ICA Lens: Interpreting Language Models Without Training Another Dictionary
Pith reviewed 2026-06-27 10:19 UTC · model grok-4.3
The pith
Independent component analysis recovers interpretable directions in language model activations without training sparse autoencoders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Independent component analysis, applied through a GPU-parallel FastICA pipeline equipped with LLM-specific stability recipes and fitting diagnostics, recovers compact human-interpretable directions from activations of GPT-2 Small, Gemma 2 2B, and Qwen 3.5 2B Base; these directions prove competitive with public sparse autoencoders on sparse probing and superior on targeted probe perturbation under modest budgets, showing that substantial interpretable structure already exists in activation geometry before any neural dictionary is trained.
What carries the argument
ICALens workflow: an optimized GPU-parallel FastICA implementation augmented with LLM-specific stability recipes and diagnostics that produces auditable, layer-wise non-Gaussian directions.
If this is right
- Layer-wise analysis of multiple models becomes feasible without per-layer dictionary training.
- ICA directions can serve as an initial set of features before any SAE is trained.
- Targeted interventions on model behavior can be tested at lower cost under small-to-medium budgets.
- The same stabilized pipeline can be rerun on new checkpoints or architectures without retraining overhead.
Where Pith is reading between the lines
- The approach might be combined with SAEs by using ICA directions to initialize or constrain dictionary learning.
- If non-Gaussianity reliably signals selectivity, the same test could be applied to attention heads or MLP neurons directly.
- Rapid iteration across many models could change the default workflow from "train SAE first" to "run ICA first, train SAE only where needed."
Load-bearing premise
Non-Gaussian directions recovered by ICA correspond to human-interpretable, token-selective features in the activations.
What would settle it
A new language model in which ICA directions produce no better than random accuracy on sparse probing tasks would falsify the competitiveness claim.
Figures

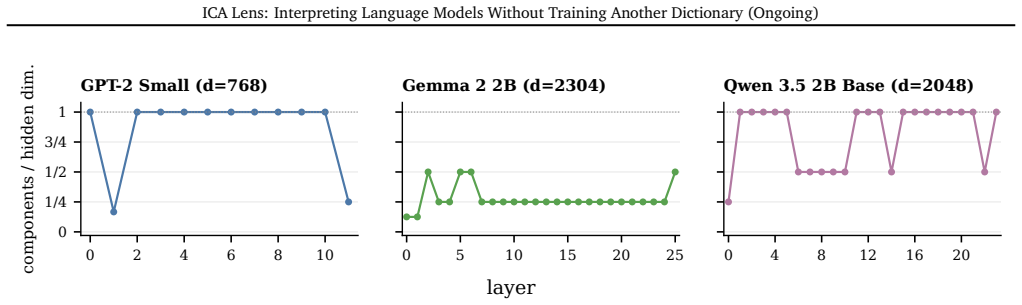



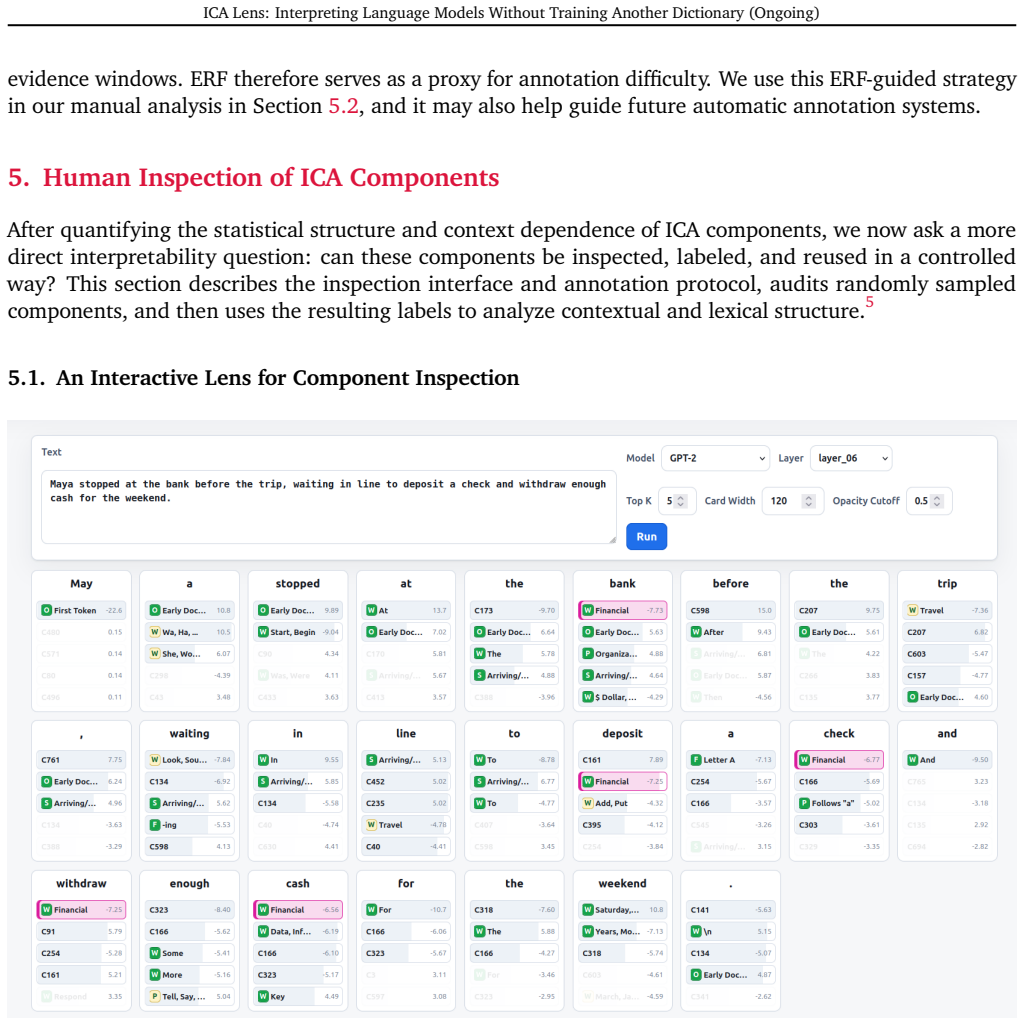



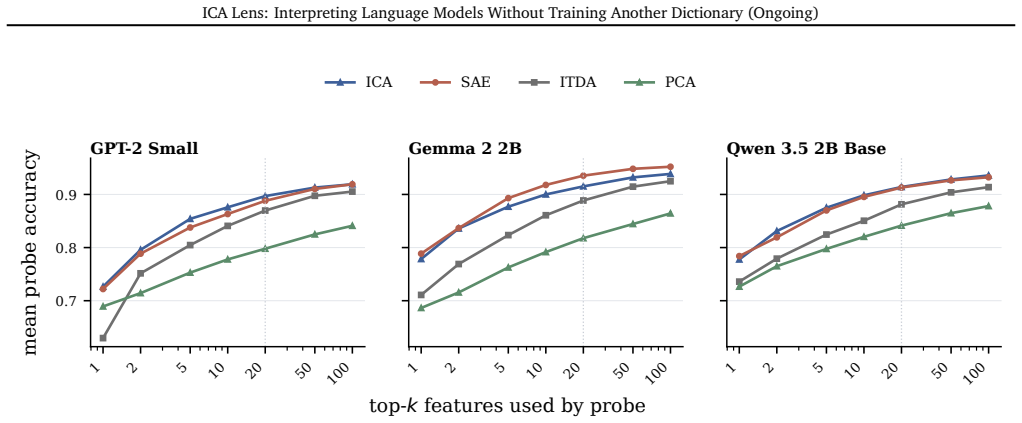
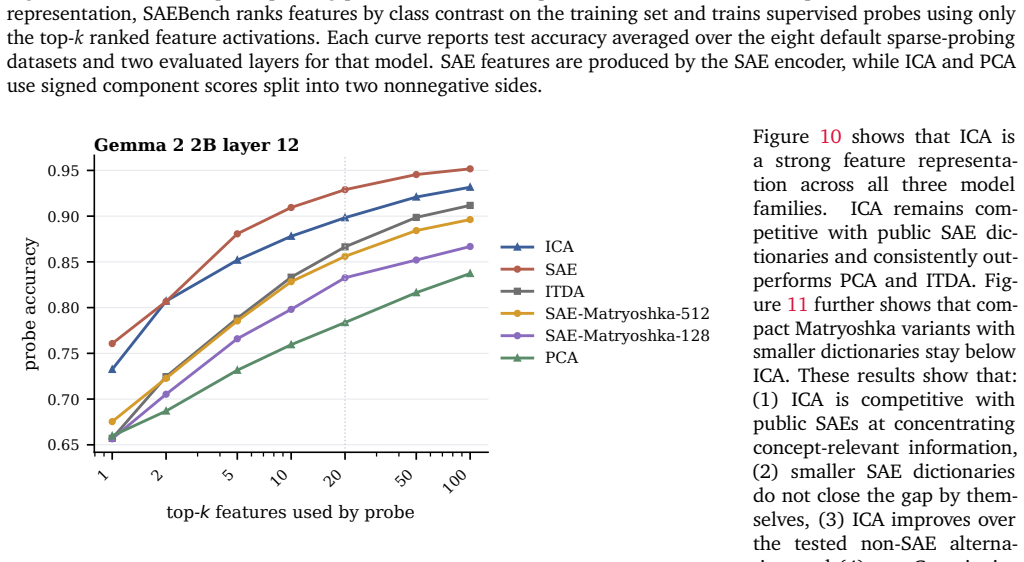













read the original abstract
Finding interpretable directions in language-model representations is critical for understanding and controlling model behavior. Sparse autoencoders (SAEs) have become the standard tool for this purpose, but using them as the default first lens often requires training, storing, and evaluating large overcomplete dictionaries. This bottleneck limits rapid exploration and raises a fundamental question: how much interpretable structure is already visible from activation geometry before training another neural dictionary? Our intuition is simple: many interpretable directions are selective on tokens, and these directions should look less Gaussian than random directions. We therefore revisit independent component analysis (ICA), a classical method for finding non-Gaussian directions, as a compact lens for language-model interpretability. We find that ICA has been underestimated for LLM interpretability, because prior uses often relied on off-the-shelf ICA implementations that are brittle on LLM activations and lacked systematic tools for inspecting and evaluating the recovered directions. To bridge these gaps, we introduce ICALens, the first practical workflow for stable, efficient, and auditable ICA analysis of LLM representations. It combines an optimized GPU-parallel FastICA pipeline with LLM-specific stability recipes and better fitting diagnostics, enabling efficient and reliable layer-wise analysis. Across GPT-2 Small, Gemma 2 2B, and Qwen 3.5 2B Base, ICALens efficiently recovers compact, human-interpretable directions without per-layer gradient-based dictionary training. On SAEBench, ICA is competitive with public SAEs in sparse probing and outperforms them in targeted probe perturbation under small-to-medium budgets. These results suggest that ICA should not be viewed as a weak baseline, but as an efficient and complementary first lens for exploring language-model representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ICALens, a workflow combining an optimized GPU-parallel FastICA pipeline with LLM-specific stability recipes and fitting diagnostics to recover non-Gaussian, token-selective directions from language-model activations. It argues that many interpretable features are already visible from activation geometry and that ICA, when properly stabilized, serves as an efficient alternative to training sparse autoencoders. The central empirical claim is that, across GPT-2 Small, Gemma 2 2B, and Qwen 3.5 2B Base, ICA directions are competitive with public SAEs on SAEBench sparse probing and outperform them on targeted probe perturbation under small-to-medium budgets, positioning ICA as a complementary first lens rather than a weak baseline.
Significance. If the benchmark results hold with full protocol details, the work would demonstrate that classical ICA, augmented with domain-specific stability techniques, can recover compact and auditable directions without per-layer gradient-based dictionary training. This would reduce computational barriers to rapid layer-wise exploration and provide a reproducible, parameter-light baseline that complements SAE-based methods. The explicit comparison to independently published public SAEs and the focus on stability recipes are strengths that support falsifiable evaluation.
major comments (1)
- [Abstract and experimental evaluation section] Abstract and experimental evaluation section: the claim that 'ICA is competitive with public SAEs in sparse probing and outperforms them in targeted probe perturbation under small-to-medium budgets' is unsupported by any quantitative results, error bars, dataset details, exact experimental protocol, or description of how the recovered ICA directions were evaluated on SAEBench. This absence is load-bearing for the central empirical claim and prevents verification of whether the data support the stated competitiveness.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit quantitative support of our central empirical claims. We agree that the experimental evaluation section must provide sufficient detail for verification and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation section] Abstract and experimental evaluation section: the claim that 'ICA is competitive with public SAEs in sparse probing and outperforms them in targeted probe perturbation under small-to-medium budgets' is unsupported by any quantitative results, error bars, dataset details, exact experimental protocol, or description of how the recovered ICA directions were evaluated on SAEBench. This absence is load-bearing for the central empirical claim and prevents verification of whether the data support the stated competitiveness.
Authors: We acknowledge this gap in the current draft. The revised manuscript will expand the experimental evaluation section to include: (1) full SAEBench metric tables with numerical values for sparse probing (e.g., F1 scores) and targeted probe perturbation (e.g., accuracy drops) across the three models; (2) error bars computed over multiple random seeds and activation samples; (3) precise dataset splits and token counts used for fitting and evaluation; (4) the exact protocol for mapping ICA directions to SAEBench probes, including thresholding and normalization steps; and (5) direct side-by-side comparisons with the cited public SAEs under matched compute budgets. These additions will make the competitiveness claim directly verifiable. revision: yes
Circularity Check
No significant circularity
full rationale
The paper applies classical ICA (a pre-existing statistical method) to LLM activations and evaluates recovered directions via external benchmarks (SAEBench) against independently published public SAEs. No equations or claims define core quantities such as non-Gaussian directions or stability metrics from the paper's own fitted outputs; the central empirical claims rest on direct comparison rather than self-referential prediction or self-citation chains. The derivation chain is self-contained against external data and classical methods.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The latent sources are statistically independent and at most one is Gaussian.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1109/TSP.2018.2844203. Anthony J. Bell and Terrence J. Sejnowski. An information-maximization approach to blind separation and blind deconvolution.Neural Computation, 7(6):1129–1159,
-
[2]
doi: 10.1162/neco.1995.7.6.1129. Anthony J Bell and Terrence J Sejnowski. The “independent components” of natural scenes are edge filters. Vision research, 37(23):3327–3338,
-
[3]
Bart Bussmann, Patrick Leask, and Neel Nanda
https://transformer-circuits.pub/2023/monosemantic-features/index.html. Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders.arXiv preprint arXiv:2412.06410,
arXiv 2023
-
[4]
Learning multi-level features with matryoshka sparse autoencoders.arXiv preprint arXiv:2503.17547,
Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. Learning multi-level features with matryoshka sparse autoencoders.arXiv preprint arXiv:2503.17547,
-
[5]
doi: 10.1049/ip-f-2.1993.0054. David Chanin. Are sparse autoencoder benchmarks reliable?arXiv preprint arXiv:2605.18229,
-
[6]
Qwen-scope: Turning sparse features into development tools for large language models
Boyi Deng, Xu Wang, Yaoning Wang, Yu Wan, Yubo Ma, Baosong Yang, Haoran Wei, Jialong Tang, Huan Lin, Ruize Gao, et al. Qwen-scope: Turning sparse features into development tools for large language models. arXiv preprint arXiv:2605.11887,
-
[7]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. InInternational Conference on Learning Representations, volume 2025, pages 26721–26754,
2025
-
[8]
Finding neurons in a haystack: Case studies with sparse probing.arXiv preprint arXiv:2305.01610,
30 ICA Lens: Interpreting Language Models Without Training Another Dictionary (Ongoing) Wes Gurnee, Neel Nanda, Matthew Pauly, Katherine Harvey, Dmitrii Troitskii, and Dimitris Bertsimas. Finding neurons in a haystack: Case studies with sparse probing.arXiv preprint arXiv:2305.01610,
-
[9]
Zerotuning: Unlocking the initial token’s power to enhance large language models without training
Feijiang Han, Xiaodong Yu, Jianheng Tang, Qingyun Zeng, Licheng Guo, and Lyle Ungar. Zerotuning: Unlocking the initial token’s power to enhance large language models without training. InICML 2025 Workshop on Methods and Opportunities at Small Scale,
2025
-
[10]
Robert Huben, Hoagy Cunningham, Logan Smith, Aidan Ewart, and Lee Sharkey
URLhttps://openreview.net/forum? id=THSbsRWy9v. Robert Huben, Hoagy Cunningham, Logan Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InInternational Conference on Learning Representations, volume 2024, pages 7827–7845,
2024
-
[11]
URL https://arxiv.org/abs/2502.16681. Adam Karvonen, Can Rager, Johnny Lin, Curt Tigges, Joseph Bloom, David Chanin, Yeu-Tong Lau, Eoin Farrell, Callum McDougall, Kola Ayonrinde, et al. Saebench: A comprehensive benchmark for sparse autoencoders in language model interpretability.arXiv preprint arXiv:2503.09532,
-
[12]
Patrick Leask, Neel Nanda, and Noura Al Moubayed. Inference-time decomposition of activations (itda): A scalable approach to interpreting large language models.arXiv preprint arXiv:2505.17769,
-
[13]
doi: 10.1162/089976699300016719. Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma
-
[14]
Towards principled evaluations of sparse autoencoders for interpretability and control
Aleksandar Makelov, Georg Lange, and Neel Nanda. Towards principled evaluations of sparse autoencoders for interpretability and control. InInternational Conference on Learning Representations, volume 2025, pages 33588–33636,
2025
-
[15]
Anish Mudide, Josh Engels, Eric Michaud, Max Tegmark, and Christian Schroeder de Witt
doi: 10.32614/RJ-2018-046. Anish Mudide, Josh Engels, Eric Michaud, Max Tegmark, and Christian Schroeder de Witt. Efficient dictionary learning with switch sparse autoencoders. InInternational Conference on Learning Representations, volume 2025, pages 101830–101844,
-
[16]
Exploring interpretability of independent components of word embeddings with automated word intruder test
31 ICA Lens: Interpreting Language Models Without Training Another Dictionary (Ongoing) Tomáš Musil and David Mareček. Exploring interpretability of independent components of word embeddings with automated word intruder test. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue, editors,Proceedings of the...
2024
-
[17]
URLhttps://aclanthology.org/2024.lrec-main.605/
ELRA and ICCL. URLhttps://aclanthology.org/2024.lrec-main.605/. Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 5(3):e00024–001,
2024
-
[18]
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models.arXiv preprint arXiv:2311.03658,
-
[19]
Gonçalo Paulo, Alex Mallen, Caden Juang, and Nora Belrose. Automatically interpreting millions of features in large language models.arXiv preprint arXiv:2410.13928,
-
[20]
Improving dictionary learning with gated sparse autoencoders.arXiv preprint arXiv:2404.16014, 2024a
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda. Improving dictionary learning with gated sparse autoencoders.arXiv preprint arXiv:2404.16014, 2024a. Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. Jumping ahead: ...
-
[21]
Massive activations in large language models.arXiv preprint arXiv:2402.17762,
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models.arXiv preprint arXiv:2402.17762,
-
[22]
pub/2024/scaling-monosemanticity/index.html
URL https://transformer-circuits. pub/2024/scaling-monosemanticity/index.html. Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D. Manning, andChristopherPotts. AxBench: SteeringLLMs? evensimplebaselinesoutperformsparseautoen- coders. InProceedings of the 42nd International Conference on Machine Learning, volu...
2024
-
[23]
Discovering universal geometry in embed- dings with ica
32 ICA Lens: Interpreting Language Models Without Training Another Dictionary (Ongoing) Hiroaki Yamagiwa, Momose Oyama, and Hidetoshi Shimodaira. Discovering universal geometry in embed- dings with ica. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4647–4675,
2023
-
[24]
Axis tour: Word tour determines the order of axes in ica-transformed embeddings
Hiroaki Yamagiwa, Yusuke Takase, and Hidetoshi Shimodaira. Axis tour: Word tour determines the order of axes in ica-transformed embeddings. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 477–506,
2024
-
[25]
Zejia You, Chunyuan Deng, and Hanjie Chen. Spherical steering: Geometry-aware activation rotation for language models.arXiv preprint arXiv:2602.08169,
-
[26]
a" W Any F Letter B ? unlabeled P Follows
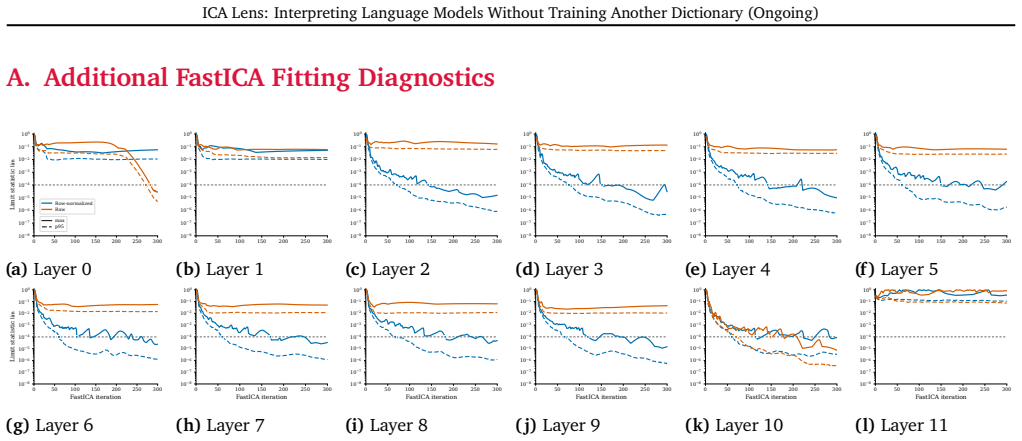
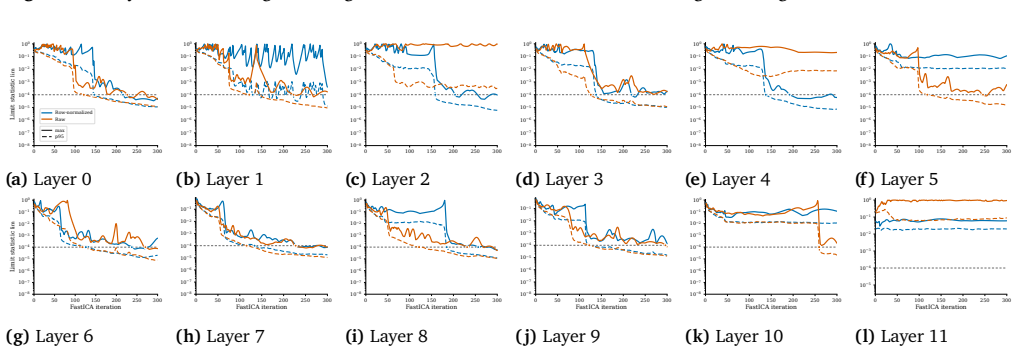
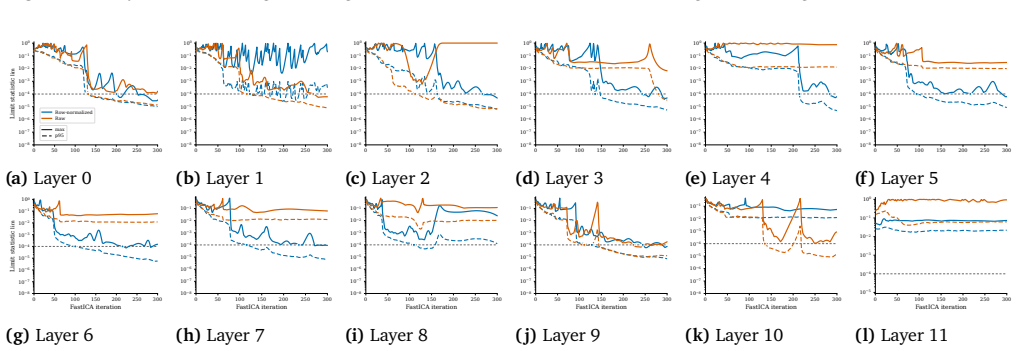
33 ICA Lens: Interpreting Language Models Without Training Another Dictionary (Ongoing) A. Additional FastICA Fitting Diagnostics 0 50 100 150 200 250 300 10−8 10−7 10−6 10−5 10−4 10−3 10−2 10−1 100 Limit statistic lim Row-normalized Raw max p95 (a)Layer 0 0 50 100 150 200 250 300 10−8 10−7 10−6 10−5 10−4 10−3 10−2 10−1 100 (b)Layer 1 0 50 100 150 200 250...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.