Modeling Depth Ambiguity: A Mixture-Density Representation for Flying-Point-Free Depth Estimation
Pith reviewed 2026-06-28 15:30 UTC · model grok-4.3
The pith
Modeling depth per pixel as a mixture of hypotheses eliminates flying points by allowing separate surface alignments at boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
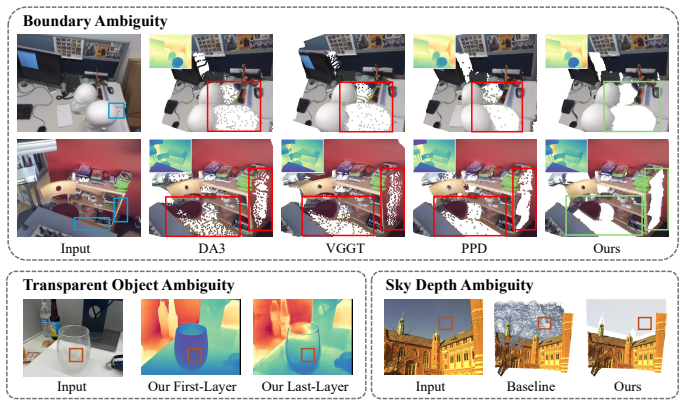
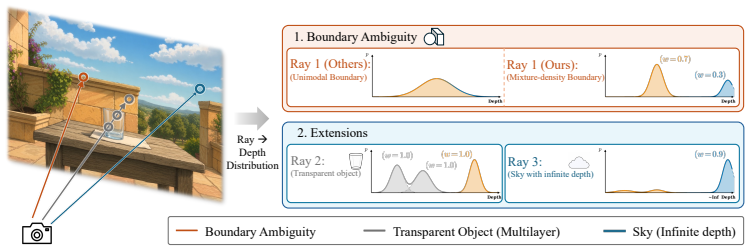
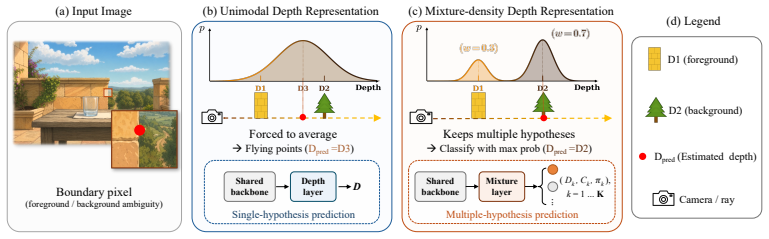
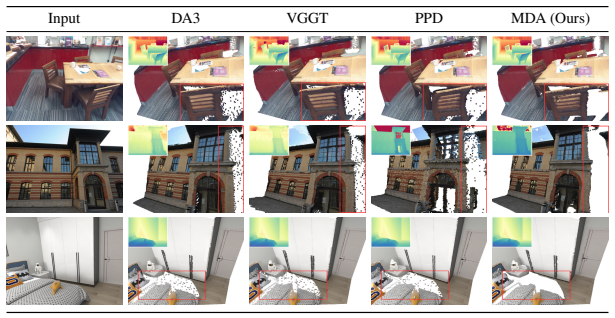
The paper establishes that replacing the single-depth output with a mixture-density representation allows the model to maintain multiple possible depths at ambiguous pixels. Different mixture components can align with different surfaces, so the decoded depth comes from an actual surface rather than the space between them. This directly addresses the source of flying points without changing the underlying network architecture.
What carries the argument
The MDA mixture-density representation, which outputs multiple depth hypotheses and their probabilities per pixel and decodes depth by selecting from these hypotheses.
If this is right
- Boundary reconstruction improves substantially across different network backbones.
- Flying-point artifacts are largely removed even under severe input blur.
- The same framework predicts multiple depth layers for transparent objects.
- A dedicated sky component separates unbounded regions from finite depths to produce clean skylines.
- Runtime overhead stays negligible.
Where Pith is reading between the lines
- Similar mixture representations could address depth ambiguities in other scenarios like reflections or occlusions.
- Adopting MDA might require only swapping the final prediction layer in existing depth networks.
- Dynamic determination of the number of mixture components per pixel could further improve flexibility.
- Testing on datasets with more varied boundary conditions would strengthen evidence for the modeling choice being the main cause.
Load-bearing premise
That the dominant source of flying points is the single-depth modeling choice at ambiguous boundary pixels rather than other factors such as network capacity, loss design, or dataset statistics.
What would settle it
Compare flying-point counts at object boundaries between a standard single-depth network and an MDA network trained identically on the same dataset; a large reduction only in the MDA version would confirm the modeling change as the key factor.
Figures







read the original abstract
Despite advances in depth estimation, flying points remain a persistent failure mode: near object boundaries, depth estimators often predict spurious 3D points in the empty space between foreground and background surfaces. We trace this artifact to a standard modeling choice: assigning each pixel a single depth hypothesis. At boundaries, a pixel can straddle a foreground and a background surface, so its true depth is ambiguous between the two. A model that predicts a single depth cannot keep both possibilities, so training instead pulls the prediction toward an intermediate depth that lies on neither surface. We address this with MDA, a mixture-density representation that lets the model predict multiple depth hypotheses and their associated probabilities for each pixel. Near boundaries, different hypotheses can align with different surfaces, and the decoded depth is selected from one of these hypotheses rather than placed in the empty space between them. Across different backbones, MDA substantially improves boundary reconstruction and largely removes flying-point artifacts even under severe input blur, while adding negligible runtime overhead. The same mixture-density framework naturally extends to transparent objects, where it predicts multiple depth layers at transparent pixels, and to sky regions, where a dedicated component separates the unbounded sky from finite-depth regions, producing flying-point-free skylines. Project Page: https://biansy000.github.io/mda-site/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that flying-point artifacts in monocular depth estimation arise from the standard single-depth hypothesis per pixel, which forces intermediate predictions at ambiguous boundary pixels; it introduces MDA, a mixture-density representation allowing multiple depth hypotheses and probabilities per pixel so that decoded depths align with surfaces rather than empty space. The approach is asserted to substantially improve boundary reconstruction and remove flying points across backbones even under severe blur, with negligible overhead, and to extend naturally to multi-layer depths for transparent objects and sky separation.
Significance. If the central attribution holds after proper controls, the work supplies a clean representational fix for a persistent artifact rather than an architectural or loss tweak, with practical value for 3D reconstruction pipelines and extensibility to transparency and unbounded regions. The negligible runtime claim, if verified, strengthens deployability.
major comments (2)
- [Experiments] Experiments section: the claim that gains are driven by the mixture representation (rather than output dimensionality, loss formulation, or training dynamics) requires explicit controls. Baselines must be re-trained with output heads matched in channel count to MDA's multiple hypotheses plus probabilities; without this, the attribution to single-depth modeling as the dominant cause of flying points cannot be isolated.
- [Abstract and §4] Abstract and §4 (results): qualitative statements of 'substantially improves boundary reconstruction' and 'largely removes flying-point artifacts' must be backed by quantitative tables reporting boundary-specific metrics (e.g., edge F-score, flying-point count) and ablations across backbones; the current absence of such numbers leaves the cross-backbone applicability unverified.
minor comments (2)
- [Method] Method section: clarify the exact decoding procedure from mixture components to final depth map (e.g., whether argmax probability or expectation is used) and how it differs from standard regression losses.
- [Figures] Figure captions: add quantitative annotations (e.g., flying-point counts or boundary error) to qualitative result figures to make visual claims directly verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The points raised highlight opportunities to strengthen the experimental validation of MDA's benefits. We address each major comment below and will incorporate the suggested controls and metrics in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the claim that gains are driven by the mixture representation (rather than output dimensionality, loss formulation, or training dynamics) requires explicit controls. Baselines must be re-trained with output heads matched in channel count to MDA's multiple hypotheses plus probabilities; without this, the attribution to single-depth modeling as the dominant cause of flying points cannot be isolated.
Authors: We agree that isolating the contribution of the mixture-density representation requires controlling for output dimensionality. In the revision we will retrain the single-hypothesis baselines with expanded output heads that produce the same number of depth channels as MDA (while retaining their original loss and training procedure). The resulting comparisons will be added to the experiments section to better support the attribution of flying-point reduction to the mixture modeling itself. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (results): qualitative statements of 'substantially improves boundary reconstruction' and 'largely removes flying-point artifacts' must be backed by quantitative tables reporting boundary-specific metrics (e.g., edge F-score, flying-point count) and ablations across backbones; the current absence of such numbers leaves the cross-backbone applicability unverified.
Authors: We acknowledge that the manuscript would benefit from explicit quantitative support for the boundary and flying-point claims. We will add a dedicated table (and corresponding ablations) in Section 4 that reports edge F-score, flying-point counts, and related boundary metrics for MDA and the baselines across the evaluated backbones. These numbers will also be referenced in the abstract to substantiate the qualitative statements. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes MDA, a mixture-density representation for depth estimation, tracing flying points to single-depth modeling at ambiguous boundary pixels and claiming empirical improvements across backbones. No equations, derivations, or load-bearing steps are shown that reduce any prediction or result to a fitted input or self-citation by construction. The central contribution is a representational change with reported empirical gains; no self-definitional, fitted-input, or uniqueness-imported patterns appear in the abstract or described claims. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Goldman, Matthias Nießner, and Justus Thies
Dejan Azinovi ´c, Ricardo Martin-Brualla, Dan B. Goldman, Matthias Nießner, and Justus Thies. Neural RGB-D surface reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[2]
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
Pith/arXiv arXiv 2013
-
[3]
Accurately computing the log-sum-exp and softmax functions.IMA Journal of Numerical Analysis, 41(4):2311–2330, 2021
Pierre Blanchard, Desmond J Higham, and Nicholas J Higham. Accurately computing the log-sum-exp and softmax functions.IMA Journal of Numerical Analysis, 41(4):2311–2330, 2021
2021
-
[4]
Butler, Jonas Wulff, Garrett B
Daniel J. Butler, Jonas Wulff, Garrett B. Stanley, and Michael J. Black. A naturalistic open source movie for optical flow evaluation. InEuropean Conference on Computer Vision, 2012
2012
-
[5]
Virtual KITTI 2.arXiv preprint arXiv:2001.10773, 2020
Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual KITTI 2.arXiv preprint arXiv:2001.10773, 2020
Pith/arXiv arXiv 2001
-
[6]
Depth map prediction from a single image using a multi-scale deep network.Advances in neural information processing systems, 27, 2014
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network.Advances in neural information processing systems, 27, 2014
2014
-
[7]
Vision meets robotics: The KITTI dataset.International Journal of Robotics Research (IJRR), 32(11):1231–1237, 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The KITTI dataset.International Journal of Robotics Research (IJRR), 32(11):1231–1237, 2013. 10
2013
-
[8]
DeepMVS: Learning multi-view stereopsis
Po-Han Huang, Kevin Matzen, Johannes Kopf, Narendra Ahuja, and Jia-Bin Huang. DeepMVS: Learning multi-view stereopsis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[9]
DynamicStereo: Consistent dynamic depth from stereo videos
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. DynamicStereo: Consistent dynamic depth from stereo videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[10]
Mapanything: Universal feed-forward metric 3d reconstruction.arXiv preprint arXiv:2509.13414, 2025
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction.arXiv preprint arXiv:2509.13414, 2025
Pith/arXiv arXiv 2025
-
[11]
Yushi Lan, Yihang Luo, Fangzhou Hong, Shangchen Zhou, Honghua Chen, Zhaoyang Lyu, Shuai Yang, Bo Dai, Chen Change Loy, and Xingang Pan. Stream3r: Scalable sequential 3d reconstruction with causal transformer.arXiv preprint arXiv:2508.10893, 2025
arXiv 2025
-
[12]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
2024
-
[13]
Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[14]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024
2024
-
[15]
ReFusion: 3d reconstruction in dynamic environments for RGB-D cameras exploiting residuals
Emanuele Palazzolo, Jens Behley, Philipp Lottes, Philippe Giguère, and Cyrill Stachniss. ReFusion: 3d reconstruction in dynamic environments for RGB-D cameras exploiting residuals. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019
2019
-
[16]
Aria digital twin: A new benchmark dataset for egocentric 3d machine perception
Xiaqing Pan, Nicholas Charron, Yongqian Yang, Scott Peters, Thomas Whelan, Chen Kong, Omkar Parkhi, Richard Newcombe, and Yuheng Carl Ren. Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20133–20143, 2023
2023
-
[17]
Open challenges in deep stereo: the booster dataset
Pierluigi Zama Ramirez, Fabio Tosi, Matteo Poggi, Samuele Salti, Stefano Mattoccia, and Luigi Di Stefano. Open challenges in deep stereo: the booster dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21168–21178, 2022
2022
-
[18]
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020
2020
-
[19]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179– 12188, 2021
2021
-
[20]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 10912–10922, 2021
2021
-
[21]
Clear grasp: 3d shape estimation of transparent objects for manipulation
Shreeyak Sajjan, Matthew Moore, Mike Pan, Ganesh Nagaraja, Johnny Lee, Andy Zeng, and Shuran Song. Clear grasp: 3d shape estimation of transparent objects for manipulation. In2020 IEEE international conference on robotics and automation (ICRA), pages 3634–3642. IEEE, 2020
2020
-
[22]
Scene coordinate regression forests for camera relocalization in RGB-D images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in RGB-D images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2013. 11
2013
-
[23]
Smd-nets: Stereo mixture density networks
Fabio Tosi, Yiyi Liao, Carolin Schmitt, and Andreas Geiger. Smd-nets: Stereo mixture density networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8942–8952, 2021
2021
-
[24]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[25]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. pages 10510–10522, 2025
2025
-
[26]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[27]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. Tartanair: A dataset to push the limits of visual slam. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4909–4916. IEEE, 2020
2020
-
[28]
π3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025
Pith/arXiv arXiv 2025
-
[29]
Zichen Wang, Ang Cao, Liam J. Wang, and Jeong Joon Park. MoE3D: A mixture-of-experts module for 3D reconstruction.arXiv preprint arXiv:2601.05208, 2026
arXiv 2026
-
[30]
Seeing and seeing through the glass: Real and synthetic data for multi-layer depth estimation
Hongyu Wen, Yiming Zuo, Venkat Subramanian, Patrick Chen, and Jia Deng. Seeing and seeing through the glass: Real and synthetic data for multi-layer depth estimation. pages 6715–6725, 2025
2025
-
[31]
Gangwei Xu, Haotong Lin, Hongcheng Luo, Xianqi Wang, Jingfeng Yao, Lianghui Zhu, Yuechuan Pu, Cheng Chi, Haiyang Sun, Bing Wang, et al. Pixel-perfect depth with semantics- prompted diffusion transformers.arXiv preprint arXiv:2510.07316, 2025
arXiv 2025
-
[32]
Pixel-perfect visual geometry estimation.arXiv preprint arXiv:2601.05246, 2026
Gangwei Xu, Haotong Lin, Hongcheng Luo, Haiyang Sun, Bing Wang, Guang Chen, Sida Peng, Hangjun Ye, and Xin Yang. Pixel-perfect visual geometry estimation.arXiv preprint arXiv:2601.05246, 2026
arXiv 2026
-
[33]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024
2024
-
[34]
Depth anything v2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2. volume 37, pages 21875–21911, 2024
2024
-
[35]
UnrealStereo: Controlling hazardous factors to analyze stereo vision
Yi Zhang, Weichao Qiu, Qi Chen, Xiaolin Hu, and Alan Yuille. UnrealStereo: Controlling hazardous factors to analyze stereo vision. InInternational Conference on 3D Vision (3DV), 2018
2018
-
[36]
Harley, Bokui Shen, Gordon Wetzstein, and Leonidas J
Yang Zheng, Adam W. Harley, Bokui Shen, Gordon Wetzstein, and Leonidas J. Guibas. PointOdyssey: A large-scale synthetic dataset for long-term point tracking. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[37]
Yang Zhou, Yifan Wang, Jianjun Zhou, Wenzheng Chang, Haoyu Guo, Zizun Li, Kaijing Ma, Xinyue Li, Yating Wang, Haoyi Zhu, et al. Omniworld: A multi-domain and multi-modal dataset for 4d world modeling.arXiv preprint arXiv:2509.12201, 2025. 12 Supplementary Material Modeling Depth Ambiguity: A Mixture-Density Representation for Flying-Point-Free Depth Estim...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.