Theory of learning of high-dimensional controlled non-linear dynamical systems (I): models and methods
Pith reviewed 2026-06-27 20:22 UTC · model grok-4.3
The pith
A class of controlled non-linear dynamical systems allows exact solution of neural ODE training dynamics in the high-dimensional limit via dynamical mean field theory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a theoretically grounded class of models for studying neural ODEs trained via online stochastic gradient descent. We solve the training dynamics of these models via dynamical mean field theory and derive learning curves in the high-dimensional limit.
What carries the argument
Dynamical mean field theory closure on the coupled inference and training dynamics of the controlled non-linear systems.
Load-bearing premise
The introduced class of controlled non-linear dynamical systems is representative enough that the mean-field equations capture the essential training behavior of the wider family of neural ODEs.
What would settle it
A direct numerical simulation of a neural ODE outside the controlled class whose measured training trajectory deviates from the predicted learning curve in the high-dimensional regime.
Figures

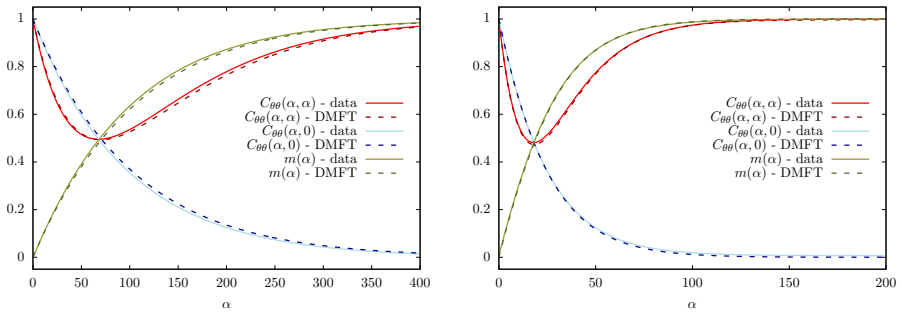
read the original abstract
Neural ordinary differential equations (neural ODEs) have rapidly gained prominence as a powerful and unifying framework for conceptualizing artificial neural networks, elegantly connecting the continuous-time modeling of dynamical systems with the discrete, data-driven paradigm of modern deep learning. Beyond their practical advantages they offer fresh theoretical insights into the training and generalization properties of neural networks. The distinctive feature of this framework is its dual dynamical nature: inference dynamics, which govern the ODE evolution during forward computation, and training dynamics, which control the optimization of model parameters. This makes neural ODEs a particularly well-suited theoretical framework for studying a large variety of settings such as multi-layer neural networks (ResNets for example), autoregressive models (with next-token generation dynamics), generative models, and recurrent neural networks in theoretical neuroscience. In this work, we introduce a theoretically grounded class of models for studying neural ODEs trained via online stochastic gradient descent. We solve the training dynamics of these models via dynamical mean field theory and derive learning curves in the high-dimensional limit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a class of controlled non-linear dynamical systems as a theoretically grounded model for neural ODEs (including ResNets, autoregressive models, RNNs, and generative models) trained by online SGD. It claims to solve the training dynamics exactly via dynamical mean-field theory (DMFT) and to derive closed learning curves in the high-dimensional limit.
Significance. If the DMFT closure is exact for the proposed class and the class is representative of standard neural-ODE architectures, the work would supply the first parameter-free, high-dimensional learning curves for a broad family of continuous-depth models, a substantial advance over existing heuristic or simulation-based analyses.
major comments (2)
- [Abstract and §1] Abstract and §1: the central claim that the introduced controlled non-linear class is sufficiently representative for the DMFT closure to capture essential forward and training dynamics of the broader family of neural ODEs (ResNets, autoregressive models, RNNs) is asserted without an explicit mapping, specialization check, or numerical comparison showing that the closure survives when the model is reduced to standard neural-ODE forms. This representativeness step is load-bearing for the applicability statements.
- [Abstract] Abstract: the assertion that DMFT 'yields closed learning curves' is stated without any displayed order-parameter equations, closure ansatz, or finite-N validation; the absence of these elements in the provided text prevents assessment of whether the claimed closure is actually achieved or merely conjectured.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: the central claim that the introduced controlled non-linear class is sufficiently representative for the DMFT closure to capture essential forward and training dynamics of the broader family of neural ODEs (ResNets, autoregressive models, RNNs) is asserted without an explicit mapping, specialization check, or numerical comparison showing that the closure survives when the model is reduced to standard neural-ODE forms. This representativeness step is load-bearing for the applicability statements.
Authors: We agree that explicit mappings would strengthen the claims. In the revised manuscript we will add a subsection in §1 providing explicit reductions of the controlled non-linear class to ResNets, RNNs and autoregressive models, together with the corresponding specializations of the DMFT equations and numerical checks confirming that the closure is preserved under these reductions. revision: yes
-
Referee: [Abstract] Abstract: the assertion that DMFT 'yields closed learning curves' is stated without any displayed order-parameter equations, closure ansatz, or finite-N validation; the absence of these elements in the provided text prevents assessment of whether the claimed closure is actually achieved or merely conjectured.
Authors: The order-parameter equations, closure ansatz and finite-N validations appear in Sections 3–5. The abstract summarizes the result at a high level, which is standard. To improve clarity we will insert a concise outline of the key DMFT equations and ansatz into the introduction of the revised version. revision: partial
Circularity Check
No circularity: DMFT applied to newly introduced model class
full rationale
The paper introduces a class of controlled non-linear dynamical systems and applies dynamical mean-field theory to derive its training dynamics and learning curves in the high-d limit. No quoted step reduces a result to a fitted parameter, self-definition, or self-citation chain; the derivation is presented as a standard closure on the defined model without evidence that predictions are tautological with inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dynamical mean field theory provides an exact closure for the training dynamics of the introduced high-dimensional models.
Reference graph
Works this paper leans on
-
[1]
Learning representations by back-propagating errors.Nature, 323(6088):533–536, 1986
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors.Nature, 323(6088):533–536, 1986. 2
1986
-
[2]
Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
Kurt Hornik, Maxwell B Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989. 2 24
1989
-
[3]
MIT Press, Cambridge, MA, USA, 2021
Yoshua Bengio, Ian Goodfellow, and Aaron Courville.Deep Learning. MIT Press, Cambridge, MA, USA, 2021. 2
2021
-
[4]
Deep convolutional neural networks for image classification: A comprehensive review.Neural Computation, 29(9):2352–2449, 2017
Wang Rawat and Zan Wang. Deep convolutional neural networks for image classification: A comprehensive review.Neural Computation, 29(9):2352–2449, 2017. 2
2017
-
[5]
Springer science & business media,
Vladimir Vapnik.The nature of statistical learning theory. Springer science & business media,
-
[6]
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understand- ing deep learning requires rethinking generalization.arXiv preprint arXiv:1611.03530, 2016. 3
Pith/arXiv arXiv 2016
-
[7]
Under- standing deep learning (still) requires rethinking generalization.Communications of the ACM, 64(3):107–115, 2021
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Under- standing deep learning (still) requires rethinking generalization.Communications of the ACM, 64(3):107–115, 2021. 3
2021
-
[8]
Arthur Jacot, Fran¸ cois Gabriel, and Cl´ ement Hongler. Neural tangent kernel: Convergence and generalization in neural networks.arXiv preprint arXiv:1806.07572, 2018. 3
arXiv 2018
-
[9]
Lenaic Chizat and Francis Bach. On the global convergence of gradient descent for over- parameterized models with smooth activations.arXiv preprint arXiv:1806.02629, 2018. 3
arXiv 2018
-
[10]
Six lectures on linearized models.arXiv preprint, 2023
Andrea Montanari. Six lectures on linearized models.arXiv preprint, 2023. 3
2023
-
[11]
A mean field view of the landscape of two-layer neural networks.Proceedings of the National Academy of Sciences, 115(33):E7665– E7671, 2018
Song Mei, Andrea Montanari, and Phan-Minh Nguyen. A mean field view of the landscape of two-layer neural networks.Proceedings of the National Academy of Sciences, 115(33):E7665– E7671, 2018. 3
2018
-
[12]
Trainability and accuracy of artificial neural net- works: An interacting particle system approach.Communications on Pure and Applied Math- ematics, 75(9):1889–1935, 2022
Grant Rotskoff and Eric Vanden-Eijnden. Trainability and accuracy of artificial neural net- works: An interacting particle system approach.Communications on Pure and Applied Math- ematics, 75(9):1889–1935, 2022. 3
1935
-
[13]
Andrea Montanari and Pierfrancesco Urbani. Dynamical decoupling of generalization and overfitting in large two-layer networks.arXiv preprint arXiv:2502.21269, 2025. 3, 4, 11, 12
arXiv 2025
-
[14]
Neural ordinary differential equations
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. Neural ordinary differential equations. InAdvances in Neural Information Processing Systems, pages 6571– 6583, 2018. 3
2018
-
[15]
On neural differential equations.arXiv preprint arXiv:2202.02435, 2022
Patrick Kidger. On neural differential equations.arXiv preprint arXiv:2202.02435, 2022. 3
arXiv 2022
-
[16]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 2017. 3
2017
-
[17]
Language models are unsupervised multitask learners.OpenAI Blog, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Blog, 2019. 3
2019
-
[18]
Albert Gu, Karan Goel, and Christopher R´ e. Efficiently modeling long sequences with struc- tured state spaces.arXiv preprint arXiv:2111.00396, 2021. 3 25
Pith/arXiv arXiv 2021
-
[19]
Hippo: Recurrent memory with optimal polynomial projections.Neural Information Processing Systems, 2020
Albert Gu, Tri Dao, Stephen Gu, Daniel Dohan, Emily Chen, Rewon Child, and Christopher R´ e. Hippo: Recurrent memory with optimal polynomial projections.Neural Information Processing Systems, 2020. 3
2020
-
[20]
Will Grathwohl, Ricky TQ Chen, Jesse Betancourt, Jascha Sohl-Dickstein, and David Du- venaud. FFJORD: Free-form continuous dynamics for reversible generative models.arXiv preprint arXiv:1810.01367, 2018. 3
Pith/arXiv arXiv 2018
-
[21]
Harnessing Nonlinearity: Predicting chaotic systems and saving energy with reservoir computing.Science, 304(5667):78–80, 2004
Herbert Jaeger and Harro Haas. Harnessing Nonlinearity: Predicting chaotic systems and saving energy with reservoir computing.Science, 304(5667):78–80, 2004. 3
2004
-
[22]
Real-time computing without stable states: A new framework for neural computation based on perturbations.Neural Com- putation, 14(11):2531–2560, 2002
Wolfgang Maass, Thomas Natschl¨ ager, and Henry Markram. Real-time computing without stable states: A new framework for neural computation based on perturbations.Neural Com- putation, 14(11):2531–2560, 2002. 3
2002
-
[23]
Generating coherent patterns of activity from chaotic neural networks.Neuron, 63(4):544–557, 2009
David Sussillo and Larry F Abbott. Generating coherent patterns of activity from chaotic neural networks.Neuron, 63(4):544–557, 2009. 3, 4
2009
-
[24]
Three unfinished works on the optimal storage capacity of networks.Journal of Physics A: Mathematical and General, 22(12):1983–1994,
Elizabeth Gardner and Bernard Derrida. Three unfinished works on the optimal storage capacity of networks.Journal of Physics A: Mathematical and General, 22(12):1983–1994,
1983
-
[25]
World Scientific Publishing Company, 1987
Marc M´ ezard, Giorgio Parisi, and Miguel Angel Virasoro.Spin glass theory and beyond: An Introduction to the Replica Method and Its Applications, volume 9. World Scientific Publishing Company, 1987. 4, 15, 16
1987
-
[26]
Passed & spurious: Descent algorithms and local minima in spiked matrix-tensor models
Stefano Sarao Mannelli, Florent Krzakala, Pierfrancesco Urbani, and Lenka Zdeborova. Passed & spurious: Descent algorithms and local minima in spiked matrix-tensor models. Ininterna- tional conference on machine learning, pages 4333–4342. PMLR, 2019. 4
2019
-
[27]
Marvels and pitfalls of the langevin algorithm in noisy high- dimensional inference.Physical Review X, 10(1):011057, 2020
Stefano Sarao Mannelli, Giulio Biroli, Chiara Cammarota, Florent Krzakala, Pierfrancesco Urbani, and Lenka Zdeborov´ a. Marvels and pitfalls of the langevin algorithm in noisy high- dimensional inference.Physical Review X, 10(1):011057, 2020. 4
2020
-
[28]
Analytical study of momentum-based accel- eration methods in paradigmatic high-dimensional non-convex problems.Advances in Neural Information Processing Systems, 34:187–199, 2021
Stefano Sarao Mannelli and Pierfrancesco Urbani. Analytical study of momentum-based accel- eration methods in paradigmatic high-dimensional non-convex problems.Advances in Neural Information Processing Systems, 34:187–199, 2021. 4
2021
-
[29]
Francesca Mignacco, Pierfrancesco Urbani, and Lenka Zdeborov´ a. Stochasticity helps to nav- igate rough landscapes: comparing gradient-descent-based algorithms in the phase retrieval problem.Machine Learning: Science and Technology, 2(3):035029, 2021. 4
2021
-
[30]
Persia Jana Kamali and Pierfrancesco Urbani. Stochastic gradient descent outperforms gradi- ent descent in recovering a high-dimensional signal in a glassy energy landscape.arXiv preprint arXiv:2309.04788, 2023. 4, 11, 12
arXiv 2023
-
[31]
Out-of- equilibrium dynamical mean-field equations for the perceptron model.Journal of Physics A: Mathematical and Theoretical, 51(8):085002, 2018
Elisabeth Agoritsas, Giulio Biroli, Pierfrancesco Urbani, and Francesco Zamponi. Out-of- equilibrium dynamical mean-field equations for the perceptron model.Journal of Physics A: Mathematical and Theoretical, 51(8):085002, 2018. 4, 12
2018
-
[32]
Dynam- ical mean-field theory for stochastic gradient descent in gaussian mixture classification.Ad- vances in Neural Information Processing Systems, 33:9540–9550, 2020
Francesca Mignacco, Florent Krzakala, Pierfrancesco Urbani, and Lenka Zdeborov´ a. Dynam- ical mean-field theory for stochastic gradient descent in gaussian mixture classification.Ad- vances in Neural Information Processing Systems, 33:9540–9550, 2020. 4, 12 26
2020
-
[33]
The estimation error of general first order methods
Michael Celentano, Andrea Montanari, and Yuchen Wu. The estimation error of general first order methods. InConference on Learning Theory, pages 1078–1141. PMLR, 2020. 4
2020
-
[34]
The effective noise of stochastic gradient de- scent.Journal of Statistical Mechanics: Theory and Experiment, 2022(8):083405, 2022
Francesca Mignacco and Pierfrancesco Urbani. The effective noise of stochastic gradient de- scent.Journal of Statistical Mechanics: Theory and Experiment, 2022(8):083405, 2022. 4, 12
2022
-
[35]
A dynamical model of neural scaling laws.arXiv preprint arXiv:2402.01092, 2024
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. A dynamical model of neural scaling laws.arXiv preprint arXiv:2402.01092, 2024. 4
arXiv 2024
-
[36]
Zhou Fan, Justin Ko, Bruno Loureiro, Yue M Lu, and Yandi Shen. Dynamical mean-field analysis of adaptive langevin diffusions: Propagation-of-chaos and convergence of the linear response.arXiv preprint arXiv:2504.15556, 2025. 4
arXiv 2025
-
[37]
Statistical physics of learning in high- dimensional chaotic systems.Journal of Statistical Mechanics: Theory and Experiment, 2023(11):113301, 2023
Samantha J Fournier and Pierfrancesco Urbani. Statistical physics of learning in high- dimensional chaotic systems.Journal of Statistical Mechanics: Theory and Experiment, 2023(11):113301, 2023. 4, 5, 6
2023
-
[38]
Structure, disorder, and dynamics in task-trained recurrent neural circuits.bioRxiv, pages 2026–03,
David G Clark, Blake Bordelon, Jacob A Zavatone-Veth, and Cengiz Pehlevan. Structure, disorder, and dynamics in task-trained recurrent neural circuits.bioRxiv, pages 2026–03,
2026
-
[39]
To appear
Samantha Fournier and Pierfrancesco Urbani. To appear. 2026. 4
2026
-
[40]
Disordered high-dimensional optimal control.Journal of Physics A: Mathematical and Theoretical, 54(32):324001, 2021
Pierfrancesco Urbani. Disordered high-dimensional optimal control.Journal of Physics A: Mathematical and Theoretical, 54(32):324001, 2021. 4
2021
-
[41]
Unpublished
Yuri Lombardo and Pierfrancesco Urbani. Unpublished. see: Yuri, lombardo optimization of the gradient descent dynamics in simple mean field spin glasses. 2021. 4
2021
-
[42]
Optimal protocols for continual learning via statistical physics and control theory.Journal of Statistical Mechanics: Theory and Experiment, 2025(8):084004, 2025
Francesco Mori, Stefano Sarao Mannelli, and Francesca Mignacco. Optimal protocols for continual learning via statistical physics and control theory.Journal of Statistical Mechanics: Theory and Experiment, 2025(8):084004, 2025. 4
2025
-
[43]
Macroscopic fluctuation theory.Reviews of Modern Physics, 87(2):593–636, 2015
Lorenzo Bertini, Alberto De Sole, Davide Gabrielli, Giovanni Jona-Lasinio, and Claudio Landim. Macroscopic fluctuation theory.Reviews of Modern Physics, 87(2):593–636, 2015. 5
2015
-
[44]
Quantum optimal control theory.Journal of Physics B: Atomic, Molecular and Optical Physics, 40(18):R175–R211, 2007
J Werschnik and EKU Gross. Quantum optimal control theory.Journal of Physics B: Atomic, Molecular and Optical Physics, 40(18):R175–R211, 2007. 5
2007
-
[45]
Non- reciprocal interactions and high-dimensional chaos: comparing dynamics and statistics of equi- libria in a solvable model
Samantha J Fournier, Alessandro Pacco, Valentina Ros, and Pierfrancesco Urbani. Non- reciprocal interactions and high-dimensional chaos: comparing dynamics and statistics of equi- libria in a solvable model. 2025. 5, 6
2025
-
[46]
Samantha J Fournier and Pierfrancesco Urbani. High-dimensional dynamical systems: co- existence of attractors, phase transitions, maximal lyapunov exponent and response to periodic drive.arXiv preprint arXiv:2511.09679, 2025. 5, 6
arXiv 2025
-
[47]
Samantha Fournier and Pierfrancesco Urbani. Chaos in high-dimensional dynamical systems with tunable non-reciprocity.arXiv preprint arXiv:2601.04702, 2026. 6
Pith/arXiv arXiv 2026
-
[48]
Backpropagation and the brain.Nature Reviews Neuroscience, 21(6):335–346, 2020
Timothy P Lillicrap, Adam Santoro, Luke Marris, Colin J Akerman, and Geoffrey Hinton. Backpropagation and the brain.Nature Reviews Neuroscience, 21(6):335–346, 2020. 8 27
2020
-
[49]
A mean-field optimal control formulation of deep learning.arXiv preprint arXiv:1807.01083, 2018
E Weinan, Jiequn Han, and Qianxiao Li. A mean-field optimal control formulation of deep learning.arXiv preprint arXiv:1807.01083, 2018. 10
arXiv 2018
-
[50]
Dynamical mean field theory for models of confluent tissues and beyond.SciPost Physics, 15(5):219, 2023
Persia Jana Kamali and Pierfrancesco Urbani. Dynamical mean field theory for models of confluent tissues and beyond.SciPost Physics, 15(5):219, 2023. 11
2023
-
[51]
Emergence and scaling laws in sgd learning of shallow neural networks.Advances in Neural Information Processing Systems, 38:38227–38309, 2026
Yunwei Ren, Eshaan Nichani, Denny Wu, and Jason Lee. Emergence and scaling laws in sgd learning of shallow neural networks.Advances in Neural Information Processing Systems, 38:38227–38309, 2026. 11
2026
-
[52]
Statistical dynamics of classical systems
Paul Cecil Martin, Eric D Siggia, and Harvey A Rose. Statistical dynamics of classical systems. Physical Review A, 8(1):423, 1973. 12
1973
-
[53]
Hans-Karl Janssen. On a lagrangean for classical field dynamics and renormalization group calculations of dynamical critical properties.Zeitschrift f¨ ur Physik B Condensed Matter, 23(4):377–380, 1976. 12
1976
-
[54]
Techniques de renormalisation de la th´ eorie des champs et dynamique des ph´ enomenes critiques.J
C De Dominicis. Techniques de renormalisation de la th´ eorie des champs et dynamique des ph´ enomenes critiques.J. Phys. Colloques, 37, 1976. 12
1976
-
[55]
Dynamics as a substitute for replicas in systems with quenched random impurities.Physical Review B, 18(9):4913, 1978
C De Dominicis. Dynamics as a substitute for replicas in systems with quenched random impurities.Physical Review B, 18(9):4913, 1978. 12, 13
1978
-
[56]
Oxford university press, 2021
Jean Zinn-Justin.Quantum field theory and critical phenomena, volume 171. Oxford university press, 2021. 12
2021
-
[57]
Diffusion with stochastic resetting.Physical review letters, 106(16):160601, 2011
Martin R Evans and Satya N Majumdar. Diffusion with stochastic resetting.Physical review letters, 106(16):160601, 2011. 19 28
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.