Can Machines Really See Objects in Images? A Study Based on Syntactic Distance and Visual Self-Referential Instances
Pith reviewed 2026-06-30 07:57 UTC · model grok-4.3
The pith
Vision models collapse to random guessing on tasks requiring global semantics once image scale crosses a critical point.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
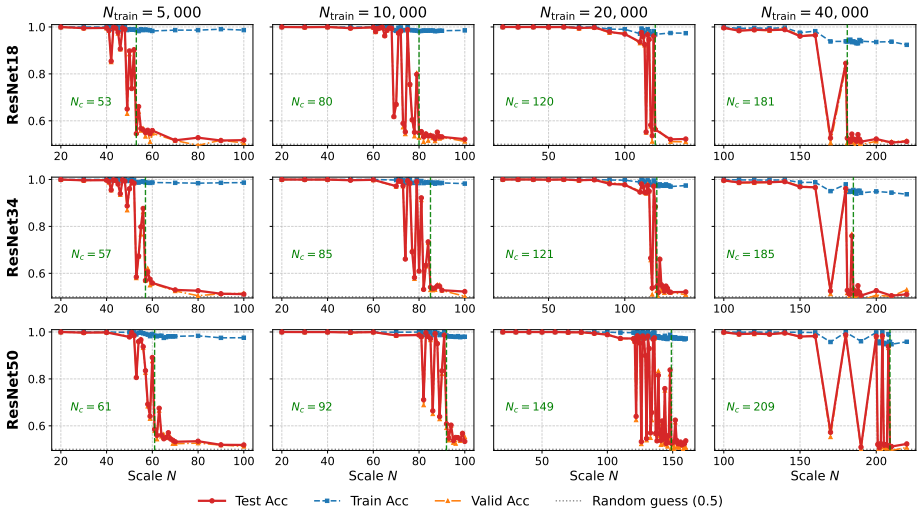
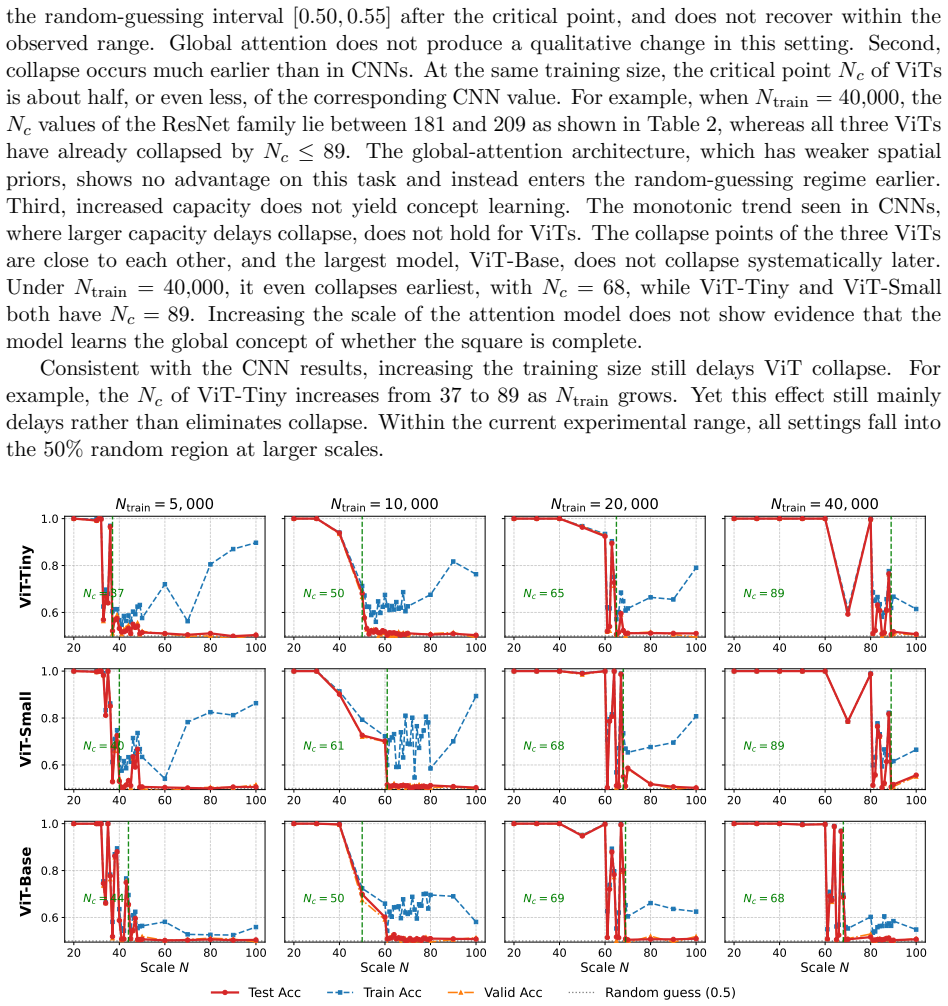
Experiments on ResNets and Vision Transformers reveal a consistent phase-transition phenomenon, with accuracy collapsing to random guessing once the image scale crosses a critical point and does not recover within the tested range. Larger training sets and models only delay this collapse, while globally attentive ViTs reach it earlier. These results reveal a structural capability boundary of current architectures on global-concept tasks, suggesting that general intelligence may require creating new language, not reusing an existing one.
What carries the argument
Syntactic distance, which quantifies class separability by the symmetry of operations mapping one class to the other; zero distance forces reliance on global semantics rather than local rules in the visual self-referential task.
If this is right
- Accuracy on the self-referential task drops to random guessing once image scale exceeds a critical threshold.
- Increasing model size or training data only postpones the accuracy collapse.
- Vision Transformers reach the collapse earlier than ResNets despite global attention.
- Zero syntactic distance removes exploitable local features and exposes dependence on global semantics.
Where Pith is reading between the lines
- Models limited to existing descriptive systems may fail on any task whose solution requires inventing new syntactic distinctions.
- The observed boundary could underlie poor generalization on relational or abstract visual reasoning problems.
- New architectures might need explicit mechanisms for generating novel syntactic rules rather than fitting existing feature spaces.
Load-bearing premise
The positive and negative samples in the constructed task truly have zero syntactic distance, so that no stable local basis for distinction exists.
What would settle it
Demonstration of a model that maintains above-chance accuracy on the self-referential task at image scales past the reported critical point without using local pixel statistics.
Figures


read the original abstract
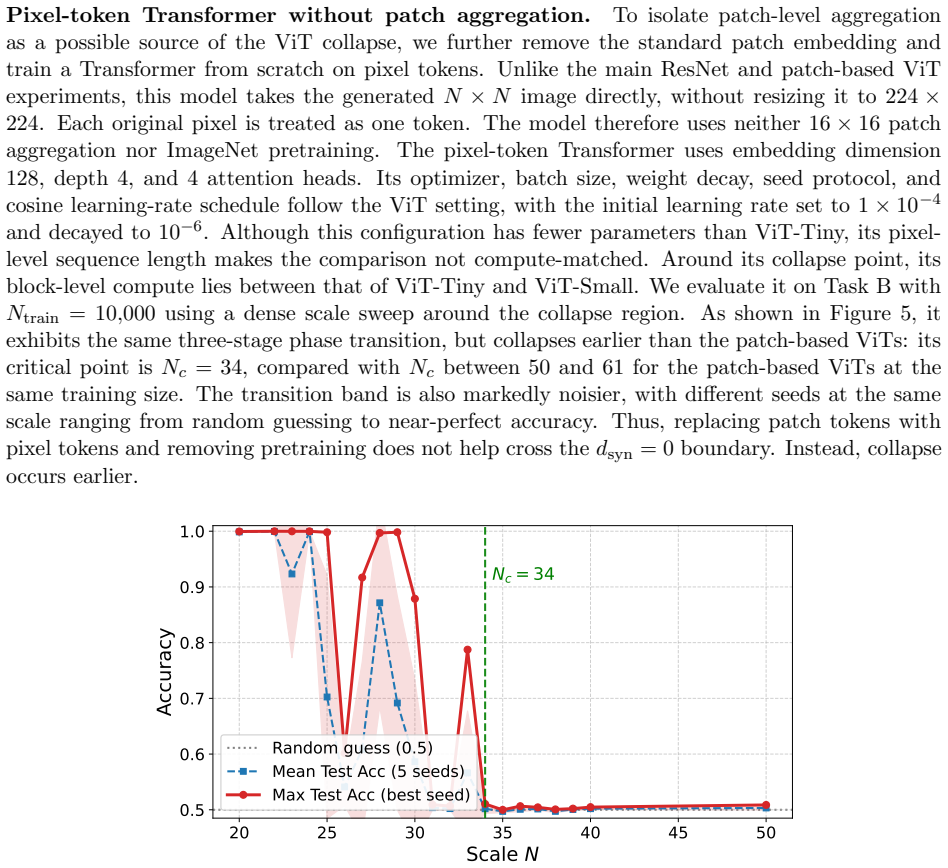
Can a vision model truly see an object, or does it only fit surface-level visual cues? Following Wittgenstein's view that the limits of language are the limits of the world, we view a model's recognition ability as bounded by the descriptive system it has learned. In current vision models, this system is often realized through learned feature representations that exploit local statistical cues. We therefore ask whether a model can still classify correctly when such local cues provide no stable basis for distinction. We formalize this question with syntactic distance, which measures class separability through the symmetry of the operations mapping one class to the other: positive distance exposes exploitable local features, whereas zero distance requires global semantics rather than local rules. We construct a visual self-referential task in maximum-variance binary noise: positive samples contain a closed square, while negative samples contain an otherwise identical square with one flipped boundary pixel. The two classes differ in global semantics but have zero syntactic distance, making local statistical shortcuts unreliable. Experiments on ResNets and Vision Transformers reveal a consistent phase-transition phenomenon, with accuracy collapsing to random guessing once the image scale crosses a critical point and does not recover within the tested range. Larger training sets and models only delay this collapse, while globally attentive ViTs reach it earlier. These results reveal a structural capability boundary of current architectures on global-concept tasks, suggesting that general intelligence may require creating new language, not reusing an existing one.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces syntactic distance as a measure of class separability via symmetry of operations mapping one class to the other (zero distance requires global semantics). It constructs a visual self-referential task in maximum-variance binary noise where positives contain a closed square and negatives an otherwise identical square with one flipped boundary pixel. Experiments on ResNets and Vision Transformers report a consistent phase-transition phenomenon in which accuracy collapses to random guessing once image scale exceeds a critical point and does not recover; larger models or datasets only delay the collapse, with globally attentive ViTs reaching it earlier. The authors interpret this as evidence of a structural capability boundary on global-concept tasks.
Significance. If the zero syntactic distance claim holds and the phase transition is shown to be independent of local shortcuts, the result would be significant for computer vision: it would provide empirical evidence of a scale-dependent limit on current architectures for tasks that cannot be solved by local statistical cues, supporting the broader claim that general visual intelligence may require new descriptive systems rather than reuse of existing feature representations.
major comments (2)
- [Task formalization] Task formalization (abstract and § on visual self-referential task): the central claim that the single boundary-pixel flip yields zero syntactic distance (i.e., the symmetry of operations provides no stable local basis for distinction) is load-bearing for the phase-transition interpretation. The construction places both classes in maximum-variance binary noise and differs only by one pixel; without an explicit protocol showing that flip positions are fully randomized per sample and that no boundary-consistency or local-patch statistic remains exploitable, the zero-distance assumption remains unverified and the collapse could reflect detection of a localized anomaly rather than a global-semantics requirement.
- [Experiments] Experiments section (phase-transition results): the reported collapse to random guessing at critical scale is presented as evidence of a structural boundary, yet no equations, training details, or verification that the syntactic-distance definition actually produces the claimed separability are supplied. This makes it impossible to confirm that the outcome is not reducible to a fitted local cue or to an artifact of how the binary-noise images are generated at different scales.
minor comments (1)
- [Abstract] Abstract: the terms 'syntactic distance' and 'visual self-referential task' are introduced without the formal definitions or any equation that would allow immediate assessment of the zero-distance property.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below with clarifications on the task construction and experimental presentation, and we commit to revisions that add the requested protocols, equations, and details without altering the core claims.
read point-by-point responses
-
Referee: [Task formalization] Task formalization (abstract and § on visual self-referential task): the central claim that the single boundary-pixel flip yields zero syntactic distance (i.e., the symmetry of operations provides no stable local basis for distinction) is load-bearing for the phase-transition interpretation. The construction places both classes in maximum-variance binary noise and differs only by one pixel; without an explicit protocol showing that flip positions are fully randomized per sample and that no boundary-consistency or local-patch statistic remains exploitable, the zero-distance assumption remains unverified and the collapse could reflect detection of a localized anomaly rather than a global-semantics requirement.
Authors: The zero syntactic distance follows directly from the definition: the sole operation mapping one class to the other is a single boundary-pixel flip whose position is chosen uniformly at random on the square perimeter for every sample. Because the background is i.i.d. maximum-variance binary noise, no fixed local patch or boundary-consistency statistic can be stable across the dataset. We will add an explicit generation protocol together with pseudocode in the revised manuscript to make this randomization and the resulting absence of exploitable local cues fully verifiable. revision: yes
-
Referee: [Experiments] Experiments section (phase-transition results): the reported collapse to random guessing at critical scale is presented as evidence of a structural boundary, yet no equations, training details, or verification that the syntactic-distance definition actually produces the claimed separability are supplied. This makes it impossible to confirm that the outcome is not reducible to a fitted local cue or to an artifact of how the binary-noise images are generated at different scales.
Authors: We accept that the current manuscript presents results at a conceptual level and omits the formal equations for syntactic distance as well as complete training specifications. The syntactic-distance definition is the minimal symmetric operation count (zero in this case), and the observed phase transition occurs at architecture-dependent critical scales even though the noise statistics are scale-invariant. We will insert the missing equations, full hyperparameter tables, and additional controls that test for residual local-cue exploitation in the revised experiments section. revision: yes
Circularity Check
No circularity; empirical phase-transition is measured outcome on constructed task
full rationale
The paper defines syntactic distance, constructs a visual self-referential task asserted to have zero syntactic distance (closed square vs. one-pixel flip in binary noise), and reports experimental accuracy collapse on ResNets and ViTs as image scale increases. This outcome is obtained by direct training and evaluation on the task; it does not reduce by the paper's equations or descriptions to a quantity defined in terms of a fitted parameter, nor does it rely on self-citation chains, uniqueness theorems, or smuggled ansatzes. The derivation chain is therefore self-contained as an empirical observation rather than a tautological renaming or fit.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Class separability can be measured by the symmetry of operations mapping one class to the other
invented entities (2)
-
syntactic distance
no independent evidence
-
visual self-referential task in maximum-variance binary noise
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Annalen der Naturphilosophie , volume=
Logisch-philosophische abhandlung , author=. Annalen der Naturphilosophie , volume=
-
[2]
2025 , publisher=
Xu, Ke and Zhou, Guangyan , journal=. 2025 , publisher=
2025
-
[3]
arXiv preprint arXiv:2601.19393 , year=
Constructing self-referential instances for the clique problem , author=. arXiv preprint arXiv:2601.19393 , year=
-
[4]
Self-referential instances of the dominating set problem are irreducible
Self-referential instances of the dominating set problem are irreducible , author=. arXiv preprint arXiv:2602.10559 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Solution independence and self-referential instances
Solution independence and self-referential instances , author=. arXiv preprint arXiv:2605.02174 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[7]
International Conference on Learning Representations (ICLR) , year =
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and others , title =. International Conference on Learning Representations (ICLR) , year =
-
[8]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[9]
International conference on learning representations , year=
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness , author=. International conference on learning representations , year=
-
[10]
Explaining and Harnessing Adversarial Examples
Explaining and harnessing adversarial examples , author=. arXiv preprint arXiv:1412.6572 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
International Conference on Learning Representations , year=
Understanding deep learning requires rethinking generalization , author=. International Conference on Learning Representations , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Recurrent world models facilitate policy evolution , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
2, 2022-06-27 , author=
A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27 , author=. Open Review , volume=
2022
-
[14]
Physica D: Nonlinear Phenomena , volume=
The symbol grounding problem , author=. Physica D: Nonlinear Phenomena , volume=. 1990 , publisher=
1990
-
[15]
Proceedings of the 40th International Conference on Machine Learning , pages=
PaLM-E: an embodied multimodal language model , author=. Proceedings of the 40th International Conference on Machine Learning , pages=
-
[16]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[17]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Climbing towards NLU: On meaning, form, and understanding in the age of data , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[18]
ACM Computing Surveys , volume=
Understanding world or predicting future? a comprehensive survey of world models , author=. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[19]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[20]
Nature Machine Intelligence , volume=
AI for radiographic COVID-19 detection selects shortcuts over signal , author=. Nature Machine Intelligence , volume=. 2021 , publisher=
2021
-
[21]
Journal of Intelligent Manufacturing , volume=
Segmentation-based deep-learning approach for surface-defect detection , author=. Journal of Intelligent Manufacturing , volume=. 2020 , publisher=
2020
-
[22]
Approximating
Wieland Brendel and Matthias Bethge , booktitle=. Approximating. 2019 , url=
2019
-
[23]
PLoS computational biology , volume=
Deep convolutional networks do not classify based on global object shape , author=. PLoS computational biology , volume=. 2018 , publisher=
2018
-
[24]
Measuring the tendency of CNNs to Learn Surface Statistical Regularities
Measuring the tendency of cnns to learn surface statistical regularities , author=. arXiv preprint arXiv:1711.11561 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Advances in neural information processing systems , volume=
Adversarial examples are not bugs, they are features , author=. Advances in neural information processing systems , volume=
-
[26]
Advances in neural information processing systems , volume=
The origins and prevalence of texture bias in convolutional neural networks , author=. Advances in neural information processing systems , volume=
-
[27]
Advances in Neural Information Processing Systems , volume=
Intriguing properties of vision transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Tim Genewein and Matija Franklin and Alexander Lerchner and Laurent Orseau and Samuel Albanie and Adam Bales and Cole Wyeth and Stephanie Chan and Iason Gabriel and Joel Z. Leibo and Allan Dafoe and Marcus Hutter and Thore Graepel and Shane Legg , year=. From. 2606.12683 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.