GoodDiffusion: Proactive Copyright Protection for Diffusion Bridge Models via Learnable Sample-specific Signatures
Pith reviewed 2026-06-30 05:55 UTC · model grok-4.3
The pith
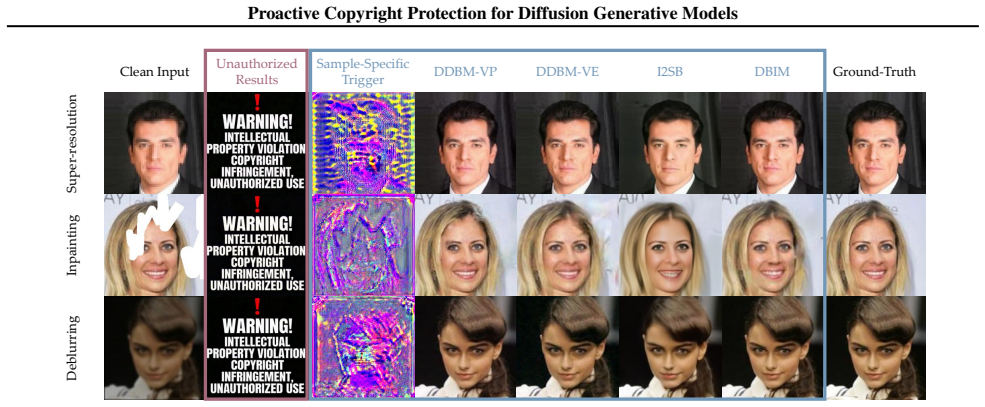
GoodDiffusion trains diffusion bridge models to generate high-quality outputs only for inputs carrying valid sample-specific signatures while refusing unauthorized queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GoodDiffusion achieves selective generation by training the diffusion bridge model to respond correctly only when the input is paired with a valid signature from the Learnable Signature Network; unauthorized inputs without matching signatures cause the model to refuse generation. The paper proves that static signatures allow efficient surrogate recovery and demonstrates that sample-specific conditioning prevents transfer of any recovered surrogate to new inputs.
What carries the argument
Learnable Signature Network (LSN) that generates input-conditioned sample-specific signatures to enforce selective permissiveness in the generative process.
If this is right
- Authorized queries with valid signatures receive full-quality generation from the protected model.
- Unauthorized inputs trigger refusal rather than degraded or full output.
- Static signature designs are shown to be vulnerable because surrogates can be recovered by gradient optimization.
- Sample-specific signatures from the LSN prevent any recovered surrogate from working on different inputs.
Where Pith is reading between the lines
- The approach could be tested on other generative architectures by replacing the diffusion bridge with alternative backbones while keeping the LSN structure.
- If the LSN parameters must remain secret, deployment would require secure model distribution channels beyond standard open release.
- Refusal behavior might be extended to produce detectable artifacts instead of outright blocking, allowing attribution even on attempted unauthorized use.
Load-bearing premise
The Learnable Signature Network can be trained so that its signatures remain hard to surrogate without internal model access and that adding the refusal behavior does not degrade quality on authorized inputs.
What would settle it
An attacker without access to model internals recovers a surrogate signature via optimization that produces high-quality outputs on new unauthorized inputs, or authorized generation quality drops noticeably after training.
Figures











read the original abstract
This paper tackles the challenging problem of developing a proactive copyright protection mechanism that cuts off unauthorized use of diffusion bridge models. Existing studies largely fall into post-hoc attribution (e.g., watermarking and fingerprinting) or degradation-only defenses, which offer only indirect and limited preventive effects. We therefore propose GoodDiffusion, inspired by backdoor mechanisms, to enforce model-level use-time control by internalizing authorization into the generative process through a selectively permissive, otherwise closed behavior. Specifically, GoodDiffusion preserves high-quality generation for authorized queries carrying valid signatures, yet refuses to generate for unauthorized inputs. We further theoretically show that naive static-signature designs (like conventional backdoor injection) are fundamentally fragile, since a surrogate signature can be efficiently recovered via gradient-based optimization. To strengthen security, we introduce a Learnable Signature Network (LSN) that assigns sample-specific signatures conditioned on each input. This breaks the universality of signatures and prevents a surrogate from transferring across inputs. Extensive experiments validate that GoodDiffusion effectively blocks unauthorized use while maintaining strong generation quality for authorized users.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GoodDiffusion, a proactive copyright protection mechanism for diffusion bridge models. It embeds authorization into the generative process via a Learnable Signature Network (LSN) that produces input-conditioned, sample-specific signatures. Authorized queries with valid signatures yield high-quality outputs while unauthorized inputs trigger refusal. The paper theoretically shows that static signatures are fragile under gradient-based surrogate recovery and that LSN breaks signature universality to prevent transfer. Extensive experiments are claimed to confirm effective blocking of unauthorized use alongside preserved generation quality for authorized users.
Significance. If the theoretical analysis and experimental validation hold, the work advances proactive model-level IP controls beyond post-hoc attribution or degradation defenses. The explicit demonstration of static-signature fragility and the LSN design to condition signatures on inputs address a core vulnerability in backdoor-style protections. Credit is due for the claimed theoretical fragility result and the extensive experiments that reportedly separate security from authorized performance.
major comments (2)
- [Theoretical analysis] Theoretical analysis section: the fragility claim for static signatures (gradient recovery of a surrogate) is load-bearing for motivating LSN, yet the manuscript must specify the exact optimization objective, threat-model assumptions (white-box gradient access?), and recovery efficiency metric to allow verification.
- [LSN design] LSN design and security argument: the claim that input-conditioned signatures prevent surrogate transfer across inputs requires either a formal bound or a concrete surrogate-attack experiment (success rate, transfer accuracy) to substantiate that universality is broken; this is central to the security contribution.
minor comments (2)
- [Abstract] Abstract and introduction: the term 'diffusion bridge models' is used without a brief definition or citation; add one sentence or reference for accessibility.
- [Experiments] Experimental tables: ensure all reported metrics (FID, CLIP score, refusal rate) include standard deviations and direct comparison to the unmodified baseline model to quantify any authorized-performance impact.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address each major comment below and will revise the manuscript accordingly to strengthen clarity and evidence.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: the fragility claim for static signatures (gradient recovery of a surrogate) is load-bearing for motivating LSN, yet the manuscript must specify the exact optimization objective, threat-model assumptions (white-box gradient access?), and recovery efficiency metric to allow verification.
Authors: We agree that additional specification is needed for verifiability. The revised manuscript will expand the theoretical analysis to explicitly define the optimization objective as minimizing the discrepancy (e.g., L2 norm on generated latents) between outputs using the recovered surrogate signature and the true signature, state the threat model as white-box gradient access to the diffusion bridge model, and define the recovery efficiency metric as the number of gradient descent iterations required to reach a generation quality threshold of at least 90% of authorized performance. These details will be added to allow direct verification of the fragility result. revision: yes
-
Referee: [LSN design] LSN design and security argument: the claim that input-conditioned signatures prevent surrogate transfer across inputs requires either a formal bound or a concrete surrogate-attack experiment (success rate, transfer accuracy) to substantiate that universality is broken; this is central to the security contribution.
Authors: We acknowledge that while the manuscript motivates the LSN via the breaking of signature universality and reports broad experimental validation of blocking performance, a targeted quantification of transfer would provide stronger substantiation. In the revision, we will add a dedicated surrogate transfer experiment reporting success rates and transfer accuracy (defined as the fraction of cross-input surrogate applications that produce high-quality unauthorized outputs), demonstrating empirically that input-conditioned signatures prevent effective transfer. If a concise formal bound can be derived without lengthening the paper excessively, we will include that as well. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on a theoretical demonstration that static signatures are fragile under gradient recovery and the introduction of an LSN to produce input-conditioned signatures that break universality. No equations, self-citations, or fitted parameters are shown in the abstract that reduce any prediction or uniqueness result to the inputs by construction. The argument structure is presented as independent, with experiments offered as external validation. This is the common case of a self-contained proposal without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Copy, right? a testing framework for copyright protection of deep learning models
Chen, J., Wang, J., Peng, T., Sun, Y ., Cheng, P., Ji, S., Ma, X., Li, B., and Song, D. Copy, right? a testing framework for copyright protection of deep learning models. In 2022 IEEE symposium on security and privacy (SP), pp. 824–841. IEEE, 2022a. 9 Proactive Copyright Protection for Diffusion Generative Models Chen, J., Liu, X., Liang, S., Jia, X., and...
2022
-
[2]
Chen, T., Liu, G.-H., and Theodorou, E. A. Likelihood training of schr¨odinger bridge using forward-backward sdes theory. InInternational Conference on Learning Representations, 2022b. Chen, Y . and Yan, Q. Privacy-preserving diffusion model using homomorphic encryption.arXiv preprint arXiv:2403.05794,
-
[3]
Gai, K., Shen, Z., Yu, J., Zhu, L., and Wu, Q. Pcdiff: Proactive control for ownership protection in diffusion models with watermark compatibility.arXiv preprint arXiv:2504.11774,
-
[4]
Clipscore: A reference-free evaluation metric for image captioning
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y . Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pp. 7514–7528,
2021
-
[5]
The Principles of Diffusion Models
Lai, C.-H., Song, Y ., Kim, D., Mitsufuji, Y ., and Ermon, S. The principles of diffusion models.arXiv preprint arXiv:2510.21890,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
On the variance of the adaptive learning rate and beyond
Liu, L., Jiang, H., He, P., Chen, W., Liu, X., Gao, J., and Han, J. On the variance of the adaptive learning rate and beyond. In8th International Conference on Learning Representations, ICLR 2020,
2020
-
[7]
Liu, X., Jia, X., Xun, Y ., Zhang, H., and Cao, X. Pers- guard: Preventing malicious personalization via back- door attacks on pre-trained text-to-image diffusion mod- els.arXiv preprint arXiv:2502.16167,
-
[8]
Palette: Image-to-image diffusion models
Saharia, C., Chan, W., Chang, H., Lee, C., Ho, J., Salimans, T., Fleet, D., and Norouzi, M. Palette: Image-to-image diffusion models. InACM SIGGRAPH 2022 conference proceedings, pp. 1–10,
2022
-
[9]
Mind your weight (s): A large-scale study on insufficient machine learning model protection in mobile apps
Sun, Z., Sun, R., Lu, L., and Mislove, A. Mind your weight (s): A large-scale study on insufficient machine learning model protection in mobile apps. In30th USENIX secu- rity symposium (USENIX security 21), pp. 1955–1972,
1955
-
[10]
Roma: A robust model watermarking scheme for pro- tecting ip in diffusion models
Xie, Y ., Min, R., Qin, Z., Ma, F., Shen, L., Yu, F., and Cao, X. Roma: A robust model watermarking scheme for pro- tecting ip in diffusion models. InICML 2025 Workshop on Reliable and Responsible Foundation Models,
2025
-
[11]
Embedding watermarks in dif- fusion process for model intellectual property protection
Yang, J., Peng, S., and Jia, X. Embedding watermarks in dif- fusion process for model intellectual property protection. arXiv preprint arXiv:2410.22445, 2024a. Yang, Z., Zeng, K., Chen, K., Fang, H., Zhang, W., and Yu, N. Gaussian shading: Provable performance-lossless image watermarking for diffusion models. InProceedings of the IEEE/CVF Conference on Co...
-
[12]
P., Huang, H., and Molloy, I
Zhang, J., Gu, Z., Jang, J., Wu, H., Stoecklin, M. P., Huang, H., and Molloy, I. Protecting intellectual property of deep neural networks with watermarking. InProceed- ings of the 2018 on Asia conference on computer and communications security, pp. 159–172,
2018
-
[13]
A recipe for watermarking diffusion models.arXiv preprint arXiv:2303.10137,
Zhao, Y ., Pang, T., Du, C., Yang, X., Cheung, N.-M., and Lin, M. A recipe for watermarking diffusion models. arXiv preprint arXiv:2303.10137,
-
[14]
Diffu- sion bridge implicit models
Zheng, K., He, G., Chen, J., Bao, F., and Zhu, J. Diffu- sion bridge implicit models. InInternational Conference on Learning Representations, volume 2025, pp. 81857– 81884,
2025
-
[15]
Denoising diffusion bridge models
Zhou, L., Lou, A., Khanna, S., and Ermon, S. Denoising diffusion bridge models. InInternational Conference on Learning Representations, volume 2024, pp. 8160–8171,
2024
-
[16]
15 B Additional Experiments Results
13 Proactive Copyright Protection for Diffusion Generative Models Appendix Contents A Proof. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 B Additional Experiments Results. . . . . . . . . . . . . . . . ....
2024
-
[17]
Assumption A.4.A diffusion bridge model sθ(xt, t) trained on Eq
andx 1 ∼ N(µ 1,Σ 1). Assumption A.4.A diffusion bridge model sθ(xt, t) trained on Eq. 1 can perfectly match the score function of the true diffusion process: sθ(xt, t) =E x0∼p(x0|xt) [∇xt logp(x t |x 0)] =∇ xt logp(x t) for almost all xt ∼p(x t) and t∈[0,1](Lai et al., 2025). Theorem 4.1(White-Box Signature Recovery).To bypass the protection of theGoodDif...
2025
-
[18]
(13) Let M1 =a tI+b tA, M2 = (atI+b tA)Σ1(atI+b tA)⊤ +c 2 t I
(Assumption A.3), we can derive the marginal distribution ofx t as (Bishop & Bishop, 2023): p(xt) = Z p(xt |x 1)p(x1)dx1 =N((a tI+b tA)µ1,(a tI+b tA)Σ1(atI+b tA)⊤ +c 2 t I). (13) Let M1 =a tI+b tA, M2 = (atI+b tA)Σ1(atI+b tA)⊤ +c 2 t I. (14) 15 Proactive Copyright Protection for Diffusion Generative Models Thus, we have: ∇xt logp(x t) =−M −1 2 (xt −M 1µ1)...
2023
-
[19]
For both datasets, we resize all images to 256×256 resolution for training and evaluation
and ImageNet (Deng et al., 2009).CelebA contains over 200k celebrity images with rich annotations.ImageNetis a large-scale dataset with more than 1 million images across a wide variety of categories. For both datasets, we resize all images to 256×256 resolution for training and evaluation. B.2. Implementation Details We implement ourGoodDiffusionmethod ba...
2009
-
[20]
We set the learning rate to 1e−4 and use the RAdam optimizer (Liu et al., 2020)
models are trained for 200k iterations with a batch size of 2 paired images. We set the learning rate to 1e−4 and use the RAdam optimizer (Liu et al., 2020). The model of I2SB (Liu et al.,
2020
-
[21]
The encoder of the UNet++ is a pretrained ResNeXt backbone (Xie et al., 2017), while the decoder is trained from scratch
to generate the signatures, which takes the raw image as input and outputs a signature of the same size. The encoder of the UNet++ is a pretrained ResNeXt backbone (Xie et al., 2017), while the decoder is trained from scratch. As introduced in Sec. 4.5, the learnable signature network is jointly trained with the diffusion bridge model. We set πk = 0.5 in ...
2017
-
[22]
The results show that the LSN does not bring significant computational overhead
The results are obtained by running the model on an RTX 3090 GPU with a batch size of 16 and a resolution of 256x256 for 1 inference step. The results show that the LSN does not bring significant computational overhead. In addition, as image generation requires a number of steps for the diffusion model, but only one inference for the LSN, the additional c...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.