Recognition: unknown
SWE-chat: Coding Agent Interactions From Real Users in the Wild
Pith reviewed 2026-05-09 23:38 UTC · model grok-4.3
The pith
In real developer interactions, coding agents see only 44% of their code reach final commits and face user pushback in 44% of turns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
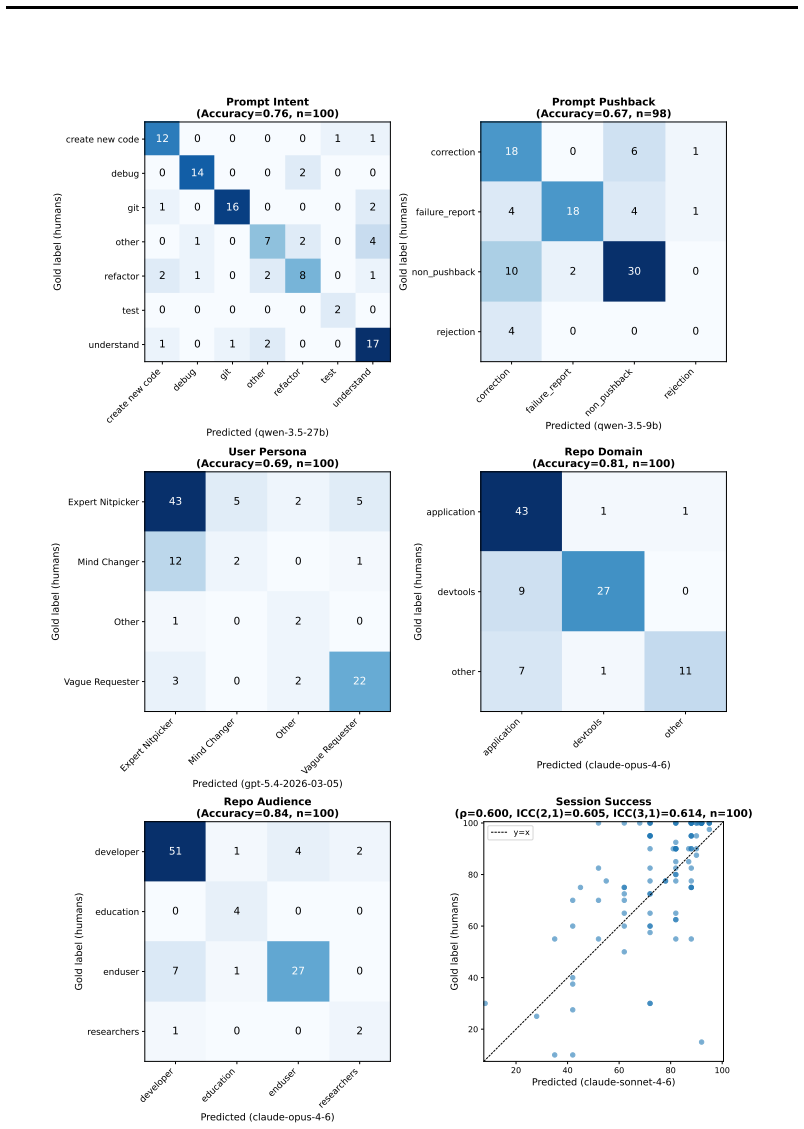
The analysis of the dataset reveals bimodal coding patterns in which agents author virtually all committed code in 41 percent of sessions while humans write all code in 23 percent. Just 44 percent of agent-produced code survives into user commits, agent-written code introduces more security vulnerabilities than human-authored code, and users push back against agent outputs through corrections, failure reports, and interruptions in 44 percent of all turns.
What carries the argument
The dataset of real coding agent sessions from public repositories, which includes complete interaction traces and accurate attribution of which code was written by the human versus the agent.
Load-bearing premise
The sessions obtained through automated collection from public repositories form a representative sample of real developer and agent interactions, with reliable attribution of code authorship.
What would settle it
Finding that a significant portion of the collected sessions have incorrect human-versus-agent code labels upon manual review, or observing substantially different survival rates in a controlled study of private developer workflows, would undermine the central claims.
Figures



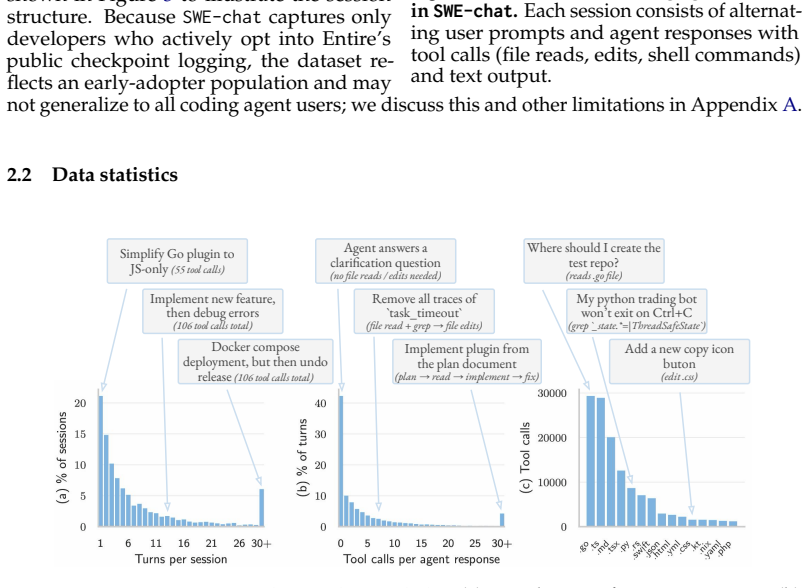

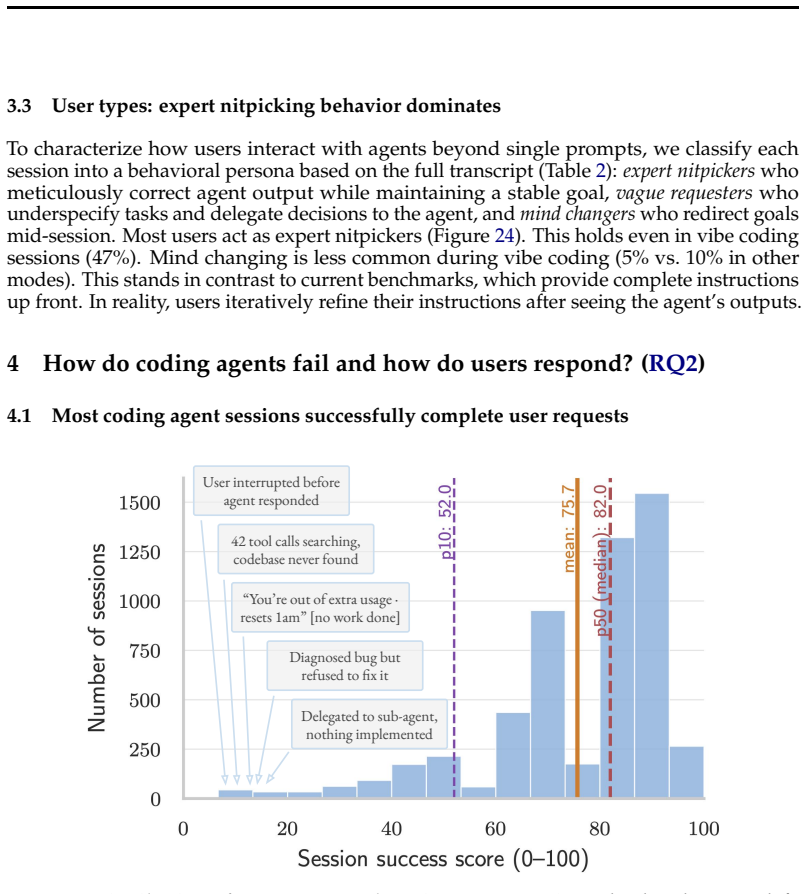

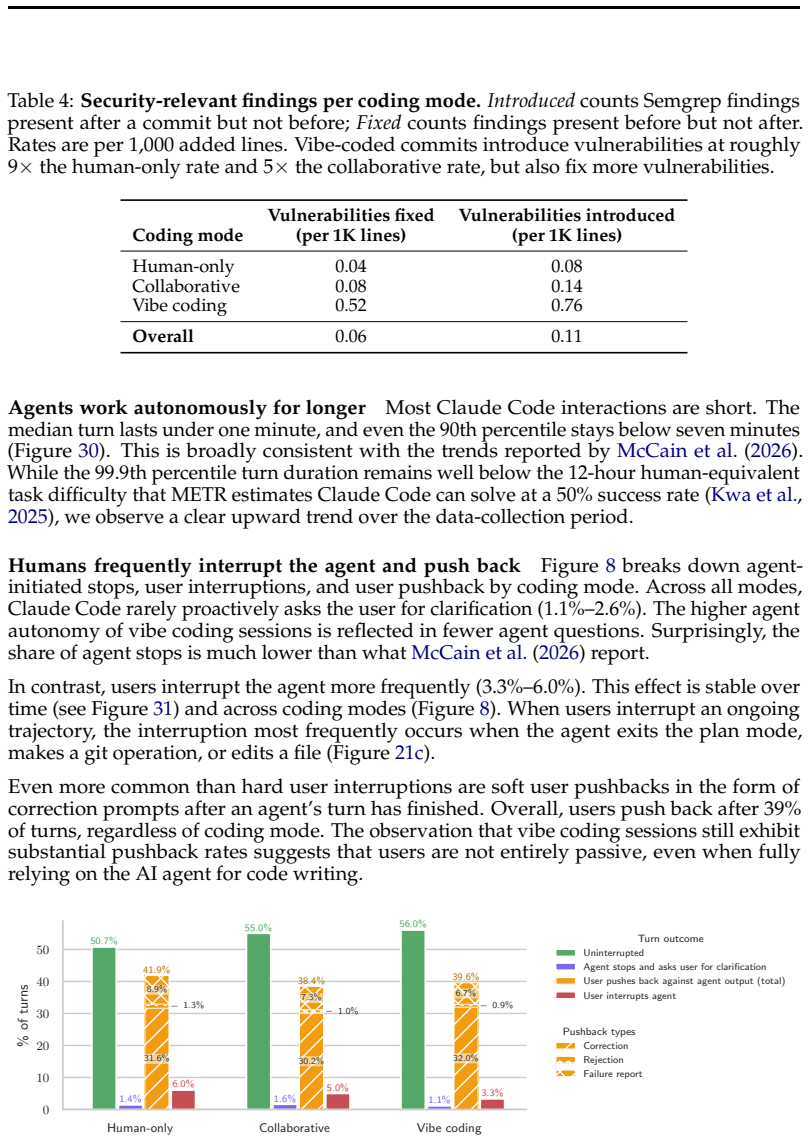












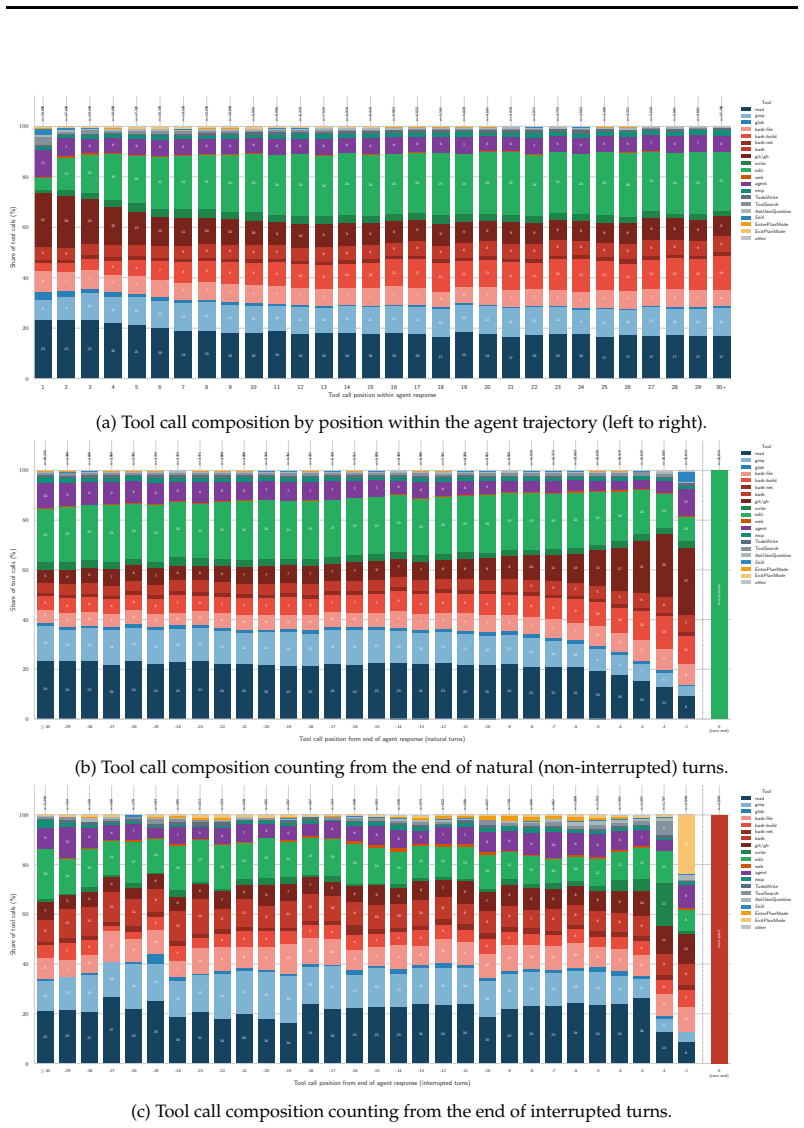
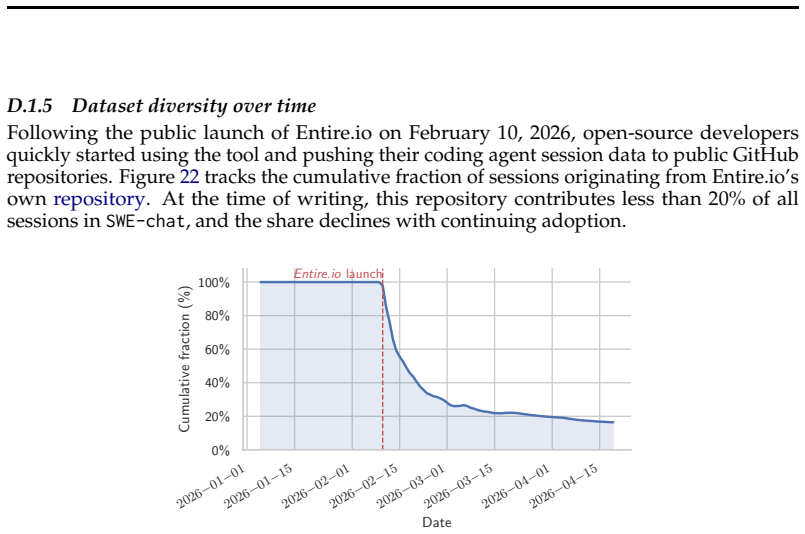







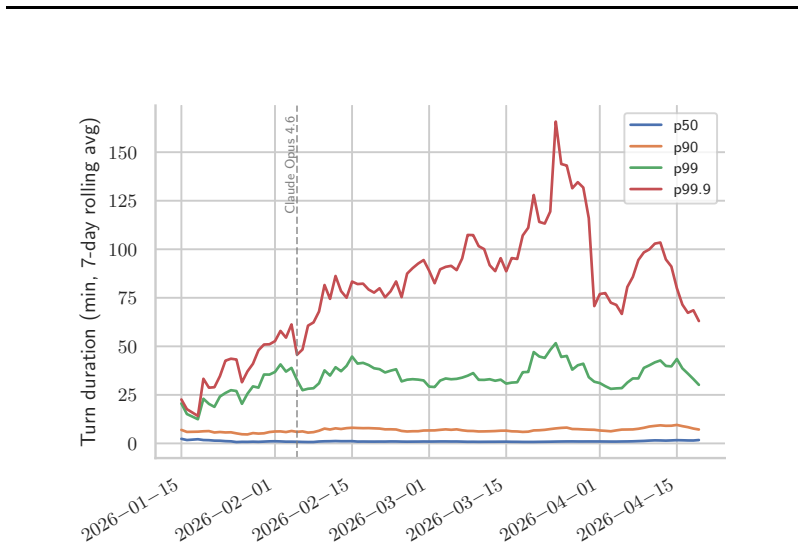
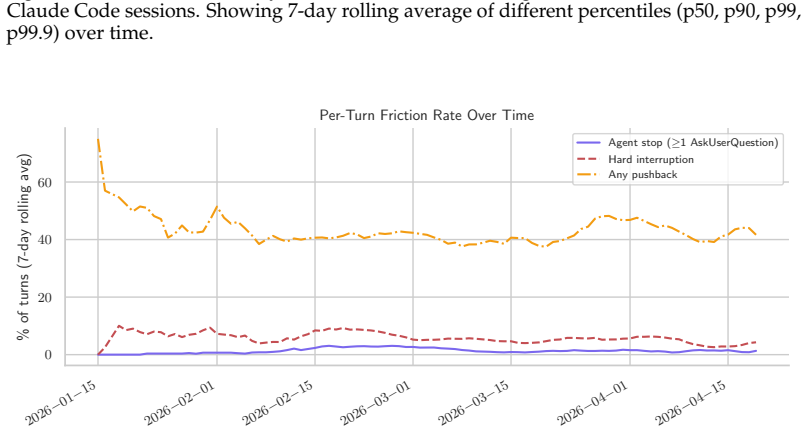
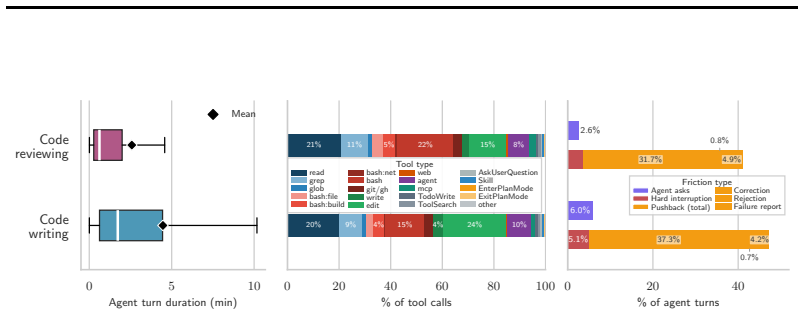

read the original abstract
AI coding agents are being adopted at scale, yet we lack empirical evidence on how people actually use them and how much of their output is useful in practice. We present SWE-chat, the first large-scale dataset of real coding agent sessions collected from open-source developers in the wild. The dataset currently contains 6,000 sessions, comprising more than 63,000 user prompts and 355,000 agent tool calls. SWE-chat is a living dataset; our collection pipeline automatically and continually discovers and processes sessions from public repositories. Leveraging SWE-chat, we provide an initial empirical characterization of real-world coding agent usage and failure modes. We find that coding patterns are bimodal: in 41% of sessions, agents author virtually all committed code ("vibe coding"), while in 23%, humans write all code themselves. Despite rapidly improving capabilities, coding agents remain inefficient in natural settings. Just 44% of all agent-produced code survives into user commits, and agent-written code introduces more security vulnerabilities than code authored by humans. Furthermore, users push back against agent outputs -- through corrections, failure reports, and interruptions -- in 44% of all turns. By capturing complete interaction traces with human vs. agent code authorship attribution, SWE-chat provides an empirical foundation for moving beyond curated benchmarks towards an evidence-based understanding of how AI agents perform in real developer workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SWE-chat, a large-scale 'living' dataset of 6,000 real-world coding agent sessions (63k+ user prompts, 355k+ tool calls) automatically collected from public open-source repositories. It reports an empirical characterization of usage patterns, including bimodal authorship (41% of sessions agent-dominated, 23% human-only), that only 44% of agent-produced code survives into user commits, that agent-written code introduces more security vulnerabilities than human code, and that users push back via corrections/failures/interruptions in 44% of turns. The dataset includes interaction traces with human-vs-agent code attribution.
Significance. If the collection pipeline and authorship attribution prove reliable, SWE-chat would be a significant contribution as the first large-scale observational dataset of AI coding agents in natural developer workflows. It moves the field beyond curated benchmarks by enabling evidence-based study of survival rates, failure modes, and pushback behaviors. The automated, ongoing collection pipeline and scale are notable strengths.
major comments (3)
- [Dataset Construction] The central claims (44% agent-code survival rate, higher vulnerabilities in agent code, 44% user pushback) rest entirely on accurate per-line/per-commit human-vs-agent authorship attribution, yet the dataset construction section provides no quantitative validation of this labeling (e.g., no manual audit sample size, inter-annotator agreement, or error-rate estimates). Without such validation, the reported differences could be artifacts of heuristic failures when users interleave edits or refactor.
- [Empirical Analysis / Vulnerability subsection] The vulnerability comparison claim lacks any description of the scanning methodology, tools employed, false-positive handling, or controls for confounding factors such as code complexity or project type. This is load-bearing for the assertion that 'agent-written code introduces more security vulnerabilities than code authored by humans.'
- [Introduction and Dataset Collection] The representativeness of the 6,000 sessions as 'real users in the wild' is asserted but not supported by analysis of selection biases in the automated discovery pipeline from public repositories (e.g., project popularity, language distribution, or session-length filters). This affects generalizability of the bimodal patterns and 44% statistics.
minor comments (2)
- [Abstract] The abstract states precise percentages (44%, 41%, 23%) without cross-references to the specific tables, figures, or sections containing the underlying counts and statistical details.
- [Usage Patterns] Notation for 'vibe coding' and session classification criteria should be defined more explicitly when first introduced to avoid ambiguity in the bimodal usage analysis.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Dataset Construction] The central claims (44% agent-code survival rate, higher vulnerabilities in agent code, 44% user pushback) rest entirely on accurate per-line/per-commit human-vs-agent authorship attribution, yet the dataset construction section provides no quantitative validation of this labeling (e.g., no manual audit sample size, inter-annotator agreement, or error-rate estimates). Without such validation, the reported differences could be artifacts of heuristic failures when users interleave edits or refactor.
Authors: We agree that the absence of quantitative validation for the authorship attribution heuristic is a limitation in the current manuscript. The heuristic relies on git blame and commit history to attribute lines, but interleaved edits could introduce errors. In the revised version, we will add a new subsection under Dataset Construction reporting a manual audit of 200 randomly sampled sessions. Two independent annotators will label authorship per commit, and we will report inter-annotator agreement (Cohen's kappa), per-line error rates, and sensitivity analysis on sessions with high interleaving. This will directly support the reliability of the 44% survival rate and related statistics. revision: yes
-
Referee: [Empirical Analysis / Vulnerability subsection] The vulnerability comparison claim lacks any description of the scanning methodology, tools employed, false-positive handling, or controls for confounding factors such as code complexity or project type. This is load-bearing for the assertion that 'agent-written code introduces more security vulnerabilities than code authored by humans.'
Authors: We acknowledge that the vulnerability subsection is insufficiently detailed. The manuscript reports the comparative finding but omits the scanner, false-positive mitigation, and controls. In the revision, we will expand this subsection to specify the static analysis tool, the process for handling false positives (including manual review of a 10% sample), and controls such as regression adjustment for cyclomatic complexity, lines of code, and project-level fixed effects. We will also report the distribution of vulnerability categories to allow readers to assess the result. revision: yes
-
Referee: [Introduction and Dataset Collection] The representativeness of the 6,000 sessions as 'real users in the wild' is asserted but not supported by analysis of selection biases in the automated discovery pipeline from public repositories (e.g., project popularity, language distribution, or session-length filters). This affects generalizability of the bimodal patterns and 44% statistics.
Authors: The collection pipeline discovers sessions from public GitHub repositories via automated search, which necessarily favors projects with visible agent usage and certain languages. The manuscript emphasizes the scale and living nature of the dataset but does not quantify these biases. In the revised version, we will add descriptive statistics on language distribution, project popularity (e.g., star counts), and session-length filters, plus a dedicated limitations paragraph discussing implications for generalizability of the bimodal authorship and 44% figures. We maintain that the observational data from actual developer workflows remains a core contribution despite these selection effects. revision: partial
Circularity Check
Observational dataset collection and reporting with no derivations or fitted predictions
full rationale
The paper collects sessions from public repositories and reports direct empirical statistics (e.g., 44% agent-code survival, 44% user pushback, bimodal coding patterns). No equations, models, parameters, or predictions are defined or derived; all claims are descriptive observations from the raw interaction traces. Attribution of human vs. agent code is presented as part of the data pipeline without any self-referential fitting or reduction to prior results. This is a standard self-contained observational study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Sessions automatically discovered from public repositories form a representative and unbiased sample of real coding-agent usage.
- domain assumption Code authorship between human and agent can be attributed accurately from commit histories and interaction traces.
Forward citations
Cited by 4 Pith papers
-
ProgramBench: Can Language Models Rebuild Programs From Scratch?
ProgramBench introduces 200 tasks where models must reconstruct full programs like FFmpeg or SQLite from docs alone; none of 9 evaluated LMs fully solve any task and the best passes 95% tests on only 3% of tasks while...
-
SecureForge: Finding and Preventing Vulnerabilities in LLM-Generated Code via Prompt Optimization
SecureForge audits LLM code for vulnerabilities, builds a synthetic prompt corpus via Markovian sampling, and optimizes system prompts to cut security issues by up to 48% while preserving unit test performance, with z...
-
SWE Atlas: Benchmarking Coding Agents Beyond Issue Resolution
SWE Atlas is a benchmark suite for coding agents that evaluates Codebase Q&A, Test Writing, and Refactoring using comprehensive protocols assessing both functional correctness and software engineering quality.
-
RECAP: An End-to-End Platform for Capturing, Replaying, and Analyzing AI-Assisted Programming Interactions
RECAP captures, replays, and analyzes AI-assisted programming sessions by linking prompts, edits, and developer actions in a single timeline.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2507.15003. Robert A. Martin and Sean Barnum. Common weakness enumeration (cwe) status update. Ada Lett., XXVIII(1):88–91, April 2008. ISSN 1094-3641. doi: 10.1145/1387830.1387835. URLhttps://doi.org/10.1145/1387830.1387835. Maxim Massenkoff, Eva Lyubich, Peter McCrory, Ruth Appel, and Ryan Heller. An- thropic economic index repor...
-
[2]
This yields 20 clusters covering 57.4% of all prompts, with cluster sizes ranging from 152 to 4,329 (median: 256)
with min_cluster_size=150 and min_samples=5. This yields 20 clusters covering 57.4% of all prompts, with cluster sizes ranging from 152 to 4,329 (median: 256). The remaining 8,265 prompts (42.6%) are classified as noise, reflecting the diversity of coding session prompts that do not form tight semantic groups. For each cluster, we select the 100 prompts w...
2026
-
[3]
List the specific technologies, libraries, and project details mentioned. 25
-
[4]
Set all of those aside. What **general software engineering activity** unites these prompts? Think in terms of the development lifecycle: planning, prototyping, implementing features, debugging, testing, deploying, configuring infrastructure, designing APIs, refactoring, reviewing code, etc
-
[5]
""Run the project's build step and return stdout
What makes this activity more specific than just "coding"? Is it about a particular layer of the stack (frontend, backend, infra, data, auth)? A particular phase ( greenfield build vs. maintenance)? A particular style of work (exploratory vs. fixing vs. migrating)? Then produce a single cluster label (4-10 words). The label must: - Be understandable to an...
2000
-
[6]
First, two annotators iteratively refined the codebook until they agreed on all labels for 10 data points
-
[7]
We computed inter-annotator agreement metrics using the results from this stage
Second, the same two humans proceeded to independently annotate NIAA = 90 additional data points. We computed inter-annotator agreement metrics using the results from this stage. The results in Tables 6 and 7 show that agreement was moderate-high for all tasks. This includes a binary version of the prompt pushback tasks that collapses all classification c...
-
[8]
"domain"
Finally, the same two humans discussed all disagreements and decided on the most appropriate gold label for each data point. Together with the 10 data points from stage 1, this yielded Ngold = 100 gold labels for evaluating LLM annotation performance. We use Cohen’sκ to measure human-human and LLM-human agreement for multi-class annotation tasks, and addi...
1960
-
[9]
Expert Nitpicker - Deep domain knowledge; high and consistent standards - Gives precise, technically specific instructions or corrections - Notices subtle issues and requests exact adjustments - Goal remains stable throughout; corrections refine execution, not direction
-
[10]
Vague Requester - Broad strokes only; underspecified goals - Missing constraints; leaves many decisions to the model - Does not correct or redirect in detail
-
[11]
Mind Changer - Shifts the overall goal or requirements mid-session - Contradicts or reverses earlier instructions - Corrections change direction, not just execution details
-
[12]
Other" for sessions where no pattern is discernible. OUTPUT FORMAT (JSON only): Return exactly one JSON with the following keys:
Other (use only when the session is too brief to judge, or the user's behavior clearly does not match any of the above) Disambiguation: - Expert Nitpicker vs Mind Changer: an Expert Nitpicker corrects HOW the model executes a stable goal; a Mind Changer revises WHAT the goal is. Repeated precise corrections within the same goal = Expert Nitpicker. - Exper...
-
[13]
The full conversation transcript (user messages and agent responses)
-
[14]
A summary of tool calls made during the session (category counts, top tools)
-
[15]
## Evaluation procedure First, analyze the session along five dimensions
Commit information, if any (commit messages and diff summaries). ## Evaluation procedure First, analyze the session along five dimensions. For each, note concrete evidence from the transcript
-
[16]
For each, judge whether it was fully resolved, partially resolved, or unresolved
**Goal completion**: Did the agent fulfill what the user asked for? Identify every distinct user request or task. For each, judge whether it was fully resolved, partially resolved, or unresolved
-
[17]
An abrupt stop (user abandons mid-task, expresses frustration, or silently disengages after an unresolved error) is negative
**Final session state**: How did the session end? A natural conclusion (user confirms satisfaction, moves on to a new topic, or signs off) is positive. An abrupt stop (user abandons mid-task, expresses frustration, or silently disengages after an unresolved error) is negative. Weigh the ending heavily - a session that goes well for many turns but ends in ...
-
[18]
Positive signals include: appropriate use of research tools before acting, surfacing uncertainty and offering the user choices, and recovering from errors autonomously
**Agent efficiency**: Did the agent make steady progress, or did it spin? Negative signals include: the user repeating the same instruction or correction, the agent retrying a failed approach without changing strategy, and unnecessary tool calls that do not advance the task. Positive signals include: appropriate use of research tools before acting, surfac...
-
[19]
**Code and commit quality**: If code was produced, does it appear correct and complete based on the available evidence (test results, diff content, user reactions)? Were changes committed? Commits are a strong positive signal for task- oriented sessions but are not required for short advisory or exploratory sessions where no code change was the expected outcome
-
[20]
score": <integer 0-100>,
**User experience**: Did the user have to fight the agent, or did the interaction flow naturally? Look for signs of satisfaction (thanks, approval, moving to the next task) and dissatisfaction (re-explaining, correcting, expressing frustration) . 37 ## Scoring rubric After analyzing the five dimensions, assign a single integer score from 0 to 100. - **90-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.