Are Tools Always Beneficial? Learning to Invoke Tools Adaptively for Dual-Mode Multimodal LLM Reasoning
Pith reviewed 2026-05-20 06:12 UTC · model grok-4.3
The pith
Multimodal LLMs gain accuracy and speed by learning to invoke tools only when they help rather than always or never.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
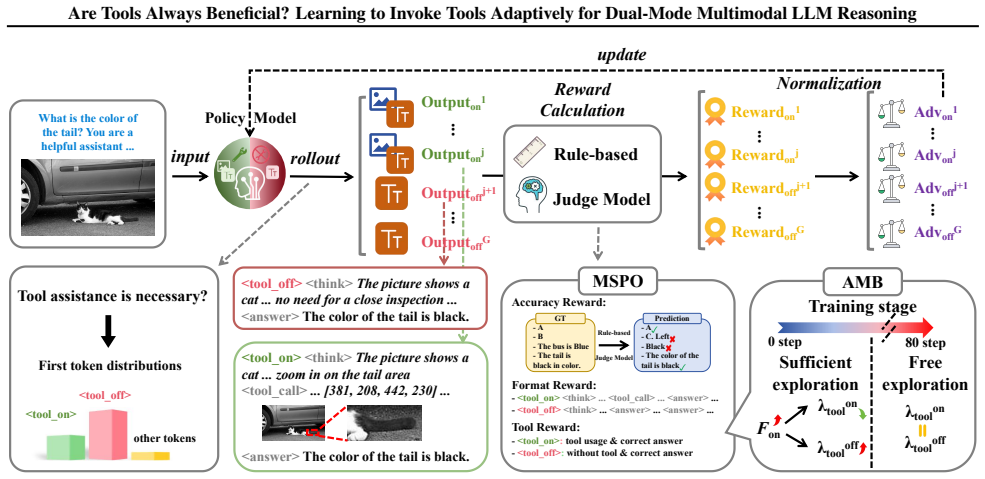
Within a reinforcement learning framework, AutoTool maintains an explicit dual-mode reasoning strategy in which the model jointly explores tool-assisted and text-centric paths, guided by mode-specific reward functions, so that it invokes tools only for queries where they improve accuracy and otherwise relies on internal reasoning to avoid unnecessary overhead.
What carries the argument
Dual-mode reasoning strategy inside reinforcement learning, using mode-specific reward functions plus phased joint exploration to decide per query whether to invoke tools.
If this is right
- Models produce correct answers at lower computational cost by skipping tools on queries that do not need them.
- Joint exploration during training keeps both reasoning modes viable rather than letting one dominate early.
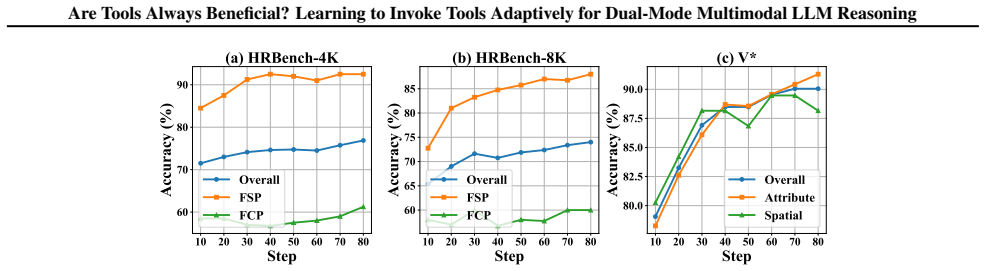
- Accuracy rises on visual reasoning tasks such as V* because the model avoids tool-induced errors.
- Efficiency improves on benchmarks like POPE because redundant tool calls are eliminated.
Where Pith is reading between the lines
- The same adaptive logic could be applied to other tool-using language models beyond the multimodal setting.
- Over-provisioning tools in model design may systematically hurt performance on simpler queries.
- Testing the method on larger base models would reveal whether the efficiency and accuracy gains scale.
- The approach suggests future tool-augmented systems should include explicit training for when to refuse a tool.
Load-bearing premise
The reinforcement learning setup with mode-specific rewards and joint exploration will reliably produce stable adaptive switching instead of locking the model into one fixed mode.
What would settle it
Retraining the model and observing that it converges to using the same mode for nearly all queries while accuracy or efficiency falls below the reported gains on V* and POPE would show the adaptive mechanism failed.
Figures









read the original abstract
Tool-augmented reasoning has emerged as a promising direction for enhancing the reasoning capabilities of multimodal large language models (MLLMs). However, existing studies mainly focus on enabling models to perform tool invocation, while neglecting the necessity of invoking tools. We argue that tool usage is not always beneficial, as redundant or inappropriate invocations largely increase reasoning overhead and even mislead model predictions. To address this issue, we introduce AutoTool, a model that adaptively decides whether to invoke tools according to the characteristics of each query. Within a reinforcement learning framework, we design an explicit dual-mode reasoning strategy with mode-specific reward functions to guide the model toward producing accurate responses. Moreover, to prevent premature bias toward a single reasoning mode, AutoTool jointly explores and balances tool-assisted and text-centric reasoning throughout training, and promotes free exploration in later stages. Extensive experiments demonstrate that AutoTool exhibits outstanding performance and high efficiency, yielding a 21.8\% accuracy gain on V* benchmark compared to the base model, and a 44.9\% improvement in efficiency over existing tool-augmented methods on POPE benchmark. Code is available at https://github.com/MQinghe/AutoTool.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AutoTool, a multimodal LLM that adaptively decides whether to invoke tools or use text-centric reasoning for each query. It employs a reinforcement learning framework with dual-mode reasoning, mode-specific reward functions, joint exploration of both modes during training, and a late-stage free-exploration phase to avoid premature bias toward one mode. The central empirical claims are a 21.8% accuracy gain on the V* benchmark relative to the base model and a 44.9% efficiency improvement over prior tool-augmented methods on the POPE benchmark.
Significance. If the adaptive, query-dependent behavior is verifiably achieved rather than a collapse to a fixed policy, the approach could meaningfully improve the efficiency-accuracy tradeoff in tool-augmented MLLMs by avoiding redundant or misleading tool calls. The reported benchmark gains indicate practical promise, but the result's significance hinges on confirming that the dual-mode RL training produces stable, non-collapsed mode selection.
major comments (2)
- [Reinforcement Learning Framework] The RL framework (as described in the methods) relies on mode-specific rewards plus joint exploration and late-stage free exploration to prevent bias, yet provides no explicit anti-collapse term (e.g., entropy bonus on mode choice) and no reported mode-selection frequency statistics during or after training. This is load-bearing for the central claim of adaptive invocation: if average reward favors one mode across the training distribution, policy gradients can still drive convergence to a non-adaptive policy, which could account for the observed gains without true query-dependent adaptation.
- [§4 (Experimental Results)] §4 (Experimental Results): the manuscript reports clear benchmark gains but omits full details on data splits, complete ablation studies isolating the adaptive mechanism, and verification that improvements stem from dual-mode adaptivity rather than other training choices. Without these, it is not possible to confirm that the 21.8% V* accuracy gain and 44.9% POPE efficiency gain are attributable to the claimed adaptive behavior.
minor comments (2)
- [Abstract] The abstract states a 44.9% efficiency improvement on POPE but does not specify the precise metric (e.g., average tool calls per query, latency, or FLOPs) or list the exact baselines; adding this clarification would aid interpretation.
- [Methods] Notation for the two reasoning modes (tool-assisted vs. text-centric) and the mode-selection policy should be introduced more explicitly with consistent symbols to improve readability of the RL formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the major concerns regarding the reinforcement learning framework and the experimental details below. We will make revisions to provide additional evidence and clarifications as outlined.
read point-by-point responses
-
Referee: [Reinforcement Learning Framework] The RL framework (as described in the methods) relies on mode-specific rewards plus joint exploration and late-stage free exploration to prevent bias, yet provides no explicit anti-collapse term (e.g., entropy bonus on mode choice) and no reported mode-selection frequency statistics during or after training. This is load-bearing for the central claim of adaptive invocation: if average reward favors one mode across the training distribution, policy gradients can still drive convergence to a non-adaptive policy, which could account for the observed gains without true query-dependent adaptation.
Authors: We agree that providing mode-selection frequency statistics would offer direct verification of the adaptive, query-dependent behavior. In the revised version, we will report the frequency of tool-assisted versus text-centric mode selections on both training and test sets to demonstrate that the policy does not collapse. While we did not include an explicit entropy bonus on mode choice, the training procedure incorporates joint exploration of both modes throughout training with mode-specific rewards, followed by a late-stage free-exploration phase. This design encourages the model to sample from both modes proportionally to their rewards without a priori bias toward one. We will clarify this rationale in the methods section and include the statistics to empirically support the non-collapse. revision: yes
-
Referee: [§4 (Experimental Results)] §4 (Experimental Results): the manuscript reports clear benchmark gains but omits full details on data splits, complete ablation studies isolating the adaptive mechanism, and verification that improvements stem from dual-mode adaptivity rather than other training choices. Without these, it is not possible to confirm that the 21.8% V* accuracy gain and 44.9% POPE efficiency gain are attributable to the claimed adaptive behavior.
Authors: We will revise §4 to include complete details on the data splits used for training and evaluation. Furthermore, we will add ablation studies that specifically isolate the adaptive mechanism, including comparisons to single-mode variants and ablations removing the free-exploration phase. These will help attribute the observed gains (21.8% on V* and 44.9% efficiency on POPE) to the dual-mode adaptive training rather than other factors. We believe the current results are consistent with adaptivity, but the additional experiments and details will strengthen this claim. revision: yes
Circularity Check
No circularity: empirical RL training with mode-specific rewards produces reported benchmark gains
full rationale
The paper introduces AutoTool via a standard reinforcement learning setup that includes dual-mode reasoning, mode-specific reward functions, joint exploration of tool-assisted and text-centric paths, and a late-stage free-exploration phase. All central claims—21.8% accuracy improvement on V* and 44.9% efficiency gain on POPE—are presented as outcomes of this training process evaluated on held-out benchmarks, not as predictions derived from equations or parameters that are defined in terms of the same quantities. No self-definitional steps, fitted-input-as-prediction reductions, or load-bearing self-citations appear in the described framework; the adaptive policy is an emergent result of the RL objective rather than presupposed by construction. The derivation chain therefore remains self-contained and externally falsifiable through the reported experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mode-specific reward functions can be designed to guide accurate responses in each reasoning mode without introducing bias toward one mode.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We design Mode-Specific Policy Optimization (MSPO), with distinct optimization objectives to different reasoning modes... Adaptive Mode Balancing (AMB) strategy that dynamically adjusts the reward coefficients to control the frequency of the two modes
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and orbit embedding unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
to prevent premature bias toward a single reasoning mode, AutoTool jointly explores and balances tool-assisted and text-centric reasoning throughout training
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
arXiv preprint arXiv:2503.10639 , year=
Got: Unleashing reasoning capability of multimodal large language model for visual generation and editing , author=. arXiv preprint arXiv:2503.10639 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Advances in Neural Information Processing Systems , volume=
Large language models are zero-shot reasoners , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems , volume=
Visual instruction tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts , author=. arXiv preprint arXiv:2310.02255 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2312.11370 , year=
G-llava: Solving geometric problem with multi-modal large language model , author=. arXiv preprint arXiv:2312.11370 , year=
-
[17]
arXiv preprint arXiv:2407.08739 , year=
Mavis: Mathematical visual instruction tuning with an automatic data engine , author=. arXiv preprint arXiv:2407.08739 , year=
-
[18]
The Twelfth International Conference on Learning Representations , year=
Grounding multimodal large language models to the world , author=. The Twelfth International Conference on Learning Representations , year=
-
[19]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Vqa: Visual question answering , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[20]
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[21]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2502.09621 , year=
Mme-cot: Benchmarking chain-of-thought in large multimodal models for reasoning quality, robustness, and efficiency , author=. arXiv preprint arXiv:2502.09621 , year=
-
[23]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
European Conference on Computer Vision , pages=
Modeling context in referring expressions , author=. European Conference on Computer Vision , pages=. 2016 , organization=
work page 2016
-
[25]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding , author=. arXiv preprint arXiv:2412.10302 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [27]
-
[28]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [29]
-
[30]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers , author=. arXiv preprint arXiv:2506.23918 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Thyme: Think beyond images , author=. arXiv preprint arXiv:2508.11630 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Traceable evidence enhanced visual grounded reasoning: Evaluation and methodology , author=. arXiv preprint arXiv:2507.07999 , year=
-
[33]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
DeepEyes: Incentivizing" Thinking with Images" via Reinforcement Learning , author=. arXiv preprint arXiv:2505.14362 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2412.18072 , year=
MMFactory: A Universal Solution Search Engine for Vision-Language Tasks , author=. arXiv preprint arXiv:2412.18072 , year=
-
[35]
arXiv preprint arXiv:2107.07566 , year=
Internet-augmented dialogue generation , author=. arXiv preprint arXiv:2107.07566 , year=
-
[36]
Workshop on Reasoning and Planning for Large Language Models , year=
TACO: Learning Multi-modal Models to Reason and Act with Synthetic Chains-of-Thought-and-Action , author=. Workshop on Reasoning and Planning for Large Language Models , year=
-
[37]
Cogcom: Train large vision-language models diving into details through chain of manipulations , author=
-
[38]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
Openthinkimg: Learning to think with images via visual tool reinforcement learning , author=. arXiv preprint arXiv:2505.08617 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
Sft or rl? an early investigation into training r1-like reasoning large vision-language models , author=. arXiv preprint arXiv:2504.11468 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
work page 2024
-
[42]
Proceedings of the 29th Symposium on Operating Systems Principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th Symposium on Operating Systems Principles , pages=
- [43]
-
[44]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
V?: Guided visual search as a core mechanism in multimodal llms , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[45]
arXiv preprint arXiv:2403.00231 , year=
Multimodal arxiv: A dataset for improving scientific comprehension of large vision-language models , author=. arXiv preprint arXiv:2403.00231 , year=
-
[46]
arXiv preprint arXiv:2504.07934 , year=
Sota with less: Mcts-guided sample selection for data-efficient visual reasoning self-improvement , author=. arXiv preprint arXiv:2504.07934 , year=
-
[47]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Coco-stuff: Thing and stuff classes in context , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[49]
Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing , pages=
Referitgame: Referring to objects in photographs of natural scenes , author=. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2014
-
[50]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Lisa: Reasoning segmentation via large language model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[51]
Evaluating Object Hallucination in Large Vision-Language Models
Evaluating object hallucination in large vision-language models , author=. arXiv preprint arXiv:2305.10355 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
European Conference on Computer Vision , pages=
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[53]
Advances in Neural Information Processing Systems , volume=
Measuring multimodal mathematical reasoning with math-vision dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
We-math: Does your large multimodal model achieve human-like mathematical reasoning? , author=. arXiv preprint arXiv:2407.01284 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models , author=. arXiv preprint arXiv:2411.00836 , year=
-
[56]
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
Logicvista: Multimodal llm logical reasoning benchmark in visual contexts , author=. arXiv preprint arXiv:2407.04973 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[58]
arXiv preprint arXiv:2411.16044 , year=
Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration , author=. arXiv preprint arXiv:2411.16044 , year=
-
[59]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning , author=. arXiv preprint arXiv:2505.15966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Mini-o3: Scaling up reasoning patterns and interaction turns for visual search , author=. arXiv preprint arXiv:2509.07969 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[64]
International Conference on Machine Learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[65]
International Conference on Machine Learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[66]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Reproducible scaling laws for contrastive language-image learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[69]
International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[70]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[71]
Advances in Neural Information Processing Systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
Advances in Neural Information Processing Systems , volume=
Cambrian-1: A fully open, vision-centric exploration of multimodal llms , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
Advances in Neural Information Processing Systems , volume=
Unveiling encoder-free vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mono-internvl: Pushing the boundaries of monolithic multimodal large language models with endogenous visual pre-training , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[75]
arXiv preprint arXiv:2504.10462 , year=
The scalability of simplicity: Empirical analysis of vision-language learning with a single transformer , author=. arXiv preprint arXiv:2504.10462 , year=
-
[76]
arXiv preprint arXiv:2505.17018 , year=
SophiaVL-R1: Reinforcing MLLMs Reasoning with Thinking Reward , author=. arXiv preprint arXiv:2505.17018 , year=
-
[77]
arXiv preprint arXiv:2505.16673 , year=
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO , author=. arXiv preprint arXiv:2505.16673 , year=
-
[78]
Advances in Neural Information Processing Systems , volume=
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Segment anything , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[80]
SAM 2: Segment Anything in Images and Videos
Sam 2: Segment anything in images and videos , author=. arXiv preprint arXiv:2408.00714 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.