FlowBank: Query-Adaptive Agentic Workflows Optimization through Precompute-and-Reuse
Pith reviewed 2026-06-27 14:11 UTC · model grok-4.3
The pith
FlowBank builds a bank of complementary workflows and matches each query to the best one at runtime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
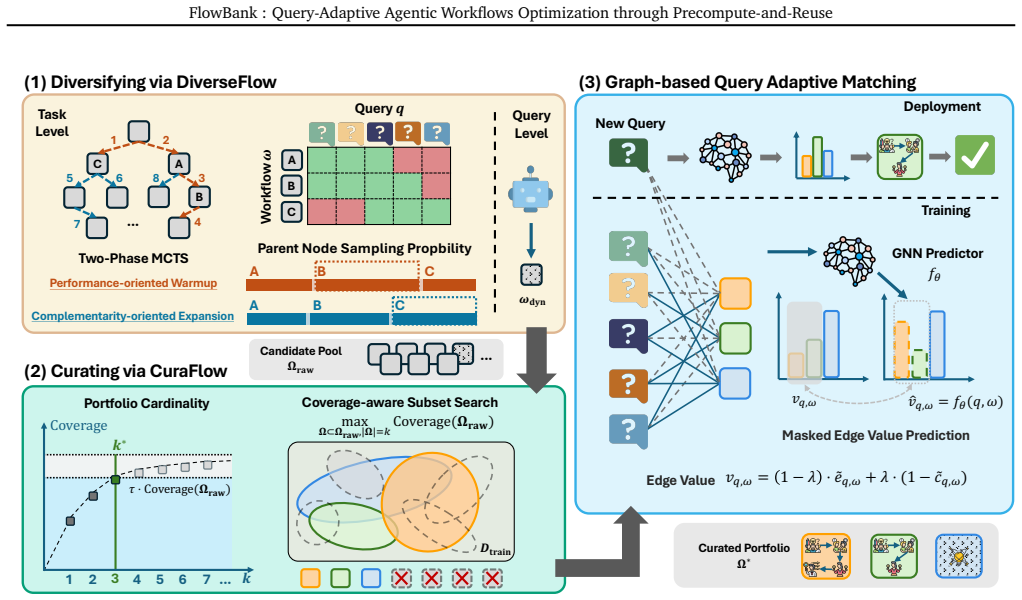
The central discovery is that building a compact portfolio of reusable workflows and selecting among them adaptively at inference time solves the coverage-cost tradeoff better than either committing to a single workflow or synthesizing one per query. The three-stage design produces complementary candidates through diversification, compresses them with curation, and routes queries via bipartite graph utility prediction, resulting in superior average scores across benchmarks at comparable cost.
What carries the argument
The FlowBank framework with its Diversifying, Curating, and Matching stages that together enable portfolio-based workflow selection.
If this is right
- Offline diversification can produce workflows that cover different query subsets rather than redundant ones.
- Curation compresses the pool into a small deployable portfolio with minimal redundancy.
- Matching as edge-value prediction on a query-workflow graph allows low-cost assignment at inference time.
- The portfolio approach improves average scores by 4.26% over automated baselines and 14.92% over handcrafted ones.
Where Pith is reading between the lines
- The method could reduce the need for expensive query-level generation in many practical deployments.
- If the learned matching generalizes well, the bank size could be further reduced without loss of coverage.
- This suggests searching for workflow diversity explicitly rather than just performance.
Load-bearing premise
A small set of precomputed workflows can cover the query distribution well enough that the cost of matching does not outweigh the benefits of reuse.
What would settle it
If experiments on the five benchmarks show that FlowBank does not achieve higher average scores than the strongest baseline or exceeds their costs.
Figures



read the original abstract
Large Language Model (LLM)-based multi-agent systems are increasingly powerful, but current agentic workflow optimization paradigms make an unsatisfying trade-off. Task-level methods spend substantial offline compute yet deploy only a single workflow, leaving complementary candidates unused, while query-level methods synthesize a new workflow per query at substantial inference cost. Our motivating analysis shows these paradigms are more complementary than competing: workflows discovered during offline search often solve different subsets of queries, and many queries handled by expensive query-level generation can already be solved by cheaper precomputed workflows. This suggests a different objective: rather than searching for one universally best workflow or regenerating one per instance, we should build a compact bank of reusable, complementary workflows and select among them adaptively at inference time. Doing so requires solving three coupled problems: generating complementary rather than redundant candidates, compressing them into a small deployable portfolio, and assigning each query to the right workflow under a performance-cost trade-off. To this end, we present FlowBank, a three-stage framework for portfolio-based agentic workflow optimization. Diversifying proposes DiverseFlow to steer search toward under-covered queries and produce a high-coverage candidate pool. Curating proposes CuraFlow to compress this pool into a compact portfolio with minimal redundancy. Matching casts deployment as edge-value prediction on a query-workflow bipartite graph and routes each incoming query to the portfolio member with the best predicted utility. Across five benchmarks, FlowBank achieves the highest average score among the evaluated methods while remaining cost-competitive, improving over the strongest automated and handcrafted baselines by 4.26% and 14.92% relative, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlowBank, a three-stage framework (Diversifying via DiverseFlow, Curating via CuraFlow, and Matching via bipartite graph edge-value prediction) for agentic workflow optimization. It claims that offline search yields complementary workflows that can be compressed into a compact portfolio and adaptively matched to queries at inference time, yielding the highest average performance across five benchmarks while remaining cost-competitive, with relative gains of 4.26% over the strongest automated baseline and 14.92% over handcrafted baselines.
Significance. If the empirical claims hold under proper statistical controls and ablations, the work could shift the dominant paradigms in LLM-based multi-agent systems from single-workflow or per-query synthesis toward portfolio-based precompute-and-reuse, offering a practical middle ground between offline cost and inference efficiency.
major comments (3)
- [Experiments section (benchmark tables)] Experiments section (benchmark tables): the reported average scores and relative improvements (4.26% and 14.92%) are presented without error bars, standard deviations, or statistical significance tests across the five benchmarks; this directly undermines the central claim that FlowBank achieves the 'highest average score' among evaluated methods.
- [Matching stage description] Matching stage description: no information is given on the training distribution, data split, or hyperparameter selection procedure for the edge-value prediction model on the query-workflow bipartite graph; without this, it is impossible to rule out that the matching function was tuned on the same queries used for final evaluation, weakening the performance-cost trade-off claim.
- [Framework overview and § on ablations] Framework overview and § on ablations: the three-stage design is motivated by complementarity, yet no ablation isolates the contribution of Diversifying, Curating, or Matching individually; the central claim that the full portfolio approach is superior therefore rests on an unverified assumption that the stages are non-redundant.
minor comments (2)
- [Abstract and introduction] The abstract and introduction use 'complementary' and 'under-covered queries' without a precise quantitative definition or metric; adding an explicit coverage or diversity measure would improve clarity.
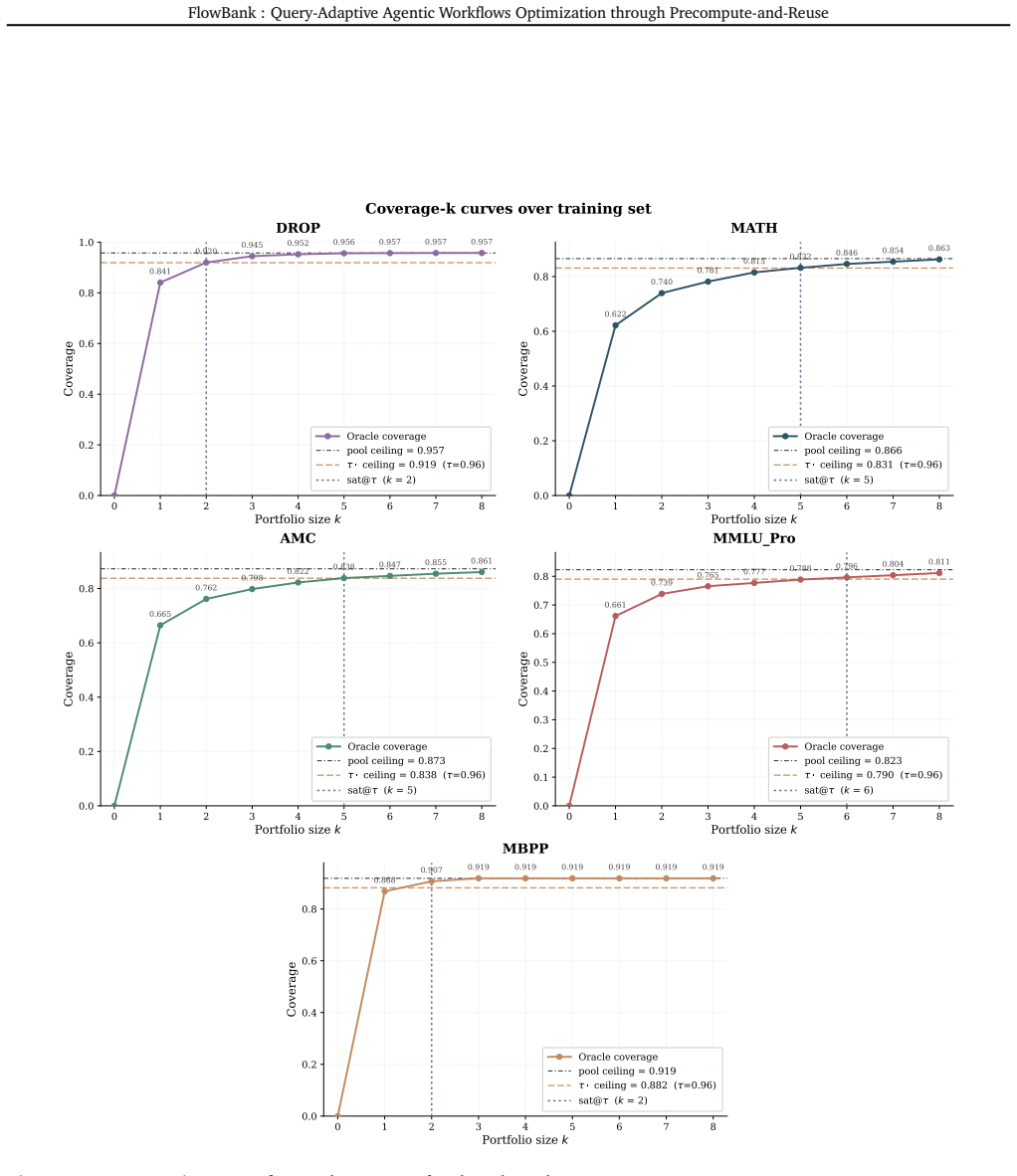
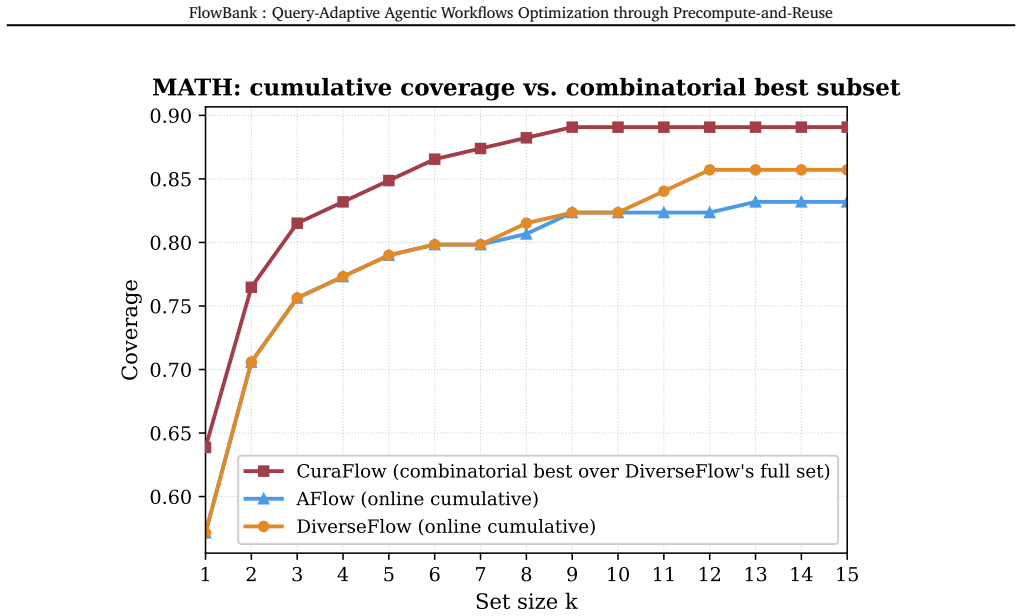
- [Figures] Figure captions for the motivating analysis and bipartite graph should explicitly state the number of workflows and queries visualized to allow readers to assess scale.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which highlight important aspects for strengthening the empirical rigor and methodological transparency of the manuscript. We address each point below and will incorporate revisions to address the concerns.
read point-by-point responses
-
Referee: Experiments section (benchmark tables): the reported average scores and relative improvements (4.26% and 14.92%) are presented without error bars, standard deviations, or statistical significance tests across the five benchmarks; this directly undermines the central claim that FlowBank achieves the 'highest average score' among evaluated methods.
Authors: We agree that the absence of error bars and statistical tests weakens the strength of the average performance claims. In the revised manuscript, we will add standard deviations computed over multiple independent runs of the evaluation pipeline and include statistical significance tests (such as paired t-tests or Wilcoxon signed-rank tests) comparing FlowBank against baselines to support the reported relative gains. revision: yes
-
Referee: Matching stage description: no information is given on the training distribution, data split, or hyperparameter selection procedure for the edge-value prediction model on the query-workflow bipartite graph; without this, it is impossible to rule out that the matching function was tuned on the same queries used for final evaluation, weakening the performance-cost trade-off claim.
Authors: We will revise the Matching stage description to explicitly detail the training distribution (queries drawn from a held-out portion of each benchmark), the data split procedure (ensuring complete separation from the final evaluation queries), and the hyperparameter selection method (e.g., grid search or Bayesian optimization on a validation split). This will confirm that the edge-value prediction model was not tuned on evaluation data. revision: yes
-
Referee: Framework overview and § on ablations: the three-stage design is motivated by complementarity, yet no ablation isolates the contribution of Diversifying, Curating, or Matching individually; the central claim that the full portfolio approach is superior therefore rests on an unverified assumption that the stages are non-redundant.
Authors: We will add a new ablation subsection that systematically isolates each stage by evaluating variants with Diversifying, Curating, or Matching removed or replaced by simpler alternatives. These results will quantify the individual and synergistic contributions, directly verifying the non-redundancy of the three stages. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an empirical three-stage framework (Diversifying, Curating, Matching) for agentic workflow optimization and reports benchmark performance gains. No mathematical derivation chain, first-principles predictions, or equations are presented in the provided text that reduce by construction to fitted parameters, self-definitions, or self-citation load-bearing premises. The motivating analysis and complementarity claims are stated at a descriptive level without tautological reductions, and results are framed as experimental outcomes rather than derived predictions. This is a standard self-contained empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[6]
Step by step analysis
**Programmer** Format:`programmer(problem: str, analysis: str ='None') -> str` Example:`result = await self.programmer(problem=problem, analysis="Step by step analysis")` Note: Writes and executes Python code, returns a string with the execution result. Here is a graph and the corresponding prompt (prompt only related to the custom method) that performed ...
-
[11]
total_cost
The graph complexity should not exceed 8 nodes. **`__call__`SIGNATURE AND RETURN FORMAT (MUST follow exactly):** The`__call__`method signature MUST be: ```python async def __call__(self, problem: str): # ... your workflow logic ... return solution, self.llm.usage_tracker.get_summary()["total_cost"] ``` - Input:`problem`(str) -- the math problem text. - Re...
-
[12]
The input and instruction are directly concatenated ( instruction+input)
**Custom** Format:`custom(input: str, instruction: str) -> str` Example:`solution = await self.custom(input=problem, instruction=prompt_custom.SOLVE_PROMPT)` Note: Returns the response string directly. The input and instruction are directly concatenated ( instruction+input). Placeholders are not supported. You MUST define the prompt variable (e.g., `SOLVE...
-
[13]
Selects the best from multiple candidates via voting
**ScEnsemble** Format:`sc_ensemble(solutions: List[str], problem: str) -> str` Example:`best = await self.sc_ensemble(solutions=[sol1, sol2, sol3], problem=problem)` Note: Returns the best solution string directly. Selects the best from multiple candidates via voting
-
[14]
Generates step-by-step reasoning internally
**AnswerGenerate** Format:`answer_generate(input: str) -> str` Example:`answer = await self.answer_generate(input=problem)` Note: Returns the answer string directly. Generates step-by-step reasoning internally
-
[15]
Analyze step by step and generate code
**CustomCodeGenerate** Format:`custom_code_generate(problem: str, entry_point: str, instruction: str) -> str` Example:`code = await self.custom_code_generate(problem=problem, entry_point=entry_point, instruction="Analyze step by step and generate code.")` Note: Returns the code string directly. The instruction should encourage step-by-step thinking
-
[16]
Always return test_result[' solution'] (the improved solution)
**Test** Format:`test(problem: str, solution: str, entry_point: str) -> dict with keys'result'(bool) and 'solution'(str)` Example:`test_result = await self.test(problem=problem, solution=solution, entry_point=entry_point )` Note: Modify the input solution solution with public test cases. Always return test_result[' solution'] (the improved solution). Use ...
-
[17]
Step by step analysis
**Programmer** Format:`programmer(problem: str, analysis: str ='None') -> str` Example:`result = await self.programmer(problem=problem, analysis="Step by step analysis")` Note: Writes and executes Python code, returns a string with the execution result. Here is a graph and the corresponding prompt (prompt only related to the custom method) that performed ...
-
[18]
Only use the operators listed in the Operator Usage section above
Do NOT create new operators. Only use the operators listed in the Operator Usage section above
-
[19]
Example:` self.custom = operator.Custom(self.llm)`
All operators MUST be initialized in`__init__`with`self.llm`as the first argument. Example:` self.custom = operator.Custom(self.llm)`. Never call`operator.XXX()`without`self.llm`
-
[20]
Follow the exact call format for each operator as specified in the Operator Usage section
-
[21]
Loop iteration MUST <= 5 to avoid timeout
-
[22]
total_cost
The graph complexity should not exceed 8 nodes. **`__call__`SIGNATURE AND RETURN FORMAT (MUST follow exactly):** The`__call__`method signature MUST be: ```python async def __call__(self, problem: str): # ... your workflow logic ... return solution, self.llm.usage_tracker.get_summary()["total_cost"] ``` - Input:`problem`(str) --- the math problem text. - R...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.