AgentFinVQA: A Deployable Multi-Agent Pipeline for Auditable Financial Chart QA
Pith reviewed 2026-06-26 17:32 UTC · model grok-4.3
The pith
A five-stage multi-agent pipeline for financial chart QA records every step in a traceable packet and lifts accuracy by up to 7.68 points on FinMME.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
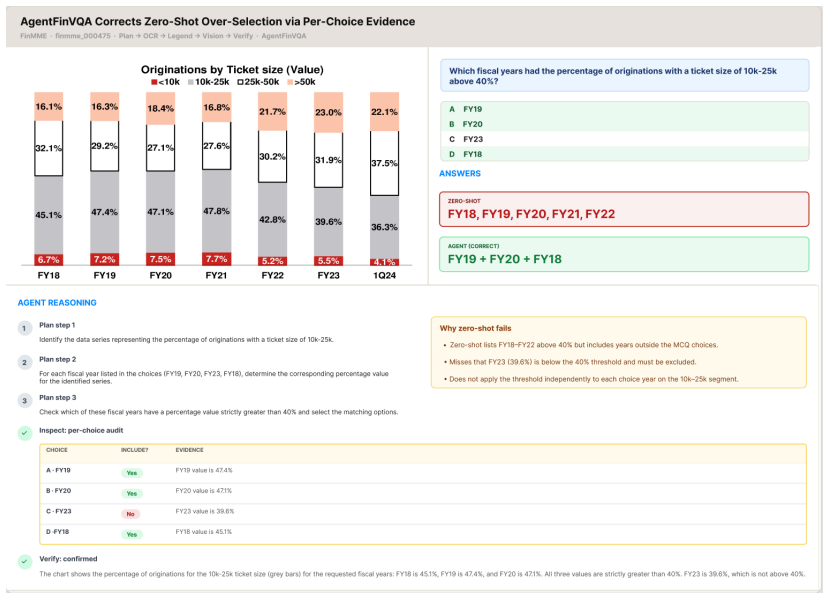
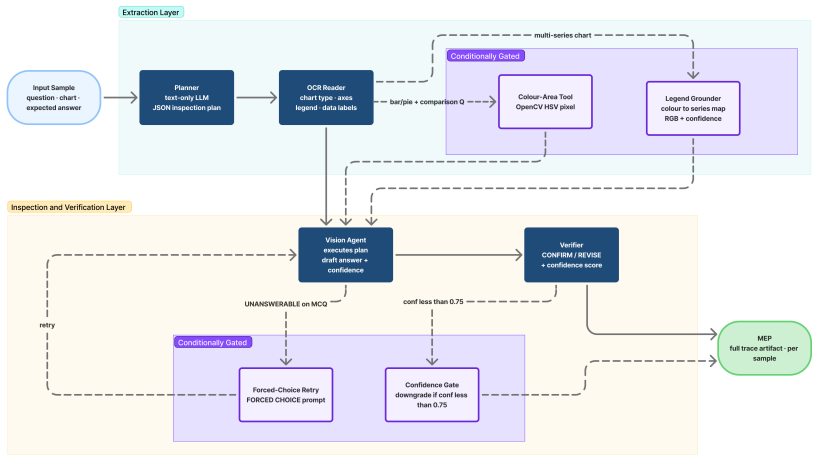
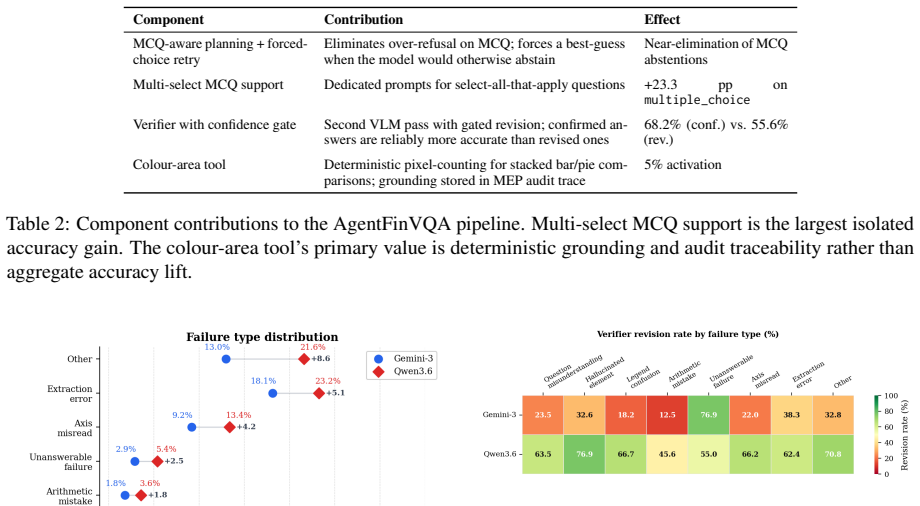
AgentFinVQA decomposes each query into planning, OCR, legend grounding, visual inspection, and verification, writing every intermediate result into a per-sample Model Evaluation Packet. With Gemini-3 Flash the system reaches 71.24 percent exact accuracy on FinMME against a 63.56 percent zero-shot baseline (McNemar p approximately 1.1 times 10 to the minus 16). The same architecture run with locally hosted Qwen3.6-27B-FP8 yields a 4.84-point gain over its matched baseline. The verifier verdict further separates high-accuracy confirmed answers (68.2 percent) from revised answers (55.6 percent), supplying a signal for human-in-the-loop routing.
What carries the argument
The five-stage multi-agent decomposition (planning, OCR, legend grounding, visual inspection, verification) together with per-sample Model Evaluation Packet logging that records every intermediate output.
If this is right
- The verifier verdict can be used to route uncertain answers to human reviewers without reviewing every case.
- Open-weights backbones retain most of the accuracy improvement while keeping all client data inside the institution.
- Question misunderstanding, legend confusion, and extraction error together account for nearly two-thirds of remaining mistakes.
- These three error types are the categories least often caught by the verifier, pointing to concrete targets for later refinement.
Where Pith is reading between the lines
- The MEP format could be adopted as a standard audit artifact for any visual QA system used in regulated finance.
- Explicit stage-by-stage logging may allow institutions to meet explainability requirements that current end-to-end models do not satisfy.
- The same decomposition pattern could be tested on non-financial chart or diagram QA tasks that also require traceability.
Load-bearing premise
The five-stage decomposition plus MEP logging actually supplies meaningful auditability and human-in-the-loop utility inside real regulated workflows rather than adding only overhead.
What would settle it
A side-by-side comparison in which compliance officers are timed on how quickly they can locate the source of an error when given only the final answer versus when given the full MEP log for the same question.
Figures
read the original abstract
Financial chart question answering in regulated settings demands more than accuracy: practitioners must know which answers to trust before acting on them, and many institutions cannot send client data to external model providers. Yet existing chart-QA agents are accuracy-focused and opaque, and most assume proprietary API access; to our knowledge, none combines auditability with on-premise deployability without significant accuracy compromise. We present AgentFinVQA, a multi-agent pipeline that decomposes each query into planning, OCR, legend grounding, visual inspection, and verification, recording every step in a traceable Model Evaluation Packet (MEP) per sample. On FinMME, AgentFinVQA improves $+7.68$ pp over a primary-backbone matched zero-shot baseline with a proprietary backbone (Gemini-3 Flash; 71.24% vs. 63.56%, McNemar $p \approx 1.1 \times 10^{-16}$), and $+4.84$ pp with open-weights Qwen3.6-27B-FP8 served locally. The verifier's verdict also serves as a useful confidence signal (68.2% vs. 55.6% exact accuracy on confirmed vs. revised answers), enabling human-in-the-loop review routing. Error analysis shows that question misunderstanding, legend confusion and extraction error account for nearly two-thirds of failures and are the categories least detected by the verifier, identifying clear directions for future work. Together these results show that auditable, on-premise financial chart QA is practical and that the open-weights system keeps most of the accuracy gains while enabling full data residency. We release our code to support reproducible evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AgentFinVQA, a multi-agent pipeline decomposing financial chart QA queries into planning, OCR, legend grounding, visual inspection, and verification stages, with all steps logged in a traceable Model Evaluation Packet (MEP) per sample to support auditability and on-premise deployment. It reports accuracy gains on FinMME of +7.68 pp versus a matched zero-shot baseline with Gemini-3 Flash (71.24% vs. 63.56%, McNemar p ≈ 1.1×10^{-16}) and +4.84 pp with local Qwen3.6-27B-FP8, notes the verifier verdict as a confidence signal (68.2% vs. 55.6% accuracy), provides an error breakdown, and releases code for reproducibility.
Significance. If the accuracy claims are reproducible and the auditability benefits are empirically validated, the work would be significant for regulated financial AI applications by demonstrating a practical path to on-premise, auditable chart QA without major accuracy loss. The code release is a clear strength that supports reproducibility and allows independent verification of the pipeline.
major comments (2)
- [Abstract] Abstract: The central claim that the five-stage decomposition plus MEP logging delivers meaningful auditability and human-in-the-loop utility in regulated financial workflows (without significant accuracy compromise) is not supported by direct evidence; no experiments measure audit time, human error-detection rates when using MEP logs, trust calibration, or deployment metrics in regulated settings, so practitioner utility is asserted from the decomposition itself rather than tested.
- [Abstract] Abstract and evaluation description: The reported accuracy lifts and McNemar significance rely on comparisons to a 'primary-backbone matched zero-shot baseline,' but the manuscript provides no details on baseline prompt construction, exact matching procedure, dataset splits, or MEP implementation, leaving the +7.68 pp and +4.84 pp gains only partially verifiable.
minor comments (1)
- [Abstract] The abstract introduces the Model Evaluation Packet (MEP) acronym without an inline definition on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims and result verifiability. We address each major comment point by point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the five-stage decomposition plus MEP logging delivers meaningful auditability and human-in-the-loop utility in regulated financial workflows (without significant accuracy compromise) is not supported by direct evidence; no experiments measure audit time, human error-detection rates when using MEP logs, trust calibration, or deployment metrics in regulated settings, so practitioner utility is asserted from the decomposition itself rather than tested.
Authors: We agree that the manuscript does not include direct empirical measurements of audit time, human error-detection rates, trust calibration, or regulated deployment metrics. The paper's contribution is the pipeline design and MEP mechanism that supplies traceable logs to enable such auditability and human-in-the-loop review, together with the reported accuracy results. We will revise the abstract to state more precisely that the MEP provides the infrastructure for auditability without claiming empirically validated practitioner utility in regulated workflows. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: The reported accuracy lifts and McNemar significance rely on comparisons to a 'primary-backbone matched zero-shot baseline,' but the manuscript provides no details on baseline prompt construction, exact matching procedure, dataset splits, or MEP implementation, leaving the +7.68 pp and +4.84 pp gains only partially verifiable.
Authors: We acknowledge that the current manuscript text does not supply sufficient implementation details for full independent verification of the baseline comparisons. While the code release supports reproducibility, we will add explicit descriptions of baseline prompt construction, the matching procedure, dataset splits, and MEP implementation to the evaluation section of the revised manuscript. revision: yes
Circularity Check
No circularity: empirical results on external benchmark
full rationale
The paper reports measured accuracy gains on the external FinMME benchmark against zero-shot baselines using Gemini-3 Flash and Qwen3.6-27B-FP8, plus a post-hoc correlation between verifier verdict and exact accuracy. These quantities are obtained by direct evaluation rather than by fitting parameters to a subset and relabeling the output as a prediction, or by any self-referential definition. The five-stage pipeline and MEP logging are presented as an engineering design whose auditability claim rests on the decomposition itself; no equations, uniqueness theorems, or ansatzes are invoked that reduce the central result to its own inputs by construction. No load-bearing self-citations appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in machine learning evaluation such as dataset representativeness and validity of statistical tests like McNemar.
invented entities (1)
-
Model Evaluation Packet (MEP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Chartagent: A chart understanding framework with tool integrated reasoning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. 2026 , url=
2026
-
[2]
2025 , month =
Gemini 3 Flash Model Card , institution =. 2025 , month =
2025
-
[3]
2026 , howpublished =
CrewAI , author =. 2026 , howpublished =
2026
-
[4]
2018 , eprint=
FigureQA: An Annotated Figure Dataset for Visual Reasoning , author=. 2018 , eprint=
2018
-
[5]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Dvqa: Understanding data visualizations via question answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=. 2018 , url=
2018
-
[6]
Proceedings of the ieee/cvf winter conference on applications of computer vision , pages=
Plotqa: Reasoning over scientific plots , author=. Proceedings of the ieee/cvf winter conference on applications of computer vision , pages=. 2020 , url=
2020
-
[7]
C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Masry, Ahmed and Long, Do Xuan and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul. C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.177
-
[8]
C hart QAP ro: A More Diverse and Challenging Benchmark for Chart Question Answering
Masry, Ahmed and Islam, Mohammed Saidul and Ahmed, Mahir and Bajaj, Aayush and Kabir, Firoz and Kartha, Aaryaman and Laskar, Md Tahmid Rahman and Rahman, Mizanur and Rahman, Shadikur and Shahmohammadi, Mehrad and Thakkar, Megh and Parvez, Md Rizwan and Hoque, Enamul and Joty, Shafiq. C hart QAP ro: A More Diverse and Challenging Benchmark for Chart Questi...
-
[9]
F in MME : Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
Luo, Junyu and Kou, Zhizhuo and Yang, Liming and Luo, Xiao and Huang, Jinsheng and Xiao, Zhiping and Peng, Jingshu and Liu, Chengzhong and Ji, Jiaming and Liu, Xuanzhe and Han, Sirui and Zhang, Ming and Guo, Yike. F in MME : Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation. Proceedings of the 63rd Annual Meeting of the Association for Comp...
-
[10]
2025 , eprint=
FinChart-Bench: Benchmarking Financial Chart Comprehension in Vision-Language Models , author=. 2025 , eprint=
2025
-
[11]
arXiv preprint arXiv:2411.03314 , year=
MME-Finance: A Multimodal Finance Benchmark for Expert-level Understanding and Reasoning , author=. arXiv preprint arXiv:2411.03314 , year=
-
[12]
D e P lot: One-shot visual language reasoning by plot-to-table translation
Liu, Fangyu and Eisenschlos, Julian and Piccinno, Francesco and Krichene, Syrine and Pang, Chenxi and Lee, Kenton and Joshi, Mandar and Chen, Wenhu and Collier, Nigel and Altun, Yasemin. D e P lot: One-shot visual language reasoning by plot-to-table translation. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/202...
-
[13]
M at C ha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering
Liu, Fangyu and Piccinno, Francesco and Krichene, Syrine and Pang, Chenxi and Lee, Kenton and Joshi, Mandar and Altun, Yasemin and Collier, Nigel and Eisenschlos, Julian. M at C ha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volum...
-
[14]
U ni C hart: A Universal Vision-language Pretrained Model for Chart Comprehension and Reasoning
Masry, Ahmed and Kavehzadeh, Parsa and Do, Xuan Long and Hoque, Enamul and Joty, Shafiq. U ni C hart: A Universal Vision-language Pretrained Model for Chart Comprehension and Reasoning. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.906
-
[15]
2023 , url =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[16]
2026 , eprint=
ChartAgent: A Multimodal Agent for Visually Grounded Reasoning in Complex Chart Question Answering , author=. 2026 , eprint=
2026
-
[17]
Advances in Neural Information Processing Systems , volume=
Chartsketcher: Reasoning with multimodal feedback and reflection for chart understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
MAC - SQL : A Multi-Agent Collaborative Framework for Text-to- SQL
Wang, Bing and Ren, Changyu and Yang, Jian and Liang, Xinnian and Bai, Jiaqi and Chai, LinZheng and Yan, Zhao and Zhang, Qian-Wen and Yin, Di and Sun, Xing and Li, Zhoujun. MAC - SQL : A Multi-Agent Collaborative Framework for Text-to- SQL. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[19]
The Fourteenth International Conference on Learning Representations , year=
Through the Lens of Contrast: Self-Improving Visual Reasoning in VLMs , author=. The Fourteenth International Conference on Learning Representations , year=
-
[20]
ACM International Conference on AI in Finance (ICAIF) , year=
FAITH: A Framework for Assessing Intrinsic Tabular Hallucinations in Finance , author=. ACM International Conference on AI in Finance (ICAIF) , year=
-
[21]
Proceedings of the 6th ACM International Conference on AI in Finance , pages=
FAITH: A Framework for Assessing Intrinsic Tabular Hallucinations in Finance , author=. Proceedings of the 6th ACM International Conference on AI in Finance , pages=. 2025 , url=
2025
-
[22]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph and Stoica, Ion , booktitle =. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.