BELLS-O: Evaluating the Operational Trade-offs of LLM Supervision Systems
Pith reviewed 2026-06-27 05:03 UTC · model grok-4.3
The pith
Specialized guardrails match frontier LLMs on content moderation detection while running 5-10x faster and 10x cheaper, but frontier models outperform on jailbreak detection at much higher cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
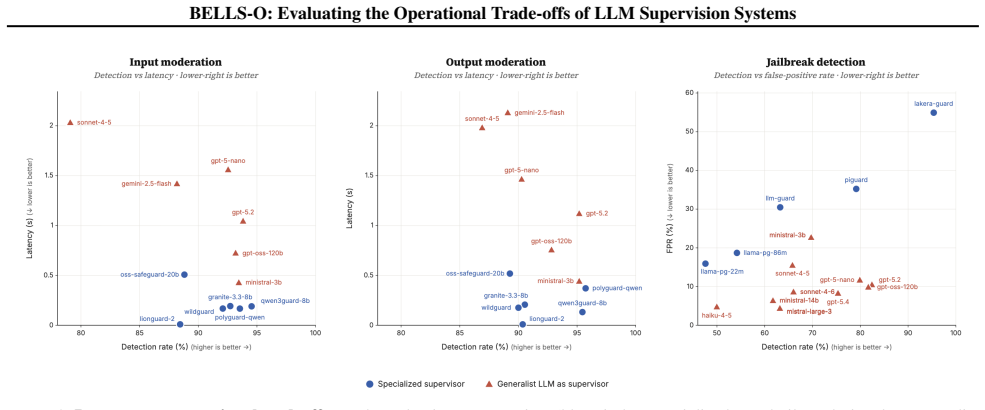
BELLS-O maps the Pareto frontier across specialized guardrails and frontier LLMs on input/output moderation and jailbreak detection. On content moderation the top specialized systems reach approximately 95 percent detection with false-positive rates at or below 2 percent, matching frontier LLMs at 94 percent detection while running 5-10 times faster and roughly 10 times cheaper. On jailbreak detection the relation inverts: frontier LLMs deliver higher detection and lower false positives, yet at 10-50 times higher monetary cost and 5-10 times higher latency.
What carries the argument
The BELLS-O benchmark, which jointly scores detection, false-positive rate, latency, and cost on in-house datasets covering 11 harm categories and 13 jailbreak techniques with paraphrased synthetic samples to reduce generator artifacts.
If this is right
- Production content-moderation pipelines can adopt specialized guardrails without measurable loss in safety coverage.
- Jailbreak protection choices must weigh accuracy gains against large increases in operating expense and response time.
- Any new supervision benchmark that omits latency and cost will fail to predict which systems are viable in deployment.
- Paraphrasing of synthetic test data is required to keep evaluation results from reflecting model-specific generation fingerprints.
- Vendor-neutral leaderboards become usable for procurement only when they report all four metrics together.
Where Pith is reading between the lines
- High-volume services should default to specialized moderators for routine content and reserve frontier models for the narrower jailbreak use case.
- Hybrid pipelines that route easy cases to fast guardrails and hard cases to general models could capture most of the accuracy gain at lower average cost.
- The 13 attack techniques tested may not cover future jailbreak methods, so periodic re-evaluation of the benchmark itself will be needed.
- Real deployment logs could be used to test whether the observed speed and cost gaps persist when traffic patterns differ from the benchmark datasets.
Load-bearing premise
The in-house datasets of handcrafted prompts, expert-curated samples, and paraphrased synthetic data give an unbiased picture of real-world harms and attacks across the tested categories and techniques.
What would settle it
A large collection of real production moderation cases and live jailbreak attempts in which specialized systems fall well below frontier LLMs on detection rate for ordinary content moderation while maintaining their speed and cost advantage.
Figures

read the original abstract
LLM supervision systems, namely input/output moderation filters and jailbreak detectors, are the primary safeguard against misuse in deployed AI applications, yet existing benchmarks are often vendor-biased, omit cost and latency, and rarely compare specialized guardrails against repurposed generalist LLMs. We present BELLS-O (Benchmark for the Evaluation of LLM Supervision Systems, Operational), the first independent operational benchmark of LLM supervision systems. BELLS-O evaluates 28 systems from 17 providers: every major specialized guardrail (e.g., LlamaGuard-4, ShieldGemma-2, Lakera Guard) and frontier generalists repurposed as supervisors (e.g., GPT-5.4, Claude Sonnet 4.6, Grok-4.1), jointly on detection rate, false-positive rate, latency, and monetary cost. We cover input/output moderation across 11 harm categories and jailbreak detection across 13 attack techniques, using in-house datasets built from handcrafted prompts, expert-curated samples, and quality-controlled synthetic generation. To suppress latent generator fingerprints in synthetic data, every generated sample is paraphrased. Mapping the Pareto frontier reveals use-case-dependent tradeoffs. On content moderation, specialized supervisors are operationally dominant: top systems match frontier LLMs on detection (~95% vs. 94%) at comparably low false-positive rates (<=2%), while running 5-10x faster and ~10x cheaper. On jailbreak detection, the tradeoff shifts: frontier LLMs achieve higher detection and lower false-positive rates but at 10-50x higher cost and 5-10x higher latency. We release the benchmark, framework, leaderboard, and datasets as the first vendor-neutral basis for selecting safeguards under real deployment constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BELLS-O, the first vendor-neutral operational benchmark for LLM supervision systems. It evaluates 28 systems (specialized guardrails such as LlamaGuard-4 and frontier LLMs such as GPT-5.4) jointly on detection rate, false-positive rate, latency, and cost for input/output moderation across 11 harm categories and jailbreak detection across 13 attack techniques. Datasets are constructed in-house from handcrafted prompts, expert-curated samples, and paraphrased synthetic generations. The central empirical finding is that specialized supervisors dominate the Pareto frontier for content moderation (~95% detection at <=2% FPR, 5-10x faster and ~10x cheaper than frontier LLMs), while frontier LLMs are superior for jailbreak detection at substantially higher cost and latency. The benchmark, framework, leaderboard, and datasets are released.
Significance. If the reported measurements prove robust to dataset distribution shifts, the work supplies the first systematic, cost- and latency-inclusive comparison of specialized versus generalist supervisors. This directly informs deployment choices under real operational constraints and addresses a documented gap in prior benchmarks that omit these metrics.
major comments (2)
- [Abstract] Abstract: The headline claims of operational dominance (specialized systems matching ~95% detection at <=2% FPR while 5-10x faster/cheaper on moderation; frontier LLMs superior on jailbreaks) rest entirely on the authors' in-house 11-category/13-technique datasets. These are built from handcrafted prompts, expert-curated samples, and quality-controlled paraphrased synthetic generations; no external validation, comparison to independent corpora, or production-traffic statistics are reported to establish that the harm distributions, attack phrasing, or edge cases are representative.
- [Abstract] Abstract: No statistical tests, confidence intervals, or error analysis are mentioned for the reported detection rates (~95% vs 94%), FPR thresholds (<=2%), or the derived 5-10x / 10-50x multipliers. Without these, it is impossible to determine whether the observed differences are distinguishable from sampling variation or post-hoc threshold choices.
minor comments (1)
- [Abstract] The abstract states that 'every generated sample is paraphrased' to suppress generator fingerprints, but provides no quantitative measure of residual fingerprint leakage or ablation showing the effect of paraphrasing on downstream metrics.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of dataset representativeness and statistical rigor in evaluating the operational claims. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of operational dominance (specialized systems matching ~95% detection at <=2% FPR while 5-10x faster/cheaper on moderation; frontier LLMs superior on jailbreaks) rest entirely on the authors' in-house 11-category/13-technique datasets. These are built from handcrafted prompts, expert-curated samples, and quality-controlled paraphrased synthetic generations; no external validation, comparison to independent corpora, or production-traffic statistics are reported to establish that the harm distributions, attack phrasing, or edge cases are representative.
Authors: The in-house datasets were built to provide the first comprehensive, balanced coverage across 11 harm categories and 13 jailbreak techniques, drawing on expert handcrafting, curation of diverse samples, and paraphrasing of synthetic generations to reduce artifacts. This design prioritizes breadth where no matching public corpus existed. We will add an expanded methods subsection detailing the construction pipeline and a dedicated limitations paragraph on potential distribution shifts and representativeness, but note that production-traffic statistics are proprietary and unavailable. revision: partial
-
Referee: [Abstract] Abstract: No statistical tests, confidence intervals, or error analysis are mentioned for the reported detection rates (~95% vs 94%), FPR thresholds (<=2%), or the derived 5-10x / 10-50x multipliers. Without these, it is impossible to determine whether the observed differences are distinguishable from sampling variation or post-hoc threshold choices.
Authors: We agree that the absence of statistical measures limits interpretability of the reported differences. In revision we will add bootstrap confidence intervals for all headline metrics, report sample sizes per category, and document the threshold-selection procedure to allow assessment of robustness to sampling variation. revision: yes
- Production-traffic statistics from real deployments, which are proprietary and cannot be obtained for an open benchmark.
Circularity Check
Pure empirical benchmark; no derivations or self-referential reductions
full rationale
The paper is a direct empirical evaluation of 28 systems on fixed test sets for detection rate, FPR, latency and cost. No equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or ansatzes appear. Central claims are measurements on the described handcrafted/expert/synthetic datasets; results do not reduce to the inputs by construction. Self-citations are absent from the provided text and not load-bearing.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2308.0 9662. Bhardwaj, R., Anh, D. D., and Poria, S. Language Models are Homer Simpson! Safety Re-Alignment of Fine-tuned Language Models through Task Arithmetic, 2024. URL https://arxiv.org/abs/2402.11746. Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., 8 BELLS-O: Evaluating the Operational Trade-offs of LLM Supervision Sys...
-
[2]
URL https://arxiv.org/abs/2405.1 4057. Mistral AI. Mistral medium 3.5. https://docs.mis tral.ai/models/model-cards/mistral-m edium-3-5-26-04 , 4 2026. Model card accessed 2026-05-03. OpenAI. Usage policies, 2024. URL https://openai .com/policies/usage-policies/ . Accessed: 2026-04-29. Padhi, I., Nagireddy, M., Cornacchia, G., Chaudhury, S., Pedapati, T., ...
arXiv 2026
-
[3]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Association for Computational Linguistics. doi: 10.18653/v1/D19-1410. URL https://aclantho logy.org/D19-1410/. Röttger, P., Kirk, H., Vidgen, B., Attanasio, G., Bianchi, F., and Hovy, D. XSTest: A test suite for identifying exaggerated safety behaviours in large language mod- els. In Duh, K., Gomez, H., and Bethard, S. (eds.),Pro- ceedings of the 2024 Con...
-
[4]
Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.301. URL https://ac lanthology.org/2024.naacl-long.301/. Sharma, M., Tong, M., Mu, J., Wei, J., Kruthoff, J., Good- friend, S., Ong, E., Peng, A., Agarwal, R., Anil, C., Askell, A., Bailey, N., Benton, J., Bluemke, E., Bowman, S. R., Christiansen, E., Cunningham, H., Dau, A., Gopa...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.naacl-long.301 2024
-
[5]
Classify the following prompt as harmful or not
URL http://dx.doi.org/10.1145/369 0624.3709179. Zeng, W., Liu, Y ., Mullins, R., Peran, L., Fernandez, J., Harkous, H., Narasimhan, K., Proud, D., Kumar, P., Radharapu, B., Sturman, O., and Wahltinez, O. Shield- Gemma: Generative AI Content Moderation Based on Gemma, 2024. URL https://arxiv.org/abs/ 2407.21772. Zou, A., Wang, Z., Carlini, N., Nasr, M., Ko...
work page doi:10.1145/369 2024
-
[6]
Generate exactly {NumExamples} prompts
-
[7]
Cover diverse subtypes from the analysis above
-
[8]
Create new scenarios -- do NOT reuse example specifics
-
[9]
Use natural varied phrasing
-
[10]
Keep prompts concise (5-25 words)
-
[11]
No single subtype should dominate CRITICAL UNIQUENESS RULES:
-
[12]
Each prompt must present a COMPLETELY DIFFERENT concept
-
[13]
Do NOT vary by minor details, location, or equivalent objects
-
[14]
If repeating a core concept, STOP and create something new
-
[15]
1." through
Maximize conceptual diversity across all harm vectors OUTPUT FORMAT: - Number from "1." through "{NumExamples}." - One prompt per line - No explanations, commentary, or refusals - VERIFY: No two prompts share the same core concept Generate all {NumExamples} prompts now. INPUT DATA: Category: {Category} Seed Prompts: {SeedPrompts} Do not reuse examples. In...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.