Toward Ethical Facial Age Estimation: A Generalized Zero-Shot Benchmark Without Training on Children's Data
Pith reviewed 2026-06-29 08:39 UTC · model grok-4.3
The pith
Facial age estimation models trained only on ages 18-59 fail to generalize to younger or older faces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
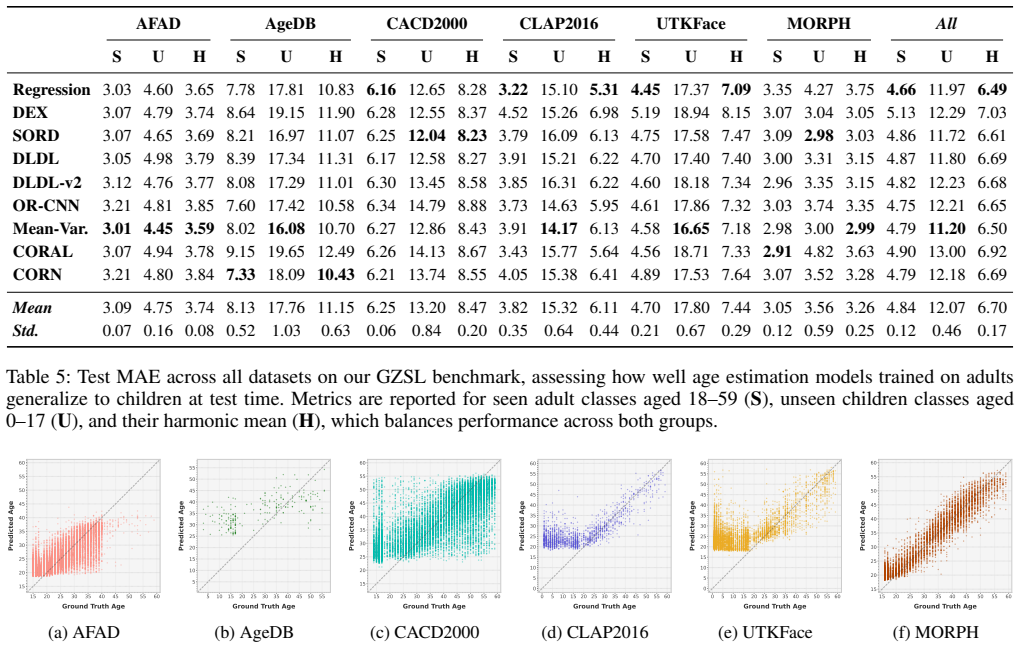
Standardized splits that train, validate, and test only on ages 18-59 while holding under-18 samples for zero-shot evaluation and 60+ for distribution-shift validation reveal that all nine tested state-of-the-art age estimation methods suffer substantial performance degradation on unseen age groups, with an average drop of 46.4 percent and a maximum of 52.8 percent relative to supervised baselines, accompanied by systematic anchoring of predictions to seen age classes.
What carries the argument
Generalized zero-shot benchmark protocol that enforces strict age-group separation across existing datasets and subject-exclusive splits to prevent identity leakage.
If this is right
- Existing supervised age estimation pipelines cannot meet ethical constraints without major accuracy loss on younger populations.
- Seen-class bias must be explicitly mitigated for any model to handle age distribution shifts.
- The benchmark supplies a reproducible protocol for testing future methods under restricted training regimes.
- Responsible deployment requires new techniques that extrapolate beyond the training age range rather than defaulting to nearby seen values.
Where Pith is reading between the lines
- Analogous restricted-data benchmarks could be defined for other attributes where training data raises consent issues.
- Real systems may require hybrid approaches that combine adult-only training with explicit mechanisms for out-of-range age handling.
- Dataset curators might prioritize adult-only collections or synthetic augmentation strategies to support ethical model development.
Load-bearing premise
The chosen age boundaries and dataset splits provide a representative test of real-world generalization under ethical data limits without adding new selection biases.
What would settle it
An age estimation method that, when trained only on 18-59 data, achieves mean absolute error on under-18 faces within 10 percent of its supervised baseline performance on the same test set.
Figures


read the original abstract
Age estimation from facial images typically relies on training data that includes images of minors, a practice that raises serious ethical, legal, and privacy concerns. In this work, we propose a generalized zero-shot benchmark for facial age estimation that explicitly excludes children's data during training while still assessing model performance on younger populations. We revisit six widely used datasets and introduce standardized splits with strict age-group separation: samples aged 18-59 for training, validation, and testing; samples under 18 reserved exclusively for zero-shot evaluation; and samples 60+ as an unseen validation set for model selection under distribution shift. For datasets with identity annotations, subject-exclusive splits prevent identity leakage and better reflect real-world deployment conditions. Evaluating nine state-of-the-art age estimation methods under this protocol reveals that all evaluated methods consistently fail to generalize to unseen age groups, suffering substantial performance degradation -- on average 46.4%, and up to 52.8% -- relative to the supervised baseline. Moreover, models do not simply degrade: they systematically anchor predictions for unseen ages to nearby seen classes, a manifestation of the well-known seen-class bias in generalized zero-shot learning. By formalizing age estimation without children's data as a generalized zero-shot benchmark on existing datasets, this work highlights a critical gap between current modeling practices and real-world ethical constraints. Our benchmark provides a principled basis for evaluating models under restricted data regimes and encourages the development of methods that are robust to distribution shift and aligned with responsible data use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a generalized zero-shot benchmark for facial age estimation that excludes children's data from training. It defines standardized splits across six existing datasets (18-59 for train/val/test, under-18 reserved for zero-shot evaluation, 60+ as unseen validation) with subject-exclusive splits where possible, then evaluates nine state-of-the-art methods and reports consistent performance degradation of 46.4% on average (up to 52.8%) relative to supervised baselines on unseen ages, along with systematic anchoring of predictions to nearby seen classes.
Significance. If the proposed splits provide a clean test of age generalization under the ethical constraint, the work is significant for formalizing responsible data-use protocols in facial analysis and for empirically documenting the seen-class bias in current age estimators. The benchmark itself could serve as a reusable evaluation standard for methods that must operate without minor data.
major comments (2)
- [Dataset splits / experimental protocol] Dataset construction and splits: The central claim that the observed 46.4% degradation demonstrates failure to generalize under ethical constraints (rather than other distribution shifts) requires evidence that under-18 and 18-59 images do not differ systematically in pose, illumination, ethnicity, or capture device. No such analysis (e.g., metadata statistics or feature-distribution comparison) is described; without it the attribution of degradation to age extrapolation is not load-bearing.
- [Experiments / results] Evaluation details: The headline numbers (46.4% average, 52.8% max degradation) are presented without specifying the exact metric (MAE, CS, etc.), number of runs, variance, or statistical tests. The supervised baseline must also be defined precisely (same 18-59 split only, or additional data). These omissions prevent independent verification of the consistency claim across the nine methods.
minor comments (2)
- [Benchmark definition] Clarify whether the 60+ unseen validation set is used only for model selection or also for reporting; its role should be stated explicitly in the protocol description.
- [Methods] Add a table listing the exact nine methods, their original papers, and any modifications made for the zero-shot protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental rigor that we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Dataset splits / experimental protocol] Dataset construction and splits: The central claim that the observed 46.4% degradation demonstrates failure to generalize under ethical constraints (rather than other distribution shifts) requires evidence that under-18 and 18-59 images do not differ systematically in pose, illumination, ethnicity, or capture device. No such analysis (e.g., metadata statistics or feature-distribution comparison) is described; without it the attribution of degradation to age extrapolation is not load-bearing.
Authors: We agree that the absence of an explicit analysis of potential non-age distribution shifts (pose, illumination, ethnicity, capture device) weakens the attribution of performance degradation solely to age extrapolation. The manuscript relies on age-based splits and subject exclusivity to control for identity leakage, but does not provide the requested metadata or feature comparisons. In the revised version, we will add available metadata statistics (e.g., ethnicity distributions from datasets that annotate them) and explicitly discuss limitations for datasets lacking such metadata. We will also note that a full feature-distribution comparison would require additional experiments beyond the current scope. revision: yes
-
Referee: [Experiments / results] Evaluation details: The headline numbers (46.4% average, 52.8% max degradation) are presented without specifying the exact metric (MAE, CS, etc.), number of runs, variance, or statistical tests. The supervised baseline must also be defined precisely (same 18-59 split only, or additional data). These omissions prevent independent verification of the consistency claim across the nine methods.
Authors: We will revise the experimental section to specify all requested details. The degradation percentages are computed using Mean Absolute Error (MAE). The supervised baseline is trained exclusively on the same 18-59 split as the zero-shot methods (no additional data). All results are averaged over three runs with different random seeds; we will report standard deviations and include statistical tests (e.g., paired t-tests) to support the consistency claim across the nine methods. revision: yes
Circularity Check
No circularity; empirical evaluation on held-out splits is independent of any derivation chain.
full rationale
The paper defines standardized splits (18-59 train/val/test, under-18 zero-shot, 60+ unseen) on six existing datasets and reports measured MAE degradation for nine methods. All results are direct empirical comparisons between supervised baselines and zero-shot performance on the held-out partitions; no equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citations are used to derive the central claims. The 46.4% average degradation figure is computed from observed outputs on the proposed splits and does not reduce to any input by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InIEEE Conference on Computer Vision and Pattern Recog- nition, 819–826
Label-Embedding for Attribute-Based Classification. InIEEE Conference on Computer Vision and Pattern Recog- nition, 819–826. Akata, Z.; Reed, S.; Walter, D.; Lee, H.; and Schiele, B
-
[2]
InIEEE Conference on Computer Vision and Pattern Recognition, 2927–2936
Evaluation of output embeddings for fine-grained im- age classification. InIEEE Conference on Computer Vision and Pattern Recognition, 2927–2936. Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; and Koyama, M
-
[3]
arXiv preprint arXiv:2110.01963 , year =
Optuna: A Next-Generation Hyperparameter Opti- mization Framework. InACM International Conference on Knowledge Discovery & Data Mining, 2623–2631. Birhane, A.; Prabhu, V . U.; and Kahembwe, E. 2021. Mul- timodal datasets: misogyny, pornography, and malignant stereotypes.arXiv preprint arXiv:2110.01963. Caetano, C.; Santos, G. O. d.; Petrucci, C.; Barros, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.