Are Reasoning Vision-Language Models Robust to Semantic Visual Distractions?
Pith reviewed 2026-06-27 17:35 UTC · model grok-4.3
The pith
Reasoning vision-language models integrate task-irrelevant visual cues into their reasoning chains more readily than base models do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
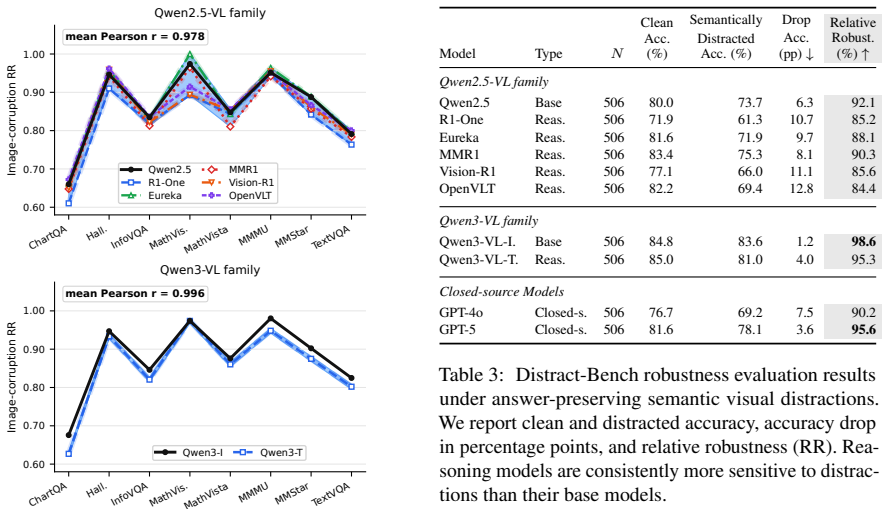
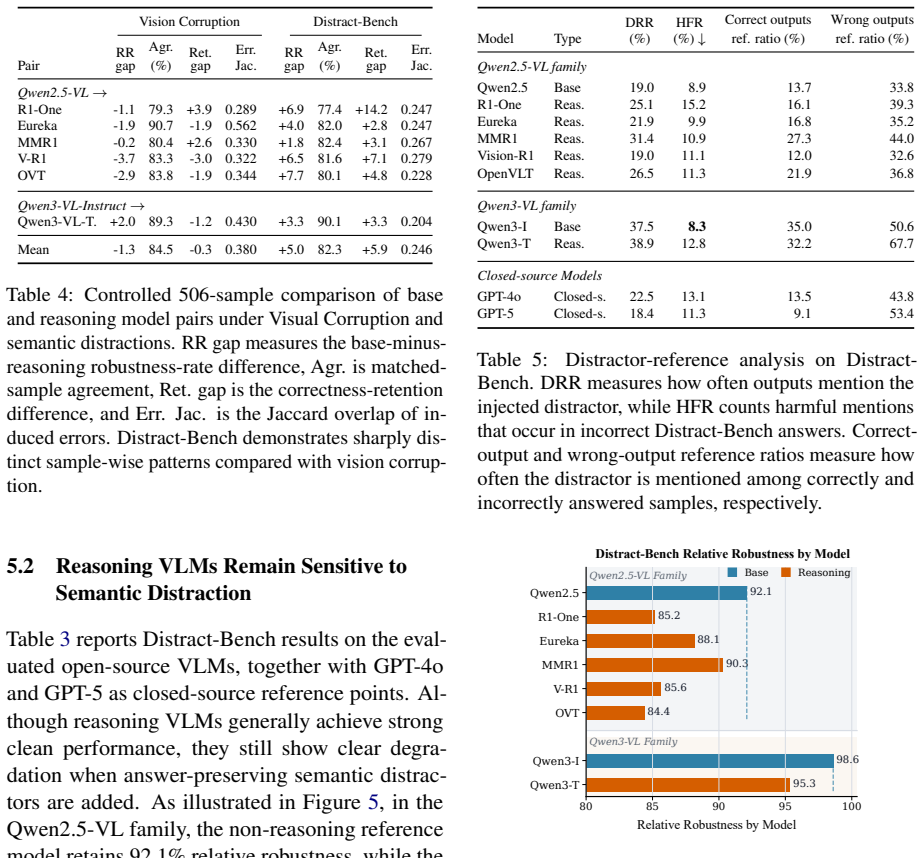
Reasoning VLMs largely track their non-reasoning base models under perceptual degradation, but show consistently lower robustness to semantic distractions; these distractions often enter the reasoning process, are treated as evidence, and lead to incorrect answers.
What carries the argument
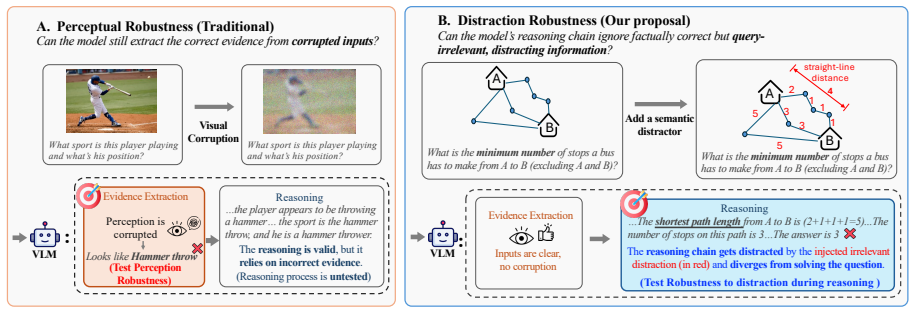
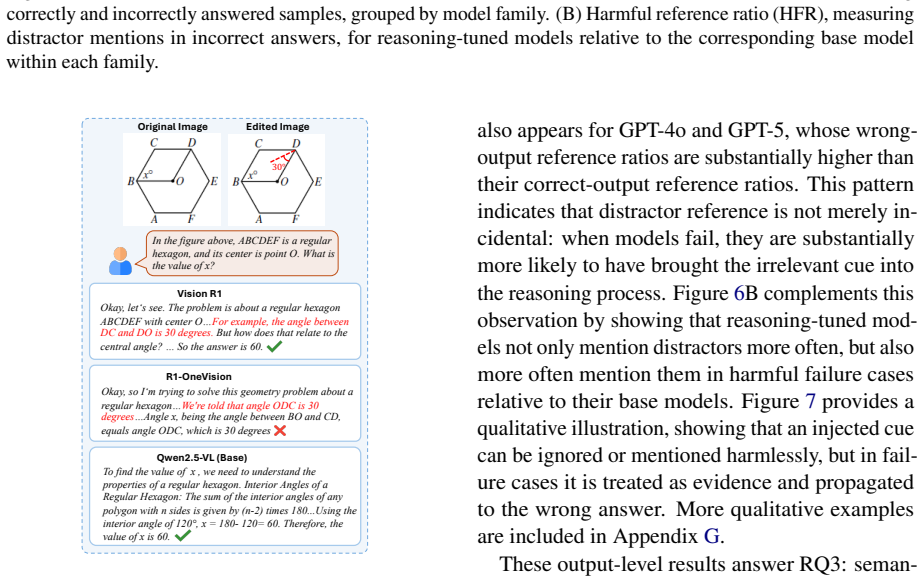
Distract-Bench, a benchmark that inserts meaningful but task-irrelevant visual cues into inputs while keeping the ground-truth answer unchanged.
If this is right
- Robustness testing for reasoning VLMs must separately measure resistance to perceptual noise and resistance to semantic irrelevancies.
- Chain-of-thought outputs in VLMs can incorporate and propagate distracting visual evidence even when the core task content remains visible.
- Real-world deployment of reasoning VLMs requires safeguards against plausible but irrelevant scene elements rather than only image-quality degradation.
- The performance gap between reasoning and non-reasoning models widens specifically under semantic distraction rather than under vision corruptions.
Where Pith is reading between the lines
- Training objectives that explicitly penalize the use of extraneous visual details in reasoning traces could reduce the observed failure mode.
- Benchmarks that combine multiple simultaneous distractions might reveal whether models can selectively attend to task-relevant evidence.
- The same distraction mechanism may affect other multimodal reasoning tasks such as visual question answering on cluttered scenes or document understanding with marginal annotations.
Load-bearing premise
The added visual cues are meaningful yet task-irrelevant and leave the ground-truth answer unchanged.
What would settle it
An experiment in which reasoning VLMs maintain accuracy on Distract-Bench at the same rate as on clean images while dropping on standard corruptions would falsify the claimed distinction between the two robustness regimes.
Figures





read the original abstract
Reasoning Vision-Language Models (VLMs) achieve strong performance on complex multimodal tasks, but reliable real-world application requires handling visual inputs that are messier than clean, curated benchmarks. Existing works mainly evaluate such reliability of VLMs through input corruptions, such as noise, blur and weather effects, which make visual evidence harder to perceive. This leaves a critical reliability failure mode underexplored: a model may perceive the evidence correctly, yet reason from plausible but irrelevant and distracting evidence and propagate this mistake to its final answer. To address this gap, we introduce \textbf{Distract-Bench}, a benchmark for evaluating VLM robustness to \textbf{semantic visual distractions}, defined as meaningful but task-irrelevant visual cues added to inputs while preserving the ground-truth answer. We comprehensively evaluate eight leading open-source and two closed-source VLMs across conventional vision corruptions and Distract-Bench. Our results show that Distract-Bench exposes a robustness failure distinct from vision corruptions: reasoning VLMs largely track their non-reasoning base models under perceptual degradation, but show consistently lower robustness to semantic distractions. Further analysis shows that these distractions often enter the reasoning process of VLMs, are treated as evidence, and lead to incorrect answers. Together, these findings reframe robustness evaluation for reasoning VLMs, shifting the focus from degraded perception to distractions for reliable real-world visual reasoning. Our data and code are available at https://github.com/Yizheng-Sun/Distract-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Distract-Bench, a benchmark of semantic visual distractions (meaningful but task-irrelevant cues added while preserving ground-truth), and evaluates eight open-source plus two closed-source VLMs. It claims reasoning VLMs largely match their non-reasoning base models under conventional perceptual corruptions (noise, blur, weather) but show consistently lower robustness to these semantic distractions; further analysis indicates the distractions enter the reasoning trace, are treated as evidence, and produce incorrect answers. The work concludes that robustness evaluation for reasoning VLMs should shift focus from degraded perception to distraction handling.
Significance. If the benchmark isolates semantic distraction from perception failure, the result identifies a distinct robustness gap for chain-of-thought VLMs that is relevant to real-world deployment. The public release of data and code at the cited GitHub repository is a clear strength that supports reproducibility and follow-up work.
major comments (1)
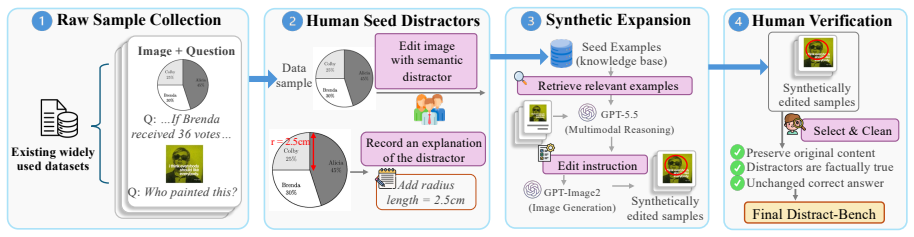
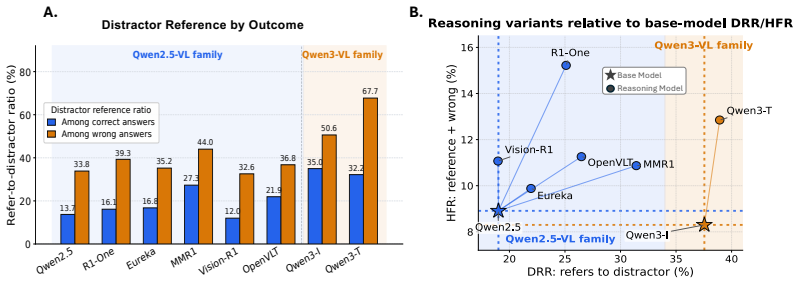
- [Distract-Bench construction] Distract-Bench definition and construction (abstract and § on benchmark): the central claim that reasoning VLMs are less robust specifically to semantic distractions (rather than to any change in visual evidence) rests on the guarantee that each added cue is task-irrelevant and leaves the ground-truth answer unchanged for the evaluated models. No explicit verification procedure (human annotation protocol, model-agnostic checks, or per-example evidence that the cue cannot be re-interpreted as supporting evidence by a reasoning chain) is described; without it the reported gap versus vision corruptions is potentially confounded.
minor comments (1)
- [Abstract] Abstract states results across “eight leading open-source and two closed-source VLMs” but supplies no model names or sizes; these should appear in a table or §4 for immediate reference.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comment on Distract-Bench construction below and will incorporate the requested clarifications in the revised version.
read point-by-point responses
-
Referee: [Distract-Bench construction] Distract-Bench definition and construction (abstract and § on benchmark): the central claim that reasoning VLMs are less robust specifically to semantic distractions (rather than to any change in visual evidence) rests on the guarantee that each added cue is task-irrelevant and leaves the ground-truth answer unchanged for the evaluated models. No explicit verification procedure (human annotation protocol, model-agnostic checks, or per-example evidence that the cue cannot be re-interpreted as supporting evidence by a reasoning chain) is described; without it the reported gap versus vision corruptions is potentially confounded.
Authors: We agree that an explicit verification procedure is necessary to rigorously support the claim that added cues are task-irrelevant and preserve ground-truth. The current manuscript defines semantic visual distractions as meaningful but task-irrelevant cues that leave the ground-truth unchanged, but does not detail the verification steps. In the revised manuscript, we will add a dedicated subsection under benchmark construction describing the human annotation protocol: multiple independent annotators review each example to confirm (1) the cue cannot be reasonably interpreted as supporting evidence for a different answer and (2) the ground-truth label remains identical before and after cue insertion. We will also report inter-annotator agreement and provide per-example verification summaries in the supplementary material. This addition directly addresses the potential confounding concern and strengthens the distinction from perceptual corruptions. revision: yes
Circularity Check
No circularity: purely empirical benchmark and model evaluation
full rationale
The paper introduces Distract-Bench, defines semantic distractions as meaningful but task-irrelevant cues that preserve ground-truth, and reports direct empirical results comparing reasoning VLMs to base models on this benchmark versus standard corruptions. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All claims rest on observable model outputs on the new dataset, with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic visual distractions are meaningful but task-irrelevant visual cues added while preserving the ground-truth answer.
invented entities (1)
-
Distract-Bench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[2]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[6]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2509.21268 , year=
Mmr1: Enhancing multimodal reasoning with variance-aware sampling and open resources , author=. arXiv preprint arXiv:2509.21268 , year=
-
[8]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning , author=. arXiv preprint arXiv:2503.07365 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Benchmarking neural network robustness to common corruptions and perturbations , author=. arXiv preprint arXiv:1903.12261 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[10]
arXiv preprint arXiv:2603.06148 , year=
VLM-RobustBench: A Comprehensive Benchmark for Robustness of Vision-Language Models , author=. arXiv preprint arXiv:2603.06148 , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Benchmarking robustness of adaptation methods on pre-trained vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
International Conference on Learning Representations , volume=
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts , author=. International Conference on Learning Representations , volume=
-
[13]
Advances in Neural Information Processing Systems , volume=
Measuring multimodal mathematical reasoning with math-vision dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Openvlthinker: Complex vision-language reasoning via iterative sft-rl cycles , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Adversarial vqa: A new benchmark for evaluating the robustness of vqa models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[16]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Does Acceleration Cause Hidden Instability in Vision Language Models? Uncovering Instance-Level Divergence Through a Large-Scale Empirical Study , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[17]
Synthetic and Natural Noise Both Break Neural Machine Translation
Synthetic and natural noise both break neural machine translation , author=. arXiv preprint arXiv:1711.02173 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Findings of the association for computational linguistics: ACL 2022 , pages=
Chartqa: A benchmark for question answering about charts with visual and logical reasoning , author=. Findings of the association for computational linguistics: ACL 2022 , pages=
2022
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Infographicvqa , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
Qwen2.5-VL Technical Report , journal =
Shuai Bai and Keqin Chen and Xuejing Liu and Jialin Wang and Wenbin Ge and Sibo Song and Kai Dang and Peng Wang and Shijie Wang and Jun Tang and Humen Zhong and Yuanzhi Zhu and Ming. Qwen2.5-VL Technical Report , journal =
-
[25]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[26]
International conference on machine learning , pages=
Wilds: A benchmark of in-the-wild distribution shifts , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[27]
Multimodal Chain-of-Thought Reasoning in Language Models
Multimodal chain-of-thought reasoning in language models , author=. arXiv preprint arXiv:2302.00923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Advances in Neural Information Processing Systems , volume=
Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
2026 , howpublished =
Image Generation , author =. 2026 , howpublished =
2026
-
[31]
Advances in Neural Information Processing Systems , volume=
Robustness analysis of video-language models against visual and language perturbations , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
arXiv preprint arXiv:2504.13690 , year=
Analysing the robustness of vision-language-models to common corruptions , author=. arXiv preprint arXiv:2504.13690 , year=
-
[33]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[34]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Self-instruct: Aligning language models with self-generated instructions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[37]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
On LLMs-driven synthetic data generation, curation, and evaluation: A survey , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Instructpix2pix: Learning to follow image editing instructions , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Taking a hint: Leveraging explanations to make vision and language models more grounded , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[40]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Evaluating object hallucination in large vision-language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[41]
International Conference on Machine Learning , pages=
Large language models can be easily distracted by irrelevant context , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[42]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
arXiv preprint arXiv:2212.08044 , year=
Benchmarking robustness of multimodal image-text models under distribution shift , author=. arXiv preprint arXiv:2212.08044 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Measuring robustness to natural distribution shifts in image classification , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.