Not All NVFP4 QAT Recipes Are Equal: How Architecture and Scale Shape Model Quality for Anomaly Segmentation
Pith reviewed 2026-06-29 18:09 UTC · model grok-4.3
The pith
Architecture choice has the largest impact on FP4 quantization robustness for anomaly segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
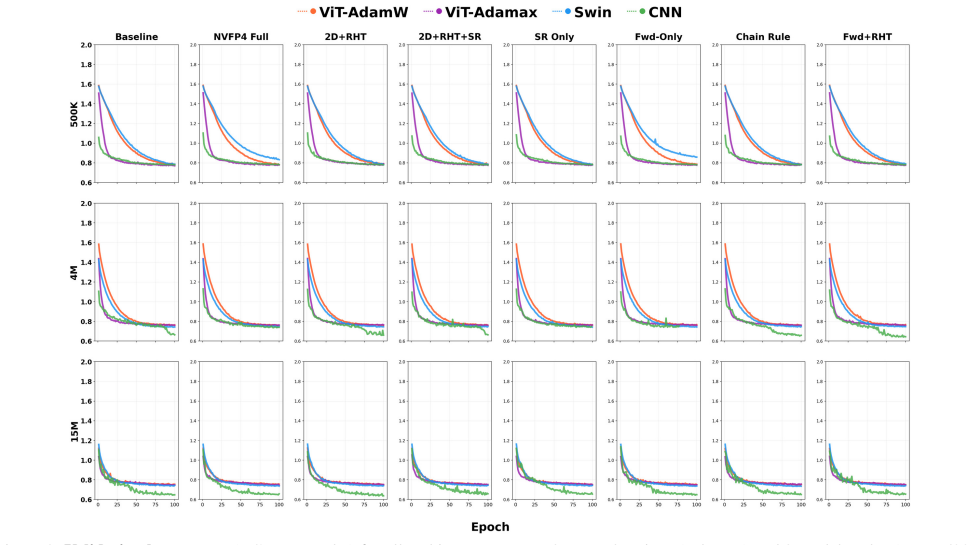
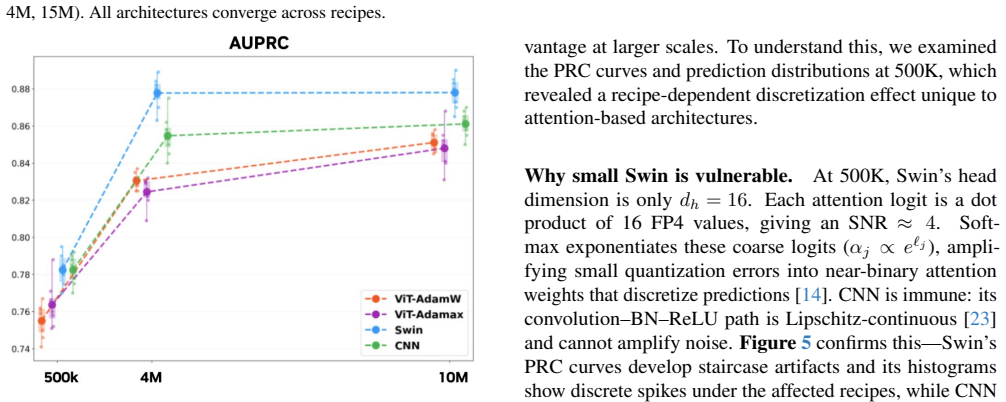
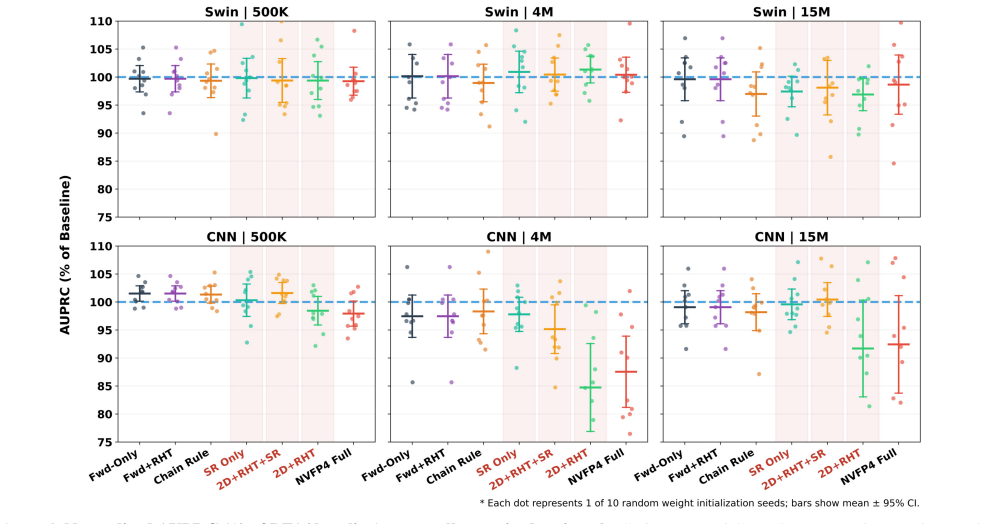
Architecture choice has the largest impact on quantization robustness, with attention-based architectures showing remarkable resilience to recipe choice while CNN degrades under gradient-quantizing recipes at larger scales. The Swin Transformer is robust to QAT recipe choice across all scales.
What carries the argument
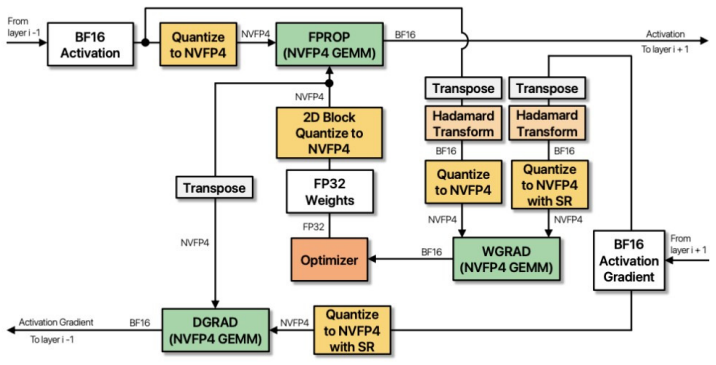
The three-way interaction of architecture, scale, and FP4 QAT recipe evaluated on recall-critical brain tumor segmentation under a unified protocol.
If this is right
- At low capacity, FP4 can discretize softmax attention, but advanced QAT recipes prevent this collapse.
- At larger scales, advanced recipes mitigate gradient quantization noise that degrades CNN quality.
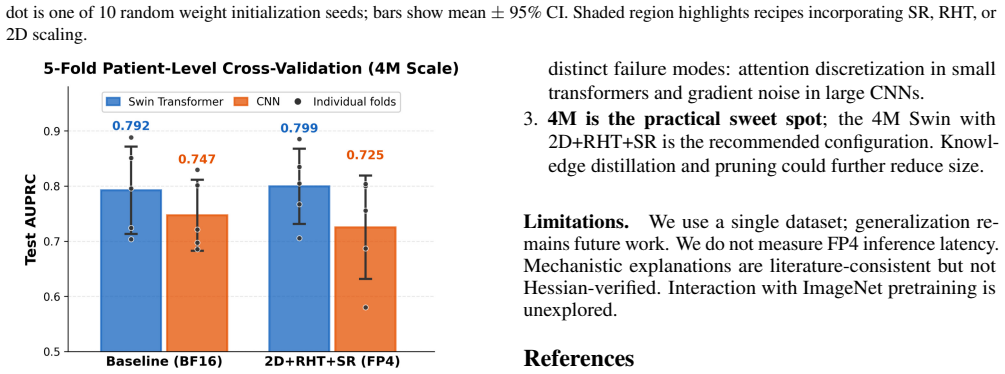
- Five-fold patient-level cross-validation confirms these findings are robust to data partition.
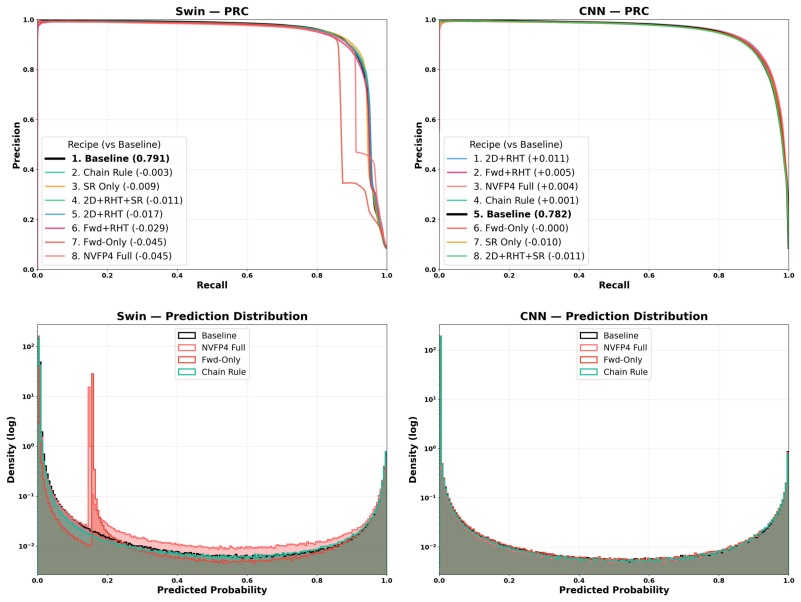
- The Swin Transformer is recommended for FP4-quantized anomaly segmentation.
Where Pith is reading between the lines
- The resilience pattern may appear in other medical imaging tasks that need low-precision inference.
- Developers targeting FP4 should prioritize architecture selection before tuning QAT recipes.
- Testing the same protocol on non-medical anomaly detection datasets would show whether the architecture effect is domain-specific.
Load-bearing premise
The observed three-way interactions between architecture, scale, and QAT recipe are assumed to be driven primarily by the model properties rather than by unexamined dataset-specific factors or implementation details of the unified evaluation protocol.
What would settle it
Repeating the experiments on a different anomaly segmentation dataset and finding that the architecture-dependent degradation patterns under gradient-quantizing recipes disappear would falsify the central claim.
Figures

read the original abstract
Real-time anomaly segmentation demands both high recall and efficient low-precision inference. We study the three-way interaction of model architecture, model scale, and FP4 quantization-aware training (QAT) recipe on a recall-critical brain tumor segmentation task, evaluating multiple architectures, scales, and QAT recipes under a unified protocol. We find that architecture choice has the largest impact on quantization robustness, with attention-based architectures showing remarkable resilience to recipe choice while CNN degrades under gradient-quantizing recipes at larger scales. At low capacity, FP4 can discretize softmax attention, but advanced QAT recipes prevent this collapse. At larger scales, advanced recipes mitigate gradient quantization noise that degrades CNN quality. Five-fold patient-level cross-validation confirms these findings are robust to data partition. Our results show that the Swin Transformer is robust to QAT recipe choice across all scales, making it the recommended architecture for FP4-quantized anomaly segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines the three-way interaction of architecture, model scale, and FP4 quantization-aware training (QAT) recipes for recall-critical anomaly segmentation on a brain tumor task. Under a unified evaluation protocol with multiple architectures and scales, it reports that architecture exerts the largest effect on quantization robustness: attention-based models exhibit resilience to recipe choice while CNNs degrade under gradient-quantizing recipes at larger scales. At low capacity FP4 can discretize softmax attention but advanced recipes avoid collapse; at scale advanced recipes mitigate gradient noise for CNNs. Five-fold patient-level cross-validation is used to confirm stability to data partitions. The Swin Transformer is identified as robust across scales and recommended for FP4-quantized anomaly segmentation.
Significance. If the reported interactions hold, the work supplies actionable guidance for architecture selection in low-precision real-time anomaly segmentation, particularly highlighting the practical advantage of attention-based models for FP4 deployment. The explicit use of 5-fold patient-level CV to demonstrate partition robustness is a methodological strength that supports the internal reliability of the empirical comparisons.
major comments (1)
- [Abstract] Abstract: The central claim that 'architecture choice has the largest impact on quantization robustness' and the resulting recommendation of the Swin Transformer for FP4-quantized anomaly segmentation rest on experiments confined to a single brain tumor segmentation task under one unified protocol. While 5-fold patient-level CV addresses stability to data splits, the absence of additional datasets, tasks, or protocol variations means the observed three-way interactions (attention resilience vs. CNN degradation) could be driven by dataset statistics or implementation details rather than intrinsic architectural properties; this directly affects the load-bearing general recommendation.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the methodological strengths of the 5-fold patient-level cross-validation. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'architecture choice has the largest impact on quantization robustness' and the resulting recommendation of the Swin Transformer for FP4-quantized anomaly segmentation rest on experiments confined to a single brain tumor segmentation task under one unified protocol. While 5-fold patient-level CV addresses stability to data splits, the absence of additional datasets, tasks, or protocol variations means the observed three-way interactions (attention resilience vs. CNN degradation) could be driven by dataset statistics or implementation details rather than intrinsic architectural properties; this directly affects the load-bearing general recommendation.
Authors: We acknowledge that the experiments are confined to a single brain tumor segmentation task and dataset. The unified protocol across architectures and scales isolates the three-way interactions under controlled conditions, and the 5-fold patient-level CV demonstrates robustness to data partitions within this setting. However, we agree that the load-bearing general recommendation in the abstract exceeds the scope of the evidence. We will therefore revise the abstract to qualify the recommendation as applying to the studied brain tumor segmentation task and add an explicit limitations paragraph discussing the need for validation on additional datasets and tasks. This constitutes a partial revision that preserves the core empirical findings while addressing the generalizability concern. revision: partial
Circularity Check
No circularity: empirical comparison with no derivations or fitted predictions
full rationale
The paper is an empirical study evaluating architecture-scale-QAT recipe interactions on brain tumor segmentation via 5-fold patient-level CV under a unified protocol. No equations, parameter fits, self-definitional claims, or load-bearing self-citations appear in the provided text. All reported outcomes are direct experimental measurements rather than reductions of inputs by construction. This matches the default case of a self-contained empirical paper (score 0-2).
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Surface defect inspection of industrial products with object detection deep networks: A systematic review.Artificial Intelligence Review, 57(257), 2024
Wenbo Chen et al. Surface defect inspection of industrial products with object detection deep networks: A systematic review.Artificial Intelligence Review, 57(257), 2024. 1
2024
-
[2]
Low dosage SEM image processing for metrology applications
Zijian Du, Lingling Pu, Jiaoying Tan, Paul Wei, and Jeeeon Kim. Low dosage SEM image processing for metrology applications. InMetrology, Inspection, and Process Control XXXVI, volume 12053, pages 59–67. SPIE, 2022
2022
-
[3]
Zijian Du, Lingling Pu, Paul Wei, Rui Yuan, Jeeeon Kim, and Jiaoying Tan. Unsupervised neural network-based image restoration framework for pattern fidelity improvement and ro- bust metrology.Journal of Micro/Nanopatterning, Materials, and Metrology, 22(3):034201, 2023. 1
2023
-
[4]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. InIEEE International Conference on Computer Vision (ICCV), pages 2980–2988, 2017. 1
2017
-
[5]
Tversky loss function for image segmentation using 3D fully convolutional deep networks
Seyed Sadegh Mohseni Salehi, Deniz Erdogmus, and Ali Gholipour. Tversky loss function for image segmentation using 3D fully convolutional deep networks. InInternational Workshop on Machine Learning in Medical Imaging (MLMI), pages 379–387. Springer, 2017. 1, 2
2017
-
[6]
The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets.PLOS ONE, 10(3): e0118432, 2015
Takaya Saito and Marc Rehmsmeier. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets.PLOS ONE, 10(3): e0118432, 2015. 1, 2, 4
2015
-
[7]
Introducing NVFP4 for efficient and accurate low- precision inference
NVIDIA. Introducing NVFP4 for efficient and accurate low- precision inference. NVIDIA Developer Blog, 2025. 1, 3, 4
2025
-
[8]
Training LLMs with MXFP4
Albert Tseng et al. Training LLMs with MXFP4. InPro- ceedings of the 42nd International Conference on Machine Learning (ICML). PMLR, 2025. 3, 7
2025
-
[9]
FP4 all the way: Fully quantized training of LLMs
Ruizhe Xi et al. FP4 all the way: Fully quantized training of LLMs.arXiv preprint arXiv:2505.19115, 2025. 1, 3, 7
-
[10]
U-Net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Inter- vention (MICCAI), pages 234–241. Springer, 2015. 1, 2, 3
2015
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representa- tions (ICLR), 2021....
2021
-
[12]
Swin Transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin Transformer: Hierarchical vision transformer using shifted windows. In IEEE/CVF International Conference on Computer Vision (ICCV), pages 10012–10022, 2021. 1, 2, 3, 5
2021
-
[13]
Transformers learn low sensitivity func- tions: Investigations and implications
Bhavya Vasudeva, Shreyas Bhattamishra, Varun Kanade, and Lenka Zdeborova. Transformers learn low sensitivity func- tions: Investigations and implications. InInternational Con- ference on Learning Representations (ICLR), 2025. 1, 2, 7
2025
-
[14]
Why are sensitive functions hard for transformers? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
Michael Hahn and Mark Rofin. Why are sensitive functions hard for transformers? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. 2, 6
2024
-
[15]
How do vision transformers work? InInternational Conference on Learning Representa- tions (ICLR), 2022
Namuk Park and Songkuk Kim. How do vision transformers work? InInternational Conference on Learning Representa- tions (ICLR), 2022. 1, 2, 7
2022
-
[16]
Training data-efficient image transformers & distillation through at- tention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herv´e J´egou. Training data-efficient image transformers & distillation through at- tention. InProceedings of the 38th International Conference on Machine Learning (ICML), pages 10347–10357. PMLR,
-
[17]
Mazurowski
Mateusz Buda, Ashirbani Saha, and Maciej A. Mazurowski. Association of genomic subtypes of lower-grade gliomas with shape features automatically extracted by a deep learning algorithm.Computers in Biology and Medicine, 109:218– 225, 2019. 1, 3
2019
-
[18]
A novel focal tversky loss function with improved attention U-Net for le- sion segmentation
Nabila Abraham and Naimul Mefraz Khan. A novel focal tversky loss function with improved attention U-Net for le- sion segmentation. InIEEE International Symposium on Biomedical Imaging (ISBI), pages 683–687, 2019. 2
2019
-
[19]
Michael Yeung, Evis Sala, Carola-Bibiane Sch ¨onlieb, and Leonardo Rundo. Unified focal loss: Generalising dice and cross entropy-based losses to handle class imbalanced medi- cal image segmentation.Computerized Medical Imaging and Graphics, 95:102026, 2022. 2
2022
-
[20]
McDermott, Lasse Hansen, Giovanni An- gelotti, Jack Gallifant, Fabian Pl¨otz, Leo Anthony Celi, and Marzyeh Ghassemi
Matthew B.A. McDermott, Lasse Hansen, Giovanni An- gelotti, Jack Gallifant, Fabian Pl¨otz, Leo Anthony Celi, and Marzyeh Ghassemi. A closer look at AUROC and AUPRC under class imbalance. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 2
2024
-
[21]
Vi- sion transformers for dense prediction
Ren´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InIEEE International Conference on Computer Vision (ICCV), pages 12179–12188,
-
[22]
Transformers in medical imaging: A survey
Fahad Shamshad, Salman Khan, Syed Waqas Zamir, Muham- mad Haris Khan, Munawar Hayat, Fahad Shahbaz Khan, and Huazhu Fu. Transformers in medical imaging: A survey. Medical Image Analysis, 88:102802, 2023. 2
2023
-
[23]
Towards understanding regularization in batch normalization
Ping Luo, Xinjiang Wang, Wenqi Shao, and Zhanglin Peng. Towards understanding regularization in batch normalization. InInternational Conference on Learning Representations (ICLR), 2019. 2, 6, 7
2019
-
[24]
Bayesian uncertainty estimation for batch normalized deep networks
Mattias Teye, Hossein Azizpour, and Kevin Smith. Bayesian uncertainty estimation for batch normalized deep networks. In Proceedings of the 35th International Conference on Machine Learning (ICML), pages 4907–4916. PMLR, 2018. 2
2018
-
[25]
Ali Edalati et al. Bridging the gap between promise and per- formance for microscaling FP4 quantization.arXiv preprint arXiv:2509.23202, 2025. 3
-
[26]
Jongmin Lee et al. TetraJet: Mitigating weight oscillation for robust MXFP4 vision transformer training.arXiv preprint arXiv:2502.20853, 2025. 3, 7
-
[27]
Stochastic rounding for LLM training: Theory and practice
Kaan Ozkara, Tao Yu, and Jongho Park. Stochastic rounding for LLM training: Theory and practice. InProceedings of the 28th International Conference on Artificial Intelligence and Statistics (AISTATS). PMLR, 2025. 3, 4
2025
-
[28]
Pretraining large language models with NVFP4.arXiv preprint arXiv:2509.25149,
Felix Abecassis, Anjulie Agrusa, Dong Ahn, Jonah Alben, et al. Pretraining large language models with NVFP4.arXiv preprint arXiv:2509.25149, 2025. 4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.