Statistical Guarantees in the Search for Less Discriminatory Algorithms
Pith reviewed 2026-05-21 16:21 UTC · model grok-4.3
The pith
An adaptive stopping algorithm supplies high-probability bounds showing when further retraining is unlikely to produce meaningfully less discriminatory models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
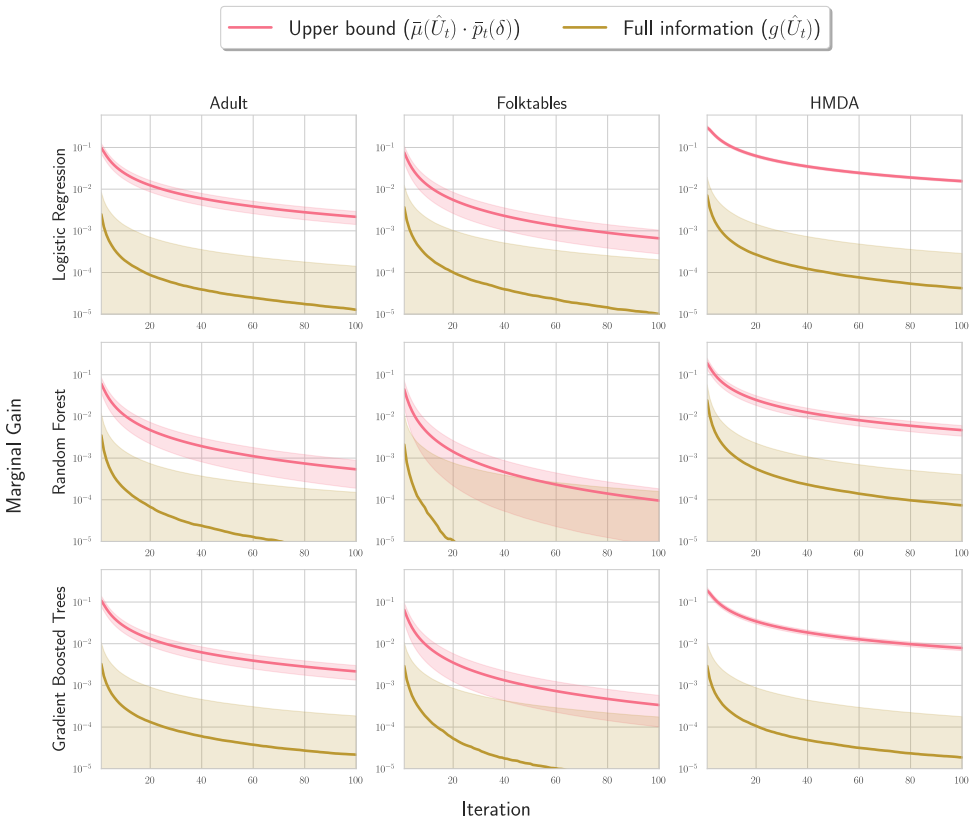
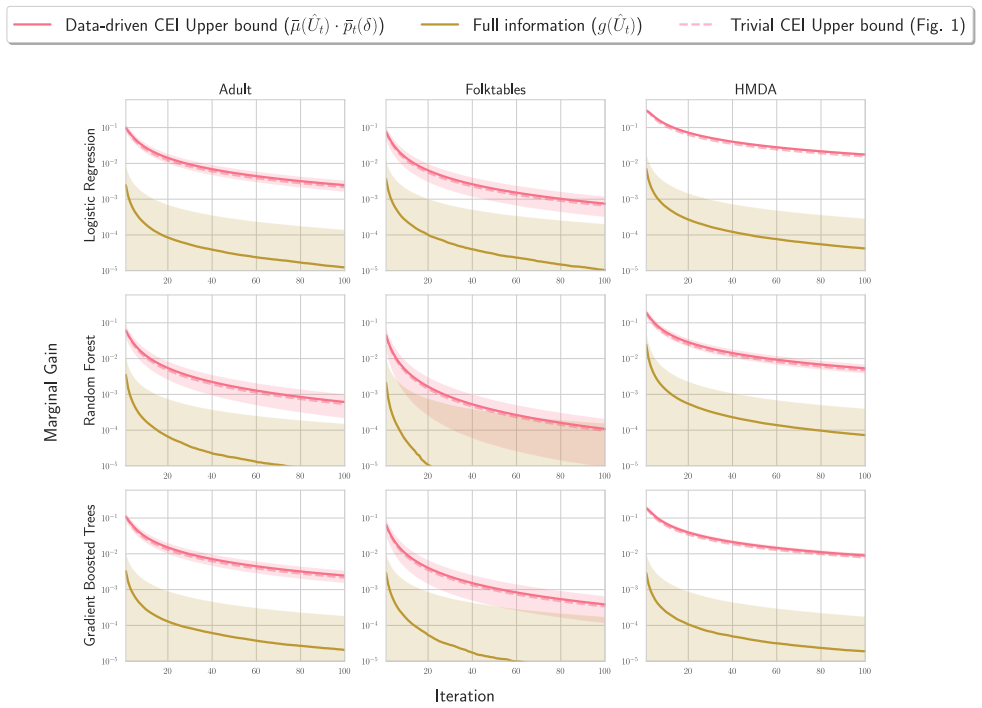
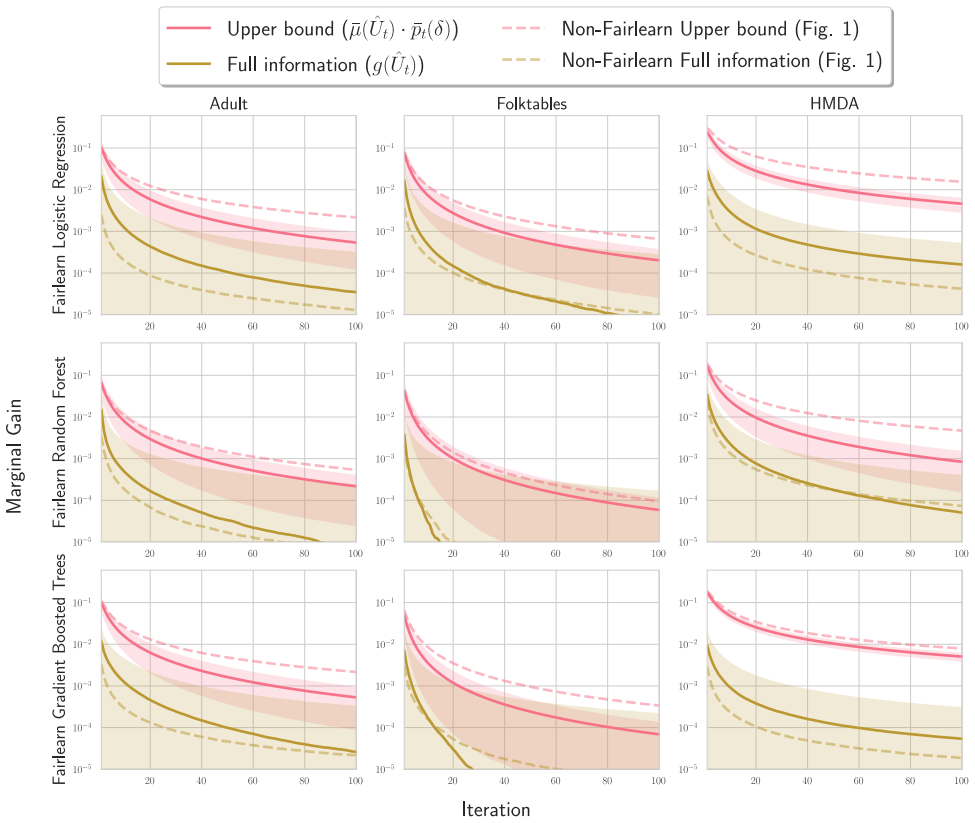
We formalize LDA search under model multiplicity as an optimal stopping problem and present an adaptive stopping algorithm that returns a high-probability upper bound on the best disparate-impact gains still attainable by continued retraining, allowing developers to certify that further search is unlikely to help.
What carries the argument
Adaptive stopping algorithm that produces a high-probability upper bound on remaining disparate-impact improvement attainable through further retraining.
If this is right
- Developers can produce evidence for regulators or courts that additional retraining is unlikely to yield meaningful fairness gains.
- Tighter bounds become available when stronger distributional assumptions are imposed on the space of possible models.
- The same stopping logic applies to real-world credit and housing datasets without requiring exhaustive search.
Where Pith is reading between the lines
- The approach could be adapted to other fairness metrics such as equalized odds by replacing the disparate-impact objective.
- Firms might integrate the bound into routine model-selection pipelines to limit compute spent on bias audits.
- The method highlights that model multiplicity can be turned into a statistical resource rather than an exhaustive enumeration problem.
Load-bearing premise
Models obtained by retraining with different random seeds can be treated as draws from a distribution that permits concentration inequalities or other probabilistic bounds on future improvement.
What would settle it
Run the stopping algorithm on a dataset where the true minimum attainable disparate impact across all possible retrainings is known in advance and check whether the reported upper bound is ever violated.
Figures
read the original abstract
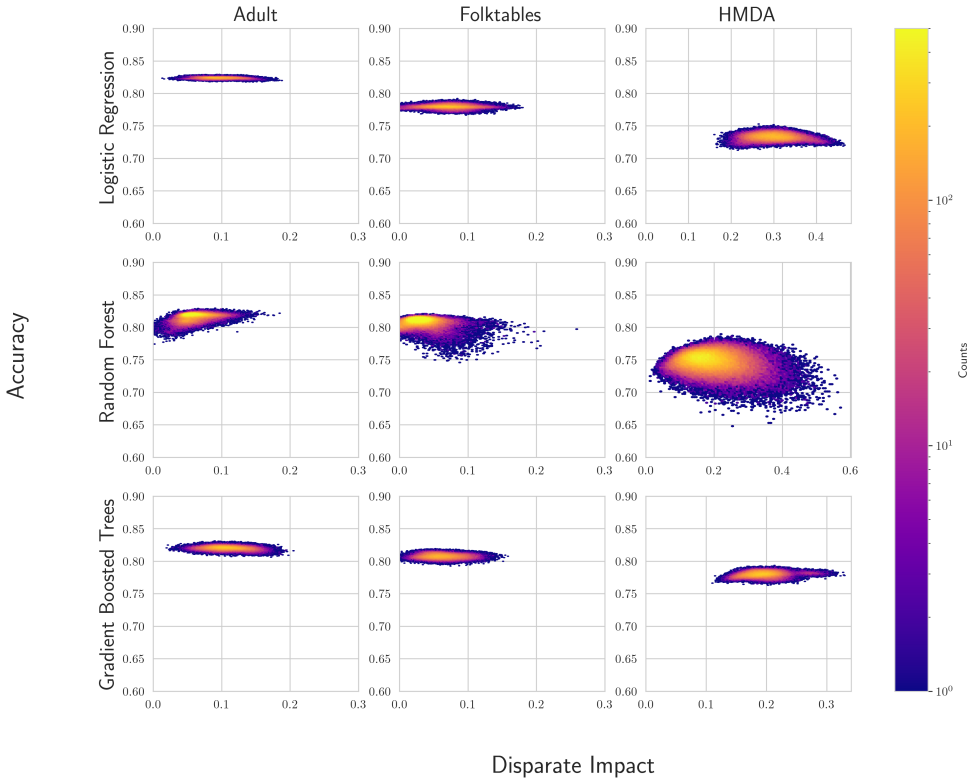
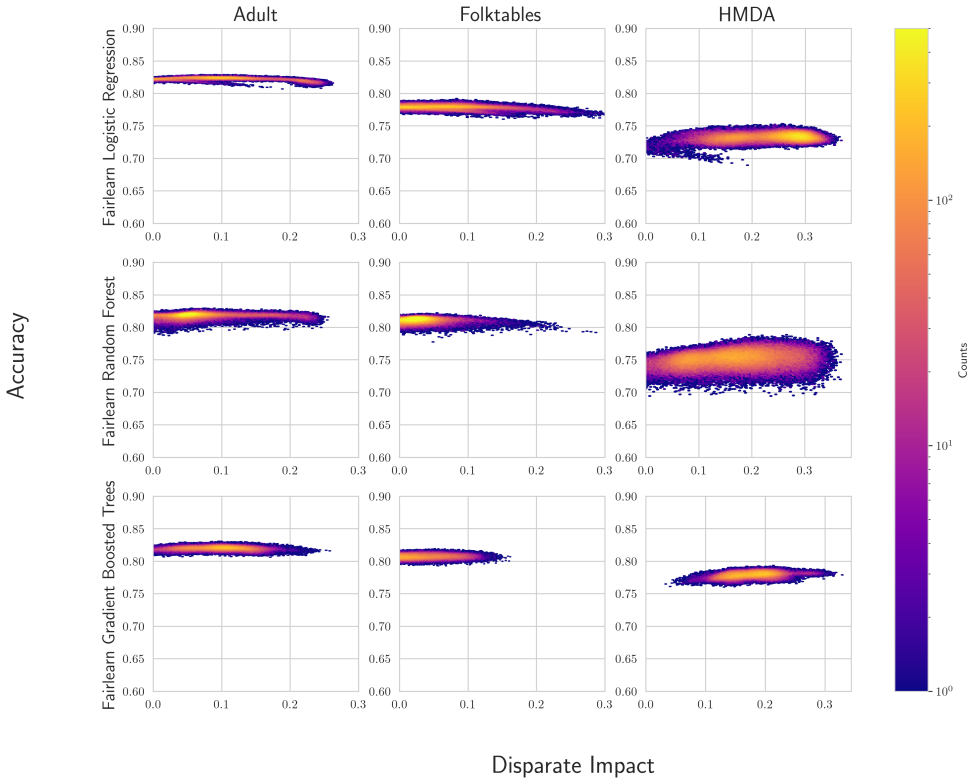
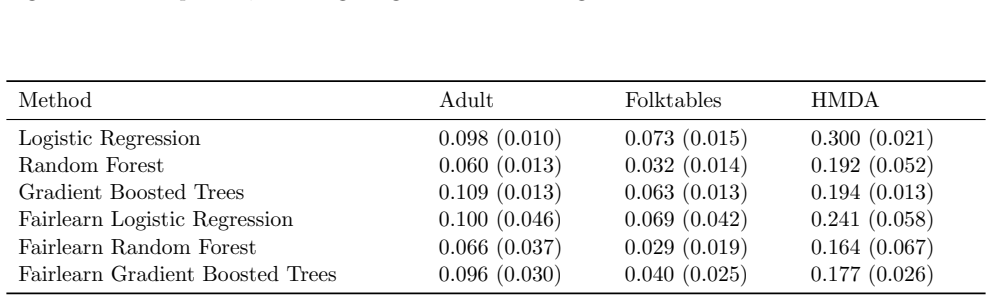
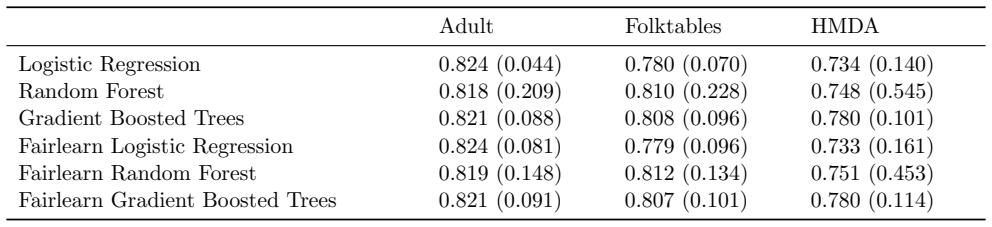
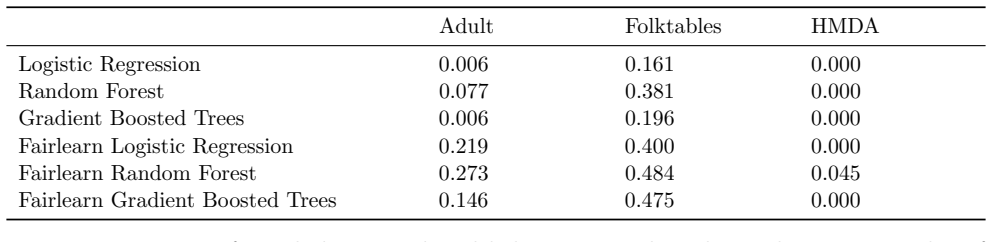
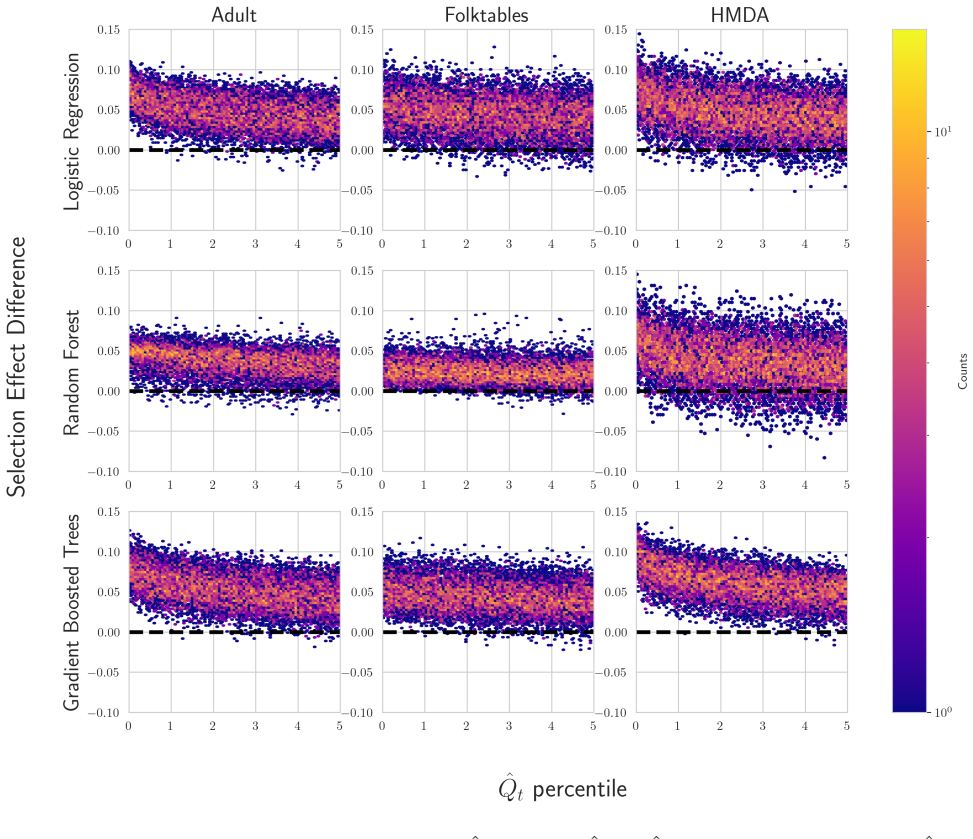
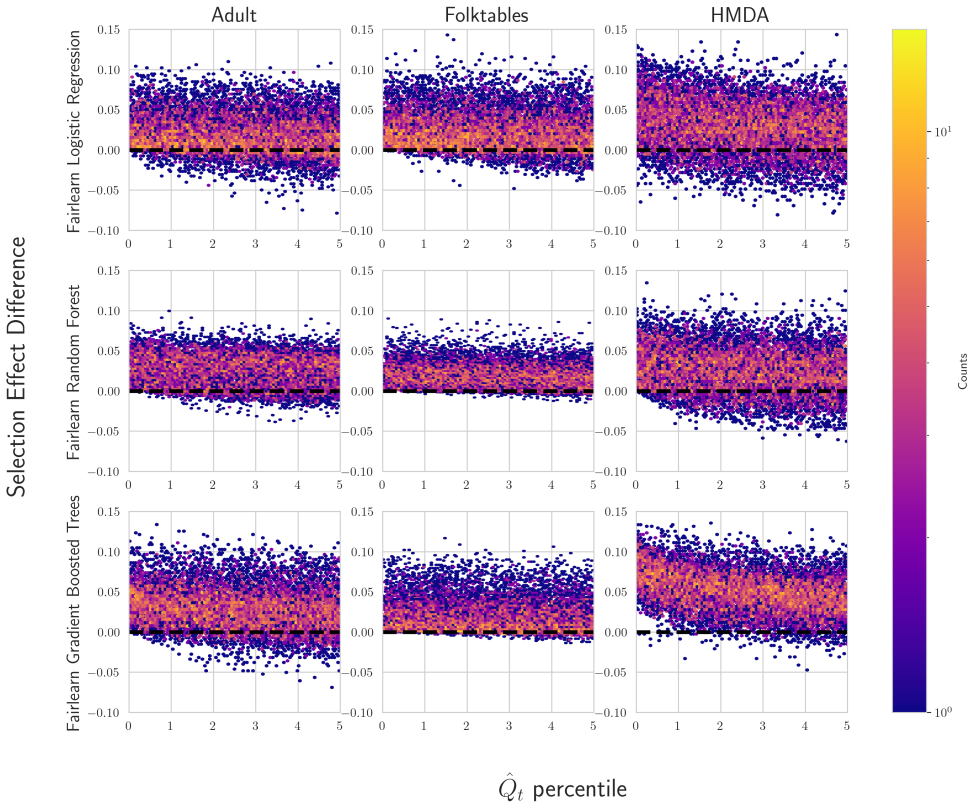
U.S. discrimination law can impose liability on firms that fail to adopt a less discriminatory alternative (LDA): a decision policy that achieves the same business objectives while reducing disparate impact on legally protected groups. Recent scholarship argues that this doctrine has direct implications for algorithmic decision-making in high-stakes domains such as employment, lending, and housing, potentially obligating firms to search for "less discriminatory algorithms" (Black et al., 2024). Regulators have at times encouraged proactive LDA searches, reinforcing the expectation of a good-faith effort to identify equally performant models with lower disparate impact. Model multiplicity makes such searches plausible: retraining with different random seeds can yield models with comparable predictive performance but materially different disparate impacts. Yet firms cannot retrain indefinitely, raising a central question: when is the search sufficient to demonstrate good faith? We formalize LDA search under multiplicity as an optimal stopping problem in which a developer seeks to produce evidence that further search is unlikely to yield meaningful improvements. Our main contribution is an adaptive stopping algorithm that provides a high-probability upper bound on the best disparate-impact gains attainable through continued retraining, enabling developers to certify (e.g., to a court) that additional search is unlikely to help. We also show how stronger distributional assumptions over the model space can yield tighter bounds, and we validate the approach on real-world credit and housing datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the search for less discriminatory algorithms (LDAs) as an optimal stopping problem under model multiplicity, where retraining with different random seeds can produce models with similar performance but varying disparate impact. The main contribution is an adaptive stopping algorithm that supplies a high-probability upper bound on the best attainable disparate-impact gains from further retraining, allowing developers to certify that additional search is unlikely to yield meaningful improvements. Stronger distributional assumptions over the model space are shown to yield tighter bounds, and the method is validated on credit and housing datasets.
Significance. If the probabilistic bounds are correctly derived, the work offers a timely statistical framework for demonstrating good-faith LDA searches in domains governed by U.S. discrimination law. It connects optimal stopping theory to algorithmic fairness and provides a practical certification tool for firms. The real-data validation on credit and housing datasets is a positive feature that grounds the claims, though the result's utility depends on the defensibility of treating random-seed retrainings as samples from a distribution amenable to concentration inequalities.
major comments (2)
- [Abstract and optimal stopping formulation] Abstract, paragraph on optimal stopping formulation: the high-probability upper bound on remaining disparate-impact gains is derived by treating the sequence of models from different random seeds as draws from a (possibly unknown) distribution permitting concentration inequalities. This modeling choice is load-bearing for the guarantee yet receives only brief mention; the manuscript must explicitly state the minimal assumptions (e.g., exchangeability or i.i.d.), derive the specific tail bound used, and include a sensitivity analysis showing how bound validity degrades under plausible misspecification.
- [Adaptive stopping algorithm] Section describing the adaptive stopping algorithm and bound computation: no explicit concentration inequality or step-by-step derivation of how the observed sequence of disparate-impact values is turned into the reported high-probability upper bound appears in the provided description. Without this, the central claim that the algorithm 'certifies that additional search is unlikely to help' cannot be evaluated for correctness.
minor comments (1)
- [Notation and definitions] Clarify notation for 'disparate-impact gains' versus raw disparate impact; ensure the stopping criterion is defined with an explicit equation rather than prose only.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight opportunities to improve the clarity of our statistical derivations and assumptions, which we have addressed through targeted revisions. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and optimal stopping formulation] Abstract, paragraph on optimal stopping formulation: the high-probability upper bound on remaining disparate-impact gains is derived by treating the sequence of models from different random seeds as draws from a (possibly unknown) distribution permitting concentration inequalities. This modeling choice is load-bearing for the guarantee yet receives only brief mention; the manuscript must explicitly state the minimal assumptions (e.g., exchangeability or i.i.d.), derive the specific tail bound used, and include a sensitivity analysis showing how bound validity degrades under plausible misspecification.
Authors: We agree that greater explicitness on the modeling assumptions will strengthen the paper. In the revised manuscript we have expanded the optimal stopping formulation section to state the minimal assumptions: the sequence of disparate-impact values obtained from random-seed retrainings is treated as exchangeable (hence amenable to concentration via de Finetti-type representations), with the i.i.d. case as a leading special case. We now derive the bound explicitly from Hoeffding’s inequality applied to the empirical maximum, and we have added an appendix containing a sensitivity analysis that quantifies bound degradation under controlled violations such as mild dependence or heavier tails. revision: yes
-
Referee: [Adaptive stopping algorithm] Section describing the adaptive stopping algorithm and bound computation: no explicit concentration inequality or step-by-step derivation of how the observed sequence of disparate-impact values is turned into the reported high-probability upper bound appears in the provided description. Without this, the central claim that the algorithm 'certifies that additional search is unlikely to help' cannot be evaluated for correctness.
Authors: We appreciate the referee’s call for a clearer derivation. Although the original manuscript contained the core steps, they were not presented with sufficient detail or separation. The revised Section 3 now includes a dedicated subsection that (i) states the observed sequence, (ii) recalls the relevant concentration inequality, (iii) shows the algebraic steps converting the empirical maximum into a high-probability upper bound on the attainable improvement, and (iv) presents the resulting adaptive stopping rule in both mathematical and algorithmic form. We believe this makes the certification claim fully evaluable. revision: yes
Circularity Check
No circularity: bound derived from external concentration inequalities on assumed model distribution
full rationale
The paper's central derivation formalizes LDA search as an optimal stopping problem and constructs a high-probability upper bound on remaining disparate-impact gains by applying concentration inequalities to the sequence of retrained models, which are modeled as draws from a (possibly unknown) distribution over model space. This modeling choice and the resulting tail bounds are external probabilistic machinery rather than a self-referential fit or definition; the bound is not shown to reduce by the paper's own equations to a quantity defined in terms of the same stopping data. No self-citation chains, ansatzes smuggled via prior work, or renaming of known results appear load-bearing in the abstract or described contribution. The approach remains self-contained against external benchmarks once the distributional assumption is granted.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Models obtained by retraining with different random seeds behave as draws from a distribution permitting high-probability bounds on remaining disparate-impact improvement.
Reference graph
Works this paper leans on
-
[1]
For HMDA, we use the cleaned dataset given in Cooper et al
The prediction target is whether the individual is employed. For HMDA, we use the cleaned dataset given in Cooper et al. (2024) for New York in 2017. The prediction target is whether the home mortgage was originated. Across all datasets, the reference group is all individuals designated White and the protected group is all individuals not designated White...
work page 2024
-
[2]
First, show that it suffices to consider the case where theXt are uniform on [0,1] via the probability integral transform
-
[3]
Then, we show that it suffices to provide an anytime-valid upper bound on the running minimum of the sequence
-
[4]
Finally, we show that ¯pt as defined above yields such a bound. We begin by using the probability integral transform to “convert” ourX t’s into uniform random vari- ables. LetF X be the CDF ofX t. Define F −1 X (u) = inf{x:F X(x)≥u}. Let{U t}∞ t=1 be iid uniform random variables on [0,1], defined onP. LetV t = min s∈[t] Us. Then, it holds, by e.g. Ch. 6, ...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.