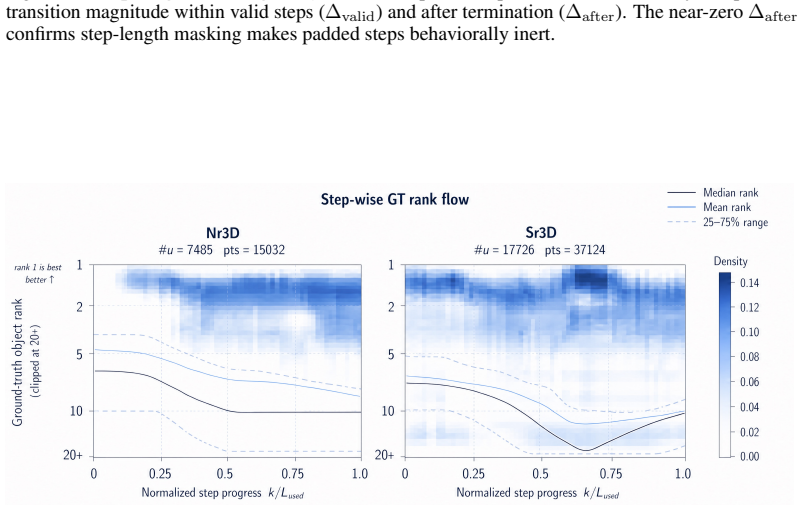
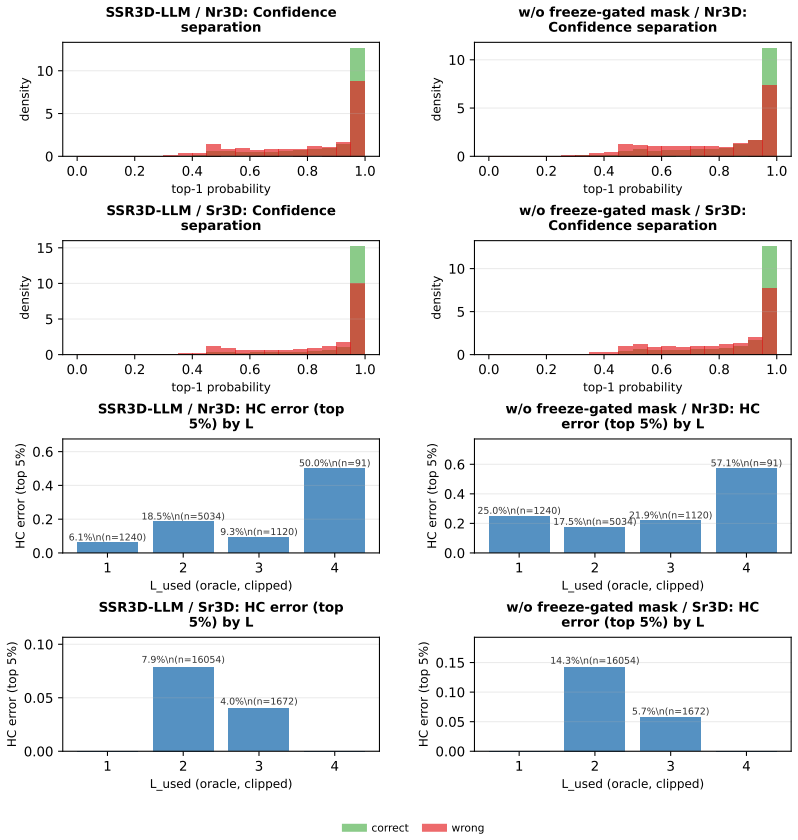
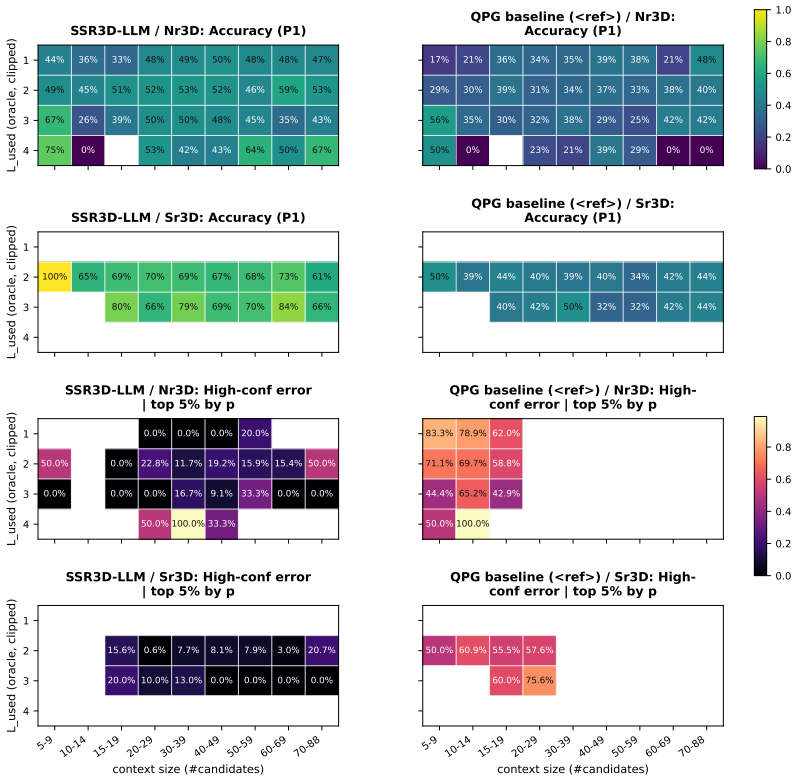
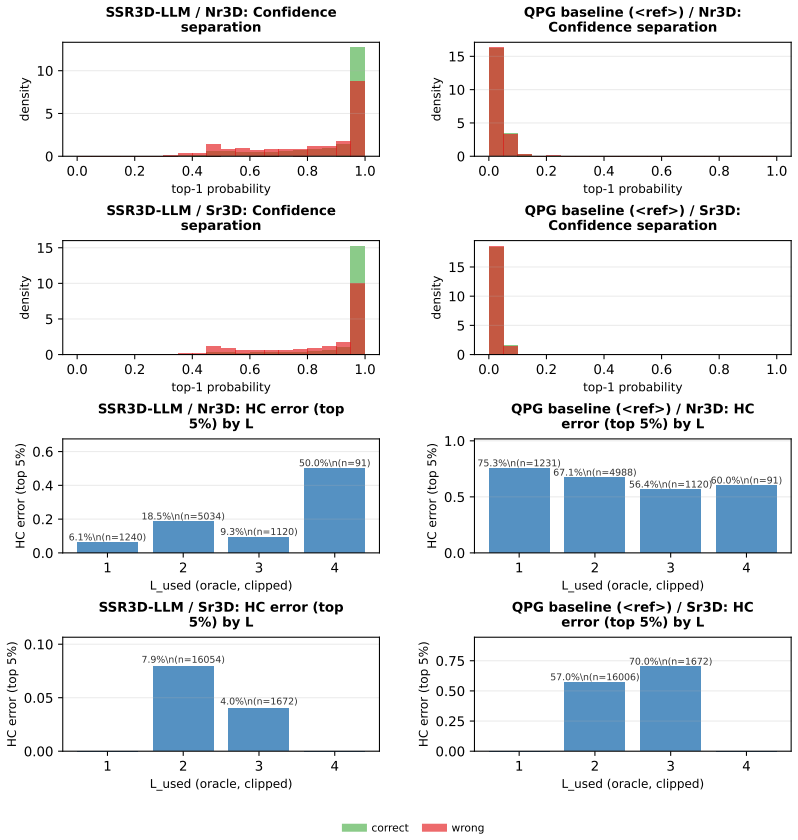
SSR3D-LLM: Structured Spatial Reasoning via Latent Steps for Fine-Grained Grounding in Unified 3D-LLMs
Pith reviewed 2026-06-29 13:51 UTC · model grok-4.3
The pith
Latent spatial reasoning steps allow 3D-LLMs to refine object rankings step by step for fine-grained queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
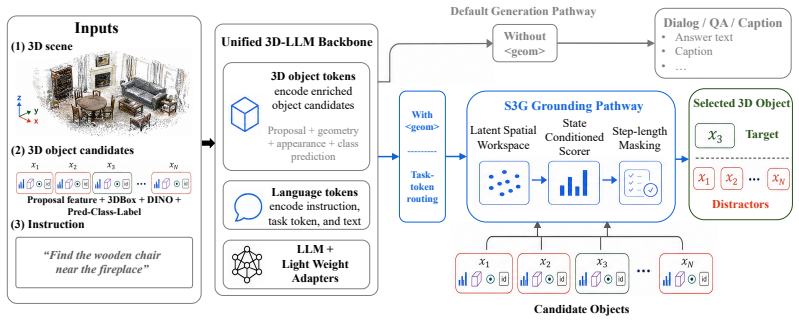
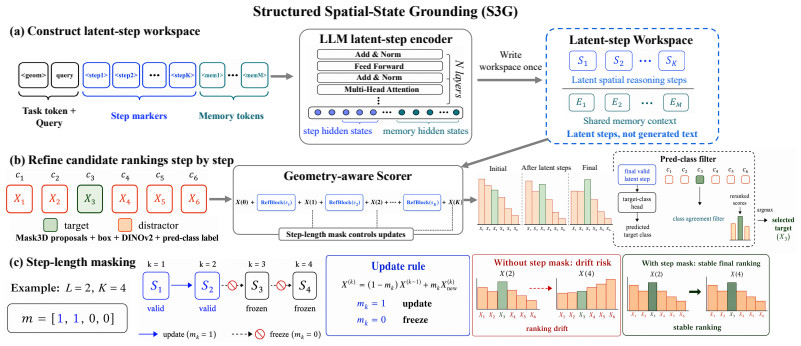
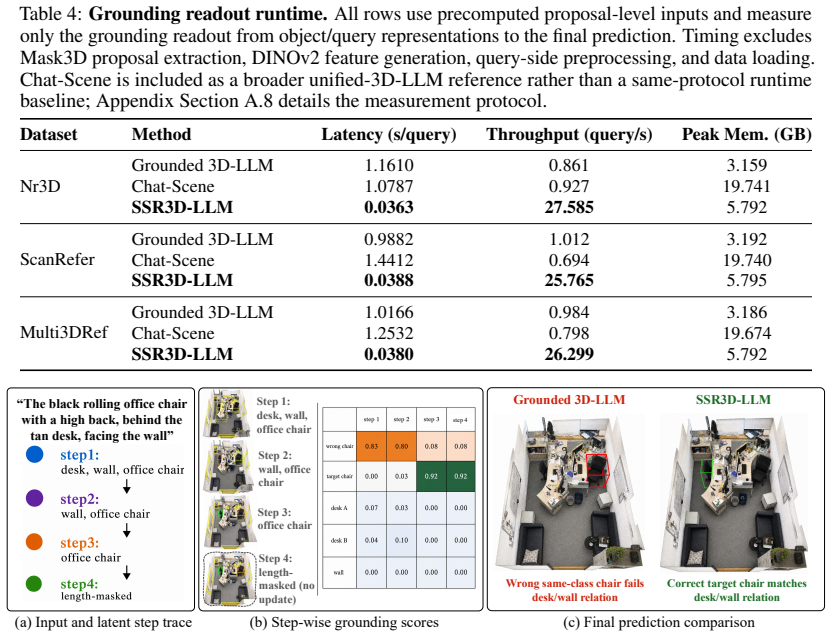
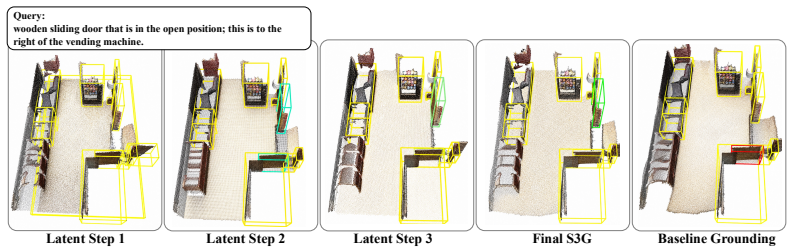
Given fixed Mask3D object proposals, the LLM produces a sequence of latent spatial reasoning steps and memory tokens from the query, and a geometry-aware scorer reads these steps in order to refine candidate rankings step by step with step-length masking. The latent steps are learned from standard benchmark target supervision together with auxiliary referential-cue supervision during training, yet inference requires only the input query and the Mask3D proposals.
What carries the argument
The sequence of latent spatial reasoning steps generated by the LLM, processed sequentially by the geometry-aware scorer to produce successive ranking refinements.
If this is right
- SSR3D-LLM records the highest scores among unified 3D-LLM methods on ReferIt3D, ScanRefer, and Multi3DRef.
- It delivers large gains over single-pointer grounding on tasks that require ruling out multiple same-class candidates.
- It improves results over earlier unified 3D-LLMs while leaving the standard language-task route unchanged.
Where Pith is reading between the lines
- Exposing the latent steps could make the model's spatial decisions easier to inspect or debug after training.
- The same step-wise refinement pattern might transfer to other sequential spatial tasks such as 3D navigation or scene editing.
- Gains could increase further if the method were paired with learned or adaptive object proposals instead of fixed ones.
Load-bearing premise
The fixed Mask3D object proposals supply enough information and the learned latent steps will create actual step-by-step refinements at inference time rather than the model simply memorizing training patterns.
What would settle it
Performance on fine-grained grounding tasks falls to the level of the single-pointer baseline when evaluated on scenes with new object arrangements or when object proposals come from a different detector than the one used in training.
Figures

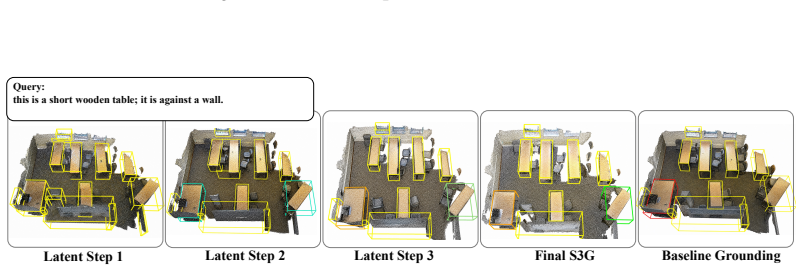
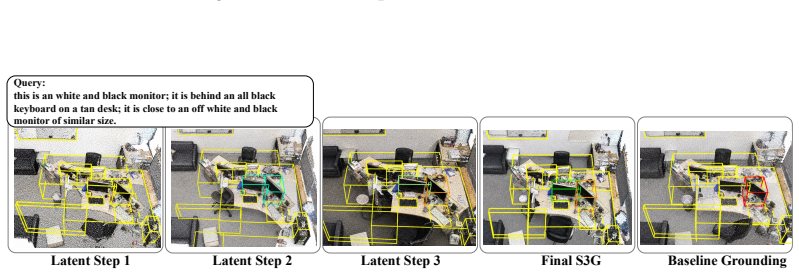
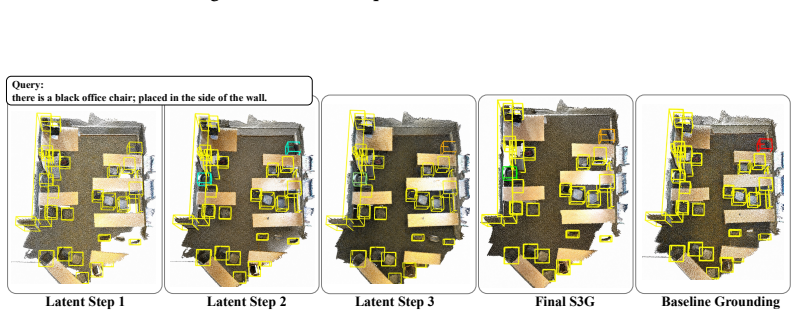






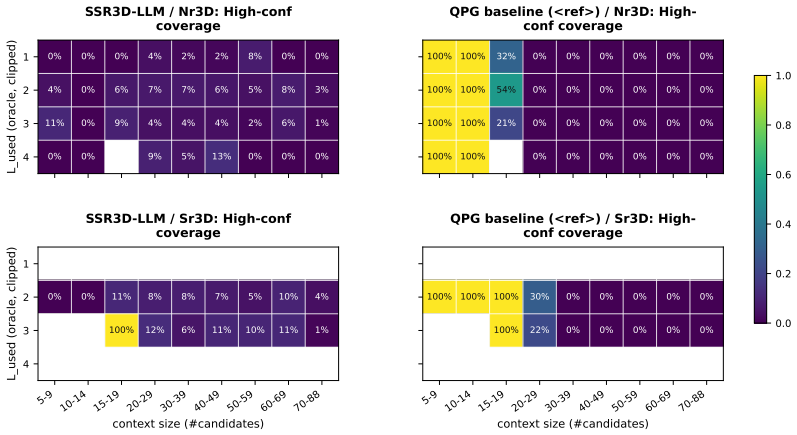

read the original abstract
3D object grounding localizes referred objects in a 3D scene from natural language. Unified instance-centric 3D-LLMs aim to solve grounding together with dialog, QA, and captioning, yet many rely on a single pointer-style grounding decision that compresses a relational instruction into one selection. This is brittle for fine-grained queries where multiple same-class candidates must be ruled out by context objects and spatial relations. We propose Structured Spatial Reasoning 3D-LLM (SSR3D-LLM), a structured grounding interface for unified 3D-LLMs. Given fixed Mask3D object proposals, the LLM writes a sequence of latent spatial reasoning steps and memory tokens from the query, and a geometry-aware scorer reads these latent steps in order to refine candidate rankings step by step with step-length masking. The latent steps are learned from standard benchmark target supervision with auxiliary referential-cue supervision during training, while inference uses only the input query and Mask3D proposals. Across ReferIt3D, ScanRefer, and Multi3DRef, SSR3D-LLM achieves the strongest results among unified 3D-LLM baselines, with substantial gains over the single-pointer QPG baseline on fine-grained grounding and consistent improvements over prior unified 3D-LLMs, while preserving the default language-task route.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SSR3D-LLM, a unified 3D-LLM for 3D object grounding that has the LLM generate a sequence of latent spatial reasoning steps and memory tokens from the natural language query; a geometry-aware scorer then reads these steps sequentially (with step-length masking) to iteratively refine rankings over fixed Mask3D object proposals. Training uses both standard target supervision and auxiliary referential-cue supervision, while inference uses only the query and the same proposals. The work claims the strongest results among unified 3D-LLM baselines on ReferIt3D, ScanRefer, and Multi3DRef, with substantial gains over the single-pointer QPG baseline on fine-grained grounding and no degradation on the default language-task route.
Significance. If the gains are robust and attributable to the latent-step mechanism rather than auxiliary supervision or scorer differences, the approach would usefully extend unified 3D-LLMs to handle relational and fine-grained queries that single-pointer methods struggle with. The design choice to keep the language-task route unchanged is a practical strength. The manuscript supplies no machine-checked proofs, reproducible code, or parameter-free derivations; its value rests entirely on the empirical results.
major comments (2)
- [Abstract] Abstract: performance numbers are stated on three benchmarks with no error bars, ablation details, training curves, or statistical tests. Without these, it is impossible to determine whether the reported improvements over QPG and prior unified 3D-LLMs are statistically supported or sensitive to post-hoc choices; this directly undermines the central empirical claim.
- [Abstract] Abstract (training/inference description): the model is trained with both target supervision and auxiliary referential-cue supervision, yet inference uses only the query. No ablation is described that isolates the contribution of the sequential latent-step reading (versus a single-step or non-masked scorer) while holding the extra supervision fixed. This leaves open the possibility that gains arise from the auxiliary signal or scorer architecture rather than from structured spatial reasoning that generalizes at inference, which is load-bearing for the paper's main thesis.
minor comments (1)
- [Abstract] Abstract: the phrase 'unified 3D-LLMs' is used without a brief definition or pointer to the specific prior works being compared.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical support and targeted ablations. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance numbers are stated on three benchmarks with no error bars, ablation details, training curves, or statistical tests. Without these, it is impossible to determine whether the reported improvements over QPG and prior unified 3D-LLMs are statistically supported or sensitive to post-hoc choices; this directly undermines the central empirical claim.
Authors: We agree that the abstract's presentation of results without error bars or statistical tests limits the ability to assess robustness. Although space constraints prevent including all details in the abstract itself, we will revise the main results tables to report error bars from multiple random seeds, add statistical significance tests comparing against baselines, and ensure ablation details and training curves are explicitly referenced in the main text with pointers to the supplementary material. revision: yes
-
Referee: [Abstract] Abstract (training/inference description): the model is trained with both target supervision and auxiliary referential-cue supervision, yet inference uses only the query. No ablation is described that isolates the contribution of the sequential latent-step reading (versus a single-step or non-masked scorer) while holding the extra supervision fixed. This leaves open the possibility that gains arise from the auxiliary signal or scorer architecture rather than from structured spatial reasoning that generalizes at inference, which is load-bearing for the paper's main thesis.
Authors: The referee is correct that the current manuscript lacks an ablation that holds auxiliary supervision fixed while varying only the sequential latent-step mechanism versus single-step or non-masked alternatives. We will add this controlled ablation in the revised version to isolate the contribution of the structured reasoning at inference time and better substantiate the central claim. revision: yes
Circularity Check
No circularity detected in empirical model proposal
full rationale
The paper describes an empirical architecture change for unified 3D-LLMs: fixed Mask3D proposals are fed to an LLM that generates latent steps, which a geometry-aware scorer then processes with step-length masking. Training uses standard target supervision plus auxiliary referential-cue supervision; inference uses only the query and proposals. Results are reported on external benchmarks (ReferIt3D, ScanRefer, Multi3DRef). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claim to its inputs by construction appear in the text. The work is self-contained as a model evaluated on held-out data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cot3dref: Chain-of-thoughts data-efficient 3d visual grounding.arXiv preprint arXiv:2310.06214, 2023
Eslam Abdelrahman, Mohamed Ayman, Mahmoud Ahmed, Habib Slim, and Mohamed El- hoseiny. Cot3dref: Chain-of-thoughts data-efficient 3d visual grounding.arXiv preprint arXiv:2310.06214, 2023
-
[2]
Scanents3d: Exploiting phrase-to-3d-object correspondences for improved visio-linguistic models in 3d scenes
Ahmed Abdelreheem, Kyle Olszewski, Hsin-Ying Lee, Peter Wonka, and Panos Achlioptas. Scanents3d: Exploiting phrase-to-3d-object correspondences for improved visio-linguistic models in 3d scenes. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3524–3534, 2024
2024
-
[3]
Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes.16th European Conference on Computer Vision (ECCV), 2020
Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, and Leonidas Guibas. Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes.16th European Conference on Computer Vision (ECCV), 2020
2020
-
[4]
Scanqa: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129–19139, 2022
2022
-
[5]
Mikasa: Multi-key- anchor & scene-aware transformer for 3d visual grounding
Chun-Peng Chang, Shaoxiang Wang, Alain Pagani, and Didier Stricker. Mikasa: Multi-key- anchor & scene-aware transformer for 3d visual grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14131–14140, 2024
2024
-
[6]
Dave Chen, Angel Chang, and Matthias Nießner.ScanRefer: 3D Object Localization in RGB-D Scans Using Natural Language, pages 202–221. 11 2020. ISBN 978-3-030-58564-8. doi: 10.1007/978-3-030-58565-5_13
-
[7]
Language conditioned spatial relation reasoning for 3d object grounding.Advances in neural information processing systems, 35:20522–20535, 2022
Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. Language conditioned spatial relation reasoning for 3d object grounding.Advances in neural information processing systems, 35:20522–20535, 2022
2022
-
[8]
Grounded 3d-llm with referent tokens.arXiv preprint arXiv:2405.10370, 2024
Yilun Chen, Shuai Yang, Haifeng Huang, Tai Wang, Runsen Xu, Ruiyuan Lyu, Dahua Lin, and Jiangmiao Pang. Grounded 3d-llm with referent tokens.arXiv preprint arXiv:2405.10370, 2024
-
[9]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[10]
A survey of embodied ai: From simulators to research tasks.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(2):230–244, 2022
Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, and Cheston Tan. A survey of embodied ai: From simulators to research tasks.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(2):230–244, 2022
2022
-
[11]
Transcrib3d: 3d referring ex- pression resolution through large language models
Jiading Fang, Xiangshan Tan, Shengjie Lin, Igor Vasiljevic, Vitor Guizilini, Hongyuan Mei, Rares Ambrus, Gregory Shakhnarovich, and Matthew R Walter. Transcrib3d: 3d referring ex- pression resolution through large language models. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9737–9744. IEEE, 2024
2024
-
[12]
Scene-llm: Extending language model for 3d visual reasoning
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wenhan Xiong. Scene-llm: Extending language model for 3d visual reasoning. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2195–2206. IEEE, 2025
2025
-
[13]
Liang Geng and Jianqin Yin. Viewinfer3d: 3d visual grounding based on embodied viewpoint inference.IEEE Robotics and Automation Letters, 9:7469–7476, 2024. doi: 10.1109/LRA. 2024.3426286
work page doi:10.1109/lra 2024
-
[14]
Ziyu Guo, Yiwen Tang, Renrui Zhang, Dong Wang, Zhigang Wang, Bin Zhao, and Xuelong Li. Viewrefer: Grasp the multi-view knowledge for 3d visual grounding with gpt and prototype guidance.arXiv preprint arXiv:2303.16894, 2023
-
[15]
TransRefer3D: Entity-and-relation aware transformer for fine-grained 3d visual grounding
Dailan He, Yusheng Zhao, Junyu Luo, Tianrui Hui, Shaofei Huang, Aixi Zhang, and Si Liu. TransRefer3D: Entity-and-relation aware transformer for fine-grained 3d visual grounding. In Proceedings of the 29th ACM International Conference on Multimedia, pages 2344–2352, 2021. doi: 10.1145/3474085.3475397. URLhttps://arxiv.org/abs/2108.02388. 10
-
[16]
3d-llm: Injecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494, 2023
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494, 2023
2023
-
[17]
Chat-scene: Bridging 3d scene and large language models with object identifiers.Advances in Neural Information Processing Systems, 37:113991–114017, 2024
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, et al. Chat-scene: Bridging 3d scene and large language models with object identifiers.Advances in Neural Information Processing Systems, 37:113991–114017, 2024
2024
-
[18]
Multi-view transformer for 3d visual grounding
Shijia Huang, Yilun Chen, Jiaya Jia, and Liwei Wang. Multi-view transformer for 3d visual grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15524–15533, 2022
2022
-
[19]
Sceneverse: Scaling 3d vision-language learning for grounded scene understanding
Baoxiong Jia, Yixin Chen, Huangyue Yu, Yan Wang, Xuesong Niu, Tengyu Liu, Qing Li, and Siyuan Huang. Sceneverse: Scaling 3d vision-language learning for grounded scene understanding. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[20]
Spazer: Spatial-semantic progressive reasoning agent for zero-shot 3d visual grounding, 2025
Zhao Jin, Rong-Cheng Tu, Jingyi Liao, Wenhao Sun, Xiao Luo, Shunyu Liu, and Dacheng Tao. Spazer: Spatial-semantic progressive reasoning agent for zero-shot 3d visual grounding, 2025. URLhttps://arxiv.org/abs/2506.21924
-
[21]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9579–9589, 2024
2024
-
[22]
Seeground: See and ground for zero-shot open-vocabulary 3d visual grounding
Rong Li, Shijie Li, Lingdong Kong, Xulei Yang, and Junwei Liang. Seeground: See and ground for zero-shot open-vocabulary 3d visual grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[23]
Daizong Liu, Yang Liu, Wencan Huang, and Wei Hu. A survey on text-guided 3d visual grounding: Elements, recent advances, and future directions.arXiv preprint arXiv:2406.05785, 2024
-
[24]
Jiazhen Liu, Mingkuan Feng, and Long Chen. Better, stronger, faster: Tackling the trilemma in mllm-based segmentation with simultaneous textual mask prediction, 2025. URL https: //arxiv.org/abs/2512.00395
-
[25]
Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods
Weichen Liu, Qiyao Xue, Haoming Wang, Xiangyu Yin, Boyuan Yang, and Wei Gao. Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods. arXiv preprint arXiv:2511.15722, 2025
-
[26]
3d-sps: Single-stage 3d visual grounding via referred point progressive selection
Junyu Luo, Jiahui Fu, Xianghao Kong, Chen Gao, Haibing Ren, Hao Shen, Huaxia Xia, and Si Liu. 3d-sps: Single-stage 3d visual grounding via referred point progressive selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18212–18221, 2022
2022
-
[27]
Language-to-space programming for training-free 3d visual grounding
Boyu Mi, Hanqing Wang, Tai Wang, Yilun Chen, and Jiangmiao Pang. Language-to-space programming for training-free 3d visual grounding. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3844–3864, 2025
2025
-
[28]
Gpt4scene: Understand 3d scenes from videos with vision-language models,
Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, and Hengshuang Zhao. Gpt4scene: Understand 3d scenes from videos with vision-language models, 2025. URL https://arxiv. org/abs/2501.01428
-
[29]
Languagerefer: Spatial-language model for 3d visual grounding.arXiv preprint arXiv:2107.03438, 2021
Junha Roh, Karthik Desingh, Ali Farhadi, and Dieter Fox. Languagerefer: Spatial-language model for 3d visual grounding.arXiv preprint arXiv:2107.03438, 2021
-
[30]
Dense multimodal alignment for open-vocabulary 3d scene understanding
Li Ruihuang, Zhang Zhengqiang, He Chenhang, Ma Zhiyuan, Patel Vishal M., and Zhang Lei. Dense multimodal alignment for open-vocabulary 3d scene understanding. InECCV, 2024
2024
-
[31]
Mask3D: Mask Transformer for 3D Semantic Instance Segmentation
Jonas Schult, Francis Engelmann, Alexander Hermans, Or Litany, Siyu Tang, and Bastian Leibe. Mask3D: Mask Transformer for 3D Semantic Instance Segmentation. 2023. 11
2023
-
[32]
Data-efficient 3d visual grounding via order-aware referring
Tung-Yu Wu, Sheng-Yu Huang, and Yu-Chiang Frank Wang. Data-efficient 3d visual grounding via order-aware referring. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3107–3117. IEEE, 2025
2025
-
[33]
Vlm- grounder: A vlm agent for zero-shot 3d visual grounding
Runsen Xu, Zhiwei Huang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. Vlm- grounder: A vlm agent for zero-shot 3d visual grounding. InCoRL, 2024
2024
-
[34]
Jianing Yang, Xuweiyi Chen, Shengyi Qian, Nikhil Madaan, Madhavan Iyengar, David F Fouhey, and Joyce Chai. Llm-grounder: Open-vocabulary 3d visual grounding with large language model as an agent.arXiv preprint arXiv:2309.12311, 2023
-
[35]
Jianing Yang, Xuweiyi Chen, Nikhil Madaan, Madhavan Iyengar, Shengyi Qian, David F Fouhey, and Joyce Chai. 3d-grand: A million-scale dataset for 3d-llms with better grounding and less hallucination.arXiv preprint arXiv:2406.05132, 2024
-
[36]
A comprehensive survey of 3d dense captioning: Localizing and describing objects in 3d scenes
Ting Yu, Xiaojun Lin, Shuhui Wang, Weiguo Sheng, Qingming Huang, and Jun Yu. A comprehensive survey of 3d dense captioning: Localizing and describing objects in 3d scenes. IEEE Transactions on Circuits and Systems for Video Technology, 34(3):1322–1338, 2023
2023
-
[37]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhihao Yuan, Jinke Ren, Chun-Mei Feng, Hengshuang Zhao, Shuguang Cui, and Zhen Li. Visual programming for zero-shot open-vocabulary 3d visual grounding.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20623–20633, 2023. doi: 10.1109/CVPR52733.2024.01949
-
[38]
Nader Zantout, Haochen Zhang, Pujith Kachana, Jinkai Qiu, Guofei Chen, Ji Zhang, and Wenshan Wang. Sort3d: Spatial object-centric reasoning toolbox for zero-shot 3d grounding using large language models, 2025. URLhttps://arxiv.org/abs/2504.18684
-
[39]
Multi3drefer: Grounding text description to multiple 3d objects
Yiming Zhang, ZeMing Gong, and Angel X Chang. Multi3drefer: Grounding text description to multiple 3d objects. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15225–15236, October 2023
2023
-
[40]
3dvg-transformer: Relation modeling for visual grounding on point clouds
Lichen Zhao, Daigang Cai, Lu Sheng, and Dong Xu. 3dvg-transformer: Relation modeling for visual grounding on point clouds. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2928–2937, October 2021. 12 Algorithm 1 ReferBlockcomputation at stepk. Require:Candidate tokensX (k−1) ∈R N×D , memoryE∈R M×D , step cues k ∈R D ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.