Drift Q-Learning
Pith reviewed 2026-06-28 22:49 UTC · model grok-4.3
The pith
DriftQL improves offline reinforcement learning policies by combining a drift-based regularizer with a critic signal to generate high-value actions in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
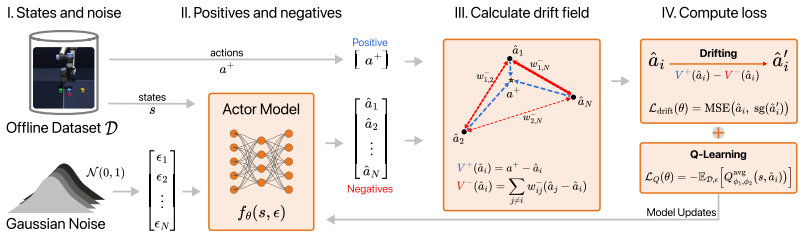
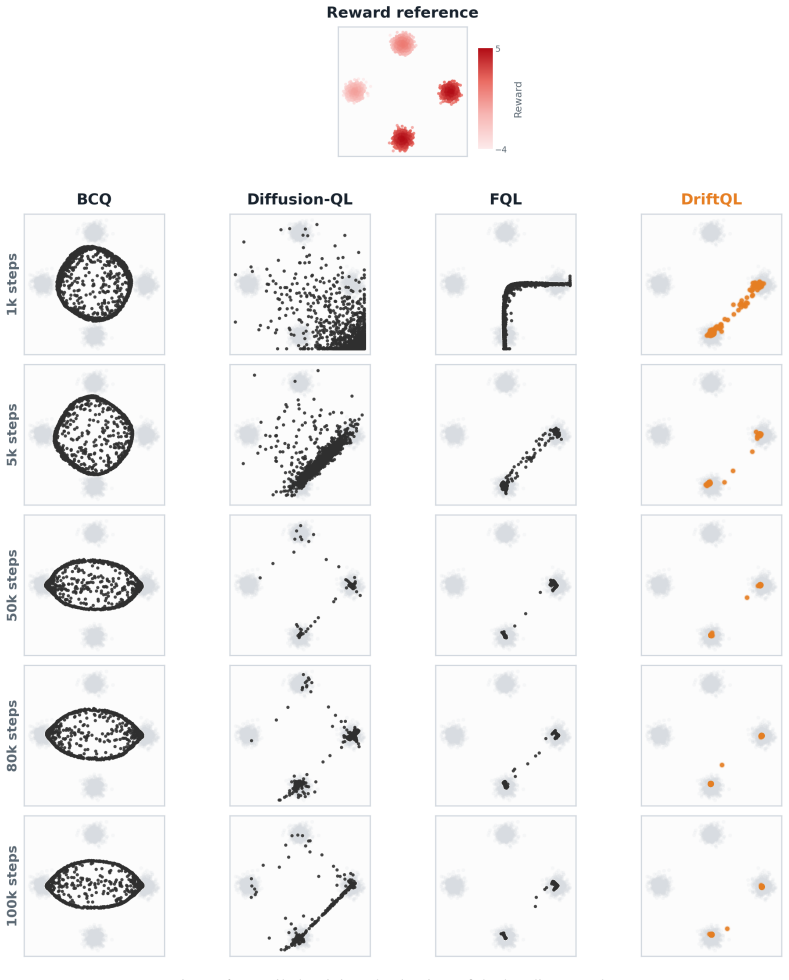
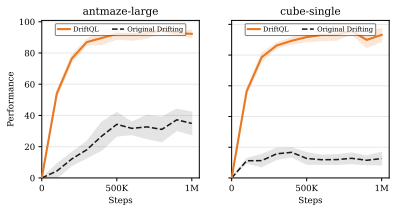
DriftQL implements a unified training objective in which the critic value signal biases the policy toward high-value regions of the data support, while attraction and repulsion terms in the drift regularizer keep generated actions near the observed data and prevent collapse onto a single mode, enabling single-forward-pass action generation that outperforms diffusion and flow methods on D4RL and OGBench and maintains performance under degraded data quality.
What carries the argument
The drift-based behavioral regularizer with attraction and repulsion terms, integrated with the critic signal inside a single unified objective.
If this is right
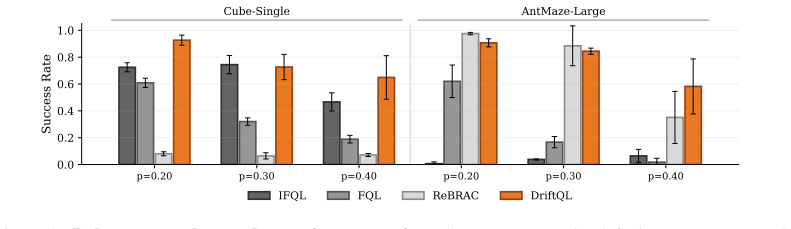
- DriftQL achieves higher returns than diffusion and flow policies on D4RL and OGBench.
- Performance stays near clean-data levels when data quality is degraded.
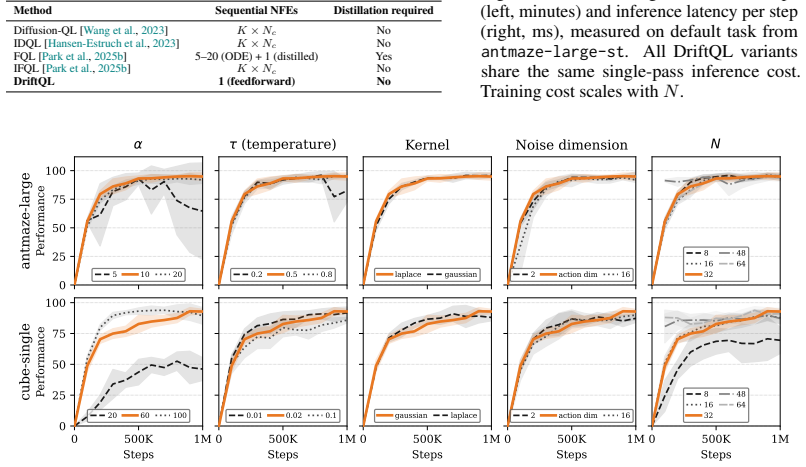
- Action generation requires only a single forward pass through one network.
- The approach offers the efficiency of deterministic policies while adding behavioral regularization.
Where Pith is reading between the lines
- The single-network design may allow direct transfer of the same weights to online fine-tuning without architecture changes.
- Robustness to data degradation suggests the regularizer could handle partial observability or sensor noise in robotic datasets.
- Because the objective is unified, gradient-based hyperparameter search over the drift strength becomes feasible without separate pre-training stages.
Load-bearing premise
The drift-based regularizer with attraction and repulsion terms, when combined with the critic signal in a unified objective, sufficiently prevents out-of-distribution actions and mode collapse without requiring iterative sampling.
What would settle it
Run DriftQL and the strongest diffusion baseline on a new offline dataset containing severe distribution shift or heavy noise; if DriftQL's normalized score drops more than 10 percent below its clean-data score while the diffusion method stays within 5 percent, the robustness claim is falsified.
Figures



read the original abstract
Offline reinforcement learning requires improving a policy from fixed data while avoiding out-of-distribution actions with unreliable value estimates. Diffusion and flow policies handle this trade-off by modeling the behavior distribution to regularize the RL objective, but they require iterative denoising, solver integrations, and in more efficient variants, distillation or other approximations at inference. We propose DriftQL, which combines a drift-based behavioral regularizer with critic-driven policy improvement. The value signal biases the policy toward high-value regions of the data support, while attraction and repulsion together keep generated actions near the data and prevent collapse onto a single mode. DriftQL is implemented as a single network with a unified training objective and generates actions in a single forward pass. On D4RL and OGBench, DriftQL consistently outperforms diffusion and flow methods, advancing the state of the art. Under degraded data quality, where the baselines visibly struggle, DriftQL remains close to its clean-data performance, positioning it as a promising alternative to diffusion and flow-based methods while maintaining the simplicity and efficiency of deterministic approaches. Project page: https://driftql.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DriftQL for offline RL: a single-network method with a unified objective combining a drift-based behavioral regularizer (attraction and repulsion terms) and critic-driven policy improvement. It generates actions in one forward pass, claims to outperform diffusion and flow methods on D4RL and OGBench, and reports robustness under degraded data quality.
Significance. If the empirical results are reproducible with proper controls and the regularizer is shown to enforce data support without iterative sampling, this would be a notable contribution by offering a simpler, more efficient alternative to diffusion/flow policies while matching or exceeding performance.
major comments (2)
- [Abstract] Abstract: the assertion that attraction and repulsion terms keep generated actions near the data support and prevent mode collapse, when combined with the critic signal, is stated without any equations, derivation of the resulting policy gradient, or argument showing why the non-iterative formulation avoids the distribution-shift problems motivating iterative denoising in the baselines.
- [Abstract] Abstract: performance and robustness claims (outperformance on D4RL/OGBench, close to clean-data performance under degradation) are asserted without reference to tables, figures, error bars, ablation studies, or experimental protocols, so it is not possible to evaluate whether the results support the central claims.
Simulated Author's Rebuttal
We thank the referee for the comments. We address each major point below, noting that the abstract serves as a concise summary while the full manuscript contains the requested technical details and experimental evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that attraction and repulsion terms keep generated actions near the data support and prevent mode collapse, when combined with the critic signal, is stated without any equations, derivation of the resulting policy gradient, or argument showing why the non-iterative formulation avoids the distribution-shift problems motivating iterative denoising in the baselines.
Authors: The abstract provides a high-level overview and omits equations to preserve brevity and accessibility. The full derivation of the unified objective (combining the drift regularizer with attraction/repulsion terms and critic-driven improvement), the resulting policy gradient, and the argument that the single-pass formulation directly enforces data support (avoiding the need for iterative denoising to mitigate distribution shift) appear in Section 3 of the manuscript. This organization follows standard practice for abstracts. revision: no
-
Referee: [Abstract] Abstract: performance and robustness claims (outperformance on D4RL/OGBench, close to clean-data performance under degradation) are asserted without reference to tables, figures, error bars, ablation studies, or experimental protocols, so it is not possible to evaluate whether the results support the central claims.
Authors: The abstract summarizes the empirical outcomes without embedding specific citations to tables or figures, which is conventional to maintain conciseness. Full support for the claims—including outperformance on D4RL and OGBench (Tables 1–2), error bars over multiple seeds, ablation studies on the regularizer (Section 4.3), robustness under data degradation (Figure 5), and experimental protocols (Section 4.1)—is provided in Section 4. The results are thus evaluable from the main text. revision: no
Circularity Check
No circularity; empirical claims rest on external benchmarks.
full rationale
The paper presents DriftQL as a modeling choice (drift regularizer + critic in one objective, single forward pass) whose performance is asserted via comparisons on D4RL and OGBench. No equations, derivations, or first-principles results appear in the supplied text that reduce any claimed prediction to a fitted quantity or self-citation by construction. The central modeling assumption (attraction/repulsion terms suffice to bound OOD actions) is stated but not derived from prior self-work in a load-bearing way. This is the common honest case of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Unified View of Score-Based and Drifting Models
A Unified View of Drifting and Score-Based Models , author=. arXiv preprint arXiv:2603.07514 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Yang, Rui and Bai, Chenjia and Ma, Xiaoteng and Wang, Zhaoran and Zhang, Chongjie and Han, Lei , journal=
-
[3]
Why so pessimistic?
Ghasemipour, Kamyar and Gu, Shixiang Shane and Nachum, Ofir , journal=. Why so pessimistic?
-
[4]
Advances in Neural Information Processing Systems , editor=
Uncertainty-Based Offline Reinforcement Learning with Diversified Q-Ensemble , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
2021
-
[5]
Advances in Neural Information Processing Systems 32 , publisher =
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author =. Advances in Neural Information Processing Systems 32 , publisher =
-
[6]
Advances in Neural Information Processing Systems , volume=
Revisiting the minimalist approach to offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
A connection between score matching and denoising autoencoders
Vincent, Pascal , title =. 2011 , issue_date =. doi:10.1162/NECO_a_00142 , journal =
-
[8]
Conference on robot learning , pages=
Implicit behavioral cloning , author=. Conference on robot learning , pages=. 2022 , organization=
2022
-
[9]
Tarasov, Denis and Nikulin, Alexander and Akimov, Dmitry and Kurenkov, Vladislav and Kolesnikov, Sergey , journal=
-
[10]
The Fourteenth International Conference on Learning Representations , year=
Flow Actor-Critic for Offline Reinforcement Learning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[11]
The Twelfth International Conference on Learning Representations , year=
Consistency Models as a Rich and Efficient Policy Class for Reinforcement Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
The Twelfth International Conference on Learning Representations , year=
Score Regularized Policy Optimization through Diffusion Behavior , author=. The Twelfth International Conference on Learning Representations , year=
-
[13]
Adam: A method for stochastic optimization , author =
-
[14]
Knowledge and information systems , publisher =
Exact indexing of dynamic time warping , author =. Knowledge and information systems , publisher =
-
[15]
doi:10.5281/zenodo.8127026 , urldate =
Gymnasium , author =. doi:10.5281/zenodo.8127026 , urldate =
-
[16]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[17]
Advances in Neural Information Processing Systems , volume=
Diffusion policies creating a trust region for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Advances in neural information processing systems , volume=
Behavior transformers: Cloning k modes with one stone , author=. Advances in neural information processing systems , volume=
-
[19]
The Thirteenth International Conference on Learning Representations , year=
Contractive Dynamical Imitation Policies for Efficient Out-of-Sample Recovery , author=. The Thirteenth International Conference on Learning Representations , year=
-
[20]
Numerical Linear Algebra with Applications , year=
Dynamically accelerating the power iteration with momentum , author=. Numerical Linear Algebra with Applications , year=
-
[21]
Advances in neural information processing systems , year=
A minimalist approach to offline reinforcement learning , author=. Advances in neural information processing systems , year=
-
[22]
For SALE: State-Action Representation Learning for Deep Reinforcement Learning , year =
Fujimoto, Scott and Chang, Wei-Di and Smith, Edward and Gu, Shixiang (Shane) and Precup, Doina and Meger, David , booktitle =. For SALE: State-Action Representation Learning for Deep Reinforcement Learning , year =
-
[23]
Conservative
Kumar, Aviral and Zhou, Aurick and Tucker, George and Levine, Sergey , journal=. Conservative
-
[24]
Fu, Justin and Kumar, Aviral and Nachum, Ofir and Tucker, George and Levine, Sergey , journal=. D4
-
[25]
5th Annual Conference on Robot Learning , year=
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation , author=. 5th Annual Conference on Robot Learning , year=
-
[26]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
robosuite: A modular simulation framework and benchmark for robot learning , author=. arXiv preprint arXiv:2009.12293 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[27]
Todorov, Emanuel and Erez, Tom and Tassa, Yuval , booktitle=. Mu. 2012 , volume=
2012
-
[28]
The Twelfth International Conference on Learning Representations , year=
Safe Offline Reinforcement Learning with Feasibility-Guided Diffusion Model , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
IEEE Robotics and Automation Letters , year=
Diffusion policies for out-of-distribution generalization in offline reinforcement learning , author=. IEEE Robotics and Automation Letters , year=
-
[30]
Zibin Dong and Yifu Yuan and Jianye HAO and Fei Ni and Yao Mu and YAN ZHENG and Yujing Hu and Tangjie Lv and Changjie Fan and Zhipeng Hu , booktitle=. Align
-
[31]
Proceedings of the 28th international conference on international conference on machine learning , year=
Contractive auto-encoders: Explicit invariance during feature extraction , author=. Proceedings of the 28th international conference on international conference on machine learning , year=
-
[32]
, author=
Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. , author=. Journal of machine learning research , volume=
-
[33]
arXiv preprint arXiv:2506.12544 , year=
Constrained Diffusers for Safe Planning and Control , author=. arXiv preprint arXiv:2506.12544 , year=
-
[34]
Forty-second International Conference on Machine Learning , year=
Behavior-Regularized Diffusion Policy Optimization for Offline Reinforcement Learning , author=. Forty-second International Conference on Machine Learning , year=
-
[35]
2024 , cdate=
Wenpin Tang and Hanyang Zhao , title=. 2024 , cdate=
2024
-
[36]
Wei Xiao and Tsun-Hsuan Wang and Chuang Gan and Ramin Hasani and Mathias Lechner and Daniela Rus , booktitle=. Safe
-
[37]
Mizuta, Kazuki and Leung, Karen , booktitle=. Co
-
[38]
Diffusion-
Mao, Liyuan and Xu, Haoran and Zhan, Xianyuan and Zhang, Weinan and Zhang, Amy , booktitle =. Diffusion-
-
[39]
arXiv preprint arXiv:2507.06111 , year=
Safe Domain Randomization via Uncertainty-Aware Out-of-Distribution Detection and Policy Adaptation , author=. arXiv preprint arXiv:2507.06111 , year=
-
[40]
ICRA 2024 Workshop
Safe Offline Reinforcement Learning using Trajectory-Level Diffusion Models , author=. ICRA 2024 Workshop
2024
-
[41]
2009 IEEE Conference on Computer Vision and Pattern Recognition , pages=
ImageNet: A Large-Scale Hierarchical Image Database , author=. 2009 IEEE Conference on Computer Vision and Pattern Recognition , pages=. 2009 , organization=
2009
-
[42]
arXiv preprint arXiv:2506.21427 , year=
Flow-Based Single-Step Completion for Efficient and Expressive Policy Learning , author=. arXiv preprint arXiv:2506.21427 , year=
-
[43]
Alles, Marvin and Chen, Nutan and van der Smagt, Patrick and Cseke, Botond , journal=. Flow
-
[44]
The Fourteenth International Conference on Learning Representations , year=
Contractive Diffusion Policies: Robust Action Diffusion via Contractive Score-Based Sampling with Differential Equations , author=. The Fourteenth International Conference on Learning Representations , year=
-
[45]
Diffusion Policies for Out-of-Distribution Generalization in Offline Reinforcement Learning , year=
Ada, Suzan Ece and Oztop, Erhan and Ugur, Emre , journal=. Diffusion Policies for Out-of-Distribution Generalization in Offline Reinforcement Learning , year=
-
[46]
International Conference on Machine Learning , year=
Planning with Diffusion for Flexible Behavior Synthesis , author=. International Conference on Machine Learning , year=
-
[47]
Hansen-Estruch, Philippe and Kostrikov, Ilya and Janner, Michael and Kuba, Jakub Grudzien and Levine, Sergey , journal=
-
[48]
2024 , booktitle=
Xiao Ma and Sumit Patidar and Iain Haughton and Stephen James , title=. 2024 , booktitle=
2024
-
[49]
Zhu, Zhengbang and Liu, Minghuan and Mao, Liyuan and Kang, Bingyi and Xu, Minkai and Yu, Yong and Ermon, Stefano and Zhang, Weinan , booktitle =. M
-
[50]
The Eleventh International Conference on Learning Representations , year=
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[51]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Efficient Diffusion Policies For Offline Reinforcement Learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[52]
Forty-second International Conference on Machine Learning , year=
Maximum Entropy Reinforcement Learning with Diffusion Policy , author=. Forty-second International Conference on Machine Learning , year=
-
[53]
CoRL 2024 Workshop on Mastering Robot Manipulation in a World of Abundant Data , year=
Diffusion Policy Policy Optimization , author=. CoRL 2024 Workshop on Mastering Robot Manipulation in a World of Abundant Data , year=
2024
-
[54]
Liang, Zhixuan and Mu, Yao and Ding, Mingyu and Ni, Fei and Tomizuka, Masayoshi and Luo, Ping , booktitle=. Adapt
-
[55]
Forty-second International Conference on Machine Learning , year=
Efficient Online Reinforcement Learning for Diffusion Policy , author=. Forty-second International Conference on Machine Learning , year=
-
[56]
2023 , organization=
Urain, Julen and Funk, Niklas and Peters, Jan and Chalvatzaki, Georgia , booktitle=. 2023 , organization=
2023
-
[57]
The International Journal of Robotics Research , year=
Diffusion policy: Visuomotor policy learning via action diffusion , author=. The International Journal of Robotics Research , year=
-
[58]
Proceedings of Robotics: Science and Systems (RSS) , year=
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations , author=. Proceedings of Robotics: Science and Systems (RSS) , year=
-
[59]
Songyuan Zhang and Oswin So and H M Sabbir Ahmad and Eric Yang Yu and Matthew Cleaveland and Mitchell Black and Chuchu Fan , booktitle=. Re. 2026 , url=
2026
-
[60]
Signal processing, sensor fusion, and target recognition VI , volume=
New extension of the Kalman filter to nonlinear systems , author=. Signal processing, sensor fusion, and target recognition VI , volume=. 1997 , organization=
1997
-
[61]
Ocean dynamics , volume=
The ensemble Kalman filter: Theoretical formulation and practical implementation , author=. Ocean dynamics , volume=. 2003 , publisher=
2003
-
[62]
Yoo , booktitle=
Thanh Xuan Nguyen and Chang D. Yoo , booktitle=. One-Step Flow. 2026 , url=
2026
-
[63]
Robotics: Science and Systems , year =
Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation , author =. Robotics: Science and Systems , year =
-
[64]
Thomas Unterthiner and Bernhard Nessler and Calvin Seward and Günter Klambauer and Martin Heusel and Hubert Ramsauer and Sepp Hochreiter , booktitle=. Coulomb. 2018 , url=
2018
-
[65]
Mean shift, mode seeking, and clustering , year=
Yizong Cheng , journal=. Mean shift, mode seeking, and clustering , year=
-
[66]
Forty-second International Conference on Machine Learning , year=
One-Step Diffusion Policy: Fast Visuomotor Policies via Diffusion Distillation , author=. Forty-second International Conference on Machine Learning , year=
-
[67]
Forty-second International Conference on Machine Learning , year=
Latent Diffusion Planning for Imitation Learning , author=. Forty-second International Conference on Machine Learning , year=
-
[68]
The Eleventh International Conference on Learning Representations , year=
Imitating Human Behavior with Diffusion Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[69]
Tsung-Wei Ke and Nikolaos Gkanatsios and Katerina Fragkiadaki , booktitle=. 3
-
[70]
8th Annual Conference on Robot Learning , year=
Sparse Diffusion Policy: A Sparse, Reusable, and Flexible Policy for Robot Learning , author=. 8th Annual Conference on Robot Learning , year=
-
[71]
Yixuan Wang and Guang Yin and Binghao Huang and Tarik Kelestemur and Jiuguang Wang and Yunzhu Li , booktitle=. Gen. 2024 , url=
2024
-
[72]
Diffusion
Huang Huang and Balakumar Sundaralingam and Arsalan Mousavian and Adithyavairavan Murali and Ken Goldberg and Dieter Fox , booktitle=. Diffusion
-
[73]
Diffusion-
Ryu, Hyunwoo and Kim, Jiwoo and An, Hyunseok and Chang, Junwoo and Seo, Joohwan and Kim, Taehan and Kim, Yubin and Hwang, Chaewon and Choi, Jongeun and Horowitz, Roberto , booktitle=. Diffusion-
-
[74]
7th Annual Conference on Robot Learning , year=
Chaineddiffuser: Unifying trajectory diffusion and keypose prediction for robotic manipulation , author=. 7th Annual Conference on Robot Learning , year=
-
[75]
Wang, Bingzheng and Wu, Guoqiang and Pang, Teng and Zhang, Yan and Yin, Yilong , booktitle=. Diff
-
[76]
Advances in neural information processing systems , year=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , year=
-
[77]
International Conference on Learning Representations , year=
Denoising Diffusion Implicit Models , author=. International Conference on Learning Representations , year=
-
[78]
Zheng, Kaiwen and Lu, Cheng and Chen, Jianfei and Zhu, Jun , booktitle =. D
-
[79]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[80]
ACM Computing Surveys , year=
Diffusion models: A comprehensive survey of methods and applications , author=. ACM Computing Surveys , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.