MetaRanker: Human-in-the-loop Active Ranking for Metalens Image Quality
Pith reviewed 2026-06-30 11:12 UTC · model grok-4.3
The pith
MetaRanker ranks metalens images by semantic interpretability using active human feedback, aligning with human judgments while cutting annotations by about 80%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
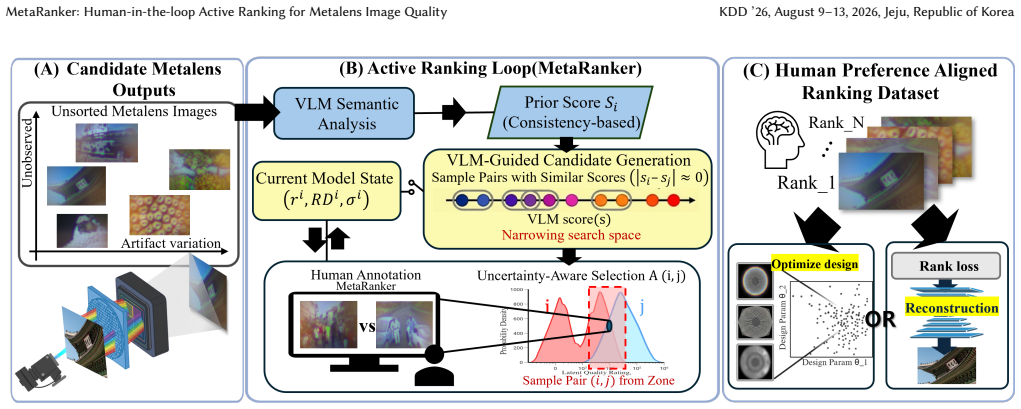
MetaRanker formalizes metalens image quality in terms of semantic interpretability and employs a human-in-the-loop active ranking framework that uses a probabilistic preference model with uncertainty-aware query selection, guided by vision-language model priors only for sampling, to achieve rankings closely aligned with human assessments while requiring approximately 80% fewer pairwise annotations than exhaustive evaluation.
What carries the argument
MetaRanker, a human-in-the-loop active ranking framework that combines a probabilistic preference model with uncertainty-aware query selection and leverages vision-language models to guide sampling of comparisons while keeping human judgments as the primary signal.
Load-bearing premise
Human judgments of semantic interpretability remain the primary supervision signal and are not materially influenced by the VLM priors that are used only to guide sampling of comparisons.
What would settle it
A controlled study on a new metalens dataset where exhaustive human pairwise comparisons produce rankings that diverge substantially from those generated by MetaRanker, while aligning better with PSNR or similar metrics.
Figures



read the original abstract
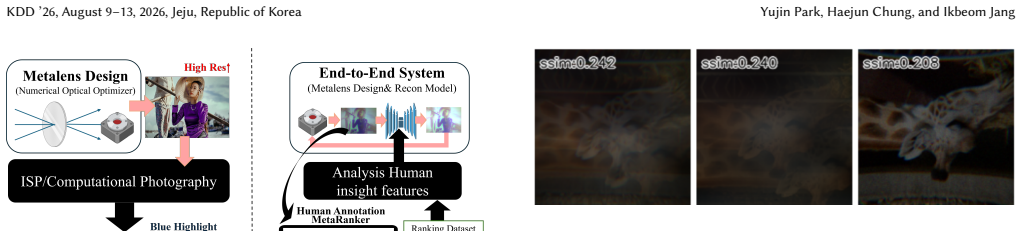
Image quality in modern imaging systems emerges from the coupled effects of the sensor, optics, and computational reconstruction. Ultra-thin metalenses offer a path toward substantial miniaturization of optical modules, but practical designs often exhibit pronounced chromatic and field-dependent aberrations that necessitate computational reconstruction. In current metalens pipelines, reconstruction models are commonly trained and selected using distortion-based fidelity objectives, such as PSNR, yet these proxies can be weakly correlated with human preference and downstream utility, reflecting the well-known perception--distortion trade-off. We introduce MetaRanker, a human-in-the-loop active ranking framework that formalizes metalens image quality in terms of semantic interpretability, defined as the degree to which humans can reliably recognize objects and structures in the presence of optical artifacts. MetaRanker combines a probabilistic preference model with uncertainty-aware query selection, and leverages vision--language models to provide lightweight semantic priors. Importantly, these priors are used only to guide the sampling of informative comparisons; human judgments remain the primary supervision signal throughout. Across real-world and synthetic metalens datasets with distinct degradation profiles, MetaRanker produces rankings that align most closely with human assessments, while reducing the number of pairwise annotations required by approximately 80% relative to exhaustive pairwise evaluation. Finally, we show that standard image quality assessment metrics exhibit limited alignment with human interpretability in the metalens domain, positioning MetaRanker as a practical step toward perceptually grounded metalens evaluation and co-design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MetaRanker, a human-in-the-loop active ranking framework for metalens image quality assessment. It formalizes quality via semantic interpretability (human ability to recognize objects despite optical artifacts) rather than distortion metrics like PSNR. The method uses a probabilistic preference model with uncertainty-aware query selection, employing VLM semantic priors exclusively to guide sampling of comparisons while keeping human judgments as the primary supervision. Evaluated on real-world and synthetic metalens datasets with distinct degradation profiles, it claims rankings that align most closely with human assessments and an ~80% reduction in pairwise annotations relative to exhaustive evaluation. It further shows that standard IQA metrics have limited alignment with human interpretability in this domain.
Significance. If the central claims hold, the work provides a concrete step toward perceptually grounded evaluation and co-design for metalens systems, directly addressing the perception-distortion tradeoff. The explicit design choice to restrict VLMs to query selection (with humans as sole primary signal) and the active-learning reduction in annotation effort are strengths that could generalize to other computational imaging pipelines where traditional metrics diverge from downstream utility.
major comments (1)
- [Abstract and Evaluation section] Abstract and § on Experiments/Evaluation: The strongest claim (superior human alignment + ~80% annotation reduction) is load-bearing on the assertion that 'human judgments remain the primary supervision signal throughout' and that VLM priors affect only sampling. The manuscript does not report (i) whether held-out human rankings used for alignment metrics were drawn from the VLM-guided pool or an independent exhaustive set, nor (ii) an ablation of VLM-guided selection versus random or uncertainty-only baselines. Without these, the reported alignment and efficiency figures are consistent with selection bias toward VLM-human concordant pairs, undermining the separation claim.
minor comments (1)
- [Abstract] The abstract states 'distinct degradation profiles' for the datasets but provides no quantitative characterization (e.g., aberration statistics or PSNR ranges) in the main text; adding a short table or paragraph would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The concern regarding potential selection bias and the need for explicit validation of the VLM-prior separation is well-taken and directly addresses the load-bearing claims in the abstract and evaluation sections. We address the points below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and § on Experiments/Evaluation: The strongest claim (superior human alignment + ~80% annotation reduction) is load-bearing on the assertion that 'human judgments remain the primary supervision signal throughout' and that VLM priors affect only sampling. The manuscript does not report (i) whether held-out human rankings used for alignment metrics were drawn from the VLM-guided pool or an independent exhaustive set, nor (ii) an ablation of VLM-guided selection versus random or uncertainty-only baselines. Without these, the reported alignment and efficiency figures are consistent with selection bias toward VLM-human concordant pairs, undermining the separation claim.
Authors: We agree that the manuscript should explicitly document these experimental controls to substantiate the claim that VLM priors are restricted to query selection. (i) The held-out human rankings used for the alignment metrics (Kendall tau and top-k overlap) were collected via an independent exhaustive pairwise comparison protocol on a disjoint set of images, with no VLM involvement in either sampling or judgment collection. (ii) While the current experiments compare against exhaustive and random baselines, we did not include a dedicated ablation isolating VLM-guided selection from pure uncertainty sampling. In the revision we will add both the clarification on the held-out set and the requested ablation (VLM-guided vs. random vs. uncertainty-only) using the same human annotation budget, reporting the resulting alignment and annotation counts. These additions will be placed in the Experiments section with corresponding updates to the abstract if the numbers change. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an active ranking framework where human judgments serve as the primary supervision signal and VLM outputs are used solely for query selection. No equations, fitted parameters, or self-citations appear in the abstract or described method that reduce the reported alignment with human assessments or the 80% annotation reduction to a self-referential definition or input. Performance claims rest on external human evaluations across datasets, rendering the approach self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Surprise-Guided MergeSort: Budget-Efficient Human-in-the-Loop Ranking via Adaptive Comparison Scheduling
Surprise-Guided MergeSort combines a MergeSort scheduler, a composite VLM-based surprise scorer, and adaptive budget allocation to reduce human comparisons while improving Kendall tau by 6-12 points over Active Elo on...
-
Surprise-Guided MergeSort: Budget-Efficient Human-in-the-Loop Ranking via Adaptive Comparison Scheduling
Surprise-Guided MergeSort uses a VLM-based composite surprise scorer to prioritize human comparisons inside a MergeSort scheduler, skipping up to 535 pairs per session and raising Kendall's τ by 6-12 points over Activ...
Reference graph
Works this paper leans on
-
[1]
Eirikur Agustsson and Radu Timofte. 2017. Ntire 2017 challenge on single image super-resolution: Dataset and study. InProceedings of the IEEE conference on computer vision and pattern recognition workshops. 126–135
2017
- [2]
-
[3]
Johansson
Herman Bergström, Emil Carlsson, Devdatt Dubhashi, and Fredrik D. Johansson
-
[4]
In Advances in Neural Information Processing Systems (NeurIPS)
Active Preference Learning for Ordering Items In- and Out-of-Sample. In Advances in Neural Information Processing Systems (NeurIPS)
-
[5]
Erdem Biyik, Nima Anari, and Dorsa Sadigh. 2024. Batch active learning of reward functions from human preferences.ACM Transactions on Human-Robot Interaction13, 2 (2024), 1–27
2024
-
[6]
Yochai Blau and Tomer Michaeli. 2018. The perception-distortion tradeoff. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6228–6237
2018
-
[7]
Ralph Allan Bradley and Milton E Terry. 1952. Rank analysis of incomplete block designs: I. The method of paired comparisons.Biometrika39, 3/4 (1952), 324–345
1952
-
[8]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Marber, Buck Shlegeris, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems, Vol. 30
2017
-
[9]
Mark E Glickman. 1995. The glicko system.Boston University16, 8 (1995), 9
1995
-
[10]
Glickman
Mark E. Glickman. 2012.Example of the Glicko-2 System. Technical Report. Boston University. 1–6 pages. https://www.glicko.net/glicko/glicko2.pdf Online technical report (commonly cited as 2012)
2012
-
[11]
Andy Gray, Alma Rahat, Tom Crick, and Stephen Lindsay. 2024. A Bayesian active learning approach to comparative judgement within education assessment. Computers and Education: Artificial Intelligence6 (2024), 100245
2024
-
[12]
Xuemei Hu, Weizhu Xu, Qingbin Fan, Tao Yue, Feng Yan, Yanqing Lu, and Ting Xu
-
[13]
Metasurface-based computational imaging: a review.Advanced Photonics 6, 1 (2024), 014002–014002
2024
-
[14]
Quan Huynh-Thu and Mohammed Ghanbari. 2008. Scope of validity of PSNR in image/video quality assessment.Electronics Letters44, 13 (2008), 800–801
2008
-
[15]
Andrey Ignatov, Nikolay Kobyshev, Radu Timofte, Kenneth Vanhoey, and Luc Van Gool. 2017. DSLR-quality photos on mobile devices with deep convolutional networks. InProceedings of the IEEE International Conference on Computer Vision. 3277–3285
2017
-
[16]
Ikbeom Jang, Garrison Danley, Ken Chang, and Jayashree Kalpathy-Cramer
- [17]
-
[18]
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. 2021. MUSIQ: Multi-scale image quality transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision. 5148–5157
2021
-
[19]
Mohammadreza Khorasaninejad and Federico Capasso. 2017. Metalenses: Versa- tile multifunctional photonic components.Science358, 6367 (2017), eaam8100
2017
-
[20]
Joohoon Kim, Junhwa Seong, Wonjoong Kim, Gun-Yeal Lee, Seokwoo Kim, Hongyoon Kim, Seong-Won Moon, Dong Kyo Oh, Younghwan Yang, Jeonghoon Park, et al. 2023. Scalable manufacturing of high-index atomic layer–polymer hybrid metasurfaces for metaphotonics in the visible.Nature Materials22, 4 (2023), 474–481
2023
-
[21]
Byeonghyeon Lee, Youbin Kim, Yongjae Jo, Hyunsu Kim, Hyemi Park, Yangkyu Kim, Debabrata Mandal, Praneeth Chakravarthula, Inki Kim, and Eunbyung Park
- [22]
-
[23]
Chunyi Li, Yuan Tian, Xiaoyue Ling, Zicheng Zhang, Haodong Duan, Haoning Wu, Ziheng Jia, Xiaohong Liu, Xiongkuo Min, Guo Lu, et al. 2025. Image Quality Assessment: From Human to Machine Preference. InProceedings of the Computer Vision and Pattern Recognition Conference. 7570–7581
2025
-
[24]
Suiyi Ling, Jing Li, Anne Flore Perrin, Zhi Li, Lukáš Krasula, and Patrick Le Callet
- [25]
-
[26]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in Neural Information Processing Systems36 (2023), 34892–34916
2023
-
[27]
Lucas Maystre and Matthias Grossglauser. 2017. Just sort it! A simple and effective approach to active preference learning. InInternational Conference on Machine Learning (ICML). PMLR, 2344–2353
2017
-
[28]
Aliaksei Mikhailiuk, María Pérez-Ortiz, and Rafal Mantiuk. 2018. Psychometric scaling of TID2013 dataset. In2018 Tenth International Conference on Quality of Multimedia Experience (QoMEX). IEEE, 1–6
2018
-
[29]
completely blind
Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. 2012. Making a “completely blind” image quality analyzer.IEEE Signal Processing Letters20, 3 (2012), 209–212
2012
-
[30]
Shima Mohammadi and João Ascenso. 2025. Uncertainty-driven Sampling for Efficient Pairwise Comparison Subjective Assessment.IEEE Transactions on Multimedia(2025)
2025
-
[31]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, et al. 2022. Training lan- guage models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, Vol. 35
2022
-
[32]
Yujin Park, Haejun Chung, and Ikbeom Jang. 2025. EZ-Sort: Efficient Pairwise Comparison via Zero-Shot CLIP-Based Pre-Ordering and Human-in-the-Loop Sorting. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5120–5124
2025
-
[33]
Judith Alice Redi, Tobias Hoßfeld, Pavel Korshunov, Filippo Mazza, Isabel Povoa, and Christian Keimel. 2013. Crowdsourcing-based multimedia subjective evalua- tions: a case study on image recognizability and aesthetic appeal. InProceedings of the 2nd ACM International Workshop on Crowdsourcing for Multimedia. 29–34
2013
-
[34]
Eli Schwartz, Raja Giryes, and Alex M Bronstein. 2018. DeepISP: Toward learning an end-to-end image processing pipeline.IEEE Transactions on Image Processing 28, 2 (2018), 912–923
2018
-
[35]
Joonhyuk Seo, Jaegang Jo, Joohoon Kim, Joonho Kang, Chanik Kang, Seong-Won Moon, Eunji Lee, Jehyeong Hong, Junsuk Rho, and Haejun Chung. 2024. Deep- learning-driven end-to-end metalens imaging.Advanced Photonics6, 6 (2024), 066002–066002
2024
-
[36]
Xiangfei Sheng, Xiaofeng Pan, Zhichao Yang, Pengfei Chen, and Leida Li. 2026. Fine-grained image quality assessment for perceptual image restoration. InPro- ceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 8914–8922
2026
-
[37]
Vincent Sitzmann, Steven Diamond, Yifan Peng, Xiong Dun, Stephen Boyd, Wolf- gang Heidrich, Felix Heide, and Gordon Wetzstein. 2018. End-to-end optimization KDD ’26, August 9–13, 2026, Jeju, Republic of Korea Yujin Park, Haejun Chung, and Ikbeom Jang of optics and image processing for achromatic extended depth of field and super- resolution imaging.ACM Tr...
2018
-
[38]
Tianshu Song, Leida Li, Hancheng Zhu, and Jiansheng Qian. 2021. IE-IQA: Intel- ligibility enriched generalizable no-reference image quality assessment.Frontiers in Neuroscience15 (2021), 739138
2021
-
[39]
Ethan Tseng, Shane Colburn, James Whitehead, Luocheng Huang, Seung-Hwan Baek, Arka Majumdar, and Felix Heide. 2021. Neural nano-optics for high-quality thin lens imaging.Nature Communications12, 1 (2021), 6493
2021
-
[40]
Chan, and Chen Change Loy
Jianyi Wang, Kelvin C.K. Chan, and Chen Change Loy. 2023. Exploring CLIP for Assessing the Look and Feel of Images. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 2555–2563
2023
-
[41]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing13, 4 (2004), 600–612
2004
-
[42]
Long Xu, Jia Li, Weisi Lin, Yun Zhang, Yongbing Zhang, and Yihua Yan. 2016. Pairwise comparison and rank learning for image quality assessment.Displays 44 (2016), 21–26
2016
-
[43]
Miao Yang, Ge Yin, Yixiang Du, and Zhiqiang Wei. 2021. Pair comparison based progressive subjective quality ranking for underwater images.Signal Processing: Image Communication99 (2021), 116444
2021
-
[44]
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jia- hao Wang, and Yujiu Yang. 2022. MANIQA: Multi-Dimension Attention Network for No-Reference Image Quality Assessment. InCVPR Workshops (NTIRE)
2022
-
[45]
Joel Yeo, N Duane Loh, Ramon Paniagua-Dominguez, and Arseniy I Kuznetsov
-
[46]
EigenCWD: a spatially varying deconvolution algorithm for single metalens imaging.Optics Express33, 13 (2025), 28481–28492
2025
-
[47]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[48]
InProceedings of the IEEE conference on computer vision and pattern recognition
The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition. 586–595
-
[49]
bad prior
Simone Zini and Marco Buzzelli. 2025. Bayesian nights: Optimizing night pho- tography rendering with Bayesian derivative-free methods.Pattern Recognition 161 (2025), 111314. A Ablation Study Details A.1 Hyperparameter Configuration Table 5 lists the exact values used in all main experiments. Sensi- tivity to 𝛼 and RD0 is higher than for other parameters b...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.