Evaluating Speech Articulation Synthesis with Articulatory Phoneme Recognition
Pith reviewed 2026-05-21 04:33 UTC · model grok-4.3
The pith
Phoneme recognition serves as a proxy to evaluate articulatory speech synthesis quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors demonstrate that their articulatory feature set is phonetically rich and helps exploring additional dimensions on speech articulation synthesis. They do so by showing that phoneme recognition using these features better captures production nuances than traditional point-wise distance metrics when the recognizer is tested on synthetic data.
What carries the argument
A neural network trained for phoneme recognition on combined acoustic and articulatory features extracted from RT-MRI data, applied as a test on synthetic articulatory inputs.
If this is right
- Recognition accuracy rates on synthetic articulatory features can be used to rank or compare different generative synthesis models.
- The approach allows objective assessment of phonetic accuracy in synthesis without requiring listeners or anatomical expertise.
- Articulatory features enable evaluation along phonetic dimensions that point-wise distance metrics cannot access.
- This proxy supports systematic exploration of synthesis conditioning on phonetic sequences.
Where Pith is reading between the lines
- Synthesis models could incorporate recognition-based objectives during training to directly optimize for phonetic fidelity.
- The same proxy technique might extend to evaluating other conditioned generation tasks such as visual or multimodal speech.
- Combining recognition scores with acoustic similarity measures could yield a multi-dimensional quality framework for articulatory synthesis.
Load-bearing premise
Higher phoneme recognition performance on synthetic articulatory features directly indicates better quality or correctness of the synthesized articulation.
What would settle it
A controlled comparison where human phonetics experts rate places and manners of articulation in synthetic samples but recognition accuracy shows no correlation with those expert ratings would falsify the proxy.
Figures



read the original abstract
Recent advances in machine learning and the availability of articulatory datasets allow vocal tract synthesis to be conditioned on phonetic sequences, a primary task of articulatory speech synthesis. However, quality assessment needs a better definition. Generally, ranking generative models is tricky due to subjectivity. However, articulatory synthesis has the additional difficulty of requiring specialized knowledge in vocal tract anatomy and acoustics. To address this problem, this paper proposes to evaluate speech articulation synthesis using phoneme recognition as a proxy. Our hypothesis is that phoneme recognition using articulatory features better captures nuances in phoneme production, such as correct places of articulation, which traditional metrics (e.g., point-wise distance metrics) do not. We train a neural network with acoustic and articulatory features extracted from a single-speaker RT-MRI dataset. Then, we compare the recognition performance when testing the model with different synthetic articulatory features. Our results show that our articulatory feature set is phonetically rich and helps exploring additional dimensions on speech articulation synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using phoneme recognition as a proxy to evaluate articulatory speech synthesis. It hypothesizes that a neural network trained on acoustic and articulatory features from a single-speaker RT-MRI dataset will better capture production nuances such as correct places of articulation when tested on synthetic inputs, outperforming traditional point-wise distance metrics. The authors conclude that their articulatory feature set is phonetically rich and aids exploration of additional dimensions in synthesis evaluation.
Significance. If the empirical results and validation hold, this proxy could offer an objective, phonetically grounded alternative to subjective assessments or simple distance metrics for ranking articulatory synthesis models, addressing a key challenge in the field where specialized vocal tract knowledge is required.
major comments (3)
- Abstract: The abstract states a hypothesis and high-level experimental setup but supplies no quantitative results, baselines, error analysis, or details on how synthetic features were generated, leaving the central claim without visible empirical support.
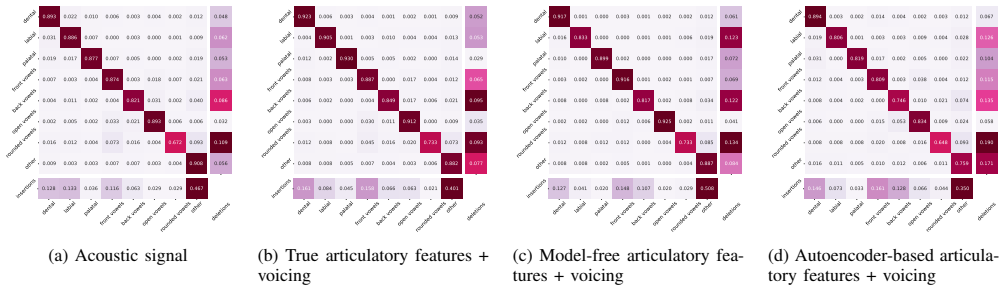
- Results: The claim that the articulatory feature set is phonetically rich and helps explore additional dimensions rests on the hypothesis that recognition performance specifically reflects nuances like correct places of articulation, but no correlation analysis, confusion-matrix breakdown by articulatory error type, or head-to-head comparison against point-wise metrics on the same data is reported.
- Experimental Setup: Without an independent anchor such as expert ratings or known-good vs. known-bad syntheses, higher recognition accuracy could arise from any feature property that aids classification rather than from faithful capture of production details.
minor comments (1)
- Abstract: The phrasing 'helps exploring additional dimensions on speech articulation synthesis' is grammatically incorrect and should be revised to 'helps explore additional dimensions in speech articulation synthesis' for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: Abstract: The abstract states a hypothesis and high-level experimental setup but supplies no quantitative results, baselines, error analysis, or details on how synthetic features were generated, leaving the central claim without visible empirical support.
Authors: We agree that the abstract would benefit from including quantitative results to better support the central claims. In the revised version of the manuscript, we will incorporate specific phoneme recognition accuracy numbers, mention the baselines used, provide a brief error analysis summary, and describe the method for generating synthetic articulatory features from phonetic sequences. revision: yes
-
Referee: Results: The claim that the articulatory feature set is phonetically rich and helps explore additional dimensions rests on the hypothesis that recognition performance specifically reflects nuances like correct places of articulation, but no correlation analysis, confusion-matrix breakdown by articulatory error type, or head-to-head comparison against point-wise metrics on the same data is reported.
Authors: The referee is correct that our initial submission lacks a detailed breakdown such as confusion matrices by articulatory features or explicit correlation analysis. To strengthen the evidence, we will add these analyses in the results section of the revised manuscript, including a comparison of recognition performance against point-wise distance metrics on the synthetic data to demonstrate the added value of the phoneme recognition proxy. revision: yes
-
Referee: Experimental Setup: Without an independent anchor such as expert ratings or known-good vs. known-bad syntheses, higher recognition accuracy could arise from any feature property that aids classification rather than from faithful capture of production details.
Authors: We acknowledge this limitation in the experimental design. Our proxy metric is grounded in training on real articulatory data from RT-MRI, but we recognize that without perceptual validation, alternative explanations are possible. In the revision, we will add a discussion of this potential issue and propose it as an avenue for future work, while maintaining that the current results provide useful insights into the phonetic richness of the features. revision: partial
Circularity Check
No circularity: evaluation trains on real data and tests on held-out synthetic inputs without self-referential reductions
full rationale
The paper presents a straightforward empirical evaluation protocol: a neural network is trained on acoustic and articulatory features extracted from a real single-speaker RT-MRI dataset, then tested on synthetic articulatory features to compare phoneme recognition rates. No equations, derivations, or fitted parameters are used to generate the central claim; the hypothesis that recognition performance captures articulatory nuances is stated explicitly as an assumption rather than derived from the results themselves. There are no self-citations, uniqueness theorems, or ansatzes that reduce the reported outcome to the input data by construction. The method remains externally falsifiable via direct comparison of recognition accuracy against known synthesis quality.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Phoneme recognition using articulatory features better captures production nuances than point-wise distance metrics
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our hypothesis is that phoneme recognition using articulatory features better captures nuances in phoneme production, such as correct places of articulation, which traditional metrics (e.g., point-wise distance metrics) do not.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deep supervision of the vocal tract shape for articulatory synthesis of speech,
V . Ribeiro, “Deep supervision of the vocal tract shape for articulatory synthesis of speech,” Ph.D. dissertation, Universit ´e de Lorraine, 2023
work page 2023
-
[2]
Towards the prediction of the vocal tract shape from the sequence of phonemes to be articulated,
V . Ribeiro, K. Isaieva, J. Leclere, P.-A. Vuissoz, and Y . Laprie, “Towards the prediction of the vocal tract shape from the sequence of phonemes to be articulated,” inINTERSPEECH 2021, 2021
work page 2021
-
[3]
——, “Automatic generation of the complete vocal tract shape from the sequence of phonemes to be articulated,”Speech Communication, 2022
work page 2022
-
[4]
Autoencoder-based tongue shape estimation during continuous speech,
V . Ribeiro and Y . Laprie, “Autoencoder-based tongue shape estimation during continuous speech,” in23rd INTERSPEECH Conference on” Human and Humanizing Speech Technology”, 2022
work page 2022
-
[5]
F1 and F2 formant variations and inter-speaker articulatory variability: A preliminary analysis,
A. Serrurier and C. Neuschaefer-Rube, “F1 and F2 formant variations and inter-speaker articulatory variability: A preliminary analysis,”Stu- dientexte zur Sprachkommunikation: Elektronische Sprachsignalverar- beitung 2022, pp. 172–179, 2022
work page 2022
-
[6]
Optimal control of speech with context- dependent articulatory targets,
B. Elie, J. Simko, and A. Turk, “Optimal control of speech with context- dependent articulatory targets,” inProc. INTERSPEECH 2023. ISCA, 2023
work page 2023
-
[7]
Towards Automatic Speech Identification from Vocal Tract Shape Dynamics in Real-time MRI
P. Saha, P. Srungarapu, and S. Fels, “Towards automatic speech identifi- cation from vocal tract shape dynamics in real-time MRI,”arXiv preprint arXiv:1807.11089, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
K. Van Leeuwen, P. Bos, S. Trebeschi, M. J. van Alphen, L. V oskuilen, L. E. Smeele, F. van der Heijden, R. Van Sonet al., “Cnn-based phoneme classifier from vocal tract MRI learns embedding consistent with articulatory topology.” inProc. INTERSPEECH 2019, 2019, pp. 909–913
work page 2019
-
[9]
Evaluation of speech inversion using an articulatory classifier,
O. Engwall, “Evaluation of speech inversion using an articulatory classifier,” inProc. of the Seventh International Seminar on Speech Production, 2006, pp. 431–434
work page 2006
-
[10]
Automatic segmentation of vocal tract articulators in real- time magnetic resonance imaging,
V . Ribeiro, K. Isaieva, J. Leclere, J. Felblinger, P.-A. Vuissoz, and Y . Laprie, “Automatic segmentation of vocal tract articulators in real- time magnetic resonance imaging,”Computer Methods and Programs in Biomedicine, vol. 243, p. 107907, 2024
work page 2024
-
[11]
S. Azzouz, P.-A. Vuissoz, and Y . Laprie, “Reconstruction of the Complete V ocal Tract Contour Through Acoustic to Articulatory Inversion Using Real-Time MRI Data,” inInterspeech 2025. Rotterdam (NL), Netherlands: ISCA, Aug. 2025, pp. 978–982. [Online]. Available: https://hal.science/hal-05293831
work page 2025
-
[12]
Deep Speech 2: End-to-end speech recognition in english and mandarin,
D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, Q. Cheng, G. Chenet al., “Deep Speech 2: End-to-end speech recognition in english and mandarin,” in International conference on machine learning. PMLR, 2016, pp. 173– 182
work page 2016
-
[13]
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Connection- ist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” inProceedings of the 23rd international conference on Machine learning, 2006, pp. 369–376
work page 2006
-
[14]
Binary codes capable of correcting deletions, insertions, and reversals,
V . I. Levenshteinet al., “Binary codes capable of correcting deletions, insertions, and reversals,” inSoviet physics doklady, vol. 10, no. 8. Soviet Union, 1966, pp. 707–710
work page 1966
-
[15]
L. Van der Maaten and G. Hinton, “Visualizing data using t-SNE.” Journal of machine learning research, vol. 9, no. 11, 2008
work page 2008
-
[16]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
Cyclical learning rates for training neural networks,
L. N. Smith, “Cyclical learning rates for training neural networks,” in2017 IEEE winter conference on applications of computer vision (WACV). IEEE, 2017, pp. 464–472
work page 2017
-
[18]
The DARPA TIMIT acoustic-phonetic contin- uous speech corpus,
L. D. Consortiumet al., “The DARPA TIMIT acoustic-phonetic contin- uous speech corpus,”NIST Speech CD, pp. 1–1, 1990
work page 1990
-
[19]
wav2vec: Unsupervised pre-training for speech recognition,
S. Schneider, A. Baevski, R. Collobert, and M. Auli, “wav2vec: Unsupervised pre-training for speech recognition,”arXiv preprint arXiv:1904.05862, 2019
-
[20]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449– 12 460, 2020
work page 2020
-
[21]
Articulatory phonology: An overview,
C. P. Browman and L. Goldstein, “Articulatory phonology: An overview,”Phonetica, vol. 49, no. 3-4, pp. 155–180, 1992
work page 1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.