OmniCoT: A Benchmark for Global and Multi-Step Panoramic Reasoning
Pith reviewed 2026-06-30 06:09 UTC · model grok-4.3
The pith
OmniCoT supplies evaluation and training data that force MLLMs to chain multi-step inferences across the full 360x180 panoramic view instead of local cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
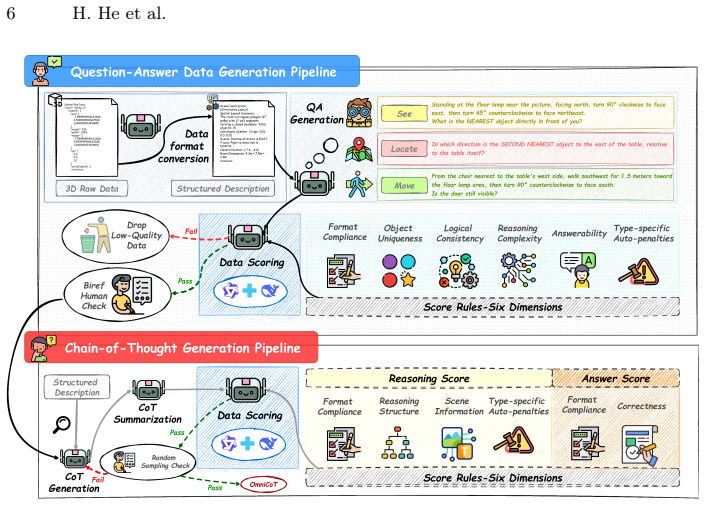
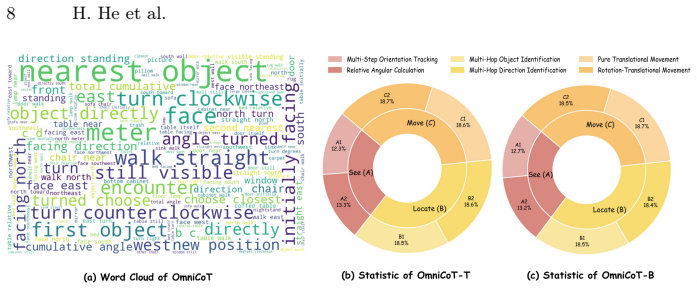
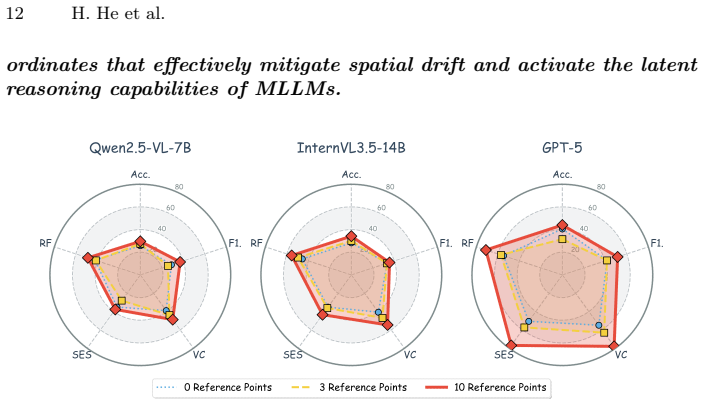
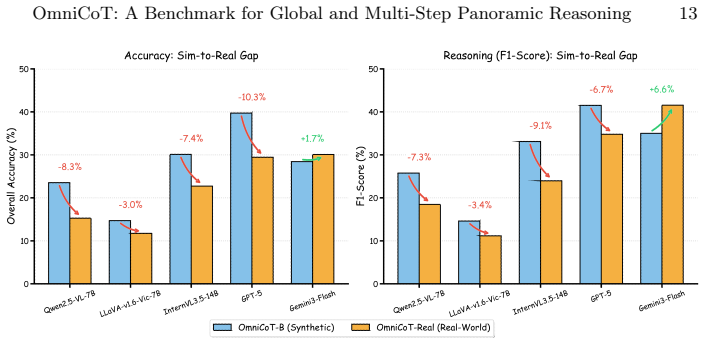
OmniCoT is a panoramic spatial reasoning suite that enables MLLMs to use global evidence and perform multi-step inference across viewpoints. It consists of OmniCoT-B for evaluation of accuracy and reasoning quality, OmniCoT-Real as a manually annotated real-world subset, and OmniCoT-T with structured stepwise Chain-of-Thought annotations that explicitly link intermediate reasoning steps to panoramic evidence such as bearings and proximity. The associated OmniCoT-R1 model is obtained through a two-stage process of supervised fine-tuning followed by GRPO that penalizes geometrically incoherent paths to enforce global 360-degree spatial consistency.
What carries the argument
OmniCoT-T training set of 14.3K examples carrying stepwise Chain-of-Thought annotations that tie each intermediate conclusion to specific panoramic evidence (bearings, proximity), used first for SFT then for GRPO that removes geometrically inconsistent reasoning paths.
If this is right
- Models trained on the new data will produce reasoning paths that remain consistent with the entire 360-degree geometry rather than drifting to contradictory local interpretations.
- Evaluation will separately score answer correctness and the quality of the intermediate steps that reference panoramic evidence.
- A quantified sim-to-real gap will be available from the manually labeled 1K real-world subset.
- Applications such as embodied navigation can draw on global evidence that simpler benchmarks never required models to use.
- The two-stage SFT-plus-GRPO procedure will reduce geometrically incoherent reasoning chains on panoramic inputs.
Where Pith is reading between the lines
- The same annotation style could be applied to other wide-field sensors such as fisheye or multi-camera rigs to test whether global consistency training transfers.
- If the GRPO penalty successfully enforces 360-degree coherence, similar geometric constraints might improve multi-view fusion tasks outside panoramas.
- Real-robot deployment using the trained model would reveal whether the measured sim-to-real gap actually affects downstream task success.
- Future benchmarks could add explicit viewpoint-change queries to force models to track evidence across deliberate rotations of the panorama.
Load-bearing premise
Current panoramic benchmarks mainly test local cues or single-step queries and therefore miss the global multi-step reasoning that the full 360-by-180 view makes possible.
What would settle it
Train an MLLM on OmniCoT-T and measure whether its accuracy and reasoning quality on global multi-step panoramic questions rise above the same model trained only on existing local-cue benchmarks; if no measurable gain appears, the claim that the new data recalibrates difficulty is not supported.
Figures






read the original abstract
Multimodal Large Language Models (MLLMs) have demonstrated promising spatial reasoning capabilities, while these abilities remain underexplored in the emerging visual modality of panoramic imagery. The full 360{\deg}$\times$180{\deg} field of view of panoramas essentially supports complex global multi-step reasoning, which is also the fundamental advantage of panoramas in applications such as embodied intelligence. However, existing panoramic benchmarks largely focus on simplistic queries that rely on local cues or single-/few-step reasoning, thereby ignoring the fundamental advantage of panoramas and failing to fully exploit their potential. To address this gap, we introduce OmniCoT, a panoramic spatial reasoning suite designed to enable MLLMs to use global evidence and perform multi-step inference across viewpoints. It includes OmniCoT-B (6.7K data) for evaluation, which measures both answer accuracy and reasoning quality, OmniCoT-Real (1K data) as a manually annotated real-world subset to quantify the Sim-to-Real gap. For training, OmniCoT-T (14.3K data) is purpose-built with structured stepwise Chain-of-Thought annotations that explicitly link intermediate reasoning steps to panoramic evidence. Based on OmniCoT-T, we introduce OmniCoT-R1 and adopt a two-stage training strategy tailored to the geometrically complex panoramic space, where Supervised Fine-tuning (SFT) anchors reasoning to panoramic evidence (e.g., bearings, proximity) and GRPO penalizes geometrically incoherent paths to consolidate global 360{\deg} spatial consistency. Through OmniCoT, we aim to recalibrate the difficulty of panoramic spatial reasoning to better align with the intrinsic capabilities of panoramic imagery, thereby fostering meaningful progress in this research area.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniCoT, a panoramic spatial reasoning benchmark and training suite for MLLMs. It comprises OmniCoT-B (6.7K samples) for evaluation of answer accuracy and reasoning quality, OmniCoT-Real (1K manually annotated real-world samples) to measure the sim-to-real gap, and OmniCoT-T (14.3K samples) with structured stepwise Chain-of-Thought annotations linking reasoning to panoramic evidence. A two-stage training procedure (SFT followed by GRPO) is proposed to anchor reasoning to geometric cues such as bearings and proximity while penalizing incoherent paths, with the goal of recalibrating difficulty to match the global 360°×180° capabilities of panoramas.
Significance. If the gap claim and empirical results hold, OmniCoT would provide a useful advance by shifting focus from local/single-step queries to global multi-step inference, which aligns with applications in embodied intelligence. The explicit linkage of CoT steps to panoramic evidence and the inclusion of a real-world subset are constructive elements. The work's value depends on reproducible data construction and clear demonstration that prior benchmarks lack comparable tasks.
major comments (4)
- [Introduction] Introduction (and §2 on related work): The central motivation—that existing panoramic benchmarks 'largely focus on simplistic queries that rely on local cues or single-/few-step reasoning'—is load-bearing for the contribution claim but is presented without a task taxonomy, comparison table, or concrete examples of prior benchmarks' limitations. This leaves the asserted gap unverified.
- [§3] §3 (Benchmark Construction): The methodology for designing the 6.7K OmniCoT-B tasks to require global evidence and multi-step inference across viewpoints, along with annotation validation procedures and inter-annotator agreement, is not described in sufficient detail to assess potential biases or reproducibility.
- [§4] §4 (Metrics): The exact definition and computation of 'reasoning quality' (distinct from answer accuracy) is unspecified, including how intermediate steps are scored against panoramic evidence; this directly affects the evaluation protocol's reliability.
- [§5] §5 (Training Procedure): The GRPO objective and its geometric incoherence penalty lack a formal definition or pseudocode, making it impossible to verify how it enforces 360° spatial consistency beyond the high-level description.
minor comments (2)
- [Abstract] The abstract and introduction use 'OmniCoT-R1' without defining whether it is a model variant or training run; clarify nomenclature early.
- [Figures] Figure captions for any panoramic examples should explicitly note which viewpoints or evidence links are used in the multi-step reasoning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity, detail, and verifiability of the contribution.
read point-by-point responses
-
Referee: [Introduction] Introduction (and §2 on related work): The central motivation—that existing panoramic benchmarks 'largely focus on simplistic queries that rely on local cues or single-/few-step reasoning'—is load-bearing for the contribution claim but is presented without a task taxonomy, comparison table, or concrete examples of prior benchmarks' limitations. This leaves the asserted gap unverified.
Authors: We agree that an explicit task taxonomy and comparison table would strengthen the motivation. In the revised manuscript, we will add a taxonomy of panoramic reasoning tasks and a comparison table in the Introduction and §2, with concrete examples drawn from prior benchmarks to demonstrate their predominant focus on local or single-step queries. revision: yes
-
Referee: [§3] §3 (Benchmark Construction): The methodology for designing the 6.7K OmniCoT-B tasks to require global evidence and multi-step inference across viewpoints, along with annotation validation procedures and inter-annotator agreement, is not described in sufficient detail to assess potential biases or reproducibility.
Authors: We will expand §3 to provide detailed methodology on task design criteria for ensuring global evidence and multi-step inference, annotation guidelines, validation procedures, and inter-annotator agreement statistics, enabling better assessment of reproducibility and potential biases. revision: yes
-
Referee: [§4] §4 (Metrics): The exact definition and computation of 'reasoning quality' (distinct from answer accuracy) is unspecified, including how intermediate steps are scored against panoramic evidence; this directly affects the evaluation protocol's reliability.
Authors: We will revise §4 to include the precise definition and computation of reasoning quality, including the scoring rubric for intermediate CoT steps against panoramic evidence and its distinction from answer accuracy. revision: yes
-
Referee: [§5] §5 (Training Procedure): The GRPO objective and its geometric incoherence penalty lack a formal definition or pseudocode, making it impossible to verify how it enforces 360° spatial consistency beyond the high-level description.
Authors: We will add a formal mathematical definition of the GRPO objective along with pseudocode for the geometric incoherence penalty in the revised §5 to enable verification of how 360° spatial consistency is enforced. revision: yes
Circularity Check
No circularity: benchmark construction with no derivations or self-referential reductions
full rationale
The paper introduces a new benchmark suite (OmniCoT-B, OmniCoT-Real, OmniCoT-T) and a two-stage training procedure (SFT + GRPO) for panoramic spatial reasoning. No mathematical derivation chain, parameter fitting, predictions, or first-principles results are present in the abstract or described structure. The central assertion about limitations of prior benchmarks is a factual claim about existing literature rather than a self-referential loop or reduction to fitted inputs. No self-citations, ansatzes, or renamings that reduce the claimed contribution to its own construction are exhibited. This is a standard benchmark-creation paper whose value rests on external validation of the new tasks, not internal equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Agrawal, A., Batra, D., Parikh, D., Kembhavi, A.: Don’t just assume; look and answer: Overcoming priors for visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4971–4980 (2018)
2018
-
[2]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X., Xie, Y., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y., Xu, S., Chen, C., Zhu, D., et al.: Llava-onevision-1.5: Fully open framework for democratized multimodal training. arXiv preprint arXiv:2509.23661 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-VL technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-VL technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Cai, W., Ponomarenko, I., Yuan, J., Li, X., Yang, W., Dong, H., Zhao, B.: Spa- tialbot: Precise spatial understanding with vision language models. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 9490–9498. IEEE (2025)
2025
-
[6]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Chou, S.H., Chao, W.L., Lai, W.S., Sun, M., Yang, M.H.: Visual question answer- ing on 360deg images. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 1607–1616 (2020)
2020
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Daxberger, E., Wenzel, N., Griffiths, D., Gang, H., Lazarow, J., Kohavi, G., Kang, K., Eichner, M., Yang, Y., Dehghan, A., et al.: Mm-spatial: Exploring 3d spatial understanding in multimodal llms. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7395–7408 (2025)
2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Dong, Y., Fang, C., Bo, L., Dong, Z., Tan, P.: Panocontext-former: Panoramic total scene understanding with a transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28087–28097 (2024)
2024
- [9]
-
[10]
Nature Machine In- telligence2(11), 665–673 (2020)
Geirhos, R., Jacobsen, J.H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., Wichmann, F.A.: Shortcut learning in deep neural networks. Nature Machine In- telligence2(11), 665–673 (2020)
2020
-
[11]
Guo, D., Wu, F., Zhu, F., Leng, F., Shi, G., Chen, H., Fan, H., Wang, J., Jiang, J., Wang, J., et al.: Seed1. 5-vl technical report. arXiv preprint arXiv:2505.07062 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
arXiv preprint arXiv:2411.13112 (2024)
Guo, X., Zhang, R., Duan, Y., He, Y., Nie, D., Huang, W., Zhang, C., Liu, S., Zhao, H., Chen, L.: SURDS: Benchmarking spatial understanding and reasoning in driving scenarios with vision language models. arXiv preprint arXiv:2411.13112 (2024)
-
[13]
Hong, W., Yu, W., Gu, X., Wang, G., Gan, G., Tang, H., Cheng, J., Qi, J., Ji, J., Pan, L., et al.: Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv:2507.01006 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
arXiv preprint arXiv:2601.09668 (2026)
Huang, A., Yao, C., Han, C., Wan, F., Guo, H., Lv, H., Zhou, H., Wang, J., Zhou, J., Sun, J., et al.: Step3-vl-10b technical report. arXiv preprint arXiv:2601.09668 (2026)
-
[15]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024) OmniCoT: A Benchmark for Global and Multi-Step Panoramic Reasoning 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
arXiv preprint arXiv:2502.09621 (2025)
Jiang, D., Zhang, R., Guo, Z., Li, Y., Qi, Y., Chen, X., Wang, L., Jin, J., Guo, C., Yan, S., et al.: Mme-cot: Benchmarking chain-of-thought in large mul- timodal models for reasoning quality, robustness, and efficiency. arXiv preprint arXiv:2502.09621 (2025)
-
[17]
In: The twelfth international conference on learning representations (2023)
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., Cobbe, K.: Let’s verify step by step. In: The twelfth international conference on learning representations (2023)
2023
-
[18]
One flight over the gap: A survey from perspective to panoramic vision,
Lin, X., Ge, X., Zhang, D., Wan, Z., Wang, X., Li, X., Jiang, W., Du, B., Tao, D., Yang, M.H., et al.: One flight over the gap: A survey from perspective to panoramic vision. arXiv preprint arXiv:2509.04444 (2025)
-
[19]
arXiv preprint arXiv:2602.21992 (2026)
Lin, Z., Zheng, X.: Panoenv: Exploring 3d spatial intelligence in panoramic envi- ronments with reinforcement learning. arXiv preprint arXiv:2602.21992 (2026)
-
[20]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al.: Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Transactions of the Association for Computational Linguistics11, 635–651 (2023)
Liu, F., Emerson, G., Collier, N.: Visual spatial reasoning. Transactions of the Association for Computational Linguistics11, 635–651 (2023)
2023
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
2024
-
[23]
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llavanext: Improved reasoning, ocr, and world knowledge (2024)
2024
-
[24]
8 model card: Towards generalized real-world agency
Seed, B.: Seed1. 8 model card: Towards generalized real-world agency. Tech. rep., Technical report (model card), December
-
[25]
URL https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild- tss/ljhwZthlaukjlkulzlp/research/Seed-1.8-Modelcard.pdf (2025)
2025
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Stogiannidis, I., McDonagh, S., Tsaftaris, S.A.: Mind the gap: Benchmarking spa- tial reasoning in vision-language models. arXiv preprint arXiv:2503.19707 (2025)
-
[29]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Kimi K2.5: Visual Agentic Intelligence
Team, K., Bai, T., Bai, Y., Bao, Y., Cai, S., Cao, Y., Charles, Y., Che, H., Chen, C., Chen, G., et al.: Kimi k2. 5: Visual agentic intelligence. arXiv preprint arXiv:2602.02276 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
PanoWorld: Towards Spatial Supersensing in 360$^\circ$ Panorama World
Wang, C., Lin, X., Liu, J., Liu, Y., Wang, Z., Qi, D., Yan, Y., Chen, X.: Panoworld: Towards spatial supersensing in 360◦ panorama world. arXiv preprint arXiv:2605.13169 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Advances in neural information processing systems35, 24824–24837 (2022) 18 H
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022) 18 H. He et al
2022
-
[34]
arXiv preprint arXiv:2510.00515 (2025)
Wen, Z., Wang, S., Zhou, Y., Zhang, J., Zhang, Q., Gao, Y., Chen, Z., Wang, B., Li, W., He, C., et al.: Efficient multi-modal large language models via progressive consistency distillation. arXiv preprint arXiv:2510.00515 (2025)
-
[35]
arXiv preprint arXiv:2601.19325 (2026)
Wen, Z., Yang, B., Chen, S., Zhang, Y., Han, Y., Ke, J., Wang, C., Fu, Y., Zhao, J., Yao, J., et al.: Innovator-vl: A multimodal large language model for scientific discovery. arXiv preprint arXiv:2601.19325 (2026)
-
[36]
xAI: Grok 4 Model Card. Tech. rep. (Aug 2025),https://data.x.ai/2025-08- 20-grok-4-model-card.pdf, model card / technical report
2025
-
[37]
In: 2012 IEEE conference on computer vision and pattern recognition
Xiao, J., Ehinger, K.A., Oliva, A., Torralba, A.: Recognizing scene viewpoint using panoramic place representation. In: 2012 IEEE conference on computer vision and pattern recognition. pp. 2695–2702. IEEE (2012)
2012
-
[38]
SpatialBench: Benchmarking Multimodal Large Language Models for Spatial Cognition
Xu, P., Wang, S., Zhu, Y., Li, J., Zhang, Y.: SpatialBench: Benchmarking multi- modal large language models for spatial cognition. arXiv preprint arXiv:2511.21471 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
IEICE transactions on in- formation and systems82(3), 568–579 (1999)
Yagi, Y.: Omnidirectional sensing and its applications. IEICE transactions on in- formation and systems82(3), 568–579 (1999)
1999
-
[40]
UAOR: Uncertainty-aware Observation Reinjection for Vision-Language-Action Models
Yang, J., Chen, Y., Xu, Y., Li, P., Wu, X., Wen, Z., Fang, B., Yu, T., Zhang, Z., Li, Y., et al.: Uaor: Uncertainty-aware observation reinjection for vision-language- action models. arXiv preprint arXiv:2602.18020 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [41]
-
[42]
arXiv preprint arXiv:2506.10100 (2025)
Yang, Y., Wang, Y., Wen, Z., Zhongwei, L., Zou, C., Zhang, Z., Wen, C., Zhang, L.: Efficientvla: Training-free acceleration and compression for vision-language-action models. arXiv preprint arXiv:2506.10100 (2025)
-
[43]
arXiv preprint arXiv:2509.18905 (2025)
Yu, S., Chen, Y., Ju, H., Jia, L., Zhang, F., Huang, S., Wu, Y., Cui, R., Ran, B., Zhang, Z., et al.: How far are vlms from visual spatial intelligence? a benchmark- driven perspective. arXiv preprint arXiv:2509.18905 (2025)
-
[44]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Zhang, C., Cui, Z., Chen, C., Liu, S., Zeng, B., Bao, H., Zhang, Y.: Deeppanocon- text: Panoramic 3d scene understanding with holistic scene context graph and relation-based optimization. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 12632–12641 (2021)
2021
-
[45]
arXiv preprint arXiv:2505.14197 (2025)
Zhang, X., Ye, Z., Zheng, X.: Towards omnidirectional reasoning with 360-r1: A dataset, benchmark, and grpo-based method. arXiv preprint arXiv:2505.14197 (2025)
-
[46]
arXiv preprint arXiv:2603.15558 (2026)
Zhang, Z., Liao, C., Zhang, H., Chen, H.H., Chen, K., Wen, Z., Guo, L., Ren, B., Zheng, X., Li, Y., et al.: Panoramic affordance prediction. arXiv preprint arXiv:2603.15558 (2026)
-
[47]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhao, Y., Huang, J., Hu, J., Wang, X., Mao, Y., Zhang, D., Jiang, Z., Wu, Z., Ai, B., Wang, A., et al.: Swift: a scalable lightweight infrastructure for fine-tuning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 29733– 29735 (2025)
2025
-
[48]
In: Proceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Zheng, C., Zhang, Z., Zhang, B., Lin, R., Lu, K., Yu, B., Liu, D., Zhou, J., Lin, J.: Processbench: Identifying process errors in mathematical reasoning. In: Proceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1009–1024 (2025)
2025
-
[49]
Zheng, X., Dongfang, Z., Jiang, L., Zheng, B., Guo, Y., Zhang, Z., Albanese, G., Yang, R., Ma, M., Zhang, Z., et al.: Multimodal spatial reasoning in the large model era: A survey and benchmarks. arXiv preprint arXiv:2510.25760 (2025) OmniCoT: A Benchmark for Global and Multi-Step Panoramic Reasoning 19
-
[50]
arXiv preprint arXiv:2509.12989 (2025)
Zheng, X., Liao, C., Weng, Z., Lei, K., Dongfang, Z., He, H., Lyu, Y., Jiang, L., Qi, L., Chen, L., et al.: Panorama: The rise of omnidirectional vision in the embodied ai era. arXiv preprint arXiv:2509.12989 (2025)
-
[51]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhong, D., Zheng, X., Liao, C., Lyu, Y., Chen, J., Wu, S., Zhang, L., Hu, X.: Omnisam: Omnidirectional segment anything model for uda in panoramic seman- tic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23892–23901 (2025)
2025
-
[52]
Zhou, Y., Zhang, T., Zhang, D., Ji, S., Li, X., Qi, L.: Dense360: Dense understand- ing from omnidirectional panoramas. arXiv preprint arXiv:2506.14471 (2025) A Ethics Statement The synthetic part of our dataset is derived from DeepPanoContext [43] and ReplicaPano [8], both of which are publicly available for academic research with the MIT license. We str...
-
[53]
the chair near the floor lamp
**Natural Language Only:** 9- While generating questions, Use ONLY natural language to describe spatial relations between objects for determining their positions, instead of using coordinate-based positioning. 10- CORRECT: "the chair near the floor lamp", "the table closest to the north wall" 11- CORRECT: "the piano in the southwest corner", "the stool ne...
-
[54]
NEAREST",
**Answer Uniqueness (CRITICAL):** 17Every question must have EXACTLY ONE unambiguous answer. 46 H. He et al. 18- Use spatial qualifiers: "NEAREST", "FIRST", "closest", "directly" 19- Specify relative positions: "to the left of", "north of", "between X and Y" 20- For visibility questions: Ask about ONE specific target object 21
-
[55]
**Wall & Window Information:** 23- Wall segments BLOCK line-of-sight (solid barriers) 24- Windows are TRANSPARENT (can see through walls with windows) 25
-
[56]
Standing at [object], facing [direction/object], turn [angle1]\textdegree [dir1], then turn [angle2]\textdegree [dir2], what is the NEAREST object?
**Reasoning Complexity:** 27- Target: 3-4 reasoning steps 28- Each step should be clear and verifiable from scene data 29- Avoid overly convoluted multi-hop chains 30 31**Question Types (Generate All 6):** 32 33TYPE 1: Viewpoint Transform - Identify Object 34**Structure:** "Standing at [object], facing [direction/object], turn [angle1]\textdegree [dir1], ...
-
[57]
Locate starting object position
-
[58]
Apply rotations to determine final facing direction
-
[59]
Identify nearest object in that direction 49 OmniCoT: A Benchmark for Global and Multi-Step Panoramic Reasoning 47 50TYPE 2: Viewpoint Transform - Angle Calculation 51**Structure:** "Standing at [object A], facing [direction/object B], turn to face [object C], then turn to face [object D]. What is the TOTAL angle turned? (Choose: 45\textdegree/90\textdegr...
-
[60]
Calculate angle from initial direction to object C
-
[61]
Calculate angle from object C to object D
-
[62]
What is [relation2 + qualifier] of the [relation1 + qualifier] object of [anchor]?
Match to closest option 66 67TYPE 3: Multi-Hop Object Identification 68**Structure:** "What is [relation2 + qualifier] of the [relation1 + qualifier] object of [anchor]?" 69 70**Requirements:** 71- Create 2-hop spatial relation chain 72- Use distance qualifiers: "nearest", "second closest", "farthest" 73- Use direction qualifiers from scene data: "north o...
-
[63]
Identify anchor object (piano)
-
[64]
Find nearest object north of piano (using Nearby + direction info)
-
[65]
In which direction is the [relation + qualifier] object of [anchor], relative to [anchor]?
Identify object west of that intermediate object 83 84TYPE 4: Multi-Hop Direction Identification 85**Structure:** "In which direction is the [relation + qualifier] object of [anchor], relative to [anchor]?" 86 87**Requirements:** 88- Create spatial relation chain 89- Query final direction (answer: N/S/E/W/NE/NW/SE/SW) 90- Use available "Nearby" direction ...
-
[66]
Identify anchor object (table)
-
[67]
Find second nearest object east of table
-
[68]
From [start_object], walk straight [direction] for [distance]m. What is the FIRST object you will encounter?
Calculate direction from table to that object 99 100TYPE 5: Move - Pure Translation 101**Structure:** "From [start_object], walk straight [direction] for [distance]m. What is the FIRST object you will encounter?" 102 103**Requirements:** 104- Straight-line movement (NO rotation) 105- Specify cardinal direction (N/S/E/W/NE/NW/SE/SW) 106- Distance: 1-3 mete...
-
[69]
Identify starting position
-
[70]
Calculate endpoint after 2m east movement
-
[71]
From [start], walk [direction] for [distance]m, then turn [angle]\textdegree [dir]. Is [specific_object] still visible?
Find first object along that path 116 117TYPE 6: Move-Turn Combined OmniCoT: A Benchmark for Global and Multi-Step Panoramic Reasoning 49 118**Structure:** "From [start], walk [direction] for [distance]m, then turn [angle]\textdegree [dir]. Is [specific_object] still visible?" 119 120**Requirements:** 121- Compound transformation: movement + rotation 122-...
-
[72]
Calculate new position after movement
-
[73]
Apply rotation to determine final facing
-
[74]
Check if target object is in new field of view
-
[75]
questions
Account for potential obstacles 134 135**Output Format (valid JSON, no markdown):** 136{{ 137"questions": [ 138{{"question": "...", "type": "viewpoint_transform_identify", "current_position_description": "...", "current_facing_description": "...", "action_description": "...", "expected_reasoning_steps": 2|3|4}}, 139{{"question": "...", "type": "viewpoint_...
-
[76]
the chair near the floor lamp in the northern area
**Format Compliance - Natural Language ONLY (CRITICAL):** 16PASS: Uses natural language to describe objects and positions 17- "the chair near the floor lamp in the northern area" 18- "the piano in the southwest corner" 19- "the table closest to the north window" 20 21FAIL (Auto score \leq 2): Contains coordinate references in question text 22- "piano(-6.9...
-
[77]
NEAREST",
**Object Uniqueness - Unambiguous Identification (CRITICAL):** 29PASS: Every mentioned object can be UNIQUELY determined from scene 30- Uses spatial qualifiers: "NEAREST", "FIRST", "second closest", "directly ahead" 31- Provides disambiguating context: "the chair near the table, closer to the window" 32- References nearby objects: "the stool next to the c...
-
[78]
north of X but also south of X
**Logical Consistency - Internal Coherence:** 40PASS: Objects mentioned in question exist in the scene description 41- Initial and final objects are both present 42- Spatial relationships are factually correct 43- Movement paths are physically possible 44 45FAIL (Score \leq 3): Logical errors 46- References non-existent objects 47- Contradictory spatial r...
-
[79]
Where is the chair?
**Reasoning Complexity - Appropriate Depth:** 50PASS: Requires 2-4 reasoning steps based on expected_reasoning_steps 51- Not trivial (single-step lookup) 52- Not overly complex (excessive multi-hop chains) 53- Tests genuine spatial understanding 54 55FAIL (Score \leq 5): Inappropriate complexity 56- Too simple: "Where is the chair?" (direct lookup) 57- To...
-
[80]
center of room
**Answerability - Question Can Be Solved:** 61PASS: Has EXACTLY ONE correct answer derivable from scene data 62- All information needed is present in scene description 63- Answer is determinate (not opinion-based) 64- Question structure allows for clear conclusion 65 66FAIL (Score \leq 3): Cannot be answered definitively 67- Missing critical information 6...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.