval 4https://huggingface.co/dat...
-
[4]
Experimental Results 4.1. Latency and Quality Analysis All latency evaluations are conducted on the Minimax sub- set using a single NVIDIA RTX 4090 GPU, with the tex- 5https://github.com/modelscope/FunASR Table 2:Objective evaluation metrics on the multilingual test set. Lower WER and higher SIM indicate better performance. “–” denotes unsupported languag...
-
[5]
Its multi-track formulation natively processes streaming inputs, completely circumventing traditional sentence-level buffering
Conclusion We propose FlashTTS, a low-latency LLM-based streaming TTS framework addressing the high latency bottleneck in real- time dialogue systems via a lagged multi-track architecture, par- allel MTP, and an X-pred Mean Flow decoder. Its multi-track formulation natively processes streaming inputs, completely circumventing traditional sentence-level bu...
-
[6]
They are not used to generate any core content, research ideas, experimental designs, results, or major textual parts of the paper
Generative AI Use Disclosure Generative AI tools are used in this work only for language edit- ing, polishing, and formatting of the manuscript. They are not used to generate any core content, research ideas, experimental designs, results, or major textual parts of the paper. All scien- tific contributions, including model design, experiments, analy- sis,...
-
[7]
Neural discrete represen- tation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete represen- tation learning,”Advances in neural information processing sys- tems, vol. 30, 2017
2017
-
[8]
Finite Scalar Quantization: VQ-VAE Made Simple
F. Mentzer, D. Minnen, E. Agustsson, and M. Tschannen, “Fi- nite scalar quantization: Vq-vae made simple,”arXiv preprint arXiv:2309.15505, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “Neural codec language mod- els are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”Trans. Mach. Learn. Res., vol. 2023, 2023
2023
-
[11]
V oicecraft: Zero-shot speech editing and text-to-speech in the wild,
P. Peng, P.-Y . Huang, S.-W. Li, A. Mohamed, and D. Harwath, “V oicecraft: Zero-shot speech editing and text-to-speech in the wild,” inProceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (V olume 1: Long Papers), 2024, pp. 12 442–12 462
2024
-
[12]
H.-H. Guo, Y . Hu, K. Liu, F.-Y . Shen, X. Tang, Y .-C. Wu, F.- L. Xie, K. Xie, and K.-T. Xu, “Fireredtts: A foundation text-to- speech framework for industry-level generative speech applica- tions,”arXiv preprint arXiv:2409.03283, 2024
-
[13]
Fish-speech: Leveraging large language models for advanced multilingual text-to-speech synthesis,
S. Liao, Y . Wang, T. Li, Y . Cheng, R. Zhang, R. Zhou, and Y . Xing, “Fish-speech: Leveraging large language models for advanced multilingual text-to-speech synthesis,”arXiv preprint arXiv:2411.01156, 2024
-
[14]
Fireredtts-2: Towards long conversational speech generation for podcast and chatbot,
K. Xie, F. Shen, J. Li, F. Xie, X. Tang, and Y . Hu, “Fireredtts-2: Towards long conversational speech generation for podcast and chatbot,”arXiv preprint arXiv:2509.02020, 2025
-
[15]
H. Hu, X. Zhu, T. He, D. Guo, B. Zhang, X. Wang, Z. Guo, Z. Jiang, H. Hao, Z. Guoet al., “Qwen3-tts technical report,” arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
C. Liu, H. Yan, S. Xue, X. Liang, X. Chen, B. Gong, Z. Xue, and G. Song, “Quarkaudio technical report,”arXiv preprint arXiv:2512.20151, 2025
-
[17]
Better speech synthesis through scaling,
J. Betker, “Better speech synthesis through scaling,”arXiv preprint arXiv:2305.07243, 2023
-
[18]
Sac: Neural speech codec with semantic-acoustic dual-stream quantization,
W. Chen, X. Wang, R. Yan, Y . Chen, Z. Niu, Z. Ma, X. Li, Y . Liang, H. Wen, S. Yinet al., “Sac: Neural speech codec with semantic-acoustic dual-stream quantization,”arXiv preprint arXiv:2510.16841, 2025
-
[19]
Llasa: Scaling train-time and inference-time compute for llama-based speech synthesis,
Z. Ye, X. Zhu, C.-M. Chan, X. Wang, X. Tan, J. Lei, Y . Peng, H. Liu, Y . Jin, Z. Daiet al., “Llasa: Scaling train-time and inference-time compute for llama-based speech synthesis,”arXiv preprint arXiv:2502.04128, 2025
-
[20]
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
X. Wang, M. Jiang, Z. Ma, Z. Zhang, S. Liu, L. Li, Z. Liang, Q. Zheng, R. Wang, X. Fenget al., “Spark-tts: An efficient llm- based text-to-speech model with single-stream decoupled speech tokens,”arXiv preprint arXiv:2503.01710, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Xtts: a massively multilingual zero-shot text-to-speech model,
E. Casanova, K. Davis, E. G ¨olge, G. G ¨oknar, I. Gulea, L. Hart, A. Aljafari, J. Meyer, R. Morais, S. Olayemiet al., “Xtts: a massively multilingual zero-shot text-to-speech model,”arXiv preprint arXiv:2406.04904, 2024
-
[22]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
P. Anastassiou, J. Chen, J. Chen, Y . Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gaoet al., “Seed-tts: A family of high-quality versatile speech generation models,”arXiv preprint arXiv:2406.02430, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Z. Du, Q. Chen, S. Zhang, K. Hu, H. Lu, Y . Yang, H. Hu, S. Zheng, Y . Gu, Z. Ma, Z. Gao, and Z. Yan, “Cosyvoice: A scal- able multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens,”CoRR, vol. abs/2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wang, F. Yu, H. Liu, Z. Sheng, Y . Gu, C. Deng, W. Wang, S. Zhang, Z. Yan, and J. Zhou, “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”CoRR, vol. abs/2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
J. Cui, Z. Yang, N. Li, J. Tian, X. Ma, Y . Zhang, G. Chen, R. Yang, Y . Cheng, Y . Zhou, G. Yu, X. Gu, and J. Tang, “Glm-tts technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2512.14291
-
[26]
X-talk: On the underestimated potential of modular speech-to-speech dialogue system,
Z. Liu, Y . Duan, M. Wang, P. Feng, H. Zhang, X. Xing, Y . Shan, H. Zhu, Y . Dai, C. Luet al., “X-talk: On the underestimated potential of modular speech-to-speech dialogue system,”arXiv preprint arXiv:2512.18706, 2025
-
[27]
Soulx-podcast: Towards realis- tic long-form podcasts with dialectal and paralinguistic diversity,
H. Xie, H. Lin, W. Cao, D. Guo, W. Tian, J. Wu, H. Wen, R. Shang, H. Liu, Z. Jianget al., “Soulx-podcast: Towards realis- tic long-form podcasts with dialectal and paralinguistic diversity,” arXiv preprint arXiv:2510.23541, 2025
-
[28]
Mean Flows for One-step Generative Modeling
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He, “Mean flows for one-step generative modeling,”arXiv preprint arXiv:2505.13447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Back to Basics: Let Denoising Generative Models Denoise
T. Li and K. He, “Back to basics: Let denoising generative models denoise,”arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical re- port,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Llasa+: Free lunch for accelerated and streaming llama-based speech syn- thesis,
W. Tian, X. Zhu, H. Xie, Z. Ye, W. Xue, and L. Xie, “Llasa+: Free lunch for accelerated and streaming llama-based speech syn- thesis,”arXiv preprint arXiv:2508.06262, 2025
-
[32]
Meanvc: Lightweight and streaming zero-shot voice conversion via mean flows,
G. Ma, J. Yao, Z. Ning, Y . Jiang, L. Xiong, L. Xie, and P. Zhu, “Meanvc: Lightweight and streaming zero-shot voice conversion via mean flows,”arXiv preprint arXiv:2510.08392, 2025
-
[33]
Int- meanflow: Few-step speech generation with integral velocity dis- tillation,
W. Wang, R. Cao, Y . Guo, Z. Chen, K. Chen, and Y . Huo, “Int- meanflow: Few-step speech generation with integral velocity dis- tillation,”arXiv preprint arXiv:2510.07979, 2025
-
[34]
Streamflow: Streaming flow matching with block-wise guided attention mask for speech token decoding,
D. Guo, J. Yao, L. Ma, H. Wang, and L. Xie, “Streamflow: Streaming flow matching with block-wise guided attention mask for speech token decoding,” inNational Conference on Man- Machine Speech Communication. Springer, 2025, pp. 75–86
2025
-
[35]
Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,
H. He, Z. Shang, C. Wang, X. Li, Y . Gu, H. Hua, L. Liu, C. Yang, J. Li, P. Shiet al., “Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 885–890
2024
-
[36]
Wenetspeech4tts: A 12,800-hour mandarin tts corpus for large speech generation model bench- mark,
L. Ma, D. Guo, K. Song, Y . Jiang, S. Wang, L. Xue, W. Xu, H. Zhao, B. Zhang, and L. Xie, “Wenetspeech4tts: A 12,800-hour mandarin tts corpus for large speech generation model bench- mark,”arXiv preprint arXiv:2406.05763, 2024
-
[37]
Libriheavy: A 50,000 hours asr corpus with punc- tuation casing and context,
W. Kang, X. Yang, Z. Yao, F. Kuang, Y . Yang, L. Guo, L. Lin, and D. Povey, “Libriheavy: A 50,000 hours asr corpus with punc- tuation casing and context,” inICASSP 2024-2024 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 10 991–10 995
2024
-
[38]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huanget al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Maskgct: Zero-shot text-to- speech with masked generative codec transformer,
Y . Wang, H. Zhan, L. Liu, R. Zeng, H. Guo, J. Zheng, Q. Zhang, X. Zhang, S. Zhang, and Z. Wu, “Maskgct: Zero-shot text-to- speech with masked generative codec transformer,”arXiv preprint arXiv:2409.00750, 2024
-
[40]
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. Zhao, K. Yu, and X. Chen, “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,”CoRR, vol. abs/2410.06885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.