IndexMem: Learned KV-Cache Eviction with Latent Memory for Long-Context LLM Inference
Pith reviewed 2026-06-29 22:00 UTC · model grok-4.3
The pith
A learned indexer predicts which KV entries to retain and a latent memory recovers information from evicted tokens for long-context LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
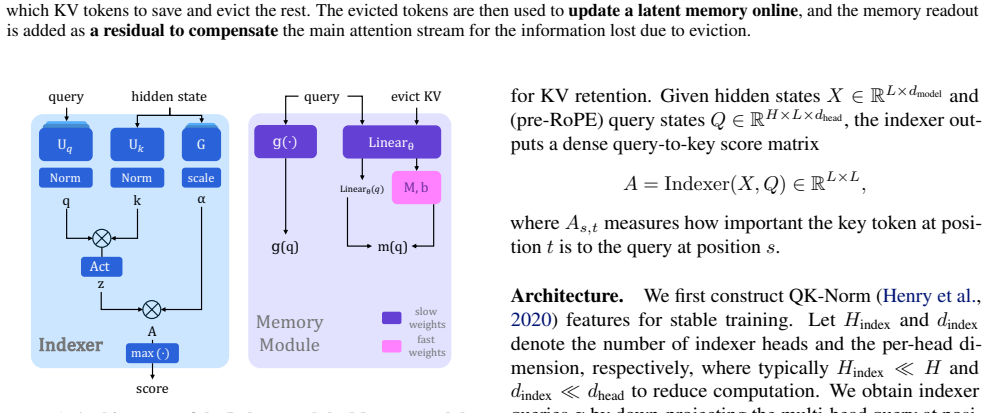
The central claim is that a learnable importance predictor for KV pairs, paired with a lightweight latent memory module that compresses evicted tokens into an online-updated compact state and supplies residual readouts, enables accurate long-context inference under a strictly bounded KV budget.
What carries the argument
The learnable indexer that scores KV importance together with the lightweight latent memory module that compresses evicted tokens and provides residual attention contributions.
If this is right
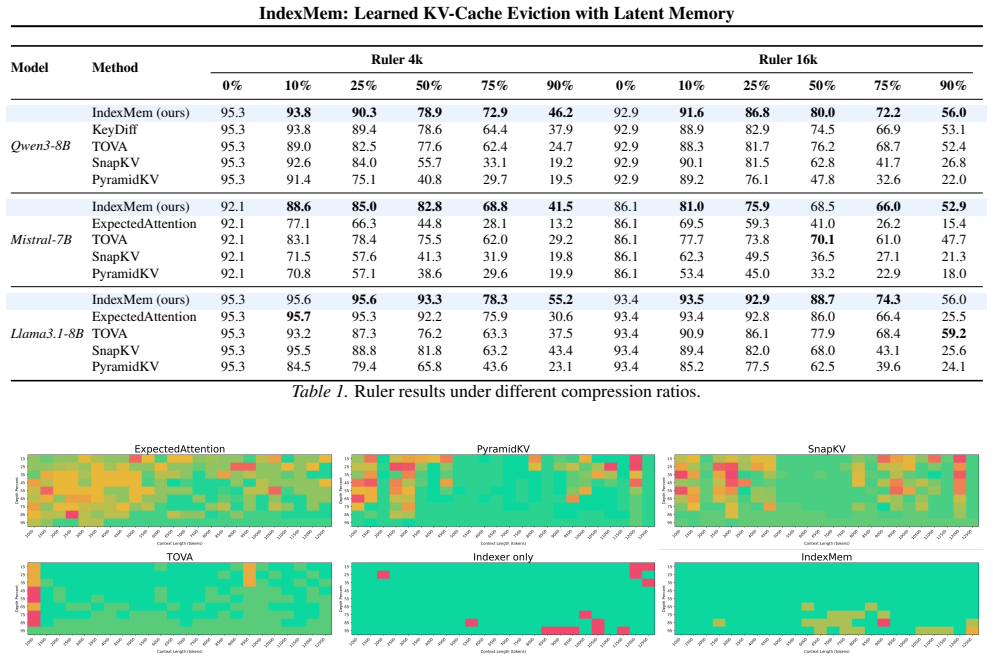
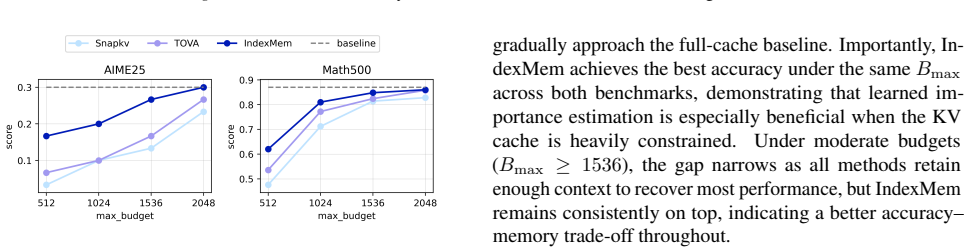
- Consistent gains on RULER at 4K and 16K contexts across Qwen, Mistral, and Llama families, reaching up to 25 points under aggressive eviction.
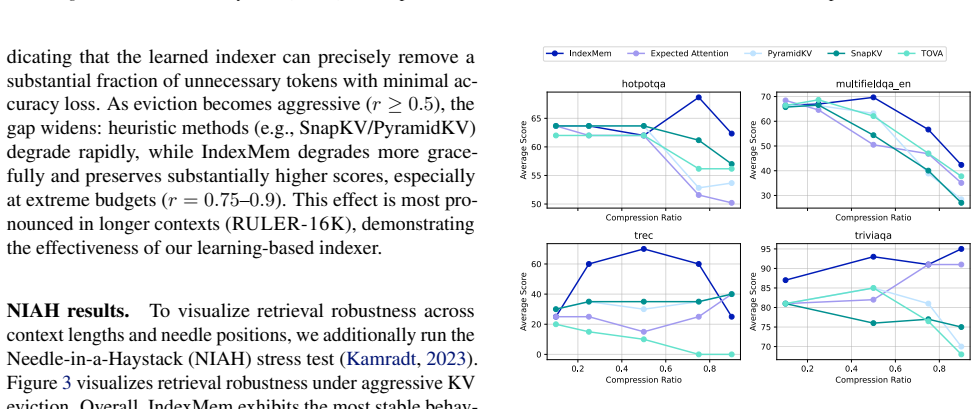
- More stable retrieval on Needle-in-a-Haystack tasks.
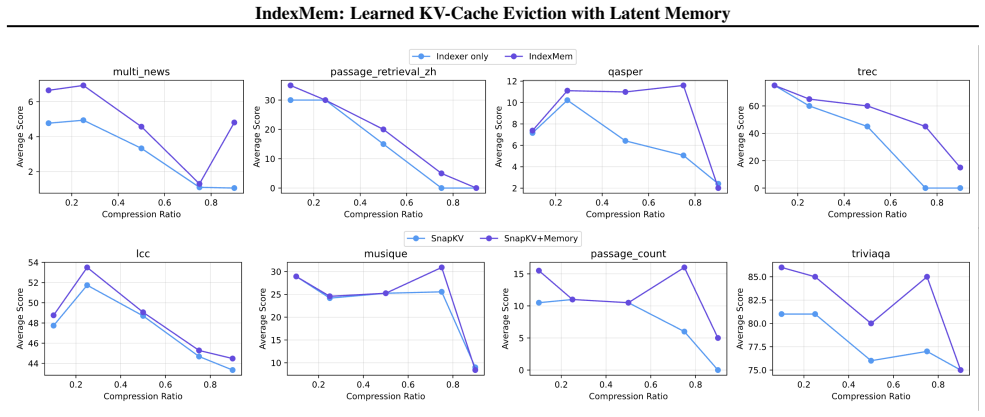
- Higher scores on LongBench and better compression curves than existing eviction policies.
Where Pith is reading between the lines
- If the latent memory overhead remains small, serving costs for long-context applications could drop without retraining the base model.
- The same compression idea might apply to other growing memory structures such as past activations in recurrent architectures.
- End-to-end joint training of the indexer with the base LLM could further reduce the need for separate eviction heuristics.
Load-bearing premise
The latent memory can encode and later retrieve enough information from the evicted tokens to make up for their absence in the attention calculation.
What would settle it
An ablation that applies the same learned eviction policy but removes the latent memory module and measures whether accuracy falls back to the level of prior heuristic eviction methods on RULER or Needle-in-a-Haystack.
Figures

read the original abstract
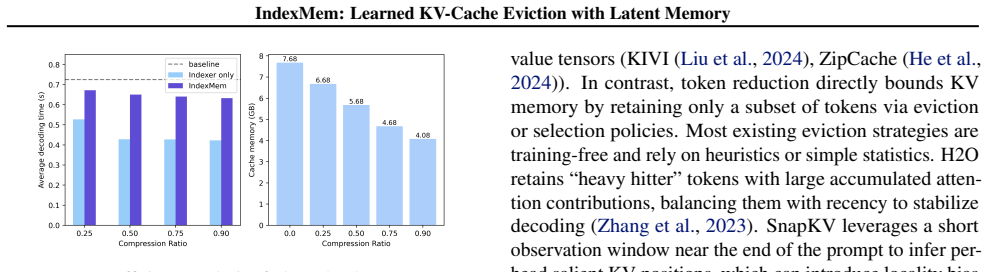
Large Language Models (LLMs) are increasingly expected to operate over long contexts, yet standard softmax attention incurs a KV cache that grows linearly with sequence length, quickly becoming the bottleneck for long context inference. A practical remedy is to evict less important KV entries; however, existing eviction policies are largely heuristic and struggle to capture the rich, input-dependent distribution of token importance. In this work, we introduce a learnable indexer that predicts KV importance, enabling more accurate retention of critical tokens. Meanwhile, naively evicting tokens permanently discards their information, leading to irreversible forgetting and degraded retrieval over long ranges. To address this, we propose a lightweight latent memory module that compresses evicted tokens into a compact, online-updated state and provides residual readouts to compensate for the attention contributions lost through KV eviction. Collectively, our method enables accurate long-context inference under a bounded KV budget, delivering consistent improvements on RULER (4K/16K) across Qwen, Mistral, and Llama models (up to 25 points under aggressive eviction), markedly more stable Needle-in-a-Haystack retrieval, and superior LongBench scores and compression curves compared to existing eviction policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces IndexMem for long-context LLM inference, featuring a learnable indexer that predicts the importance of KV cache entries to enable more accurate eviction under a bounded budget, and a lightweight latent memory module that compresses evicted tokens into a compact, online-updated state providing residual readouts to compensate for lost attention contributions. The method is evaluated on RULER (4K/16K), Needle-in-a-Haystack, and LongBench across Qwen, Mistral, and Llama models, claiming up to 25-point improvements under aggressive eviction and better compression curves than existing policies.
Significance. If the results hold and the compensation mechanism is validated, the work could meaningfully advance practical long-context inference by allowing bounded KV budgets without catastrophic retrieval loss. The multi-model evaluation on standard benchmarks provides a reasonable starting point for assessing real-world utility.
major comments (2)
- [Abstract (latent memory module description)] Abstract (paragraph describing the latent memory module): The central claim that residual readouts from the latent memory compensate for attention contributions lost through KV eviction is load-bearing, yet the abstract supplies no derivation showing mathematical alignment with softmax attention (e.g., as an added term in the value sum) or a bound on residual error. Without this, the reported 25-point RULER gains cannot be attributed to guaranteed recovery rather than the indexer alone.
- [Abstract] Abstract: No equations, training procedure, ablation studies, or error analysis are provided, preventing verification that the claimed gains on RULER, Needle-in-a-Haystack, and LongBench are reproducible or that they arise from the proposed components rather than implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below and will incorporate revisions to strengthen the presentation of the latent memory module and supporting details.
read point-by-point responses
-
Referee: [Abstract (latent memory module description)] Abstract (paragraph describing the latent memory module): The central claim that residual readouts from the latent memory compensate for attention contributions lost through KV eviction is load-bearing, yet the abstract supplies no derivation showing mathematical alignment with softmax attention (e.g., as an added term in the value sum) or a bound on residual error. Without this, the reported 25-point RULER gains cannot be attributed to guaranteed recovery rather than the indexer alone.
Authors: We agree that the abstract, being a concise summary, does not include the derivation or error bound. The full manuscript derives the residual readout as an additive term to the value sum in the attention computation (Section 3.2) and provides a bound on the approximation error under bounded cache assumptions. To address the concern directly in the abstract, we will revise it to briefly indicate this mathematical alignment and reference the detailed analysis in the paper, allowing the 25-point gains to be more clearly attributed to the combined components. revision: yes
-
Referee: [Abstract] Abstract: No equations, training procedure, ablation studies, or error analysis are provided, preventing verification that the claimed gains on RULER, Needle-in-a-Haystack, and LongBench are reproducible or that they arise from the proposed components rather than implementation details.
Authors: We acknowledge that the abstract omits these elements, as is conventional for abstracts. The manuscript contains the equations (Section 3), training procedure (Section 4), ablations (Section 5.3), and error analysis (Section 3.2). To improve self-containment and address reproducibility concerns, we will expand the abstract with a high-level reference to the training objective and note that ablations and analyses appear in the main text. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an architectural proposal consisting of a learnable indexer for KV importance and a latent memory module for residual readouts after eviction. No equations, fitting procedures, or derivation steps appear in the abstract or description that reduce any prediction or result to its own inputs by construction. Claims rest on empirical benchmark improvements (RULER, LongBench, Needle-in-a-Haystack) that are externally falsifiable and not forced by self-definition or self-citation chains. No load-bearing self-citations, uniqueness theorems, or ansatz smuggling are referenced. The central compensation assumption is an unproven architectural hypothesis rather than a circular reduction, leaving the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
latent memory module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bai, Y ., Dong, Q., Jiang, T., Lv, X., Du, Z., Zeng, A., Tang, J., and Li, J. Indexcache: Accelerating sparse attention via cross-layer index reuse.arXiv preprint arXiv:2603.12201,
-
[2]
Titans: Learning to Memorize at Test Time
Behrouz, A., Zhong, P., and Mirrokni, V . Titans: Learning to memorize at test time.arXiv preprint arXiv:2501.00663,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Chang, C.-C., Lin, C.-Y ., Akhauri, Y ., Lin, W.-C., Wu, K.-C., Ceze, L., and Abdelfattah, M. S. xkv: Cross-layer svd for kv-cache compression.arXiv preprint arXiv:2503.18893,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2510.00636 , year=
Devoto, A., Jeblick, M., and J´egou, S. Expected attention: Kv cache compression by estimating attention from future queries distribution.arXiv preprint arXiv:2510.00636,
- [5]
-
[6]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
BTC-LLM: Efficient Sub-1-Bit LLM Quantization via Learnable Transformation and Binary Codebook
Gu, H., Li, L., Wang, H., Wang, L., Wang, Z., Liu, B., Liu, J., Zhu, Q., Han, S., and Guo, Y . Btc-llm: Efficient sub-1-bit llm quantization via learnable transformation and binary codebook.arXiv preprint arXiv:2506.12040, 2025a. Gu, H., Li, W., Li, L., Zhu, Q., Lee, M., Sun, S., Xue, W., and Guo, Y . Delta decompression for moe-based llms compression.arX...
work page internal anchor Pith review Pith/arXiv arXiv
- [8]
-
[9]
R., Pawar, S
Henry, A., Dachapally, P. R., Pawar, S. S., and Chen, Y . Query-key normalization for transformers. InFindings of the Association for Computational Linguistics: EMNLP 2020, pp. 4246–4253,
2020
-
[10]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Zhang, Y ., and Ginsburg, B. Ruler: What’s the real context size of your long-context language models? arXiv preprint arXiv:2404.06654,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Memory in the Age of AI Agents
9 IndexMem: Learned KV-Cache Eviction with Latent Memory Hu, Y ., Liu, S., Yue, Y ., Zhang, G., Liu, B., Zhu, F., Lin, J., Guo, H., Dou, S., Xi, Z., et al. Memory in the age of ai agents.arXiv preprint arXiv:2512.13564,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Huang, Y ., Yuan, B., Han, X., Xiao, C., and Liu, Z. Locret: Enhancing eviction in long-context llm inference with trained retaining heads on consumer-grade devices.arXiv preprint arXiv:2410.01805,
-
[13]
Nosa: Na- tive and offloadable sparse attention.arXiv preprint arXiv:2510.13602,
Huang, Y ., Xiao, C., Han, X., and Liu, Z. Nosa: Na- tive and offloadable sparse attention.arXiv preprint arXiv:2510.13602,
-
[14]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Jain, N., Han, K., Gu, A., Li, W.-D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., and Stoica, I. Livecodebench: Holistic and contamination free eval- uation of large language models for code.arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
arXiv preprint arXiv:2407.02490 , year=
Jiang, H., Li, Y ., Zhang, C., Wu, Q., Luo, X., Ahn, S., Han, Z., Abdi, A. H., Li, D., Lin, C.-Y ., Yang, Y ., and Qiu, L. Minference 1.0: Accelerating pre-filling for long- context llms via dynamic sparse attention.arXiv preprint arXiv:2407.02490,
-
[16]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al. Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Liu, Z., Yuan, J., Jin, H., Zhong, S., Xu, Z., Braverman, V ., Chen, B., and Hu, X. Kivi: A tuning-free asym- metric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Lu, E. et al. Moba: Mixture of block attention for long- context llms.arXiv preprint arXiv:2502.13189,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URL https:// github.com/NVIDIA/kvpress. Accessed: 2026- 01-26. Oren, M., Hassid, M., Yarden, N., Adi, Y ., and Schwartz, R. Transformers are multi-state rnns.arXiv preprint arXiv:2401.06104,
-
[20]
J., Goel, R., Lee, M., and Lott, C
Park, J., Jones, D., Morse, M. J., Goel, R., Lee, M., and Lott, C. Keydiff: Key similarity-based kv cache eviction for long-context llm inference in resource-constrained environments.arXiv preprint arXiv:2504.15364,
-
[21]
Memorag: Boosting long context processing with global memory-enhanced retrieval augmentation
Qian, H., Liu, Z., Zhang, P., Mao, K., Lian, D., Dou, Z., and Huang, T. Memorag: Boosting long context processing with global memory-enhanced retrieval augmentation. In Proceedings of the ACM on Web Conference 2025, pp. 2366–2377,
2025
-
[22]
Fast Transformer Decoding: One Write-Head is All You Need
Shazeer, N. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[23]
Huy Truong, Andrés Tello, Alexander Lazovik, and Victoria Degeler
Tandon, A., Dalal, K., Li, X., Koceja, D., Rød, M., Buchanan, S., Wang, X., Leskovec, J., Koyejo, S., Hashimoto, T., et al. End-to-end test-time training for long context.arXiv preprint arXiv:2512.23675,
-
[24]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Tang, J., Zhao, Y ., Zhu, K., Xiao, G., Kasikci, B., and Han, S. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Kimi K2: Open Agentic Intelligence
10 IndexMem: Learned KV-Cache Eviction with Latent Memory Team, K., Bai, Y ., Bao, Y ., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y ., Chen, Y ., Chen, Y ., et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Aime problem set 1983- 2024,
Veeraboina, H. Aime problem set 1983- 2024,
1983
-
[27]
com/datasets/hemishveeraboina/ aime-problem-set-1983-2024
URL https://www.kaggle. com/datasets/hemishveeraboina/ aime-problem-set-1983-2024. Wang, J., Chen, T., Cheng, P., Hou, X., and Liu, J. Adar- eason: Progressive training of multi-lora adapters for budget-adaptive language reasoning models. InProceed- ings of the AAAI Conference on Artificial Intelligence, volume 40, pp. 26242–26250,
1983
-
[28]
Wang, Y ., Ji, S., Liu, Y ., Xu, Y ., Xu, Y ., Zhu, Q., and Che, W. Lookahead q-cache: Achieving more consis- tent kv cache eviction via pseudo query.arXiv preprint arXiv:2505.20334,
-
[29]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Bit-by-Bit: Progressive QAT Strategy with Outlier Channel Splitting for Stable Low-Bit LLMs
Xu, B., Gu, H., Li, L., Wang, H., Liu, B., Liu, J., Zhu, Q., Yang, X., Li, C., Han, S., et al. Bit-by-bit: Progressive qat strategy with outlier channel splitting for stable low-bit llms.arXiv preprint arXiv:2604.07888,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Yuan, A., Wang, Z., Miao, R., Wang, D., Tian, Y ., Wang, Z., Peng, Y ., Wu, Y ., Yi, B., Liu, X., et al. Kvreviver: Reversible kv cache compression with sketch-based token reconstruction.arXiv preprint arXiv:2512.17917, 2025a. Yuan, J. et al. Native sparse attention: Hardware-aligned and natively trainable sparse attention.arXiv preprint arXiv:2502.11089,...
-
[33]
Zhao, T. and Jones, L. Fast-weight product key memory. arXiv preprint arXiv:2601.00671,
-
[34]
Limitations and Future Work
11 IndexMem: Learned KV-Cache Eviction with Latent Memory A. Limitations and Future Work. Long chain-of-thought (CoT) reasoning has become a standard capability of modern language models. However, longer CoT also leads to substantially larger KV-cache memory consumption, which can become the dominant memory bottleneck during long-context inference. As a r...
2025
-
[35]
and quantization (Xu et al., 2026; Gu et al., 2025a
2026
-
[36]
toward reducing the KV-cache footprint. Although recent works have explored reducing reasoning length or adaptively controlling CoT generation (Chen et al., 2026; Wang et al., 2026; Zhu et al., 2026), our work focuses on a complementary direction: improving KV-cache efficiency while preserving the model’s ability to reason over long contexts. While effect...
2026
-
[37]
We report the overall averagescore, computed as the mean over tasks, under compression ratios CR∈ {0.25,0.50,0.75,0.90}
Experimental summary.We evaluate Expected Attention (EA) and running-mean variants onRULER. We report the overall averagescore, computed as the mean over tasks, under compression ratios CR∈ {0.25,0.50,0.75,0.90} . Table 2 shows that entropy-gated running mean with skip-high, computed via softmax, consistently improves over the naive layer-mean running mea...
2026
-
[38]
Method wikiqa hotpotqa triviaqa passage retrieval en multifieldqa en multi news multifieldqa zh Avg. (shown) IndexMem (ours)50.97 68.67 91.0040.0059.80 25.40 56.58 56.06 xKV 46.21 55.81 90.00 1.00 32.61 25.04 46.13 42.40 Locret 10.10 13.20 59.5585.0716.94 19.13 16.51 31.50 C. More Results We provide additional experimental results that complement the main...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.