A Unified View of Score-Based and Drifting Models
Pith reviewed 2026-05-21 11:11 UTC · model grok-4.3
The pith
Drifting models with Gaussian kernels perform exact score matching on smoothed distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
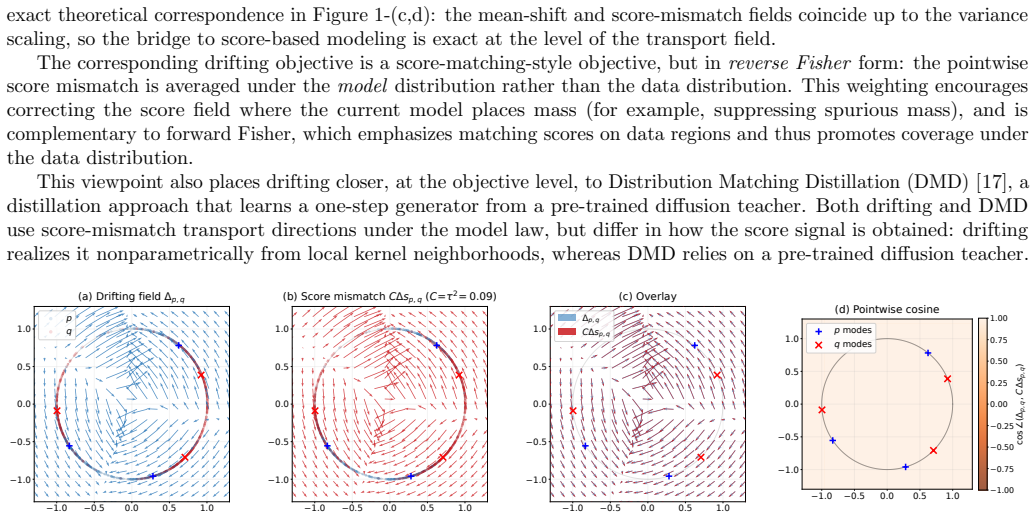
For Gaussian kernels, the population mean-shift field exactly equals the difference between the scores of the Gaussian-smoothed data and model distributions. This identity follows from Tweedie's formula and implies that Gaussian-kernel drifting is exactly a score-matching objective on smoothed distributions. More generally, an exact decomposition for radial kernels shows that mean shift equals a score-based field plus a residual term. For the practical Laplace kernel, the residual is negligible in high dimension, implying that the transport field used in practice is nearly score-based. This reveals a structural connection to diffusion models: both methods use score-mismatch transport but one
What carries the argument
The kernel-induced mean-shift field, which for Gaussian kernels equals the score difference of smoothed distributions via Tweedie's formula.
If this is right
- Gaussian-kernel drifting is exactly a score-matching objective on smoothed distributions.
- The transport directions in drifting equal score differences, allowing direct transfer of analysis between drifting and diffusion models.
- In high dimensions the Laplace kernel produces a transport field that is nearly identical to a score-based field.
- Both drifting and diffusion realize generation by following directions that reduce score mismatch, differing only in whether the score is estimated nonparametrically or parametrically.
Where Pith is reading between the lines
- Hybrid estimators could blend the nonparametric kernel estimates of drifting with learned neural scores to gain robustness in data-scarce regimes.
- The same decomposition might be used to design new kernels whose residual term supplies a controlled form of regularization.
- Drifting could serve as a nonparametric baseline for studying when score-based transport succeeds or fails without the confounding effects of neural-network training.
Load-bearing premise
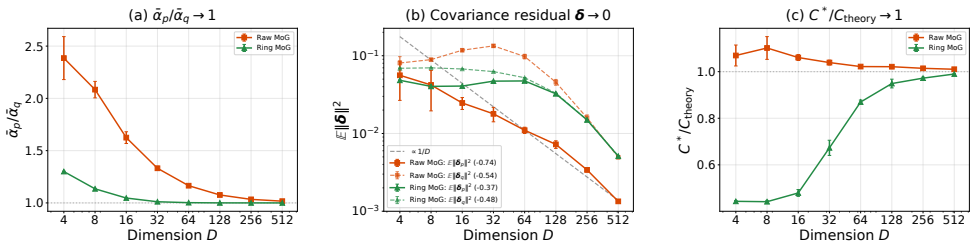
The residual term in the exact decomposition for radial kernels is negligible for the practical Laplace kernel when operating in high-dimensional regimes.
What would settle it
Direct numerical comparison of the mean-shift vector against the score difference vector for a Gaussian kernel on a known low-dimensional distribution such as a standard normal, checking whether the two vectors coincide to machine precision.
Figures






read the original abstract
Drifting models train one-step generators by optimizing a kernel-induced mean-shift discrepancy between the data and model distributions, with Laplace kernels used by default in practice. At each point, this discrepancy compares the kernel-weighted displacement toward nearby data samples with the corresponding displacement toward nearby model samples, thereby defining a transport direction for generated samples. In this paper, we show that drifting is more closely connected to score-based generative modeling than it may first appear, establishing a precise link to the score-matching principle underlying diffusion models. For Gaussian kernels, the population mean-shift field exactly equals the difference between the scores (i.e., the gradient-log-densities) of the Gaussian-smoothed data and model distributions. This identity follows from Tweedie's formula, which links the score of a Gaussian-smoothed density to its conditional mean, and implies that Gaussian-kernel drifting is exactly a score-matching objective on smoothed distributions. More generally, we derive an exact decomposition for radial kernels in which mean shift equals a score-based field plus a residual term. For the practical Laplace kernel, we further show theoretically and empirically that this residual is negligible in high dimension, implying that the transport field used in practice is nearly score-based. Our results reveal a structural connection to diffusion models: both methods use score-mismatch transport directions, but drifting realizes the score nonparametrically through kernel-based estimates, whereas diffusion models learn it parametrically with neural networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that drifting models, which optimize a kernel-induced mean-shift discrepancy for one-step generation using Laplace kernels by default, are closely connected to score-based generative modeling. For Gaussian kernels, the population mean-shift field exactly equals the difference between the scores of the Gaussian-smoothed data and model distributions via Tweedie's formula, implying Gaussian-kernel drifting is a score-matching objective on smoothed distributions. For radial kernels, it derives an exact decomposition of the mean-shift into a score-based field plus a residual term. For the practical Laplace kernel, it argues theoretically and empirically that the residual is negligible in high dimensions, so that the transport field is nearly score-based. This reveals a structural link where both drifting and diffusion models use score-mismatch transport directions, but drifting does so nonparametrically via kernels.
Significance. If the central claims hold, the work provides a precise unification of drifting and score-based methods, with the exact Gaussian identity and radial decomposition as notable strengths, plus empirical support for the Laplace case. This could clarify how nonparametric kernel estimates relate to parametric neural score learning in generative modeling, and highlights that both approaches rely on score-mismatch transport.
major comments (1)
- [Section deriving decomposition for radial kernels and Laplace analysis] In the derivation of the exact decomposition for radial kernels (leading to the claim that mean-shift equals score-difference plus residual), the argument that the residual is negligible for the Laplace kernel in high dimensions lacks an explicit quantitative scaling bound or rate showing ||residual|| / ||score term|| = o(1) uniformly in dimension d or for the bandwidths used in the experiments. This is load-bearing for the practical conclusion that drifting transport is nearly score-based, as the residual could remain O(1) or grow in typical high-d regimes (d ≈ 100).
minor comments (2)
- Clarify all assumptions on kernel bandwidth selection and data distribution moments in the high-dimensional residual analysis to make the negligibility claim more precise.
- [Gaussian kernel identity section] Add explicit statements of all regularity conditions required for applying Tweedie's formula in the Gaussian case.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We address the major comment point by point below and will revise the paper to strengthen the analysis as suggested.
read point-by-point responses
-
Referee: In the derivation of the exact decomposition for radial kernels (leading to the claim that mean-shift equals score-difference plus residual), the argument that the residual is negligible for the Laplace kernel in high dimensions lacks an explicit quantitative scaling bound or rate showing ||residual|| / ||score term|| = o(1) uniformly in dimension d or for the bandwidths used in the experiments. This is load-bearing for the practical conclusion that drifting transport is nearly score-based, as the residual could remain O(1) or grow in typical high-d regimes (d ≈ 100).
Authors: We agree that an explicit quantitative scaling bound would strengthen the theoretical justification for the negligibility of the residual in high dimensions. Our current manuscript provides a theoretical argument based on the radial kernel decomposition together with empirical verification across dimensions up to 100, but we acknowledge the absence of a precise rate. In the revised manuscript we will add a new lemma deriving the asymptotic scaling of ||residual|| / ||score term|| for the Laplace kernel, showing that the ratio is o(1) as d grows under standard assumptions on the bandwidth (h = O(1/sqrt(d))) and bounded moments of the data distribution. We will also include additional numerical confirmation for the exact bandwidths used in the experiments. revision: yes
Circularity Check
No significant circularity; derivation uses external Tweedie's formula and independent kernel decomposition
full rationale
The paper's core identity for Gaussian kernels is obtained by applying Tweedie's formula (an external, standard result linking smoothed scores to conditional means) to the mean-shift field, yielding an exact equivalence to score differences on smoothed distributions. The general radial-kernel decomposition into score-based field plus residual is derived directly from kernel properties without reducing to fitted parameters or prior self-referential results. The claim of residual negligibility for the Laplace kernel in high dimensions is supported by separate theoretical arguments and empirical checks rather than by construction or self-citation chains. All load-bearing steps remain independent of the target conclusion and are self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Tweedie's formula holds, linking the score of a Gaussian-smoothed density to its conditional mean
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
For Gaussian kernels, the population mean-shift field exactly equals the difference between the scores ... This identity follows from Tweedie's formula
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
exact decomposition for radial kernels in which mean shift equals a score-based field plus a residual term
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 11 Pith papers
-
Generative Modeling with Flux Matching
Flux Matching generalizes score-based generative modeling by using a weaker objective that admits infinitely many non-conservative vector fields with the data as stationary distribution, enabling new design choices be...
-
One-Step Generative Modeling via Wasserstein Gradient Flows
W-Flow achieves state-of-the-art one-step ImageNet 256x256 generation at 1.29 FID by training a static neural network to follow a Wasserstein gradient flow that minimizes Sinkhorn divergence, delivering roughly 100x f...
-
Identifiability and Stability of Generative Drifting with Companion-Elliptic Kernel Families
Companion-elliptic kernels (exactly the Gaussians and Matérn kernels with ν ≥ 1/2) ensure drifting-field identifiability for equal measures and restore stability via an asymptotic lower bound on the intrinsic overlap scalar.
-
Identifiability and Stability of Generative Drifting with Companion-Elliptic Kernel Families
For companion-elliptic kernels vanishing drifting fields identify target measures exactly, and field convergence yields weak convergence once mass escape to infinity is detected by a single C0 scalar.
-
Finite-Particle Convergence Rates for Conservative and Non-Conservative Drifting Models
Establishes finite-particle convergence rates for a conservative KDE-gradient drifting method in one-step generative modeling on R^d along with analysis of a non-conservative Laplace kernel variant, yielding explicit ...
-
Drifting Field Policy: A One-Step Generative Policy via Wasserstein Gradient Flow
DFP is a one-step generative policy using Wasserstein gradient flow on a drifting model backbone, with a top-K behavior cloning surrogate, that reaches SOTA on Robomimic and OGBench manipulation tasks.
-
On the Wasserstein Gradient Flow Interpretation of Drifting Models
The paper interprets GMD algorithms as limiting points of Wasserstein gradient flows on KL divergence with Parzen smoothing and on Sinkhorn divergence, while extending the approach to MMD, sliced Wasserstein, and GAN critics.
-
Lookahead Drifting Model
The lookahead drifting model improves upon the drifting model by sequentially computing multiple drifting terms that incorporate higher-order gradient information, leading to better performance on toy examples and CIFAR10.
-
Drift Flow Matching
Drift Flow Matching connects direct transport maps from Drift Models with flow-based iterative refinement to enable adaptive computation in generative modeling.
-
Teacher-Feature Drifting: One-Step Diffusion Distillation with Pretrained Diffusion Representations
A simplified one-step diffusion distillation uses pretrained teacher features directly for drifting loss plus a mode coverage term, achieving FID 1.58 on ImageNet-64 and 18.4 on SDXL.
-
On the Wasserstein Gradient Flow Interpretation of Drifting Models
GMD algorithms correspond to limiting points of Wasserstein gradient flows on the KL divergence with Parzen smoothing and bear resemblance to Sinkhorn divergence fixed points, with extensions to MMD and other divergences.
Reference graph
Works this paper leans on
-
[1]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational Conference on Machine Learning, pages 2256–2265. PMLR, 2015
work page 2015
-
[2]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
work page 2020
-
[3]
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[4]
Score- based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score- based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2020
work page 2020
-
[5]
The Principles of Diffusion Models
Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, and Stefano Ermon. The principles of diffusion models. arXiv preprint arXiv:2510.21890, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models.arXiv preprint arXiv:2303.01469, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Consistency trajectory models: Learning probability flow ode trajectory of diffusion
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ode trajectory of diffusion. InInternational Conference on Learning Representations, 2024
work page 2024
-
[8]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Nicholas M Boffi, Michael S Albergo, and Eric Vanden-Eijnden. Flow map matching.arXiv preprint arXiv:2406.07507, 2024
-
[10]
Zheyuan Hu, Chieh-Hsin Lai, Yuki Mitsufuji, and Stefano Ermon. Cmt: Mid-training for efficient learning of consistency, mean flow, and flow map models.arXiv preprint arXiv:2509.24526, 2025
-
[11]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting.arXiv preprint arXiv:2602.04770, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Dorin Comaniciu and Peter Meer. Mean shift: A robust approach toward feature space analysis.IEEE Transactions on pattern analysis and machine intelligence, 24(5):603–619, 2002
work page 2002
-
[13]
Aapo Hyv¨ arinen and Peter Dayan. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6(4), 2005
work page 2005
-
[14]
Pascal Vincent. A connection between score matching and denoising autoencoders.Neural computation, 23(7):1661– 1674, 2011
work page 2011
-
[15]
Interpretation and Generalization of Score Matching
Siwei Lyu. Interpretation and generalization of score matching.arXiv preprint arXiv:1205.2629, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[16]
Bradley Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602– 1614, 2011
work page 2011
-
[17]
One-step diffusion with distribution matching distillation
Tianwei Yin, Micha¨ el Gharbi, Richard Zhang, Eli Shechtman, Fr´ edo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6613–6623. IEEE, 2024
work page 2024
-
[18]
Chun-Liang Li, Wei-Cheng Chang, Yu Cheng, Yiming Yang, and Barnab´ as P´ oczos. Mmd gan: Towards deeper understanding of moment matching network.Advances in neural information processing systems, 30, 2017
work page 2017
-
[19]
Generative moment matching networks
Yujia Li, Kevin Swersky, and Richard Zemel. Generative moment matching networks. InProceedings of the 32nd International Conference on Machine Learning-Volume 37, pages 1718–1727, 2015
work page 2015
-
[20]
Coulomb gans: Provably optimal nash equilibria via potential fields
Thomas Unterthiner, Bernhard Nessler, Calvin Seward, G¨ unter Klambauer, Martin Heusel, Hubert Ramsauer, and Sepp Hochreiter. Coulomb gans: Provably optimal nash equilibria via potential fields. InInternational Conference on Learning Representations, 2018. 23
work page 2018
-
[21]
Driftin: Single-step image generation via drift fields, 2026
Elliot. Driftin: Single-step image generation via drift fields, 2026
work page 2026
-
[22]
Oriane Sim´ eoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha¨ el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ ee Darcet, Th´ eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie,...
work page 2025
-
[23]
Zhiqi Li and Bo Zhu. A long-short flow-map perspective for drifting models.arXiv preprint arXiv:2602.20463, 2026
-
[24]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
work page 2014
-
[25]
Assaf Shocher, Amil V Dravid, Yossi Gandelsman, Inbar Mosseri, Michael Rubinstein, and Alexei A Efros. Idempotent generative network. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[26]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InInternational Conference on Learning Representations, 2021
work page 2021
-
[27]
Pagoda: Progressive growing of a one-step generator from a low-resolution diffusion teacher
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Yuhta Takida, Naoki Murata, Toshimitsu Uesaka, Yuki Mitsufuji, and Stefano Ermon. Pagoda: Progressive growing of a one-step generator from a low-resolution diffusion teacher. arXiv preprint arXiv:2405.14822, 2024
-
[28]
Knowledge Distillation in Iterative Generative Models for Improved Sampling Speed
Eric Luhman and Troy Luhman. Knowledge distillation in iterative generative models for improved sampling speed.arXiv preprint arXiv:2101.02388, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Equilibrium matching: Generative modeling with implicit energy-based models,
Runqian Wang and Yilun Du. Equilibrium matching: Generative modeling with implicit energy-based models. arXiv preprint arXiv:2510.02300, 2025. 24 Contents 1 Introduction 1 2 Preliminaries 3 3 A Fixed-Point Regression Template 4 3.1 Training Objective of Drifting Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 3.2 Mean-Shi...
-
[30]
For everyµin the above family, ifx∼µthen E ∥x∥2 2 −R 2 0 4 ≤ Cnorm,4R8 0 D2
-
[31]
For anyµ, νin the above family, ifx∼µandy∼νare independent then E⟨x,y⟩ 4 ≤ Cip,4R8 0 D2 . Assumption 7(Bounded (Feature) Norm).There exists B <∞ independent of D such that for every µ in the above family, ifx∼µthen ∥x∥2 ≤Balmost surely. Drifting-model pipelines that rely on pretrained feature maps typically enforce explicit norm control, for instance via ...
-
[32]
+ (∥y∥2 2 −R 2 0)−2⟨x,y⟩. Using (a+b+c) 2 ≤3(a 2 +b 2 +c 2), (S2 −ρ 2)2 ≤3 (∥x∥2 2 −R 2 0)2 + (∥y∥2 2 −R 2 0)2 + 4⟨x,y⟩ 2 . Taking expectations and applying Assumptions 4 and 5 gives E(S2 −ρ 2)2 ≤3 σ2R4 0 D + σ2R4 0 D + 4κR4 0 D = 3(2σ2 + 4κ)R4 0 D . Divide byρ 2 = 2R2 0 and absorb the factor 1/2 into the constant. 31 Lemma 3(Fourth Moment Bound for Mixed...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.