Social Structure Matters in 3D Human-Human Interaction Generation
Pith reviewed 2026-06-26 00:24 UTC · model grok-4.3
The pith
Text-to-3D human-human interaction requires an LLM to first recover social phases and roles before motion generation can succeed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HHI generation is a social structure modeling and grounding problem. The LLM planner converts implicit interaction semantics into motion-aligned social supervision by decomposing interactions into phases, assigning partner-aware actor roles, and aligning them with motion sequence. The motion executor grounds the planned social structure into coordinated two-person motion by adapting a pretrained solo motion model with LoRA, previous-phase self-conditioning, and ego-relative partner conditioning.
What carries the argument
The planner-executor paradigm (Solo-to-Social framework) in which an LLM decomposes text into phased, role-assigned supervision that an adapted motion model then realizes as partner-aware 3D sequences.
If this is right
- Generated interactions exhibit higher phase consistency across the full sequence.
- Actor roles remain aligned with the original text description throughout the motion.
- Partner conditioning produces measurable improvements in inter-actor spatial and temporal coordination.
- The same pretrained solo motion model can be reused for social tasks once conditioned on the planned structure.
Where Pith is reading between the lines
- The planner-executor split may transfer to other multi-agent generation settings that require both high-level organization and low-level physical control.
- Extending the planner to handle more than two actors would require only additional role-assignment logic while reusing the same executor adaptations.
- Datasets that annotate phase boundaries and role switches would directly test whether the LLM planning step is the current performance bottleneck.
Load-bearing premise
LLMs can recover phase decompositions and partner-aware roles from text that translate into physically plausible, interaction-aware 3D motion when fed to the adapted executor.
What would settle it
A benchmark run in which LLM-generated phase and role plans produce two-person motions that violate coordination metrics or physical plausibility on existing HHI test sets.
Figures

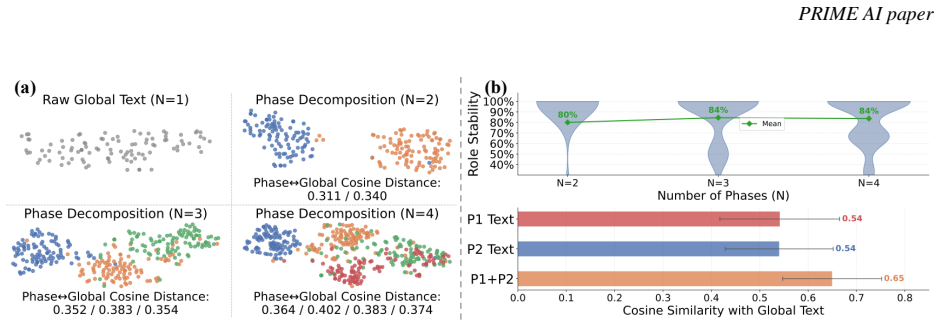

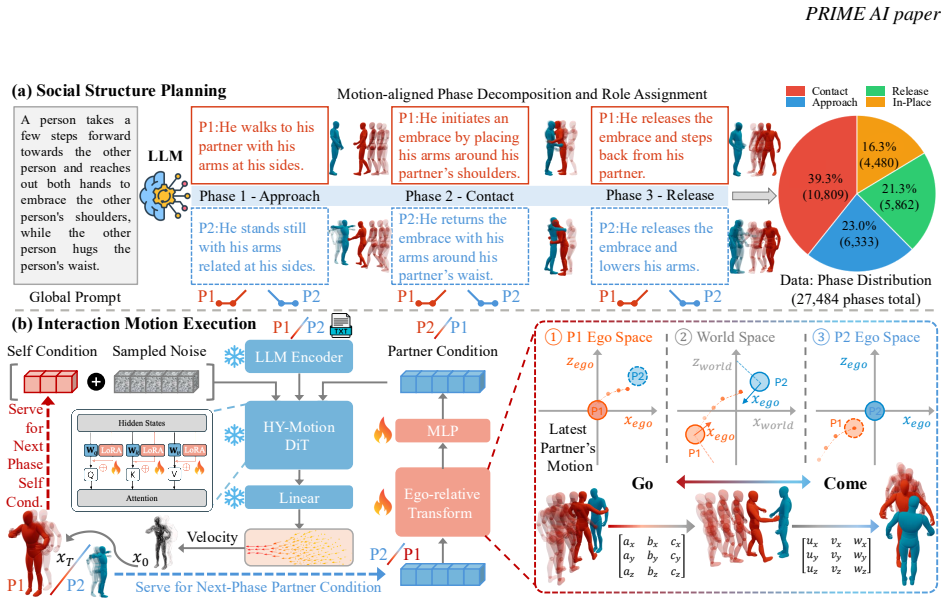



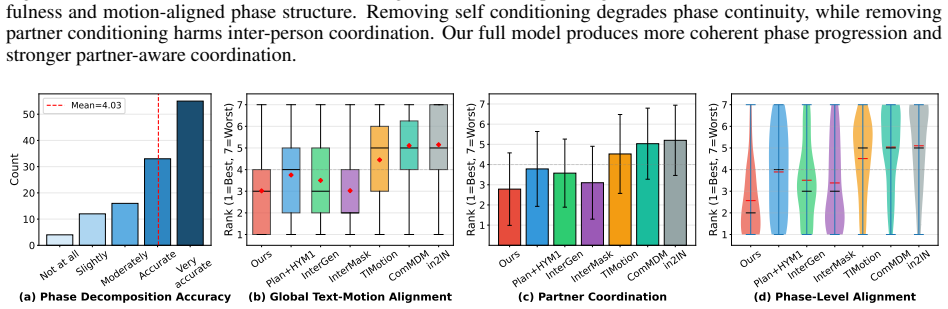
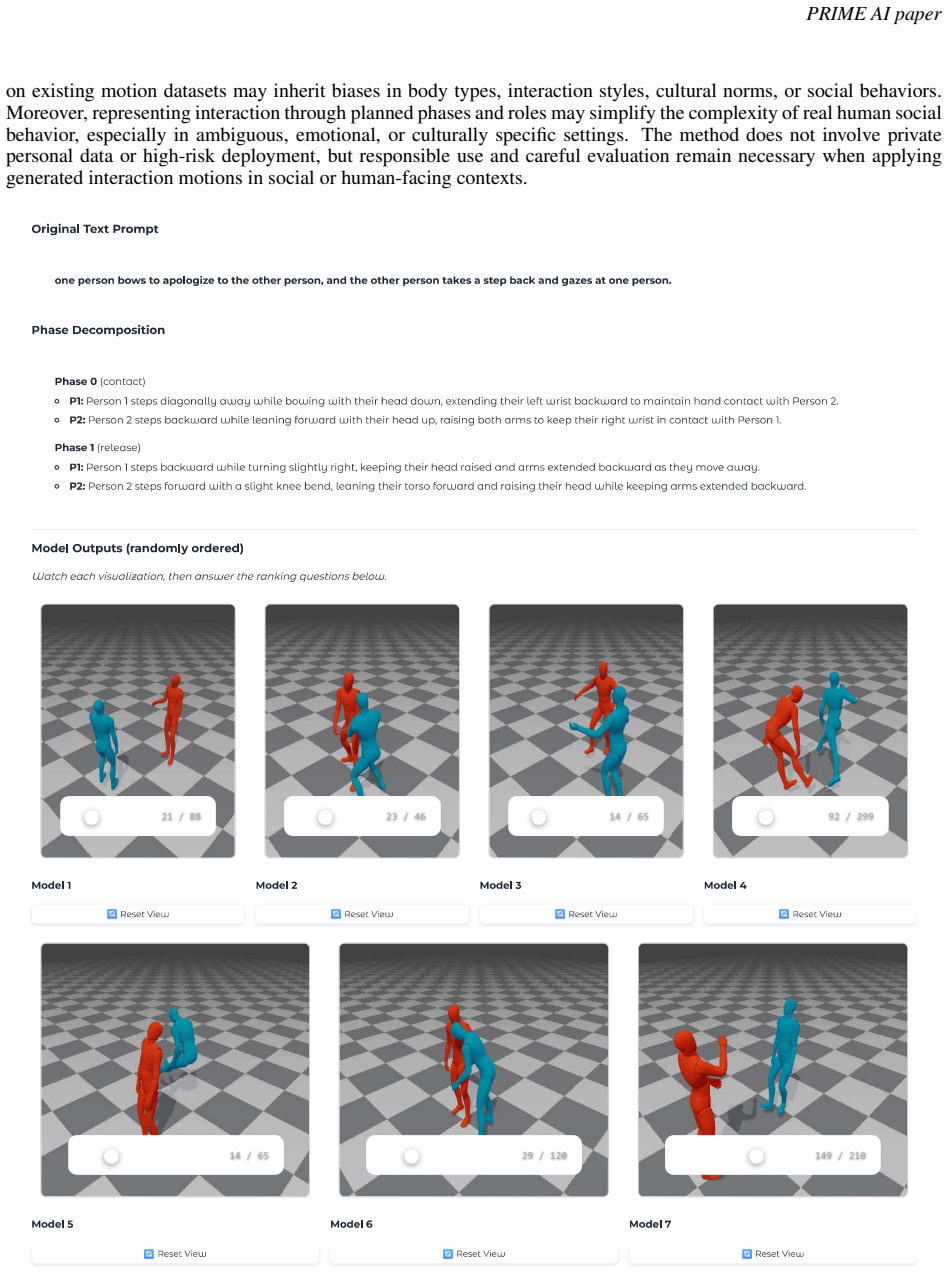

read the original abstract
Although text-to-motion generation has achieved strong progress in synthesizing realistic single-person motions from language, extending it to text-driven 3D human-human interaction (HHI) remains non-trivial, as HHI requires modeling the underlying \textbf{social structure} that governs phase progression, actor roles, and inter-actor coordination. In this paper, we formulate HHI generation as a social structure modeling and grounding problem: the model must first infer how an interaction unfolds and how the two actors coordinate their roles, and then realize this structure as continuous, physically plausible, and partner-aware 3D motion. To study how such structure should be modeled, we first examine the capability boundary of large language models (LLMs) for HHI generation. Our analysis shows that LLMs can \textit{think} by recovering phase decompositions and partner-aware roles, but cannot directly \textit{move}, as they fail to generate dynamic, physically plausible, and interaction-aware motion. This motivates our planner-executor paradigm, \textbf{Think with LLM, Move with Motion Skill}. The LLM planner converts implicit interaction semantics into motion-aligned social supervision by decomposing interactions into phases, assigning partner-aware actor roles, and aligning them with motion sequence. The motion executor then grounds the planned social structure into coordinated two-person motion by adapting a pretrained solo motion model with LoRA, previous-phase self-conditioning, and ego-relative partner conditioning. Together, our Solo-to-Social framework bridges social organization and motion realization, producing 3D HHI with improved phase consistency, role alignment, and partner-aware coordination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that text-to-3D human-human interaction (HHI) generation requires explicit modeling of social structure (phase progression, actor roles, inter-actor coordination). It first analyzes the capability boundary of LLMs, finding that they can recover phase decompositions and partner-aware roles from text but cannot directly generate dynamic, physically plausible motion. This motivates a planner-executor framework ('Think with LLM, Move with Motion Skill'): the LLM planner produces motion-aligned social supervision via phase decomposition, role assignment, and sequence alignment; the motion executor then grounds this into coordinated two-person motion by adapting a pretrained solo motion model via LoRA, previous-phase self-conditioning, and ego-relative partner conditioning. The resulting Solo-to-Social approach is reported to yield improved phase consistency, role alignment, and partner-aware coordination.
Significance. If the quantitative results and ablations hold, the work provides a principled separation between high-level social reasoning (handled by LLMs) and low-level motion realization (handled by adapted generative models), addressing a clear gap in extending single-person text-to-motion methods to interactive settings. The explicit planner-executor design and the reported LLM capability analysis constitute a concrete, testable contribution that could influence subsequent HHI generation research.
major comments (2)
- [§3] §3 (LLM Capability Boundary Analysis): The central motivation for the planner-executor split rests on the claim that LLMs reliably recover accurate phase decompositions and partner-aware roles from text. No quantitative metrics (e.g., phase-boundary F1, role-assignment accuracy, or inter-annotator agreement against human labels) are referenced in the provided description of this analysis; without such numbers the reliability of the generated social supervision cannot be assessed and error propagation to the executor remains unquantified.
- [§5] §5 (Motion Executor Experiments): The abstract and paradigm description assert improved phase consistency and partner-aware coordination, yet the soundness assessment notes the absence of reported error metrics, ablation tables, or baseline comparisons (e.g., direct fine-tuning without planner supervision). If these results exist in later sections they must be explicitly tied back to the planner output quality to substantiate the load-bearing claim that the social-structure supervision is what drives the gains.
minor comments (1)
- [§4.2] Notation for 'ego-relative partner conditioning' and 'previous-phase self-conditioning' should be formalized with explicit equations or pseudocode in the executor section to clarify how these signals are injected into the adapted diffusion or autoregressive backbone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify how to strengthen the quantitative grounding of our claims. We address the two major comments point-by-point below and will revise the manuscript to incorporate the suggested metrics and explicit linkages.
read point-by-point responses
-
Referee: [§3] §3 (LLM Capability Boundary Analysis): The central motivation for the planner-executor split rests on the claim that LLMs reliably recover accurate phase decompositions and partner-aware roles from text. No quantitative metrics (e.g., phase-boundary F1, role-assignment accuracy, or inter-annotator agreement against human labels) are referenced in the provided description of this analysis; without such numbers the reliability of the generated social supervision cannot be assessed and error propagation to the executor remains unquantified.
Authors: We agree that the current presentation of the LLM analysis in §3 is primarily qualitative (via illustrative examples of phase decomposition and role assignment). This leaves the reliability of the generated supervision unquantified. In the revised manuscript we will add quantitative metrics against human annotations, including phase-boundary F1, role-assignment accuracy, and inter-annotator agreement, to allow direct assessment of supervision quality and error propagation. revision: yes
-
Referee: [§5] §5 (Motion Executor Experiments): The abstract and paradigm description assert improved phase consistency and partner-aware coordination, yet the soundness assessment notes the absence of reported error metrics, ablation tables, or baseline comparisons (e.g., direct fine-tuning without planner supervision). If these results exist in later sections they must be explicitly tied back to the planner output quality to substantiate the load-bearing claim that the social-structure supervision is what drives the gains.
Authors: We acknowledge that the experimental section would benefit from more explicit reporting and linkage. While ablations and baseline comparisons are present, we will revise §5 to (i) report additional error metrics, (ii) include a direct fine-tuning baseline without planner supervision, and (iii) add explicit analysis correlating planner output quality with downstream motion gains, thereby directly substantiating that the social-structure supervision drives the observed improvements. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper formulates HHI generation as a planner-executor paradigm justified by an empirical analysis of LLM capabilities (recovering phases/roles but failing at direct motion generation). The LLM planner produces social supervision, while the motion executor adapts external pretrained solo models via LoRA and conditioning. No equations, fitted parameters, or predictions are present that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The derivation relies on external pretrained components and stated capability boundaries without self-referential loops or renaming of known results, rendering it self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can recover phase decompositions and partner-aware roles from implicit interaction semantics
invented entities (1)
-
social structure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on human inter- action motion generation.International Journal of Computer Vision, 134(3):113, 2026
Kewei Sui, Anindita Ghosh, Inwoo Hwang, Bing Zhou, Jian Wang, and Chuan Guo. A survey on human inter- action motion generation.International Journal of Computer Vision, 134(3):113, 2026
2026
-
[2]
Text-driven motion generation: Overview, challenges and directions
Ali Rida Sahili, Najett Neji, and Hedi Tabia. Text-driven motion generation: Overview, challenges and directions. arXiv preprint arXiv:2505.09379, 2025
arXiv 2025
-
[3]
3d human interaction generation: A survey.arXiv preprint arXiv:2503.13120, 2025
Siyuan Fan, Wenke Huang, Xiantao Cai, and Bo Du. 3d human interaction generation: A survey.arXiv preprint arXiv:2503.13120, 2025
arXiv 2025
-
[4]
Tencent Hunyuan 3D Digital Human Team. Hy-motion 1.0: Scaling flow matching models for text-to-motion generation.arXiv preprint arXiv:2512.23464, 2025
arXiv 2025
-
[5]
Make-an-animation: Large-scale text-conditional 3d human motion generation
Samaneh Azadi, Akbar Shah, Thomas Hayes, Devi Parikh, and Sonal Gupta. Make-an-animation: Large-scale text-conditional 3d human motion generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15039–15048, 2023
2023
-
[6]
Wenlong Liang, Rui Zhou, Yang Ma, Bing Zhang, Songlin Li, Yijia Liao, and Ping Kuang. Large model em- powered embodied ai: A survey on decision-making and embodied learning.arXiv preprint arXiv:2508.10399, 2025
arXiv 2025
-
[7]
Di Wu, Xian Wei, Guang Chen, Hao Shen, Xiangfeng Wang, Wenhao Li, and Bo Jin. Generative multi-agent collaboration in embodied ai: A systematic review.arXiv preprint arXiv:2502.11518, 2025
arXiv 2025
-
[8]
Long-term interactions with social robots: Trends, insights, and recommendations.ACM Transactions on Human-Robot Interaction, 14(3):1–42, 2025
Kayla Matheus, Rebecca Ramnauth, Brian Scassellati, and Nicole Salomons. Long-term interactions with social robots: Trends, insights, and recommendations.ACM Transactions on Human-Robot Interaction, 14(3):1–42, 2025
2025
-
[9]
in2in: Leveraging individual information to generate human interactions
Pablo Ruiz-Ponce, German Barquero, Cristina Palmero, Sergio Escalera, and Jos ´e Garc´ıa-Rodr´ıguez. in2in: Leveraging individual information to generate human interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 1941–1951, June 2024
1941
-
[10]
Mixer- mdm: Learnable composition of human motion diffusion models
Pablo Ruiz-Ponce, German Barquero, Cristina Palmero, Sergio Escalera, and Jos ´e Garc´ıa-Rodr´ıguez. Mixer- mdm: Learnable composition of human motion diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12380–12390, 2025
2025
-
[11]
Human motion diffusion as a generative prior
Yoni Shafir, Guy Tevet, Roy Kapon, and Amit Haim Bermano. Human motion diffusion as a generative prior. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[12]
Intergen: Diffusion-based multi-human motion generation under complex interactions.International Journal of Computer Vision, pages 1–21, 2024
Han Liang, Wenqian Zhang, Wenxuan Li, Jingyi Yu, and Lan Xu. Intergen: Diffusion-based multi-human motion generation under complex interactions.International Journal of Computer Vision, pages 1–21, 2024
2024
-
[13]
Intermask: 3d human interaction generation via collaborative masked modeling
Muhammad Gohar Javed, Chuan Guo, Li Cheng, and Xingyu Li. Intermask: 3d human interaction generation via collaborative masked modeling. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[14]
Timotion: Temporal and interactive framework for efficient human-human motion generation
Yabiao Wang, Shuo Wang, Jiangning Zhang, Ke Fan, Jiafu Wu, Zhucun Xue, and Yong Liu. Timotion: Temporal and interactive framework for efficient human-human motion generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7169–7178, 2025
2025
-
[15]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
Pith/arXiv arXiv 2026
-
[16]
A human-in-the-loop approach to robot action replanning through llm common-sense reasoning.IEEE Robotics and Automation Letters, 2025
Elena Merlo, Marta Lagomarsino, and Arash Ajoudani. A human-in-the-loop approach to robot action replanning through llm common-sense reasoning.IEEE Robotics and Automation Letters, 2025
2025
-
[17]
Henry Peng Zou, Wei-Chieh Huang, Yaozu Wu, Yankai Chen, Chunyu Miao, Hoang Nguyen, Yue Zhou, Weizhi Zhang, Liancheng Fang, Langzhou He, et al. Llm-based human-agent collaboration and interaction systems: A survey.arXiv preprint arXiv:2505.00753, 2025
Pith/arXiv arXiv 2025
-
[18]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: A skinned multi-person linear model.ACM Trans. Graphics (Proc. SIGGRAPH Asia), 34(6):248:1–248:16, October 2015
2015
-
[19]
Human motion generation: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(4):2430–2449, 2023
Wentao Zhu, Xiaoxuan Ma, Dongwoo Ro, Hai Ci, Jinlu Zhang, Jiaxin Shi, Feng Gao, Qi Tian, and Yizhou Wang. Human motion generation: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(4):2430–2449, 2023
2023
-
[20]
Aliasghar Khani, Arianna Rampini, Bruno Roy, Larasika Nadela, Noa Kaplan, Evan Atherton, Derek Cheung, and Jacky Bibliowicz. Motion generation: A survey of generative approaches and benchmarks.arXiv preprint arXiv:2507.05419, 2025. 10 PRIME AI paper
arXiv 2025
-
[21]
The language of motion: Unifying verbal and non-verbal language of 3d human motion
Changan Chen, Juze Zhang, Shrinidhi K Lakshmikanth, Yusu Fang, Ruizhi Shao, Gordon Wetzstein, Li Fei-Fei, and Ehsan Adeli. The language of motion: Unifying verbal and non-verbal language of 3d human motion. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 6200–6211, 2025
2025
-
[22]
Ls-gan: Human motion synthesis with latent-space gans
Avinash Amballa, Gayathri Akkinapalli, and Vinitra Muralikrishnan. Ls-gan: Human motion synthesis with latent-space gans. InProceedings of the Winter Conference on Applications of Computer Vision, pages 326–335, 2025
2025
-
[23]
Learning diverse stochastic human-action generators by learning smooth latent transitions
Zhenyi Wang, Ping Yu, Yang Zhao, Ruiyi Zhang, Yufan Zhou, Junsong Yuan, and Changyou Chen. Learning diverse stochastic human-action generators by learning smooth latent transitions. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 12281–12288, 2020
2020
-
[24]
Action2motion: Conditioned generation of 3d human motions
Chuan Guo, Xinxin Zuo, Sen Wang, Shihao Zou, Qingyao Sun, Annan Deng, Minglun Gong, and Li Cheng. Action2motion: Conditioned generation of 3d human motions. InProceedings of the 28th ACM international conference on multimedia, pages 2021–2029, 2020
2021
-
[25]
Attt2m: Text-driven human motion generation with multi-perspective attention mechanism
Chongyang Zhong, Lei Hu, Zihao Zhang, and Shihong Xia. Attt2m: Text-driven human motion generation with multi-perspective attention mechanism. InProceedings of the IEEE/CVF international conference on computer vision, pages 509–519, 2023
2023
-
[26]
Generating human motion from textual descriptions with discrete representations
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Yong Zhang, Hongwei Zhao, Hongtao Lu, Xi Shen, and Ying Shan. Generating human motion from textual descriptions with discrete representations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14730–14740, 2023
2023
-
[27]
Actformer: A gan-based transformer towards general action-conditioned 3d human motion generation
Liang Xu, Ziyang Song, Dongliang Wang, Jing Su, Zhicheng Fang, Chenjing Ding, Weihao Gan, Yichao Yan, Xin Jin, Xiaokang Yang, et al. Actformer: A gan-based transformer towards general action-conditioned 3d human motion generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2228–2238, 2023
2023
-
[28]
Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36, 2024
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[29]
Yuan Wang, Di Huang, Yaqi Zhang, Wanli Ouyang, Jile Jiao, Xuetao Feng, Yan Zhou, Pengfei Wan, Shixi- ang Tang, and Dan Xu. Motiongpt-2: A general-purpose motion-language model for motion generation and understanding.arXiv preprint arXiv:2410.21747, 2024
Pith/arXiv arXiv 2024
-
[30]
Motiongpt3: Human motion as a second modality.arXiv preprint arXiv:2506.24086, 2025
Bingfan Zhu, Biao Jiang, Sunyi Wang, Shixiang Tang, Tao Chen, Linjie Luo, Youyi Zheng, and Xin Chen. Motiongpt3: Human motion as a second modality.arXiv preprint arXiv:2506.24086, 2025
arXiv 2025
-
[31]
Human motion diffusion model.arXiv preprint arXiv:2209.14916, 2022
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion diffusion model.arXiv preprint arXiv:2209.14916, 2022
Pith/arXiv arXiv 2022
-
[32]
Guided motion diffusion for controllable human motion synthesis
Korrawe Karunratanakul, Konpat Preechakul, Supasorn Suwajanakorn, and Siyu Tang. Guided motion diffusion for controllable human motion synthesis. InProceedings of the IEEE/CVF international conference on computer vision, pages 2151–2162, 2023
2023
-
[33]
Tm2d: Bimodality driven 3d dance generation via music-text integration
Kehong Gong, Dongze Lian, Heng Chang, Chuan Guo, Zihang Jiang, Xinxin Zuo, Michael Bi Mi, and Xinchao Wang. Tm2d: Bimodality driven 3d dance generation via music-text integration. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9942–9952, 2023
2023
-
[34]
Motion- diffuse: Text-driven human motion generation with diffusion model.IEEE transactions on pattern analysis and machine intelligence, 46(6):4115–4128, 2024
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motion- diffuse: Text-driven human motion generation with diffusion model.IEEE transactions on pattern analysis and machine intelligence, 46(6):4115–4128, 2024
2024
-
[35]
Tm2t: Stochastic and tokenized modeling for the recipro- cal generation of 3d human motions and texts
Chuan Guo, Xinxin Zuo, Sen Wang, and Li Cheng. Tm2t: Stochastic and tokenized modeling for the recipro- cal generation of 3d human motions and texts. InEuropean Conference on Computer Vision, pages 580–597. Springer, 2022
2022
-
[36]
Tmr: Text-to-motion retrieval using contrastive 3d human motion synthesis
Mathis Petrovich, Michael J Black, and G ¨ul Varol. Tmr: Text-to-motion retrieval using contrastive 3d human motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9488– 9497, 2023
2023
-
[37]
Understanding human-human interactions: a survey.arXiv preprint arXiv:1808.00022, 2, 2018
Alexandros Stergiou and Ronald Poppe. Understanding human-human interactions: a survey.arXiv preprint arXiv:1808.00022, 2, 2018
arXiv 2018
-
[38]
Regennet: Towards human action-reaction synthesis
Liang Xu, Yizhou Zhou, Yichao Yan, Xin Jin, Wenhan Zhu, Fengyun Rao, Xiaokang Yang, and Wenjun Zeng. Regennet: Towards human action-reaction synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1759–1769, 2024
2024
-
[39]
Bailando: 3d dance generation by actor-critic gpt with choreographic memory
Li Siyao, Weijiang Yu, Tianpei Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. Bailando: 3d dance generation by actor-critic gpt with choreographic memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11050–11059, 2022. 11 PRIME AI paper
2022
-
[40]
Dance with you: The diversity controllable dancer generation via diffusion models
Siyue Yao, Mingjie Sun, Bingliang Li, Fengyu Yang, Junle Wang, and Ruimao Zhang. Dance with you: The diversity controllable dancer generation via diffusion models. InProceedings of the 31st ACM International Conference on Multimedia, pages 8504–8514, 2023
2023
-
[41]
Duolando: Follower gpt with off-policy reinforcement learning for dance accompaniment
Li Siyao, Tianpei Gu, Zhitao Yang, Zhengyu Lin, Ziwei Liu, Henghui Ding, Lei Yang, and Chen Change Loy. Duolando: Follower gpt with off-policy reinforcement learning for dance accompaniment. InThe Twelfth Inter- national Conference on Learning Representations, 2024
2024
-
[42]
Ronghui Li, Youliang Zhang, Yachao Zhang, Yuxiang Zhang, Mingyang Su, Jie Guo, Ziwei Liu, Yebin Liu, and Xiu Li. Interdance: Reactive 3d dance generation with realistic duet interactions.arXiv preprint arXiv:2412.16982, 2024
arXiv 2024
-
[43]
Think then react: Towards unconstrained action-to-reaction motion generation
Wenhui Tan, Boyuan Li, Chuhao Jin, Wenbing Huang, Xiting Wang, and Ruihua Song. Think then react: Towards unconstrained action-to-reaction motion generation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[44]
Ready- to-react: Online reaction policy for two-character interaction generation
Zhi Cen, Huaijin Pi, Sida Peng, Qing Shuai, Yujun Shen, Hujun Bao, Xiaowei Zhou, and Ruizhen Hu. Ready- to-react: Online reaction policy for two-character interaction generation. InICLR, 2025
2025
-
[45]
Remos: 3d motion-conditioned reaction synthesis for two-person interactions
Anindita Ghosh, Rishabh Dabral, Vladislav Golyanik, Christian Theobalt, and Philipp Slusallek. Remos: 3d motion-conditioned reaction synthesis for two-person interactions. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[46]
Interaction transformer for human reaction generation.IEEE Transactions on Multimedia, 25:8842–8854, 2023
Baptiste Chopin, Hao Tang, Naima Otberdout, Mohamed Daoudi, and Nicu Sebe. Interaction transformer for human reaction generation.IEEE Transactions on Multimedia, 25:8842–8854, 2023
2023
-
[47]
Inter-x: Towards versatile human-human interaction analysis
Liang Xu, Xintao Lv, Yichao Yan, Xin Jin, Shuwen Wu, Congsheng Xu, Yifan Liu, Yizhou Zhou, Fengyun Rao, Xingdong Sheng, et al. Inter-x: Towards versatile human-human interaction analysis. InCVPR, pages 22260–22271, 2024
2024
-
[48]
Pablo Ruiz-Ponce, Sergio Escalera, Jos ´e Garc´ıa-Rodr´ıguez, Jiankang Deng, and Rolandos Alexandros Potamias. Interact2ar: Full-body human-human interaction generation via autoregressive diffusion models.arXiv preprint arXiv:2512.19692, 2025
arXiv 2025
-
[49]
A unified framework for motion reasoning and generation in human interaction
Jeongeun Park, Sungjoon Choi, and Sangdoo Yun. A unified framework for motion reasoning and generation in human interaction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10698–10707, 2025
2025
-
[50]
Aman Goel, Qianhui Men, and Edmond S. L. Ho. Interaction Mix and Match: Synthesizing Close Interaction using Conditional Hierarchical GAN with Multi-Hot Class Embedding.Computer Graphics Forum, 2022
2022
-
[51]
Intermamba: Efficient human-human interaction generation with adaptive spatio-temporal mamba.IEEE Transactions on Visualization and Computer Graphics, 2025
Zizhao Wu, Yingying Sun, Yiming Chen, Xiaoling Gu, Ruyu Liu, and Jiazhou Chen. Intermamba: Efficient human-human interaction generation with adaptive spatio-temporal mamba.IEEE Transactions on Visualization and Computer Graphics, 2025
2025
-
[52]
Zichen Geng, Zeeshan Hayder, Bo Miao, Jian Liu, Wei Liu, and Ajmal Mian. Disentangled hierarchical vae for 3d human-human interaction generation.arXiv preprint arXiv:2603.00144, 2026
arXiv 2026
-
[53]
Zichen Geng, Zeeshan Hayder, Wei Liu, Hesheng Wang, and Ajmal Mian. Armflow: Autoregressive meanflow for online 3d human reaction generation.arXiv preprint arXiv:2512.16234, 2025
arXiv 2025
-
[54]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5152–5161, 2022
2022
-
[55]
not accurate at all
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3D hands, face, and body from a single image. InProceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 10975–10985, 2019. 12 PRIME AI paper A Metric Details •FID.Fr ´echet Inceptio...
2019
-
[56]
approach: one or both people move closer or prepare to interact before contact
-
[57]
contact: physical contact, object transfer, blocking, supporting, or direct interaction occurs
-
[58]
release: physical contact or interaction ends and one or both people withdraw or return to neutral
-
[59]
Instructions:
in-place: the interaction happens mostly without clear approach/contact/release progression, or the actors coordinate while staying near their positions. Instructions:
-
[60]
Decompose the global prompt into 1 to 4 temporally ordered phases
-
[61]
Assign exactly one phase type to each phase: approach, contact, release, or in-place
-
[62]
For each phase, write one action sentence for P1 and one action sentence for P2
-
[63]
The P1 and P2 actions must be partner-aware
-
[64]
Do not invent unrelated actions
Preserve the semantics of the global prompt. Do not invent unrelated actions
-
[65]
If the prompt implies asymmetric roles, make them explicit, such as initiator/receiver, attacker/defender, giver/taker, or supporter/assisted person
-
[66]
If there is no clear movement toward or away from the partner, use in-place
-
[67]
<INPUT_GLOBAL_PROMPT>
Keep each action concise, physically plausible, and suitable for motion generation. Output format: Phase 1: (<phase_type>) P1 action: <one sentence describing Person 1’s action> P2 action: <one sentence describing Person 2’s action> Phase 2: (<phase_type>) P1 action: <one sentence describing Person 1’s action> P2 action: <one sentence describing Person 2’...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.