SPATIOROUTE: Dynamic Prompt Routing for Zero-Shot Spatial Reasoning
Pith reviewed 2026-05-20 11:02 UTC · model grok-4.3
The pith
SpatioRoute routes questions to tailored prompts to lift zero-shot spatial video reasoning by up to 5 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
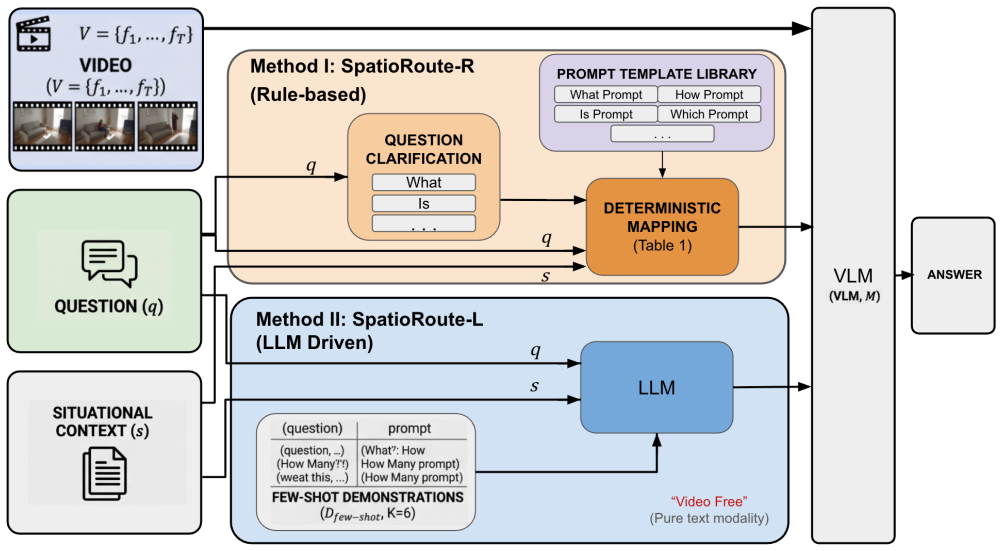
SpatioRoute is a prompt-generation system that routes each incoming question to a semantically matched template without training, fine-tuning, or 3D input. In its rule-based mode it maps typologies such as What, Is, How, Can, and Which to distinct templates; in its LLM mode it generates a task-specific prompt from the question and situational context alone. Evaluated on SQA3D, the approach yields consistent accuracy gains up to 5 percent over fixed-prompt baselines and sets a new state of the art for zero-shot video-only spatial visual question answering.
What carries the argument
A question router that deterministically or generatively selects a specialized prompt template from the question text and context without access to the video.
If this is right
- Question-aware routing outperforms a single fixed prompt for spatial video tasks.
- Rule-based typology mapping provides deterministic gains without extra model calls.
- LLM-driven prompt generation works using only the question and context, with no video required.
- Chain-of-thought prompting reduces accuracy on Qwen-series models for this task.
- The gains hold across multiple VLM families without 3D sensors or fine-tuning.
Where Pith is reading between the lines
- The same typology-based router could be tested on other reasoning domains by swapping the prompt templates.
- Combining the router with lightweight adapters might compound the zero-shot gains.
- If the routing decision proves stable across datasets, it could reduce the need for task-specific fine-tuning in egocentric video systems.
Load-bearing premise
That question typologies or content can be mapped to prompt templates that reliably improve spatial reasoning performance even when the router never sees the video.
What would settle it
Running the same router on a non-spatial VQA benchmark and finding no accuracy gain, or finding that the single best fixed template matches SpatioRoute performance on SQA3D.
Figures

read the original abstract
Spatial question answering over egocentric video is a challenging task that requires Vision-Language Models (VLMs) to reason about 3D object positions, scene affordances, and directional relationships, particularly in the zero-shot setting where no task-specific fine-tuning is available. We introduce SpatioRoute, a dynamic prompt generation approach that routes each incoming question to a semantically tailored prompt template -- without any additional training, fine-tuning, or 3D sensor input. SpatioRoute operates in two complementary modes: SpatioRoute-R, a rule-based router that deterministically maps question typologies (e.g., What, Is, How, Can, Which) to specialized prompt templates; and SpatioRoute-L, an LLM-driven approach that generates task-specific prompts from the question and situational context alone, with no video input at routing time. We evaluate SpatioRoute on the SQA3D benchmark across VLMs spanning model families. SpatioRoute achieves consistent overall accuracy gains up to 5% over fixed prompt baselines, establishing a new state-of-the-art for zero-shot video-only spatial VQA without requiring 3D point-cloud inputs. As an additional finding, we observe that Chain-of-Thought (CoT) prompting, implemented via the Think it Twice architecture, consistently degrades performance in this setting on Qwen series models, confirming that question-aware routing is more effective than uniform reasoning instructions for spatial video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpatioRoute, a dynamic prompt routing method for zero-shot spatial visual question answering on egocentric videos with VLMs. SpatioRoute-R is a rule-based router that maps question typologies (e.g., What, Is, How, Can, Which) to specialized prompt templates. SpatioRoute-L is an LLM-driven router that generates task-specific prompts from the question and situational context alone, without video input at routing time. Evaluated on the SQA3D benchmark, the method reports consistent accuracy gains of up to 5% over fixed prompt baselines across model families and claims a new state-of-the-art for zero-shot video-only spatial VQA without 3D point-cloud inputs. It additionally observes that Chain-of-Thought prompting via the Think it Twice architecture degrades performance on Qwen-series models.
Significance. If the reported gains are robust, this work offers a practical, training-free technique to improve spatial reasoning in VLMs for video inputs by tailoring prompts to question characteristics rather than using uniform strategies. It provides empirical support for question-aware routing over generic CoT in spatial video tasks and demonstrates gains without 3D sensors or fine-tuning, which could inform prompt design in multimodal and robotics applications.
major comments (2)
- [§4 (Experiments)] §4 (Experiments): The results report accuracy gains up to 5% and a new SOTA but provide no details on statistical significance, error bars, exact baseline implementations, or data splits used on SQA3D. This is load-bearing for the central empirical claim of consistent improvements.
- [§3 (Method)] §3 (Method): Both SpatioRoute-R and SpatioRoute-L perform routing without access to video frames or 3D cues, relying solely on question typology or situational context. The paper should explicitly discuss the risk that scene-specific spatial relations (e.g., occlusions or affordances) may require different templates, as this assumption is central to the zero-shot video-only SOTA claim.
minor comments (1)
- [Abstract] Abstract: The phrase 'Think it Twice architecture' for CoT is used without a citation or brief definition, which reduces clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We address each major comment below and have prepared revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: §4 (Experiments): The results report accuracy gains up to 5% and a new SOTA but provide no details on statistical significance, error bars, exact baseline implementations, or data splits used on SQA3D. This is load-bearing for the central empirical claim of consistent improvements.
Authors: We agree that additional experimental details are necessary to fully support the empirical claims. In the revised manuscript, we will expand Section 4 to include: (1) error bars or standard deviations computed across multiple inference runs with different random seeds where feasible; (2) explicit descriptions of the fixed-prompt baseline implementations, including the exact template text used for each comparison; and (3) confirmation that all evaluations follow the official SQA3D data splits and evaluation protocol from the benchmark authors. While we did not originally report formal statistical significance tests due to space constraints, we will add a brief analysis noting the consistency of gains across model families and include confidence intervals. These changes will be made without altering the reported accuracy numbers. revision: yes
-
Referee: §3 (Method): Both SpatioRoute-R and SpatioRoute-L perform routing without access to video frames or 3D cues, relying solely on question typology or situational context. The paper should explicitly discuss the risk that scene-specific spatial relations (e.g., occlusions or affordances) may require different templates, as this assumption is central to the zero-shot video-only SOTA claim.
Authors: We thank the referee for highlighting this important assumption. While our method deliberately avoids video input at routing time to maintain a purely zero-shot, training-free pipeline, we acknowledge the potential limitation that certain scene-specific factors (such as heavy occlusions or nuanced affordances) could in principle benefit from visual feedback for template selection. In the revised Section 3, we will add a dedicated paragraph discussing this risk, noting that our empirical results on SQA3D demonstrate robust performance under the current assumption, but that future extensions could incorporate optional visual features for hybrid routing in more complex scenes. This addition will explicitly qualify the scope of the zero-shot video-only SOTA claim. revision: yes
Circularity Check
No circularity: purely empirical benchmark comparisons
full rationale
The paper reports accuracy gains from rule-based and LLM-driven prompt routing on the SQA3D benchmark using fixed prompt baselines as controls. No equations, derivations, fitted parameters, or self-citation chains appear in the described methodology or results. Claims rest on direct measurement of performance differences rather than any reduction of outputs to inputs by construction, making the evaluation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs respond differently to prompt templates based on question typology in zero-shot spatial video tasks
Reference graph
Works this paper leans on
-
[1]
Md Rabiul Awal, Hanxue Jiang, Yifan Peng, et al. Inves- tigating prompting techniques for zero- and few-shot visual question answering.arXiv preprint arXiv:2306.09996, 2023
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
SpatialVLM: En- dowing vision-language models with spatial reasoning capa- bilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. SpatialVLM: En- dowing vision-language models with spatial reasoning capa- bilities. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14455–14465, 2024
work page 2024
-
[5]
Jiaxin Chen et al. Enhancing spatial reasoning in vision- language models via chain-of-thought prompting and rein- forcement learning.arXiv preprint arXiv:2507.13362, 2025
-
[6]
Spatial- RGPT: Grounded spatial reasoning in vision-language mod- els
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Rui- han Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatial- RGPT: Grounded spatial reasoning in vision-language mod- els. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[7]
Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scan- Net: Richly-annotated 3D reconstructions of indoor scenes. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[8]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Video-of-thought: Step-by-step video reasoning from perception to cognition
Hao Fei, Shengqiong Wu, Wei Ji, Hanwang Zhang, Meishan Zhang, Mong-Li Lee, and Wynne Hsu. Video-of-thought: Step-by-step video reasoning from perception to cognition. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[10]
Jiaxian Guo, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Boyang Li, Dacheng Tao, and Steven Hoi. From im- ages to textual prompts: Zero-shot visual question answering with frozen large language models. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[11]
3D-LLM: In- jecting the 3D world into large language models
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3D-LLM: In- jecting the 3D world into large language models. InAd- vances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[12]
Zero-shot 3D question answering via voxel-based dynamic token compression
Chenming Huang et al. Zero-shot 3D question answering via voxel-based dynamic token compression. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[13]
Chat- scene: Bridging 3D scene and large language models with object identifiers
Haifeng Huang, Zehan Wang, Rongjie Huang, Luping Liu, Xize Cheng, Yang Zhao, Tao Jin, and Zhou Zhao. Chat- scene: Bridging 3D scene and large language models with object identifiers. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2024
work page 2024
-
[14]
An embodied generalist agent in 3D world
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3D world. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[15]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), pages 22199–22213, 2022
work page 2022
-
[16]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Vision-language memory for spatial reasoning
Zuntao Liu, Yi Du, Taimeng Fu, Shaoshu Su, Cherie Ho, and Chen Wang. Vision-language memory for spatial reasoning. arXiv preprint arXiv:2511.20644, 2025
-
[18]
SQA3D: Situ- ated question answering in 3D scenes
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. SQA3D: Situ- ated question answering in 3D scenes. InInternational Con- ference on Learning Representations (ICLR), 2023
work page 2023
-
[19]
Compositional chain-of-thought prompting for large multimodal models
Chancharik Mitra, Brandon Huang, Trevor Darrell, and Roei Herzig. Compositional chain-of-thought prompting for large multimodal models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[20]
Ruizhe Quan et al. When more is less: A systematic analysis of spatial and commonsense information for visual spatial reasoning.arXiv preprint arXiv:2602.21619, 2025
-
[21]
Shun Taguchi et al. SpatialPrompting: Keyframe-driven zero-shot spatial reasoning with off-the-shelf multimodal large language models.arXiv preprint arXiv:2505.04911, 2025
-
[22]
Xiaoyu Tian, Sitong Zhao, Haotian Wang, Shuaiting Chen, Yunjie Ji, Yiping Peng, Han Zhao, and Xiangang Li. Think twice: Enhancing LLM reasoning by scaling multi-round test-time thinking.arXiv preprint arXiv:2503.19855, 2025
-
[23]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompt- ing. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[24]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learn- ing Representations (ICLR), 2023
work page 2023
-
[26]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), pages 24824–24837, 2022
work page 2022
-
[27]
Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and re- call spaces. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10632–10643, 2025. Oral Presentation
work page 2025
-
[28]
Multi-modal situated reasoning in 3D scenes
Xiongkun Yang et al. Multi-modal situated reasoning in 3D scenes. InAdvances in Neural Information Processing Sys- tems (NeurIPS), 2024
work page 2024
-
[29]
Video-3D LLM: Learning position-aware video representation for 3D scene understanding
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3D LLM: Learning position-aware video representation for 3D scene understanding. InIEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2025
work page 2025
-
[30]
Large lan- guage models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large lan- guage models are human-level prompt engineers. InInter- national Conference on Learning Representations (ICLR), 2023
work page 2023
-
[31]
LLaV A-3D: A simple yet effective pathway to empowering LMMs with 3D-awareness
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. LLaV A-3D: A simple yet effective pathway to empowering LMMs with 3D-awareness. InInternational Conference on Computer Vision (ICCV), 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.