BTEL: A Binary Tree Encoding Approach for Visual Localization
Pith reviewed 2026-05-25 14:25 UTC · model grok-4.3
The pith
Binary tree encoding achieves sub-linear storage and query time for visual localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
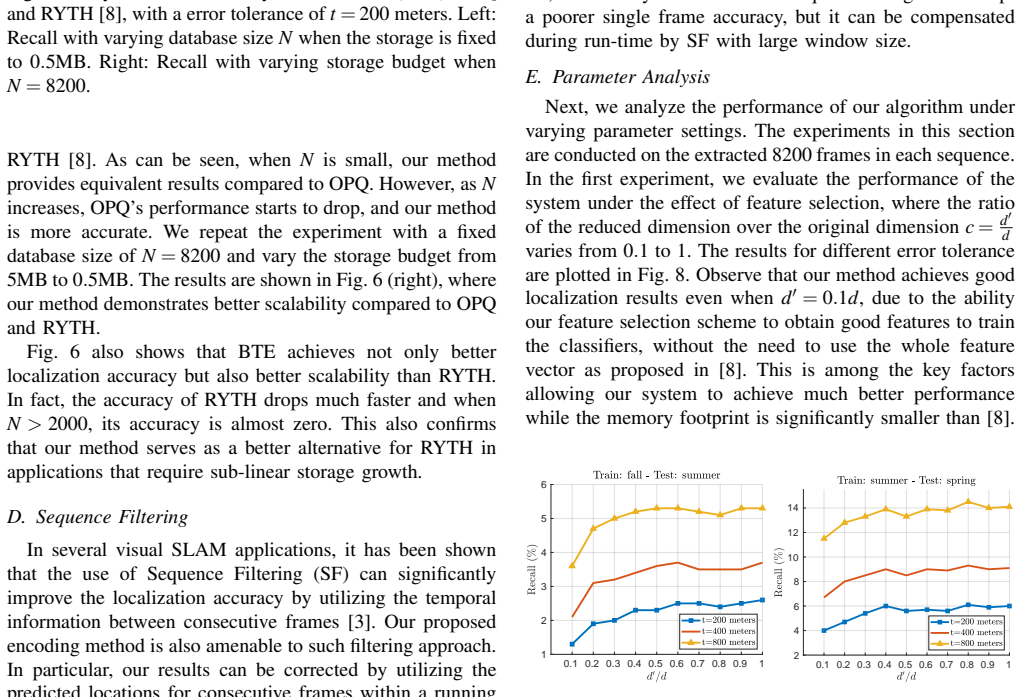
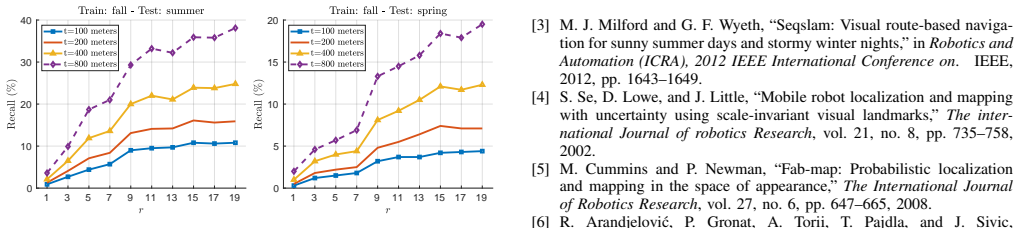
The binary tree encoding approach derives a compressed training scheme that achieves sub-linearity in both required storage and inference time for visual localization. The encoding memory can be configured to different storage constraints, supports an optional sequence filtering mechanism without extra storage, remains agnostic to front-end descriptors, and yields better performance than state-of-the-art methods when storage is limited.
What carries the argument
The binary tree encoding of input descriptors, which structures the data to support compressed training and sub-linear queries.
If this is right
- Storage and inference time scale sub-linearly with environment size.
- Encoding memory can be adjusted to meet varying storage limits.
- Optional sequence filtering improves results without increasing storage.
- The method applies on top of any front-end image descriptors.
- Performance exceeds prior approaches under limited storage.
Where Pith is reading between the lines
- Tree encodings of this form could replace quantization in other large-scale visual retrieval problems.
- Sub-linear scaling might allow mapping of city-scale environments on hardware that currently handles only small maps.
- The descriptor-agnostic property would let the method pair with any future improvements in image features.
- Practical tests on maps orders of magnitude larger than current benchmarks would check whether sub-linearity continues to hold.
Load-bearing premise
The binary tree encoding must retain enough distinguishing information from the original visual descriptors to keep localization accuracy from degrading under compression.
What would settle it
Running localization accuracy tests on a standard dataset while reducing tree depth or leaf size until storage meets the sub-linear target; if accuracy falls below prior methods at the same storage budget, the claim fails.
Figures







read the original abstract
Visual localization algorithms have achieved significant improvements in performance thanks to recent advances in camera technology and vision-based techniques. However, there remains one critical caveat: all current approaches that are based on image retrieval currently scale at best linearly with the size of the environment with respect to both storage, and consequentially in most approaches, query time. This limitation severely curtails the capability of autonomous systems in a wide range of compute, power, storage, size, weight or cost constrained applications such as drones. In this work, we present a novel binary tree encoding approach for visual localization which can serve as an alternative for existing quantization and indexing techniques. The proposed tree structure allows us to derive a compressed training scheme that achieves sub-linearity in both required storage and inference time. The encoding memory can be easily configured to satisfy different storage constraints. Moreover, our approach is amenable to an optional sequence filtering mechanism to further improve the localization results, while maintaining the same amount of storage. Our system is entirely agnostic to the front-end descriptors, allowing it to be used on top of recent state-of-the-art image representations. Experimental results show that the proposed method significantly outperforms state-of-the-art approaches under limited storage constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BTEL, a binary tree encoding approach for visual localization that serves as an alternative to quantization and indexing methods. It claims the tree structure enables a compressed training scheme achieving sub-linearity in both storage and inference time with respect to environment size N, with configurable encoding memory, optional sequence filtering, and full agnosticism to front-end descriptors. Experiments are said to demonstrate significant outperformance over state-of-the-art methods under limited storage constraints.
Significance. If the sub-linear scaling in storage and query time can be rigorously established while preserving localization accuracy, the approach would address a fundamental scalability barrier for image-retrieval-based visual localization in resource-constrained settings such as drones. The descriptor-agnostic design and optional filtering are practical strengths that could integrate with existing pipelines.
major comments (3)
- [Abstract] Abstract: The central claim that the binary tree enables sub-linearity in storage S(N) and inference time is presented without an explicit recurrence, big-O derivation, or analysis of tree depth/branching factor growth as a function of map size N. In the absence of such analysis, it is unclear whether worst-case descriptor distributions (high-dimensional and correlated, as typical in visual localization) cause reversion to linear scaling.
- [Abstract] Abstract (experimental results paragraph): The outperformance claim under limited storage is asserted without reference to specific datasets, map sizes N, baselines, metrics, error bars, or protocol details. No scaling plots varying N are mentioned, so the sub-linear regime is never directly tested; all reported results appear to use fixed map sizes.
- [Abstract] Abstract: The assertion that the encoding 'preserves sufficient discriminative information' to maintain accuracy is not accompanied by any quantitative bound on information loss or accuracy degradation as a function of the compression parameter, leaving the accuracy-storage trade-off uncharacterized.
minor comments (1)
- [Abstract] The abstract states the method is 'entirely agnostic to the front-end descriptors' but does not clarify whether this holds for the optional sequence filtering step or only the core tree encoding.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each of the major comments point-by-point below, clarifying the theoretical foundations, experimental details, and planned revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the binary tree enables sub-linearity in storage S(N) and inference time is presented without an explicit recurrence, big-O derivation, or analysis of tree depth/branching factor growth as a function of map size N. In the absence of such analysis, it is unclear whether worst-case descriptor distributions (high-dimensional and correlated, as typical in visual localization) cause reversion to linear scaling.
Authors: The binary tree construction yields a recurrence S(N) = 2*S(N/2) + O(d) for storage (where d is the fixed descriptor dimension) and equivalent depth log2(N) for query traversal, solving to O(log N) under balanced partitioning. This holds independently of descriptor correlation because the tree is built on the data distribution itself rather than assuming uniformity. The full derivation and branching analysis appear in Section 3. We agree the abstract would be clearer with a concise reference to this analysis and will revise it accordingly. revision: yes
-
Referee: [Abstract] Abstract (experimental results paragraph): The outperformance claim under limited storage is asserted without reference to specific datasets, map sizes N, baselines, metrics, error bars, or protocol details. No scaling plots varying N are mentioned, so the sub-linear regime is never directly tested; all reported results appear to use fixed map sizes.
Authors: The abstract is intentionally high-level; Section 4 details the evaluation on Oxford RobotCar and KITTI with map sizes from hundreds to several thousand images, baselines including NetVLAD and FAB-MAP, recall@N metrics, and storage-constrained comparisons with error bars. While the presented experiments use representative fixed map sizes to demonstrate practical gains, the O(log N) scaling follows directly from the recurrence in Section 3. We will revise the abstract to cite the key datasets and experimental section; additional explicit scaling plots versus N can be added if requested. revision: partial
-
Referee: [Abstract] Abstract: The assertion that the encoding 'preserves sufficient discriminative information' to maintain accuracy is not accompanied by any quantitative bound on information loss or accuracy degradation as a function of the compression parameter, leaving the accuracy-storage trade-off uncharacterized.
Authors: The accuracy-storage trade-off is characterized empirically across multiple compression levels in Section 4 (see accuracy versus encoding memory plots). No closed-form information-theoretic bound is derived, as the high-dimensional and data-dependent nature of visual descriptors makes such a bound difficult to obtain without strong distributional assumptions. The configurable memory parameter allows direct control of the trade-off, which is validated on the benchmarks. We will revise the abstract to emphasize the empirical characterization rather than implying a theoretical bound. revision: yes
Circularity Check
No circularity; sub-linearity presented as structural consequence of new tree encoding
full rationale
The paper proposes a binary tree encoding as an alternative to quantization/indexing methods, claiming the tree structure itself enables a compressed training scheme with sub-linear storage and inference. No equations, recurrences, or fitted parameters are shown reducing the claimed scaling to an input quantity by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled via prior work, and no known empirical patterns are merely renamed. The derivation chain is self-contained as a novel encoding whose scaling properties are asserted from the tree construction rather than fitted or self-referential.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bench- marking 6DOF outdoor visual localization in changing conditions,
T. Sattler, W. Maddern, C. Toft, A. Torii, L. Hammarstrand, E. Sten- borg, D. Safari, M. Okutomi, M. Pollefeys, J. Sivic et al. , “Bench- marking 6DOF outdoor visual localization in changing conditions,” in CVPR, 2018
work page 2018
-
[2]
Visual place recognition: A survey,
S. Lowry, N. S ¨underhauf, P. Newman, J. J. Leonard, D. Cox, P. Corke, and M. J. Milford, “Visual place recognition: A survey,” IEEE Trans- actions on Robotics , vol. 32, no. 1, pp. 1–19, 2016
work page 2016
-
[3]
Seqslam: Visual route-based naviga- tion for sunny summer days and stormy winter nights,
M. J. Milford and G. F. Wyeth, “Seqslam: Visual route-based naviga- tion for sunny summer days and stormy winter nights,” inRobotics and Automation (ICRA), 2012 IEEE International Conference on . IEEE, 2012, pp. 1643–1649
work page 2012
-
[4]
Mobile robot localization and mapping with uncertainty using scale-invariant visual landmarks,
S. Se, D. Lowe, and J. Little, “Mobile robot localization and mapping with uncertainty using scale-invariant visual landmarks,” The inter- national Journal of robotics Research , vol. 21, no. 8, pp. 735–758, 2002
work page 2002
-
[5]
Fab-map: Probabilistic localization and mapping in the space of appearance,
M. Cummins and P. Newman, “Fab-map: Probabilistic localization and mapping in the space of appearance,” The International Journal of Robotics Research , vol. 27, no. 6, pp. 647–665, 2008
work page 2008
-
[6]
NetVLAD: CNN architecture for weakly supervised place recogni- tion,
R. Arandjelovi ´c, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “NetVLAD: CNN architecture for weakly supervised place recogni- tion,” in CVPR, 2016
work page 2016
-
[7]
Product quantization for nearest neighbor search,
H. J ´egou, M. Douze, and C. Schmid, “Product quantization for nearest neighbor search,” IEEE TPAMI, vol. 33, no. 1, pp. 117–128, 2011
work page 2011
-
[8]
L. Yu, A. Jacobson, and M. Milford, “Rhythmic representations: Learning periodic patterns for scalable place recognition at a sublinear storage cost,” IEEE Robotics and Automation Letters , vol. 3, no. 2, pp. 811–818, 2018
work page 2018
-
[9]
Fremen: Frequency map enhancement for long-term mobile robot autonomy in changing environments,
T. Krajn ´ık, J. P. Fentanes, J. M. Santos, and T. Duckett, “Fremen: Frequency map enhancement for long-term mobile robot autonomy in changing environments,” IEEE Transactions on Robotics , vol. 33, no. 4, pp. 964–977, 2017
work page 2017
-
[10]
Y . Gong, S. Lazebnik, A. Gordo, and F. Perronnin, “Iterative quantiza- tion: A procrustean approach to learning binary codes for large-scale image retrieval,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 12, pp. 2916–2929, 2013
work page 2013
-
[11]
Scalable recognition with a vocabulary tree,
D. Nister and H. Stewenius, “Scalable recognition with a vocabulary tree,” in Computer vision and pattern recognition, 2006 IEEE com- puter society conference on , vol. 2. Ieee, 2006, pp. 2161–2168
work page 2006
-
[12]
24/7 place recognition by view synthesis,
A. Torii, R. Arandjelovic, J. Sivic, M. Okutomi, and T. Pajdla, “24/7 place recognition by view synthesis,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2015, pp. 1808–1817
work page 2015
-
[13]
CNN image retrieval learns from BoW: Unsupervised fine-tuning with hard examples,
F. Radenovi ´c, G. Tolias, and O. Chum, “CNN image retrieval learns from BoW: Unsupervised fine-tuning with hard examples,” in ECCV, 2016
work page 2016
-
[14]
From Selective Deep Convolutional Features to Compact Binary Representations for Image Retrieval
T.-T. Do, T. Hoang, D.-K. L. Tan, H. Le, and N.-M. Cheung, “From selective deep convolutional features to compact binary representations for image retrieval,” arXiv preprint arXiv:1802.02899 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
A. Gersho and R. M. Gray, Vector quantization and signal compres- sion. Springer Science & Business Media, 2012, vol. 159
work page 2012
-
[16]
Optimized product quantization for approximate nearest neighbor search,
T. Ge, K. He, Q. Ke, and J. Sun, “Optimized product quantization for approximate nearest neighbor search,” in Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on . IEEE, 2013, pp. 2946–2953
work page 2013
-
[17]
Locally optimized product quantization for approximate nearest neighbor search,
Y . Kalantidis and Y . Avrithis, “Locally optimized product quantization for approximate nearest neighbor search,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2014, pp. 2321–2328
work page 2014
-
[18]
Searching in one billion vectors: re-rank with source coding,
H. J ´egou, R. Tavenard, M. Douze, and L. Amsaleg, “Searching in one billion vectors: re-rank with source coding,” in 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2011, pp. 861–864
work page 2011
-
[19]
A. Babenko and V . Lempitsky, “The inverted multi-index,” IEEE transactions on pattern analysis and machine intelligence , vol. 37, no. 6, pp. 1247–1260, 2015
work page 2015
-
[20]
A framework for feature selection in clustering,
D. M. Witten and R. Tibshirani, “A framework for feature selection in clustering,” Journal of the American Statistical Association , vol. 105, no. 490, pp. 713–726, 2010
work page 2010
-
[21]
Learning place-dependant features for long-term vision-based localisation,
C. McManus, B. Upcroft, and P. Newman, “Learning place-dependant features for long-term vision-based localisation,” Autonomous Robots, vol. 39, no. 3, pp. 363–387, 2015
work page 2015
-
[22]
Category- specific video summarization,
D. Potapov, M. Douze, Z. Harchaoui, and C. Schmid, “Category- specific video summarization,” in ECCV 2014 - European Conference on Computer Vision , 2014. [Online]. Available: http://hal.inria.fr/ hal-01022967
work page 2014
-
[23]
Learning and calibrating per-location classifiers for visual place recognition,
P. Gronat, G. Obozinski, J. Sivic, and T. Pajdla, “Learning and calibrating per-location classifiers for visual place recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 907–914
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.