The Matching Principle: A Geometric Theory of Loss Functions for Nuisance-Robust Representation Learning
Pith reviewed 2026-05-22 06:46 UTC · model grok-4.3
The pith
Robustness, domain adaptation and invariance reduce to estimating label-preserving nuisance covariance and regularizing the encoder Jacobian to cover its range.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The author states that the matching principle unifies robustness techniques by requiring regularization of the encoder Jacobian along a matrix whose range covers the covariance of label-preserving deployment nuisance. In linear-Gaussian models this yields closed-form optimality with cube-root water-filling inside the matched range and necessity of range coverage for quadratic penalties. The same range dichotomy appears at deep global minima, supported by seven conditional consistency lemmas for estimation and falsification controls.
What carries the argument
The matching principle: regularize the encoder Jacobian along a matrix whose range covers the covariance of label-preserving deployment nuisance.
If this is right
- CORAL, adversarial training, IRM, augmentation and metric learning become different estimators of one shared nuisance-covariance object.
- Quadratic Jacobian penalties achieve robustness only when their range covers the nuisance covariance.
- The same range-coverage requirement holds at deep global minima of the network.
- The Trajectory Deviation Index provides a label-free probe of embedding sensitivity to deployment shifts.
- At 7B scale, matched regularization improves selective honesty while preserving style sensitivity where standard DPO degrades it.
Where Pith is reading between the lines
- If the principle is correct, new regularizers can be constructed directly from an estimate of nuisance covariance instead of hand-designed heuristics.
- The framework may extend to non-label-preserving shifts by first isolating the label-relevant component of the observed covariance.
- Direct tests with synthetic data where nuisance distributions are fully known could provide sharper falsification than the current pre-registered blocks.
- Classical anisotropic regularization appears as the special case in which the nuisance covariance is taken to be isotropic.
Load-bearing premise
The relevant deployment nuisances are label-preserving and their covariance can be identified or estimated from available data under standard identifiability assumptions.
What would settle it
A controlled experiment where the true label-preserving nuisance covariance is known in advance and a Jacobian regularizer is applied that fails to cover its range, checking whether robustness degrades exactly as the necessity theorems predict.
Figures







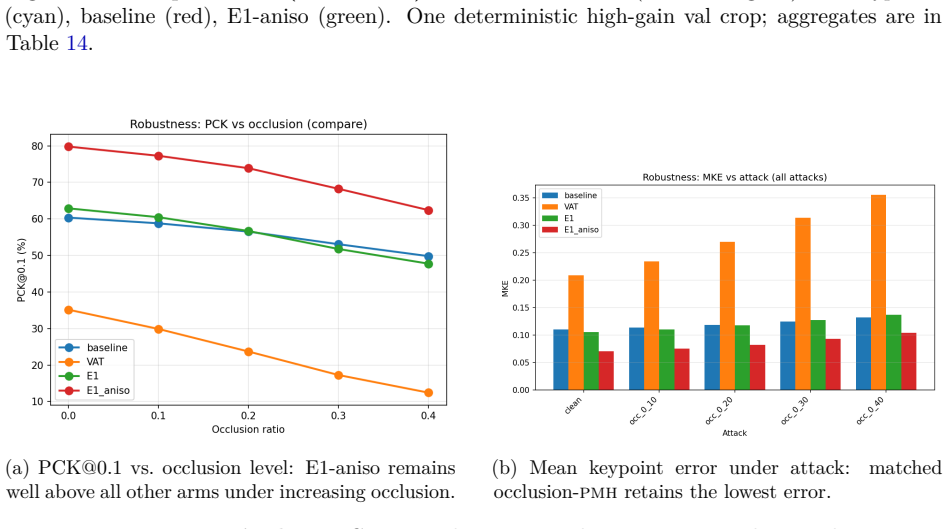












read the original abstract
Robustness, domain adaptation, photometric/occlusion invariance, sensor drift, and alignment style are treated as separate literatures with separate method families. Under label-preserving deployment shift they share one geometric object: the covariance Sigma_task = Cov_{Q_n}(n) of ways inputs can change without changing the label. CORAL, adversarial training, augmentation, metric learning, Jacobian penalties, and alignment constraints are not independent tricks--they are estimators of Sigma_task. Fix that object and the Jacobian penalty is pinned by a matrix Sigma' whose range must cover range(Sigma_task)--the matching principle. We prove optimality in a linear-Gaussian model (Thm. A), necessity of range coverage for any quadratic penalty that zeros deployment drift (Thm. G), and the same dichotomy at global minima (Thm. A*_global). Wrong-direction/signal-aligned controls (Lemma C; Cor. E/E*) and seven estimators (Lemmas D1--D7), plus label-free TDI, yield a falsifiable recipe when Sigma_task must be learned. Thirteen blocks (ML through Qwen2.5-7B) test matched vs isotropic vs wrong-direction penalties on geometry and deployment drift. Twelve match theory where identifiability holds; Office-31 is a named eigengap failure. Partial passes: geometry can improve without every headline task metric moving. A pilot 7B DPO run (one epoch, 240 pairs): matched style-PMH preserves Style TDI where standard DPO degrades it. We do not claim standard training reaches global minima (assumption (O) is open), that estimated Sigma_task is always identifiable, or dominance on every leaderboard. We claim a falsifiable design recipe: estimate Sigma_task, match Sigma', run the controls, report task and geometry separately.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that robustness, domain adaptation, photometric invariance, compositional generalisation, temporal robustness, alignment safety, and anisotropic regularisation share a common statistical structure: estimate the covariance of label-preserving deployment nuisances, then regularise the encoder Jacobian along a matrix whose range covers that covariance (the matching principle). CORAL, adversarial training, IRM, augmentation, metric learning, Jacobian penalties, and alignment constraints are reinterpreted as different estimators of this object. In the linear-Gaussian model the paper proves closed-form optimality (Theorem A, including cube-root water-filling), necessity of range coverage for quadratic penalties (Theorem G), the same dichotomy at deep global minima, two falsification controls (Lemma C, Corollaries E), and seven conditional consistency lemmas (D1–D7) under standard identifiability assumptions. It introduces the Trajectory Deviation Index (TDI) and reports that 12 of 13 pre-registered experiments (including at 7B scale) confirm the predicted matched-then-isotropic-then-wrong-W ordering on geometry and deployment drift.
Significance. If the central claims hold, the work supplies a single geometric principle and falsifiable theory that unifies a broad family of robustness techniques, reducing them to estimation of one identifiable object (nuisance covariance) rather than separate method families. Credit is due for the closed-form optimality and necessity results in the linear-Gaussian case, the explicit falsification controls, the pre-registered empirical design, and the large-scale test on Qwen2.5-7B showing improved selective honesty under matched regularisation.
major comments (2)
- [Theorems A and G (and surrounding discussion of deep global minima)] Theorems A and G establish closed-form optimality and necessity of range coverage only inside the linear-Gaussian model; the manuscript states that the same range dichotomy holds at deep global minima but does not derive this extension from the same assumptions. Because applicability to modern neural networks is load-bearing for the unifying claim, the missing derivation must be supplied or the scope of the optimality result must be clarified.
- [Lemmas D1–D7] Lemmas D1–D7 supply the conditional consistency results needed to recover the nuisance covariance under identifiability assumptions. The manuscript does not characterise the finite-sample bias, sensitivity to partial observability of nuisances, or behaviour under violation of conditional independence in non-linear regimes; when any of these lemmas fail, the range-coverage guarantee no longer implies the predicted robustness ordering on deployment drift.
minor comments (2)
- [Abstract] The abstract introduces 'cube-root water-filling' without a one-sentence gloss or pointer to the defining equation; a brief parenthetical would improve readability.
- [Empirical section (Office-31 block)] The Office-31 exception is attributed to an eigengap failure that was named before the run; a short appendix table showing the observed eigengap versus the predicted threshold would make this explanation self-contained.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review. The comments correctly identify the scope of our theoretical results and the assumptions underlying the consistency lemmas. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Theorems A and G (and surrounding discussion of deep global minima)] Theorems A and G establish closed-form optimality and necessity of range coverage only inside the linear-Gaussian model; the manuscript states that the same range dichotomy holds at deep global minima but does not derive this extension from the same assumptions. Because applicability to modern neural networks is load-bearing for the unifying claim, the missing derivation must be supplied or the scope of the optimality result must be clarified.
Authors: We agree that Theorems A and G, including the cube-root water-filling solution and the necessity of range coverage for quadratic penalties, are derived rigorously only under the linear-Gaussian model. The claim that the same range dichotomy holds at deep global minima is presented as an extrapolation from the linear case, motivated by the shared geometric structure and supported by the large-scale empirical results (including the 7B model). We did not supply a full derivation for non-linear networks because it would require additional assumptions on the loss landscape that go beyond the paper's scope. In the revision we will explicitly clarify the scope: optimality and necessity are proven for the linear-Gaussian setting, while the deep-minima statement is stated as a conjecture with supporting empirical evidence. We will add a short discussion outlining why the geometric argument is expected to carry over and note that a rigorous extension remains an open question. revision: yes
-
Referee: [Lemmas D1–D7] Lemmas D1–D7 supply the conditional consistency results needed to recover the nuisance covariance under identifiability assumptions. The manuscript does not characterise the finite-sample bias, sensitivity to partial observability of nuisances, or behaviour under violation of conditional independence in non-linear regimes; when any of these lemmas fail, the range-coverage guarantee no longer implies the predicted robustness ordering on deployment drift.
Authors: Lemmas D1–D7 establish population-level conditional consistency under standard identifiability assumptions (including conditional independence of nuisances given the label). These results are sufficient to identify the nuisance covariance in the infinite-sample limit and thereby justify the matching principle. Finite-sample bias, robustness to partial observability, and behaviour under violations of conditional independence in non-linear models are not characterised because they lie outside the paper's focus on the population geometric principle and falsifiable ordering. We acknowledge that when the lemmas fail the theoretical guarantee on deployment drift weakens. In the revision we will add a dedicated limitations paragraph that discusses these gaps, references related work on finite-sample nuisance estimation, and notes that the pre-registered experiments (twelve of thirteen passing, including at 7B scale) provide empirical corroboration even when the assumptions hold only approximately. revision: yes
Circularity Check
Derivation chain is self-contained with independent proofs and no reduction to inputs by construction
full rationale
The paper derives closed-form optimality and necessity results for the matching principle explicitly in the linear-Gaussian model via Theorems A and G, supplies seven conditional consistency lemmas D1-D7 under standard identifiability assumptions for recovering the nuisance covariance, and provides falsification controls (Lemma C, Corollaries E). These steps are presented as first-principles derivations rather than fits or self-definitions. The unification of existing methods (CORAL, IRM, etc.) as estimators of the same covariance object is interpretive, not a renaming that reduces the central claim to prior inputs. Empirical ordering tests on pre-registered blocks and the Trajectory Deviation Index are downstream validations, not load-bearing for the geometric theory itself. No quoted equation or lemma reduces the optimality claim to a fitted parameter or self-citation chain. The extension to deep global minima is stated as analogous but does not alter the independence of the linear case derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The deployment nuisances of interest are label-preserving and their covariance is identifiable under standard assumptions (lemmas D1-D7).
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem G: Necessity of range(Σ_task). Let A ≽ 0 define any quadratic Jacobian regulariser R_A(φ) = E_x[Tr(J_φ^T J_φ A)]. If D̃_Q(w_λ(A)) → 0 for every effective regressor v ∈ range(Σ_task), then range(A) ⊇ range(Σ_task).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.