CRAB-Bench: Evaluating LLM Agents under Complex Task Dependencies and Human-aligned User Simulation
Pith reviewed 2026-06-28 14:43 UTC · model grok-4.3
The pith
Frontier LLM agents reach only 61% pass rate on tasks with complex entity dependencies, falling further when users behave realistically rather than cooperatively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
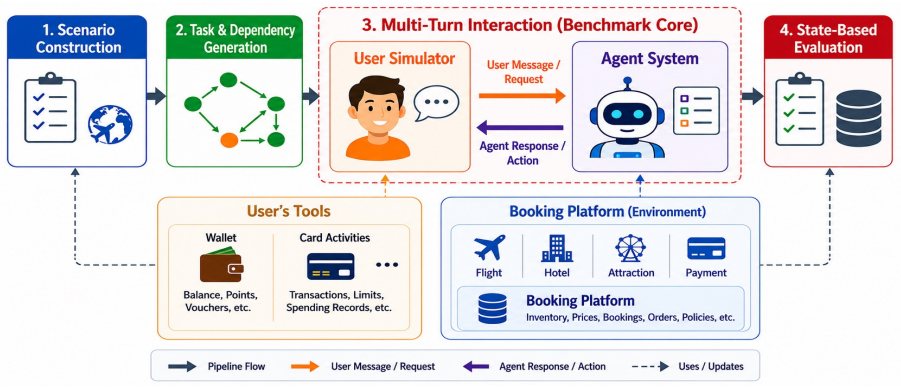
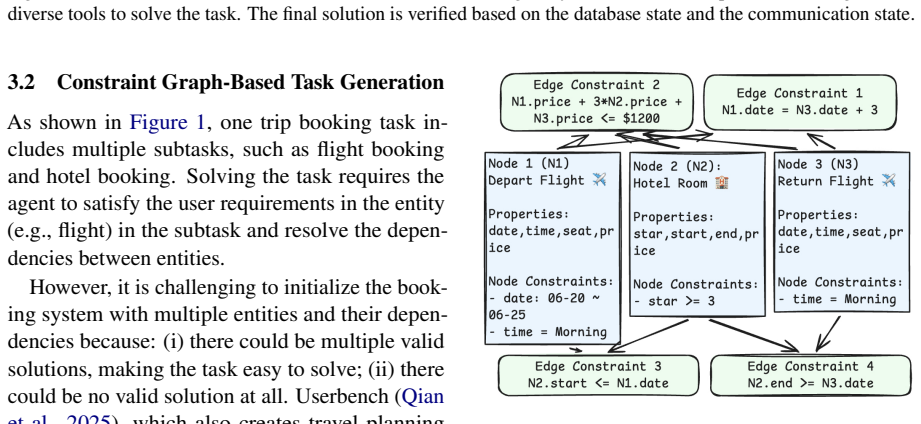
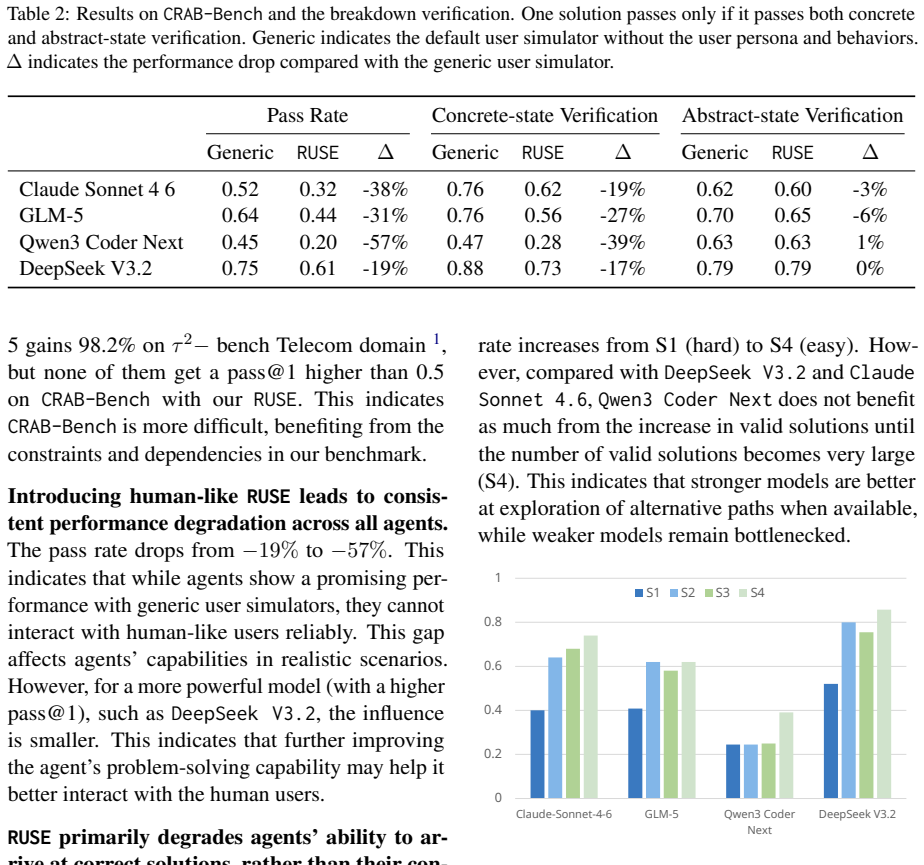
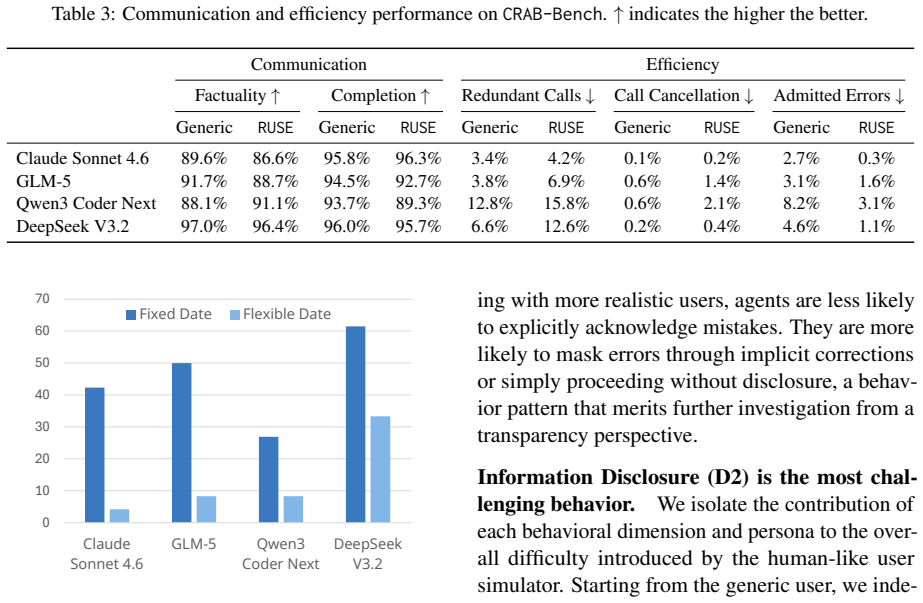
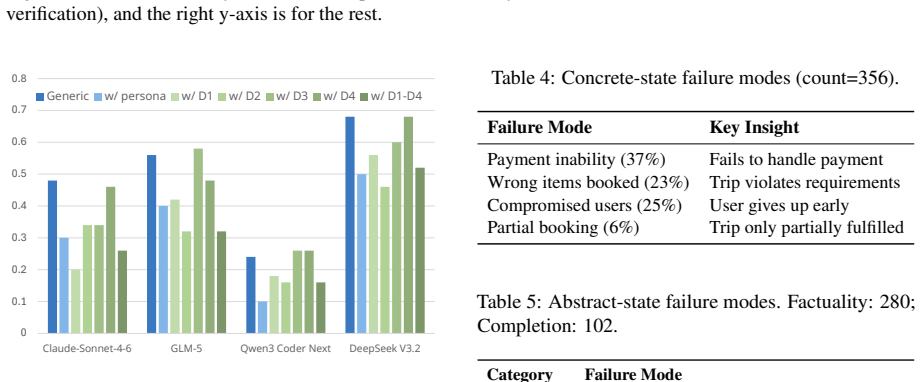
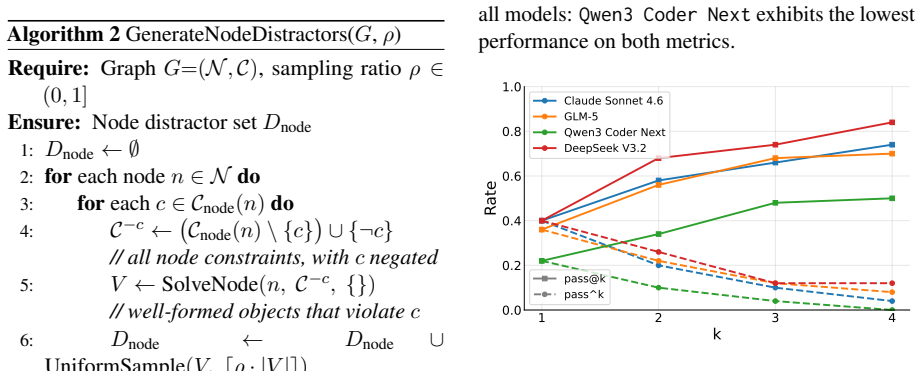
CRAB-Bench generates tasks via a constraint graph over multiple interdependent entities with structured distractors, requiring agents to reason carefully over thousands of misleading candidates where only a tiny fraction of solutions are valid. RUSE replaces cooperative, template-like simulators with realistic users grounded in human behavioral studies, instantiated across diverse personas and four behavioral dimensions. Experiments on four frontier LLM agents show that the best model achieves only 61% pass@1 on CRAB-Bench, and switching to RUSE causes further drops of up to 57%, concentrated in task-solving ability rather than conversational quality. Information Disclosure is the most damag
What carries the argument
CRAB-Bench constraint graph over interdependent entities with distractors, paired with RUSE behavioral simulation across four dimensions from human studies
If this is right
- Agents require stronger mechanisms to filter valid solutions from large sets of misleading candidates.
- Task-solving performance degrades more than conversational quality when users deviate from cooperative behavior.
- Information disclosure by users is the single dimension that most reduces agent success rates.
- Agents shift toward implicit error masking instead of explicit admission when users follow realistic patterns.
Where Pith is reading between the lines
- Current agent designs trained on cooperative simulators may systematically underperform once deployed with actual customers.
- Error-handling training could target explicit mistake admission to reduce masking behavior observed with RUSE.
- Benchmarks without user simulation may overestimate readiness for real service environments.
- Extending the four behavioral dimensions to other domains like technical support could reveal similar gaps.
Load-bearing premise
RUSE accurately captures real human user behavior in service scenarios so performance drops reflect genuine agent limitations rather than simulation artifacts.
What would settle it
Direct comparison of the same agents interacting with real human users versus RUSE on matched tasks, checking whether the magnitude and pattern of performance drops align.
Figures



read the original abstract
Evaluating LLM agents in realistic service scenarios requires complex task dependencies, imperfect user behavior, and an evaluation that accommodates multiple valid solutions. We introduce CRAB-Bench (Constraint-based Realistic Agent Benchmark) and RUSE (Realistic User Simulation Engine) to address this gap. CRAB-Bench generates tasks via a constraint graph over multiple interdependent entities with structured distractors, requiring agents to reason carefully over thousands of misleading candidates where only a tiny fraction of solutions are valid. RUSE replaces cooperative, template-like simulators with realistic users grounded in human behavioral studies, instantiated across diverse personas and four behavioral dimensions. Experiments on four frontier LLM agents show that the best model achieves only 61% pass@1 on CRAB-Bench, and switching to RUSE causes further drops of up to 57%, concentrated in task-solving ability rather than conversational quality. Information Disclosure is the most damaging behavioral dimension, and agents interacting with RUSE are less likely to admit mistakes, instead masking errors through implicit corrections.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CRAB-Bench, a benchmark generating tasks via constraint graphs over interdependent entities with structured distractors, and RUSE, a user simulation engine grounded in human behavioral studies across personas and four dimensions (including Information Disclosure). Experiments with four frontier LLM agents report a maximum 61% pass@1 on CRAB-Bench, with further drops of up to 57% under RUSE, primarily affecting task-solving rather than conversation quality, and reduced mistake admission.
Significance. If the results hold, this work highlights important gaps in LLM agents' robustness to realistic, imperfect user behaviors in complex service tasks, emphasizing the need for better handling of information disclosure and error recovery. The constraint-based task generation with thousands of misleading candidates offers a strong test of careful reasoning. Credit is due for attempting to move beyond cooperative simulators. However, the absence of empirical calibration of RUSE to human data means the performance gaps may not generalize to real users.
major comments (3)
- [RUSE description] The claim that RUSE captures real user behavior such that drops reflect agent limitations requires quantitative validation (e.g., matching disclosure rates or mistake-admission frequencies to human studies); the text only states it is 'grounded in human behavioral studies' without reporting any such match or statistical comparison.
- [Experiments section] The reported metrics (61% pass@1, 57% drops) lack accompanying details on the number of tasks evaluated, number of trials, statistical tests used, or specific baseline comparisons, which are necessary to evaluate the strength of the empirical claims.
- [Task generation] The abstract mentions 'structured distractors' and 'thousands of misleading candidates' but provides no specifics on how distractors were generated or validated to ensure only a tiny fraction of solutions are valid, which is central to the benchmark's difficulty claim.
minor comments (1)
- [Abstract] The abstract could more clearly distinguish between the contributions of CRAB-Bench and RUSE in the reported performance drops.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas for strengthening the empirical grounding and methodological transparency of CRAB-Bench and RUSE. We address each major comment below and commit to revisions that improve clarity without overstating current results.
read point-by-point responses
-
Referee: The claim that RUSE captures real user behavior such that drops reflect agent limitations requires quantitative validation (e.g., matching disclosure rates or mistake-admission frequencies to human studies); the text only states it is 'grounded in human behavioral studies' without reporting any such match or statistical comparison.
Authors: We agree this is a substantive limitation. The manuscript grounds the four behavioral dimensions in cited human studies but does not perform or report quantitative matching (e.g., statistical comparisons of disclosure rates or mistake-admission frequencies). We will revise the RUSE section to explicitly state the specific studies used for each dimension, add any available descriptive alignments, and include a limitations paragraph noting the absence of direct empirical calibration and its implications for generalization. revision: yes
-
Referee: The reported metrics (61% pass@1, 57% drops) lack accompanying details on the number of tasks evaluated, number of trials, statistical tests used, or specific baseline comparisons, which are necessary to evaluate the strength of the empirical claims.
Authors: The Experiments section will be expanded to report the exact number of tasks evaluated, number of trials per agent, any statistical tests applied to the pass@1 and drop figures, and more granular baseline comparisons (including per-dimension breakdowns). These details exist in our experimental logs and will be added to the revised manuscript. revision: yes
-
Referee: The abstract mentions 'structured distractors' and 'thousands of misleading candidates' but provides no specifics on how distractors were generated or validated to ensure only a tiny fraction of solutions are valid, which is central to the benchmark's difficulty claim.
Authors: We will add a dedicated subsection under Task Generation describing the constraint-graph construction process, the sampling procedure for distractors, and the validation steps (including enumeration of valid solutions per task) used to confirm that only a tiny fraction of candidates satisfy all constraints. This will also be referenced from the abstract. revision: yes
- Quantitative empirical calibration of RUSE to human data (direct statistical matching of behavioral rates such as information disclosure or mistake admission), as no such matched human dataset or comparison is present in the current work and would require new data collection.
Circularity Check
No significant circularity; empirical benchmark paper with no load-bearing derivations or self-referential reductions.
full rationale
The paper introduces CRAB-Bench and RUSE via constraint graphs and behavioral dimensions grounded in external human studies, then reports pass rates on frontier LLMs. No equations, fitted parameters, predictions-by-construction, or self-citations appear in the provided text. Central results (61% pass@1, drops under RUSE) are direct experimental measurements against external models, not reductions to the paper's own inputs. The RUSE fidelity concern is a validity issue, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human behavioral studies provide a valid grounding for instantiating realistic user personas and four behavioral dimensions in service scenarios
invented entities (2)
-
CRAB-Bench
no independent evidence
-
RUSE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
AgentBench: Evaluating LLMs as Agents , author=
-
[4]
SWE-bench: Can Language Models Resolve Real-world Github Issues? , author=
-
[5]
2024 , eprint=
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models , author=. 2024 , eprint=
2024
-
[6]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=
-
[7]
Chatbot arena: An open platform for evaluating llms by human preference , author=
-
[9]
arXiv preprint arXiv:2510.12399 , year=
A survey of vibe coding with large language models , author=. arXiv preprint arXiv:2510.12399 , year=
-
[10]
agentic coding: Fundamentals and practical implications of agentic ai , author=
Vibe coding vs. agentic coding: Fundamentals and practical implications of agentic ai , author=. arXiv preprint arXiv:2505.19443 , year=
-
[11]
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik R , url =. \ \. The Thirteenth International Conference on Learning Representations , date =
-
[13]
URL https://aclanthology.org/2024.acl-long.850/
Trivedi, Harsh and Khot, Tushar and Hartmann, Mareike and Manku, Ruskin and Dong, Vinty and Li, Edward and Gupta, Shashank and Sabharwal, Ashish and Balasubramanian, Niranjan , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , date =. doi:10.18653/v1/2024.acl-long.850 , pages =
-
[14]
Rana, Manik and Man, Calissa and Msiiwa, Anotida Expected and Paine, Jeffrey and Zhu, Kevin and Dev, Sunishchal and Sharma, Vasu and others , date =
-
[15]
Seshadri, Preethi and Cahyawijaya, Samuel and Odumakinde, Ayomide and Singh, Sameer and Goldfarb-Tarrant, Seraphina , date =
-
[16]
Zhou, Xuhui and Sun, Weiwei and Ma, Qianou and Xie, Yiqing and Liu, Jiarui and Du, Weihua and Welleck, Sean and Yang, Yiming and Neubig, Graham and Wu, Sherry Tongshuang and others , date =
-
[18]
Identifying & Interactively Refining Ambiguous User Goals for Data Visualization Code Generation
Inan, Mert and Sicilia, Anthony and Xie, Alex and Vaduguru, Saujas and Fried, Daniel and Alikhani, Malihe. Identifying & Interactively Refining Ambiguous User Goals for Data Visualization Code Generation. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1283
-
[21]
International Conference on Learning Representations , volume=
Proactive agent: Shifting llm agents from reactive responses to active assistance , author=. International Conference on Learning Representations , volume=
-
[23]
Advances in neural information processing systems , volume=
Aligning llm agents by learning latent preference from user edits , author=. Advances in neural information processing systems , volume=
-
[24]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
A user-centric multi-intent benchmark for evaluating large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[25]
International Conference on Learning Representations , volume=
Mint: Evaluating llms in multi-turn interaction with tools and language feedback , author=. International Conference on Learning Representations , volume=
-
[26]
SWE-chat: Coding Agent Interactions From Real Users in the Wild
Swe-chat: Coding agent interactions from real users in the wild , author=. arXiv preprint arXiv:2604.20779 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
The Fourteenth International Conference on Learning Representations , year=
LLMs Get Lost in Multi-Turn Conversation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[28]
GLM-5: from Vibe Coding to Agentic Engineering
Glm-5: from vibe coding to agentic engineering , author=. arXiv preprint arXiv:2602.15763 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. https://arxiv.org/abs/2506.07982 ^2 -bench: Evaluating conversational agents in a dual-control environment . Preprint, arXiv:2506.07982
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Chatbot arena: An open platform for evaluating llms by human preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, and 1 others. Chatbot arena: An open platform for evaluating llms by human preference. In Forty-first International Conference on Machine Learning
-
[32]
Ge Gao, Alexey Taymanov, Eduardo Salinas, Paul Mineiro, and Dipendra Misra. 2024. Aligning llm agents by learning latent preference from user edits. Advances in neural information processing systems, 37:136873--136896
2024
- [33]
-
[34]
Swe-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. Swe-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations
-
[35]
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. 2026. Llms get lost in multi-turn conversation. In The Fourteenth International Conference on Learning Representations
2026
- [36]
-
[37]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, and 1 others. Agentbench: Evaluating llms as agents. In The Twelfth International Conference on Learning Representations
-
[38]
Yaxi Lu, Shenzhi Yang, Cheng Qian, Guirong Chen, Qinyu Luo, Yesai Wu, Huadong Wang, Xin Cong, Zhong Zhang, Yankai Lin, and 1 others. 2025. Proactive agent: Shifting llm agents from reactive responses to active assistance. In International Conference on Learning Representations, volume 2025, pages 47431--47457
2025
- [39]
-
[40]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, and 1 others. Toolllm: Facilitating large language models to master 16000+ real-world apis. In The Twelfth International Conference on Learning Representations
-
[41]
Agentchangebench: A multi-dimensional evaluation framework for goal-shift robustness in conversational ai
Manik Rana, Calissa Man, Anotida Expected Msiiwa, Jeffrey Paine, Kevin Zhu, Sunishchal Dev, Vasu Sharma, and 1 others. Agentchangebench: A multi-dimensional evaluation framework for goal-shift robustness in conversational ai
-
[42]
Lost in simulation: Llm-simulated users are unreliable proxies for human users in agentic evaluations
Preethi Seshadri, Samuel Cahyawijaya, Ayomide Odumakinde, Sameer Singh, and Seraphina Goldfarb-Tarrant. Lost in simulation: Llm-simulated users are unreliable proxies for human users in agentic evaluations
- [43]
-
[44]
Harmanpreet Singh, Nikhil Verma, Yixiao Wang, Manasa Bharadwaj, Homa Fashandi, Kevin Ferreira, and Chul Lee. 2024. https://doi.org/10.18653/v1/2024.emnlp-industry.37 Personal large language model agents: A case study on tailored travel planning . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pag...
- [45]
- [46]
-
[47]
Jiayin Wang, Fengran Mo, Weizhi Ma, Peijie Sun, Min Zhang, and Jian-Yun Nie. 2024 a . A user-centric multi-intent benchmark for evaluating large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 3588--3612
2024
-
[48]
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. 2024 b . Mint: Evaluating llms in multi-turn interaction with tools and language feedback. In International Conference on Learning Representations, volume 2024, pages 32593--32627
2024
-
[49]
https://openreview.net/forum?id=roNSXZpUDN \ \ tau\ \ -bench: A benchmark for underline\ T\ ool- underline\ A\ gent- underline\ U\ ser interaction in real-world domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R Narasimhan. https://openreview.net/forum?id=roNSXZpUDN \ \ tau\ \ -bench: A benchmark for underline\ T\ ool- underline\ A\ gent- underline\ U\ ser interaction in real-world domains . In The Thirteenth International Conference on Learning Representations
- [50]
-
[51]
Mind the sim2real gap in user simulation for agentic tasks
Xuhui Zhou, Weiwei Sun, Qianou Ma, Yiqing Xie, Jiarui Liu, Weihua Du, Sean Welleck, Yiming Yang, Graham Neubig, Sherry Tongshuang Wu, and 1 others. Mind the sim2real gap in user simulation for agentic tasks
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.