MindMelody: A Closed-Loop EEG-Driven System for Personalized Music Intervention
Pith reviewed 2026-05-21 00:56 UTC · model grok-4.3
The pith
MindMelody decodes real-time EEG into affect states to drive a closed-loop music generation system that adapts to instantaneous emotional needs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
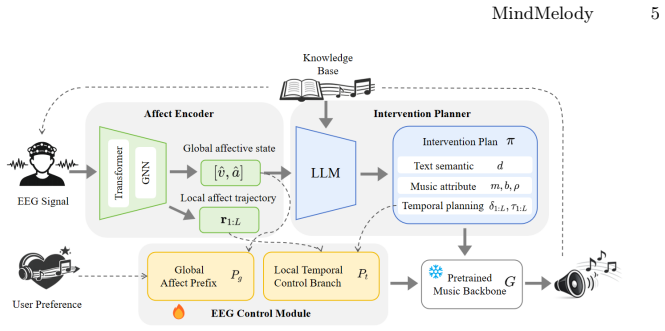
MindMelody is a fully functional closed-loop real-time system for EEG-driven personalized music intervention. A hybrid Transformer-GNN decodes raw EEG into global Valence-Arousal states and local temporal affect trajectories. These states enter a RAG-equipped LLM that produces structured intervention plans, which a Hierarchical EEG Controller then injects as global prefixes and local guidance into a pretrained music backbone. A continuous feedback loop updates generation parameters on the fly from the user's evolving EEG dynamics.
What carries the argument
The emotion-mediated semantic bridge: EEG signals are decoded into affective states that serve as the intermediary layer between brain data and controllable music synthesis parameters.
If this is right
- Music generation gains measurable improvements in control adherence to the intended emotional direction.
- Emotional alignment between generated audio and the user's real-time state increases compared with static baselines.
- Users report higher perceived helpfulness after short-term sessions with the adaptive system.
- The architecture demonstrates a workable path for affect-aware music frameworks that update continuously rather than once at the start.
Where Pith is reading between the lines
- If the loop remains stable over longer periods, the same components could support daily mental-health routines rather than lab sessions only.
- The same EEG-to-plan-to-audio chain could be tested with other sensory outputs such as lighting or scent to broaden non-verbal regulation tools.
- Wearable EEG headbands already on the market could serve as the input device, turning the method into a portable consumer product.
Load-bearing premise
Real-time EEG signals can be decoded reliably enough by the hybrid model to produce affect states that the downstream LLM and controller can actually use to change music output.
What would settle it
A controlled listening study that finds no measurable improvement in emotional alignment scores or user helpfulness ratings when participants use MindMelody versus a non-adaptive music player.
Figures

read the original abstract
Driven by the escalating global burden of mental health conditions, music-based interventions have attracted significant attention as a non-invasive, cost-effective modality for emotion regulation and psychological stress relief. However, current digital music services rely on static preferences and fail to adapt to users' instantaneous psychological states. Furthermore, directly mapping electroencephalography (EEG) to music generation remains challenging due to severe paired-data scarcity and a lack of interpretability. To address these limitations, we propose MindMelody, a fully functional, closed-loop real-time system for EEG-driven personalized music intervention. MindMelody introduces an emotion-mediated semantic bridge. Specifically, a hybrid Transformer-GNN first decodes real-time EEG signals into global Valence-Arousal states and local temporal affect trajectories. These states are then fed into a Retrieval-Augmented Generation (RAG)-equipped Large Language Model (LLM) to formulate structured intervention plans. Subsequently, a novel Hierarchical EEG Controller injects global affect prefixes and local temporal guidance into a pretrained music backbone, enabling fine-grained controllable audio synthesis. Crucially, the system incorporates a continuous feedback loop that updates generation parameters on the fly based on the user's evolving EEG dynamics. Extensive experiments show that MindMelody improves control adherence and emotional alignment, and receives higher perceived helpfulness in a short-term listening setting, suggesting its promise as an adaptive affect-aware music generation framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MindMelody, a closed-loop real-time EEG-driven system for personalized music intervention. A hybrid Transformer-GNN decodes real-time EEG signals into global Valence-Arousal states and local temporal affect trajectories; these feed a RAG-equipped LLM to generate structured intervention plans. A Hierarchical EEG Controller then injects global affect prefixes and local temporal guidance into a pretrained music backbone for controllable audio synthesis, with a continuous feedback loop that updates parameters based on evolving EEG dynamics. The paper claims that extensive experiments demonstrate improvements in control adherence, emotional alignment, and perceived helpfulness in a short-term listening setting.
Significance. If the central claims hold, the work could advance adaptive music-based mental health interventions by establishing an interpretable semantic bridge between real-time brain signals and fine-grained controllable music generation. The combination of EEG decoding, RAG-LLM planning, and hierarchical control addresses key limitations of static preference-based services and direct EEG-to-music mapping.
major comments (1)
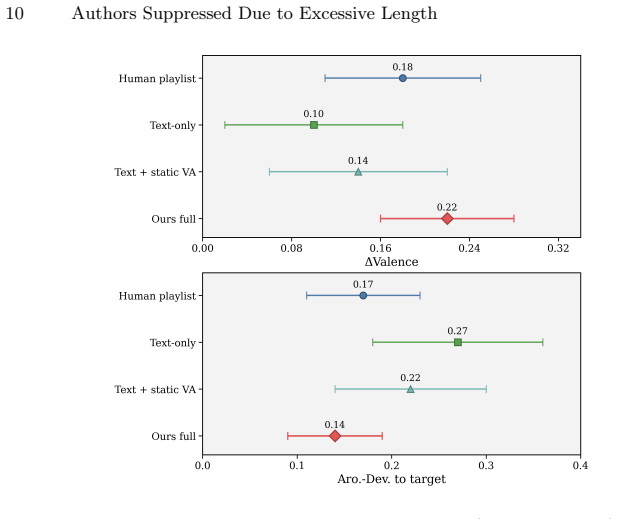
- [Abstract and System Description] Abstract and System Description (hybrid Transformer-GNN component): The central claim that the hybrid Transformer-GNN reliably extracts global Valence-Arousal states and local temporal affect trajectories from noisy, subject-specific EEG in real time is load-bearing for the closed-loop premise and for attributing improvements to the EEG-mediated bridge. No per-subject classification accuracies, confusion matrices, temporal alignment scores, ablation results on the EEG decoder, or robustness metrics under real-time conditions are reported, leaving open the possibility that observed gains in control adherence and emotional alignment arise from the music backbone, user expectations, or post-hoc selection rather than the claimed decoding step.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract and System Description] Abstract and System Description (hybrid Transformer-GNN component): The central claim that the hybrid Transformer-GNN reliably extracts global Valence-Arousal states and local temporal affect trajectories from noisy, subject-specific EEG in real time is load-bearing for the closed-loop premise and for attributing improvements to the EEG-mediated bridge. No per-subject classification accuracies, confusion matrices, temporal alignment scores, ablation results on the EEG decoder, or robustness metrics under real-time conditions are reported, leaving open the possibility that observed gains in control adherence and emotional alignment arise from the music backbone, user expectations, or post-hoc selection rather than the claimed decoding step.
Authors: We agree that the manuscript would benefit from more detailed quantitative evaluation of the hybrid Transformer-GNN decoder to strengthen attribution of system improvements to the EEG decoding stage. In the revised version, we will add per-subject classification accuracies and standard deviations for Valence-Arousal prediction, confusion matrices, temporal alignment scores (e.g., dynamic time warping or correlation metrics between predicted and ground-truth affect trajectories), ablation results isolating the Transformer and GNN contributions, and robustness metrics under simulated real-time conditions including streaming latency and additive noise. These results will be presented in a new subsection of the Experiments section with corresponding figures and tables. revision: yes
Circularity Check
No circularity in system architecture or claims
full rationale
The paper describes an EEG-driven music intervention system using a hybrid Transformer-GNN decoder, RAG-LLM, and Hierarchical EEG Controller, with a feedback loop. No equations, parameter fits, or derivations are present in the abstract or system description. Claims about decoding EEG into Valence-Arousal states and trajectories are architectural assertions, not reductions of outputs to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way. Experimental improvements are reported as empirical outcomes rather than predicted quantities forced by fitted inputs. This is a standard engineering system paper with independent content.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a hybrid Transformer-GNN first decodes real-time EEG signals into global Valence-Arousal states and local temporal affect trajectories... Hierarchical EEG Controller injects global affect prefixes and local temporal guidance into a pretrained music backbone
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
continuous feedback loop that updates generation parameters on the fly based on the user's evolving EEG dynamics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
The effect of music on the human stress response,
M. V. Thoma, R. La Marca, R. Brönnimann, L. Finkel, U. Ehlert, and U. M. Nater, “The effect of music on the human stress response,”PLOS ONE, vol. 8, no. 8, p. e70156, 2013
work page 2013
-
[3]
DEAP: A database for emotion analysis using physiological signals,
S. Koelstraet al., “DEAP: A database for emotion analysis using physiological signals,”IEEE Transactions on Affective Computing, vol. 3, no. 1, pp. 18–31, 2012
work page 2012
-
[4]
W.-L. Zheng and B.-L. Lu, “Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks,”IEEE Transactions on Autonomous Mental Development, vol. 7, no. 3, pp. 162–175, 2015
work page 2015
-
[5]
EEG-basedemotionrecognition:Atutorialandreview,
X. Li, Y. Zhang, P. Tiwari, D. Song, B. Hu, M. Yang, Z. Zhao, N. Kumar, and P.Marttinen,“EEG-basedemotionrecognition:Atutorialandreview,”ACM Com- puting Surveys, vol. 55, no. 4, pp. 1–57, 2022
work page 2022
-
[6]
Hybrid transfer learning strategy for cross-subject EEG emotion recognition,
W. Lu, H. Liu, H. Ma, T.-P. Tan, and L. Xia, “Hybrid transfer learning strategy for cross-subject EEG emotion recognition,”Frontiers in Human Neuroscience, vol. 17, Art. 1280241, 2023
work page 2023
-
[7]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewiset al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems, vol. 33, 2020
work page 2020
-
[8]
CLAP: Learning audio concepts from natural language supervision,
B. Elizalde, S. Deshmukh, M. Al Ismail, and H. Wang, “CLAP: Learning audio concepts from natural language supervision,” inProc. IEEE Int. Conf. Acoustics, Speech and Signal Processing (ICASSP), 2023
work page 2023
-
[9]
Simple and controllable music generation,
J. Copetet al., “Simple and controllable music generation,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
work page 2023
-
[10]
JASCO: Joint audio and symbolic conditioning for temporally controlled text-to-music generation,
A. Défossezet al., “JASCO: Joint audio and symbolic conditioning for temporally controlled text-to-music generation,”arXiv preprint arXiv:2406.10970, 2024
-
[11]
Parameter-efficient transfer learning for music foundation models,
Y. Ding and A. Lerch, “Parameter-efficient transfer learning for music foundation models,”arXiv preprint arXiv:2411.19371, 2024
-
[12]
Fréchet audio distance: A reference-free metric for evaluating music enhancement algorithms,
K. Kilgour, M. Zuluaga, D. Roblek, and M. Sharifi, “Fréchet audio distance: A reference-free metric for evaluating music enhancement algorithms,” inProc. In- terspeech, pp. 2350–2354, 2019
work page 2019
-
[13]
Naturalistic music decoding from EEG data via latent diffusion mod- els,
E. Postolache, N. Polouliakh, H. Kitano, A. Connelly, E. Rodolà, L. Cosmo, and T. Akama, “Naturalistic music decoding from EEG data via latent diffusion mod- els,”arXiv preprint arXiv:2405.09062, 2024. 12 Authors Suppressed Due to Excessive Length
-
[14]
Domain-adversarialtrainingofneuralnetworks,
Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M.Marchand,andV.Lempitsky,“Domain-adversarialtrainingofneuralnetworks,” Journal of Machine Learning Research, vol. 17, no. 59, pp. 1–35, 2016
work page 2016
-
[15]
MusicLM: Generating Music From Text
A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. Tagliasacchi, M. Sharifi, N. Zeghidour, and C. Frank, “MusicLM: Generating music from text,”arXiv preprint arXiv:2301.11325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,”arXiv preprint arXiv:1711.05101, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[17]
W. Chen, J. Feng, C. Lin, H. Zhang, and Z. Liu, “EEG-based emotion recogni- tion using graph convolutional neural network with dual attention mechanism,” Frontiers in Computational Neuroscience, vol. 18, 2024
work page 2024
-
[18]
EEG-based emotion recognition us- ing multi-scale dynamic CNN and gated transformer network,
Z. Cheng, Y. Zhang, X. Wang, and Y. Li, “EEG-based emotion recognition us- ing multi-scale dynamic CNN and gated transformer network,”Scientific Reports, vol. 14, 2024
work page 2024
-
[19]
Mustango: Toward controllable text-to-music generation,
J. Melechovsky, Z. Guo, D. Ghosal, N. Majumder, D. Herremans, and S. Poria, “Mustango: Toward controllable text-to-music generation,” inProc. NAACL-HLT, pp. 8286–8309, 2024
work page 2024
-
[20]
S. Wu, D. Yu, X. Tan, and M. Sun, “CLaMP: Contrastive language-music pre- training for cross-modal symbolic music information retrieval,” inProc. ISMIR, pp. 157–165, 2023
work page 2023
-
[21]
Prefix-tuning: Optimizing continuous prompts for genera- tion,
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for genera- tion,” inProc. ACL-IJCNLP, pp. 4582–4597, 2021
work page 2021
-
[22]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inProc. ICLR, 2022
work page 2022
-
[23]
Cross-attention is all you need: Adapting pre- trained transformers for machine translation,
M. Gheini, X. Ren, and J. May, “Cross-attention is all you need: Adapting pre- trained transformers for machine translation,” inProc. EMNLP, pp. 1754–1765, 2021
work page 2021
-
[24]
A concordance correlation coefficient to evaluate reproducibility,
L. I.-K. Lin, “A concordance correlation coefficient to evaluate reproducibility,” Biometrics, vol. 45, no. 1, pp. 255–268, 1989
work page 1989
-
[25]
P.800.1: Mean opinion score (MOS) terminology,
ITU-T, “P.800.1: Mean opinion score (MOS) terminology,” International Telecom- munication Union, 2016
work page 2016
-
[26]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu,et al., “Qwen2.5 technical report,” arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Simple and controllable music generation,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y. Adi, and A. Dé- fossez, “Simple and controllable music generation,” inProc. NeurIPS, 2023
work page 2023
-
[28]
K. S. Moore and D. Hanson-Abromeit, “Theory-guided therapeutic function of music to facilitate emotion regulation development in preschool-aged children,” Frontiers in Human Neuroscience, vol. 9, p. 572, 2015
work page 2015
-
[29]
Y. Liu, G. Liu, D. Wei, Q. Li, G. Yuan, S. Wu, G. Wang, and X. Zhao, “Effects of musical tempo on musicians’ and non-musicians’ emotional experience when listening to music,”Frontiers in Psychology, vol. 9, p. 2118, 2018
work page 2018
-
[30]
Music, emotion, and time perception: The influence of subjective emotional valence and arousal?,
S. Droit-Volet, D. Ramos, M. Piñeiro Chousa, and E. Bigand, “Music, emotion, and time perception: The influence of subjective emotional valence and arousal?,” Frontiers in Psychology, vol. 4, p. 417, 2013
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.