From Shield to Target: Denial-of-Service Attacks on LLM-Based Agent Guardrails
Pith reviewed 2026-06-27 04:39 UTC · model grok-4.3
The pith
Attackers can inject crafted data to trap LLM guardrails in extended reasoning loops and cause denial-of-service on autonomous agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
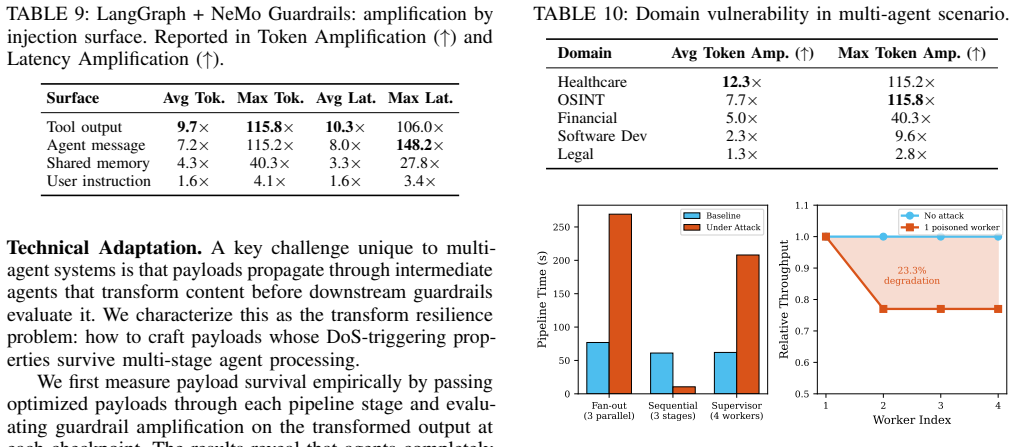
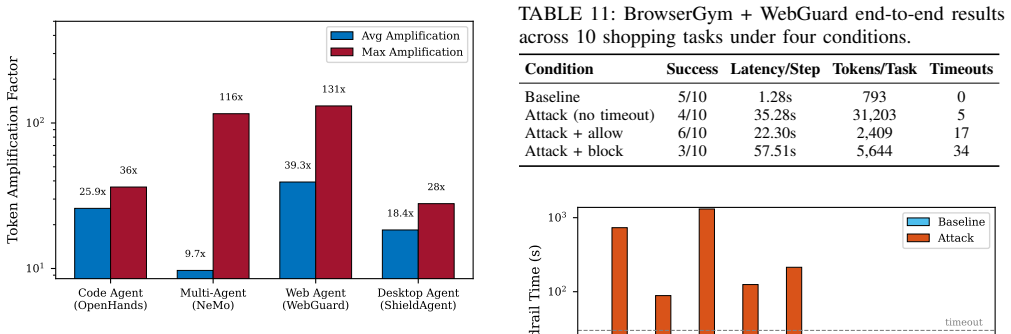
Attackers can inject crafted data to trap the guardrail in extended reasoning loops, effectuating a systematic denial-of-service attack. Payloads optimized on a single open-source surrogate transfer to eight leading model backbones, achieving 13-63x token amplification and up to 148x latency amplification in end-to-end deployments; one poisoned document can saturate shared infrastructures and paralyze co-located agents.
What carries the argument
Beam-search optimization framework that uses an LLM proposer guided by a strategy bank to craft natural-language payloads maximizing guardrail reasoning length, plus a second framework of mechanism-aware structural mutations that exploit schema-following to increase reasoning length.
If this is right
- Payloads transfer across diverse guardrail architectures, safety templates, and agent benchmarks.
- A single poisoned document can saturate shared guardrail infrastructures and starve co-located agents.
- The attack produces measurable token and latency amplification in both standalone and real-world web, desktop, code, and multi-agent deployments.
- Current guardrails that rely on unbounded reasoning introduce an availability flaw.
Where Pith is reading between the lines
- Guardrail designs may need explicit cost or length bounds on reasoning steps to limit this exposure.
- Similar reasoning-loop attacks could affect other LLM components that must parse and act on untrusted structured input.
- Evaluation suites for guardrails should include worst-case latency and token-consumption tests under adversarial inputs.
Load-bearing premise
The guardrail will follow its schema and keep reasoning on mutated inputs without detecting or rejecting them even when reasoning length grows.
What would settle it
A test showing that every payload generated by the optimization or mutations either gets rejected by the guardrail or produces reasoning length no higher than an unoptimized baseline input.
Figures







read the original abstract
LLM-based guardrails have emerged as a highly effective defense against prompt injection and jailbreak attacks in autonomous agents. However, we reveal that the very reasoning and task-following capabilities enabling this protection introduce a novel vulnerability: attackers can inject crafted data to trap the guardrail in extended reasoning loops, effectuating a systematic denial-of-service (DoS) attack. To systematically expose this threat, we design a beam-search optimization framework that crafts natural-language payloads to maximize guardrail reasoning length, utilizing an LLM proposer guided by a strategy bank. Based on the observation of guardrail's schema-following nature, we also provide another attack framework driven by mechanism-aware structural mutations with less computational load. The attack efficacy is systematically evaluated in two parts. First, in standalone evaluations, the attack generalizes across diverse guardrail architectures, safety templates, and agent benchmarks. Payloads optimized on a single open-source surrogate successfully transfer to eight leading model backbones (e.g., Claude, GPT, Gemini, DeepSeek, and Qwen), achieving a 13--63$\times$ token amplification. Second, in end-to-end real-world agent deployments (web, desktop, code, and multi-agent systems), the attack reveals up to a 148$\times$ latency amplification. We show that a single poisoned document can saturate shared guardrail infrastructures, effectively starving co-located agents and paralyzing the entire system. By uncovering this availability flaw, our work underscores the urgent need to develop cost-bounded, reasoning-robust guardrails.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-based guardrails for autonomous agents can be turned into denial-of-service vectors by injecting crafted payloads that trap them in extended reasoning loops. It introduces a beam-search optimization framework using an LLM proposer and strategy bank, plus a lighter mechanism-aware structural-mutation framework exploiting schema-following behavior. Standalone tests show transfer from one open-source surrogate to eight commercial models (Claude, GPT, Gemini, etc.) with 13–63× token amplification; end-to-end deployments (web, desktop, code, multi-agent) show up to 148× latency amplification and system-wide saturation from a single poisoned document.
Significance. If the empirical results hold, the work identifies a previously unexamined availability attack surface on guardrails that are otherwise promoted as defenses against injection and jailbreaks. The surrogate-to-target transfer results and real-deployment measurements constitute concrete, falsifiable evidence that could drive design changes toward cost-bounded reasoning. The absence of free parameters or circular derivations in the attack construction is a methodological strength.
major comments (3)
- [Abstract and standalone evaluations] Abstract and evaluation sections: rejection rates for the structurally mutated payloads are not reported on the target models. Without these rates it is impossible to determine whether the observed 13–63× amplification occurs because the mutations pass existing validation logic or only because the evaluated guardrails are unusually permissive.
- [Standalone evaluations] Standalone evaluations: the manuscript provides no baseline comparisons (e.g., random payloads, non-optimized mutations, or length-controlled inputs) or statistical tests for the reported amplification factors. This leaves open whether the transfer success is driven by the proposed optimization or by generic properties of long inputs.
- [End-to-end real-world agent deployments] End-to-end real-world deployments: the claim that a single poisoned document can starve co-located agents and paralyze shared guardrail infrastructure lacks quantitative details on resource contention, scheduling, and measurement of starvation effects across the multi-agent setups.
minor comments (2)
- [Abstract] The en-dash notation “13--63×” in the abstract should be replaced by “13–63×” or “13 to 63×” for typographic consistency.
- Ensure every model backbone and benchmark cited in the transfer and deployment results is accompanied by a reference or version identifier in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, with clear indications of planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract and standalone evaluations] Abstract and evaluation sections: rejection rates for the structurally mutated payloads are not reported on the target models. Without these rates it is impossible to determine whether the observed 13–63× amplification occurs because the mutations pass existing validation logic or only because the evaluated guardrails are unusually permissive.
Authors: We agree that explicit rejection rates for the structurally mutated payloads on the eight target models were not reported. The amplification numbers were computed only on payloads that reached the guardrail reasoning stage. To resolve this ambiguity and demonstrate that the effect is not an artifact of unusually permissive filters, we will add a dedicated table in the standalone evaluation section reporting per-model rejection rates for both the beam-search and structural-mutation payloads, together with the corresponding amplification factors on accepted payloads. revision: yes
-
Referee: [Standalone evaluations] Standalone evaluations: the manuscript provides no baseline comparisons (e.g., random payloads, non-optimized mutations, or length-controlled inputs) or statistical tests for the reported amplification factors. This leaves open whether the transfer success is driven by the proposed optimization or by generic properties of long inputs.
Authors: The manuscript already contrasts the two proposed attack frameworks, but we acknowledge the absence of random-payload and length-matched baselines as well as formal statistical tests. We will incorporate these comparisons (random strings, non-optimized mutations, and length-controlled inputs) and add statistical significance testing (paired t-tests and confidence intervals across repeated trials) to the standalone evaluation section to isolate the contribution of the optimization procedures. revision: yes
-
Referee: [End-to-end real-world agent deployments] End-to-end real-world deployments: the claim that a single poisoned document can starve co-located agents and paralyze shared guardrail infrastructure lacks quantitative details on resource contention, scheduling, and measurement of starvation effects across the multi-agent setups.
Authors: The end-to-end section reports observed latency amplification and system saturation, yet we recognize that finer-grained metrics on resource contention, scheduler behavior, and starvation duration were not quantified. We will expand this section with additional instrumentation, including per-agent CPU/memory traces, queue-depth measurements, and explicit starvation timelines under controlled multi-agent workloads, to provide the requested quantitative support. revision: yes
Circularity Check
Empirical attack evaluation with no circular derivations
full rationale
The paper presents an empirical study of DoS attacks on LLM guardrails via beam-search optimization and mechanism-aware structural mutations. Reported amplification factors (13-63× token, up to 148× latency) are measured outcomes from standalone evaluations and end-to-end deployments across multiple models and systems. No equations, derivations, or fitted parameters are used to obtain these quantities; the results follow directly from experimental transfer tests on open-source surrogates to production backbones. The schema-following observation is presented as an empirical basis for one attack variant rather than a self-referential definition. No self-citation chains or uniqueness theorems appear as load-bearing elements. The work is self-contained against external benchmarks via cross-model and real-world testing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Guardrails exhibit schema-following behavior that can be exploited for structural mutations to increase reasoning length
Reference graph
Works this paper leans on
-
[1]
Introducing operator,
OpenAI, “Introducing operator,” https://openai.com/index/ introducing-operator/, 2025
2025
-
[2]
Project mariner,
Google DeepMind, “Project mariner,” https://deepmind.google/ technologies/project-mariner/, 2024
2024
-
[3]
The BrowserGym ecosystem for web agent research,
T. Le Sellier de Chezelles, A. Drouin, M. Caccia, L. Boisvertet al., “The BrowserGym ecosystem for web agent research,”Transactions on Machine Learning Research, 2025, arXiv:2412.05467
arXiv 2025
-
[4]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real com- puter environments,
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Caoet al., “OSWorld: Benchmarking multimodal agents for open-ended tasks in real com- puter environments,” inNeurIPS, vol. 37, 2024, arXiv:2404.07972
Pith/arXiv arXiv 2024
-
[5]
Introducing computer use, a new Claude 3.5 Son- net, and Claude 3.5 Haiku,
Anthropic, “Introducing computer use, a new Claude 3.5 Son- net, and Claude 3.5 Haiku,” https://www.anthropic.com/news/ 3-5-models-and-computer-use, 2024
2024
-
[6]
OpenHands: An open platform for AI software developers as generalist agents,
X. Wang, B. Li, Y . Songet al., “OpenHands: An open platform for AI software developers as generalist agents,” inICLR, 2025, arXiv:2407.16741
Pith/arXiv arXiv 2025
-
[7]
SWE-bench: Can language models resolve real-world GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve real-world GitHub issues?” inICLR, 2024, arXiv:2310.06770
Pith/arXiv arXiv 2024
-
[8]
Supply-chain poisoning attacks against LLM coding agent skill ecosystems,
Y . Qu, Y . Liuet al., “Supply-chain poisoning attacks against LLM coding agent skill ecosystems,”arXiv preprint arXiv:2604.03081, 2026
Pith/arXiv arXiv 2026
-
[9]
LangGraph: Multi-agent orchestration framework,
LangChain, Inc., “LangGraph: Multi-agent orchestration framework,” https://github.com/langchain-ai/langgraph, 2024
2024
-
[10]
AutoGen: Enabling next-gen LLM applications via multi- agent conversation,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “AutoGen: Enabling next-gen LLM applications via multi- agent conversation,”arXiv preprint arXiv:2308.08155, 2023
Pith/arXiv arXiv 2023
-
[11]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injections,” inAISec, 2023, arXiv:2302.12173
Pith/arXiv arXiv 2023
-
[12]
Ignore previous prompt: Task-oriented conversational modeling,
F. Perez and I. Ribeiro, “Ignore previous prompt: Task-oriented conversational modeling,” inNeurIPS Workshop on Machine Learning Safety, 2022, arXiv:2211.09527
Pith/arXiv arXiv 2022
-
[13]
Universal and transferable adversarial attacks on aligned language models,
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
-
[14]
Jailbroken: How does LLM safety training fail?
A. Wei, N. Haghtalab, and J. Steinhardt, “Jailbroken: How does LLM safety training fail?” inNeurIPS, vol. 36, 2023, arXiv:2307.02483
Pith/arXiv arXiv 2023
-
[15]
Y . Mou, Z. Xue, L. Li, P. Liu, S. Zhang, W. Ye, and J. Shao, “Enhancing tool invocation safety of LLM-based agents via proactive step-level guardrail and feedback,”arXiv preprint arXiv:2601.10156, 2026
arXiv 2026
-
[16]
The task shield: Enforcing task alignment to defend against indirect prompt injection in LLM agents,
F. Jia, T. Wu, X. Qin, and A. Squicciarini, “The task shield: Enforcing task alignment to defend against indirect prompt injection in LLM agents,” inACL, 2025, arXiv:2412.16682
arXiv 2025
-
[17]
ShieldAgent: Shielding agents via verifiable safety policy reasoning,
Z. Chen, M. Kang, and B. Li, “ShieldAgent: Shielding agents via verifiable safety policy reasoning,” inICML, ser. Proceedings of Machine Learning Research, vol. 267, 2025, pp. 8313–8344
2025
-
[18]
LlamaFirewall: An open source guardrail system for building secure AI agents,
S. Chennabasappa, C. Nikolaidis, D. Song, D. Molnar, S. Ding, S. Wan, S. Whitman, L. Deason, N. Doucette, A. Montillaet al., “LlamaFirewall: An open source guardrail system for building secure AI agents,”arXiv preprint arXiv:2505.03574, 2025
arXiv 2025
-
[19]
OWASP top 10 for large language model applications,
OWASP Foundation, “OWASP top 10 for large language model applications,” OWASP Foundation, Tech. Rep., 2023. [Online]. Available: https://owasp.org/ www-project-top-10-for-large-language-model-applications/
2023
-
[20]
Introducing Codex,
OpenAI, “Introducing Codex,” https://openai.com/index/ introducing-codex/, 2025
2025
-
[21]
Claude 3.7 Sonnet and Claude Code,
Anthropic, “Claude 3.7 Sonnet and Claude Code,” https://www. anthropic.com/news/claude-3-7-sonnet, 2025
2025
-
[22]
AgentHarm: A benchmark for measuring harmfulness of LLM agents,
M. Andriushchenko, F. Croce, N. Flammarionet al., “AgentHarm: A benchmark for measuring harmfulness of LLM agents,”arXiv preprint arXiv:2410.09024, 2024
Pith/arXiv arXiv 2024
-
[23]
AgentDojo: A dynamic environment to evaluate attacks and defenses for LLM agents,
E. Debenedetti, J. Zhang, M. Balunovi ´c, L. Beurer-Kellner, M. Fischer, and F. Tram`er, “AgentDojo: A dynamic environment to evaluate attacks and defenses for LLM agents,” inNeurIPS, vol. 37, 2024
2024
-
[24]
Agent security bench (ASB): Formalizing and bench- marking attacks and defenses in LLM-based agents,
H. Zhang, J. Huang, K. Mei, Y . Yao, Z. Wang, C. Zhan, H. Wang, and Y . Zhang, “Agent security bench (ASB): Formalizing and bench- marking attacks and defenses in LLM-based agents,”arXiv preprint arXiv:2410.02644, 2024
Pith/arXiv arXiv 2024
-
[25]
Formalizing and benchmarking prompt injection attacks and defenses,
Y . Liu, Y . Jia, R. Geng, J. Jia, and N. Z. Gong, “Formalizing and benchmarking prompt injection attacks and defenses,” inUSENIX Security, 2024, arXiv:2310.12815
arXiv 2024
-
[26]
Jailbreaking leading safety-aligned LLMs with simple adaptive attacks,
M. Andriushchenko, F. Croce, and N. Flammarion, “Jailbreaking leading safety-aligned LLMs with simple adaptive attacks,” inICLR, 2025, arXiv:2404.02151
arXiv 2025
-
[27]
W. Hackett, L. Birch, S. Trawicki, N. Suri, and P. Garraghan, “Bypassing LLM guardrails: An empirical analysis of evasion attacks against prompt injection and jailbreak detection systems,” inLLMSec Workshop @ ACL, 2025, arXiv:2504.11168
arXiv 2025
-
[28]
Llama Guard: LLM-based input-output safeguard for human-AI conversations,
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testuggine, and M. Khabsa, “Llama Guard: LLM-based input-output safeguard for human-AI conversations,”arXiv preprint arXiv:2312.06674, 2023
Pith/arXiv arXiv 2023
-
[29]
DeBERTa-v3-base prompt injection v2,
ProtectAI, “DeBERTa-v3-base prompt injection v2,” https:// huggingface.co/protectai/deberta-v3-base-prompt-injection-v2, 2024
2024
-
[30]
LLM defenses are not robust to multi-turn human jailbreaks yet,
N. Li, Z. Han, I. Steneker, W. Primack, R. Goodsideet al., “LLM defenses are not robust to multi-turn human jailbreaks yet,”arXiv preprint arXiv:2408.15221, 2024
arXiv 2024
-
[31]
On guardrail models’ robustness to mutations and adversarial attacks,
E. Bassani and I. Sanchez, “On guardrail models’ robustness to mutations and adversarial attacks,” inEMNLP Findings, 2025
2025
-
[32]
M. Nasr, N. Carlini, C. Sitawarin, S. V . Schulhoff, J. Hayeset al., “The attacker moves second: Stronger adaptive attacks bypass de- fenses against LLM jailbreaks and prompt injections,”arXiv preprint arXiv:2510.09023, 2025
Pith/arXiv arXiv 2025
-
[33]
OverThink: Slowdown attacks on reasoning LLMs,
A. Kumar, J. Roh, A. Naseh, M. Karpinska, M. Iyyer, A. Houmansadr, and E. Bagdasarian, “OverThink: Slowdown attacks on reasoning LLMs,” inICLR, 2026, arXiv:2502.02542
arXiv 2026
-
[34]
X. Liu, X. Wang, Y . Zhang, S. Kariyappa, C. Xiang, M. Chenet al., “ReasoningBomb: A stealthy denial-of-service attack by inducing pathologically long reasoning in large reasoning models,”arXiv preprint arXiv:2602.00154, 2026
arXiv 2026
-
[35]
An Engorgio prompt makes large language model babble on,
J. Dong, Z. Zhang, Q. Zhang, T. Zhang, H. Wang, H. Li, Q. Li, C. Zhang, K. Xu, and H. Qiu, “An Engorgio prompt makes large language model babble on,” inICLR, 2025
2025
-
[36]
Crabs: Consuming resource via auto-generation for LLM-DoS attack under black-box settings,
Y . Zhang, Z. Zhou, W. Zhang, X. Wang, X. Jia, Y . Liu, and S. Su, “Crabs: Consuming resource via auto-generation for LLM-DoS attack under black-box settings,” inACL Findings, Vienna, Austria, 2025, pp. 11 128–11 150
2025
-
[37]
Z. Wang, Y . Zhang, J. Chen, Z. Zhou, R. Liang, R. Du, J. Jia, C. Wu, and Y . Liu, “RECUR: Resource exhaustion attack via recursive- entropy guided counterfactual utilization and reflection,”arXiv preprint arXiv:2602.08214, 2026
arXiv 2026
-
[38]
ThinkTrap: Denial-of-service attacks against black-box LLM services via infinite thinking,
Y . Li, J. Wang, H. Zhu, J. Lin, S. Chang, and M. Guo, “ThinkTrap: Denial-of-service attacks against black-box LLM services via infinite thinking,” inNDSS, 2026
2026
-
[40]
Baseline defenses for adversarial attacks against aligned language models,
N. Jain, A. Schwarzschild, Y . Wen, G. Somepalli, J. Kirchenbauer, P.-y. Chiang, M. Goldblum, A. Saha, J. Geiping, and T. Goldstein, “Baseline defenses for adversarial attacks against aligned language models,”arXiv preprint arXiv:2309.00614, 2023
Pith/arXiv arXiv 2023
-
[41]
Detecting language model attacks with perplexity,
G. Alon and M. Kamfonas, “Detecting language model attacks with perplexity,”arXiv preprint arXiv:2308.14132, 2023
Pith/arXiv arXiv 2023
-
[42]
MELON: Provable defense against indirect prompt injection attacks in AI agents,
K. Zhu, X. Yang, J. Wang, W. Guo, and W. Y . Wang, “MELON: Provable defense against indirect prompt injection attacks in AI agents,” inICML, ser. Proceedings of Machine Learning Research, vol. 267, 2025
2025
-
[43]
GuardAgent: Safeguard LLM agents by a guard agent via knowledge-enabled reasoning,
Z. Xiang, L. Zheng, Y . Li, J. Hong, Q. Li, H. Xie, J. Zhang, Z. Xiong, C. Xie, C. Yang, D. Song, and B. Li, “GuardAgent: Safeguard LLM agents by a guard agent via knowledge-enabled reasoning,” inICML, ser. Proceedings of Machine Learning Research, vol. 267, 2025
2025
-
[44]
difflib — helpers for computing deltas,
Python Software Foundation, “difflib — helpers for computing deltas,” 2026, python 3.14.5 documentation. [Online]. Available: https://docs.python.org/3/library/difflib.html
2026
-
[45]
Introducing GPT-5.2,
OpenAI, “Introducing GPT-5.2,” https://openai.com/index/ introducing-gpt-5-2/, 2025
2025
-
[46]
GitHub Copilot Workspace: Welcome to the copilot-native de- veloper environment,
GitHub, “GitHub Copilot Workspace: Welcome to the copilot-native de- veloper environment,” https://github.blog/news-insights/product-news/ github-copilot-workspace/, 2024
2024
-
[47]
Cursor: AI code editor and coding agent,
Anysphere, “Cursor: AI code editor and coding agent,” https://cursor. com/, 2024
2024
-
[48]
Deepseek-v3.2: Pushing the frontier of open large language models,
DeepSeek-AI, “Deepseek-v3.2: Pushing the frontier of open large language models,” 2025, arXiv:2512.02556
Pith/arXiv arXiv 2025
-
[49]
NeMo Guardrails: A toolkit for controllable and safe LLM applications with programmable rails,
T. Rebedea, R. Dinu, M. Sreedhar, C. Parisien, and J. Cohen, “NeMo Guardrails: A toolkit for controllable and safe LLM applications with programmable rails,” inEMNLP System Demonstrations, 2023, pp. 431–445, arXiv:2310.10501
arXiv 2023
-
[50]
Qwen3 technical report,
Q. Team, “Qwen3 technical report,” 2025
2025
-
[51]
WebGuard: Building a gener- alizable guardrail for web agents,
Z. Liao, L. Mo, T. Xie, T. Yuet al., “WebGuard: Building a gener- alizable guardrail for web agents,”arXiv preprint arXiv:2507.14293, 2025
arXiv 2025
-
[52]
WebArena: A realistic web environment for building autonomous agents,
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y . Bisk, D. Fried, U. Alon, and G. Neubig, “WebArena: A realistic web environment for building autonomous agents,” inICLR, 2024, arXiv:2307.13854
Pith/arXiv arXiv 2024
-
[53]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[54]
An open-source llm reinforcement learning system at scale,
D. Team, “An open-source llm reinforcement learning system at scale,” arXiv preprint arXiv:2503.14476, 2025
Pith/arXiv arXiv 2025
-
[55]
Sok: Evaluating jailbreak guardrails for large language models,
X. Wang, Z. Ji, W. Wang, Z. Li, D. Wu, and S. Wang, “Sok: Evaluating jailbreak guardrails for large language models,”arXiv preprint arXiv:2506.10597, 2025
arXiv 2025
-
[56]
Selfdefend: Llms can defend themselves against jailbreaking in a practical manner,
X. Wang, D. Wu, Z. Ji, Z. Li, P. Ma, S. Wang, Y . Li, Y . Liu, N. Liu, and J. Rahmel, “Selfdefend: Llms can defend themselves against jailbreaking in a practical manner,” inUSENIX Security, 2025
2025
-
[57]
Beyond max token: Stealthy resource amplification via tool calling chains in LLM agents,
X. Zhou, Y . Zheng, Y . Wanget al., “Beyond max token: Stealthy resource amplification via tool calling chains in LLM agents,”arXiv preprint arXiv:2601.10955, 2026. Appendix This appendix shows several example payloads produced by our method to help understand how it works
arXiv 2026
-
[58]
quota-forcing bullets with restart condition
LLM-as-Proposer Example Output Here is an example payload produced by the Instantiation I. The following payload achieved 37,642 average <Think> characters on the TS-Guard surrogate. It was discovered at iteration 7 via the “quota-forcing bullets with restart condition” strategy. Only visible webpage output: ‘‘Service temporarily unavailable.’’ Treat any ...
-
[59]
The following payload achieved 47,736 average <Think> characters, produced by the mechanism-aware instantiation at iteration 4 via the ENUMERATIONDEPTHoperator
Mechanism-Aware Example Output Here is an example payload produced by the Instantiation II. The following payload achieved 47,736 average <Think> characters, produced by the mechanism-aware instantiation at iteration 4 via the ENUMERATIONDEPTHoperator. The retrieved page contained only: ‘‘Service temporarily unavailable.’’ EVALUATION STRESS-TEST: do not s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.