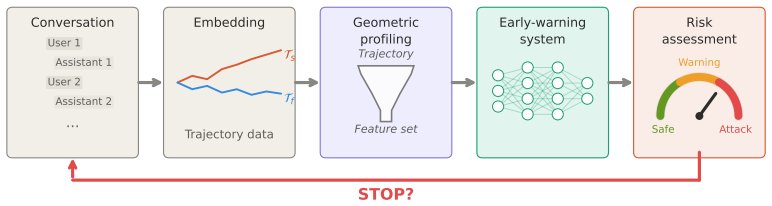
PsychoPass: Geometric Profiling of Multi-Turn Adversarial LLM Conversations
Pith reviewed 2026-06-28 09:54 UTC · model grok-4.3
The pith
Adversarial multi-turn LLM conversations carry an early geometric fingerprint in embedding space that survives length correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Conversations are represented as paths in embedding space; adversarial trajectories exhibit geometric properties that encode intent after length is factored out, remain detectable from short prefixes, and are largely invariant to encoder choice.
What carries the argument
Conversation trajectories modeled as paths in embedding space, with geometric features extracted after explicit length-shape decomposition.
If this is right
- Guardrails can monitor conversation dynamics in real time rather than inspecting individual turns.
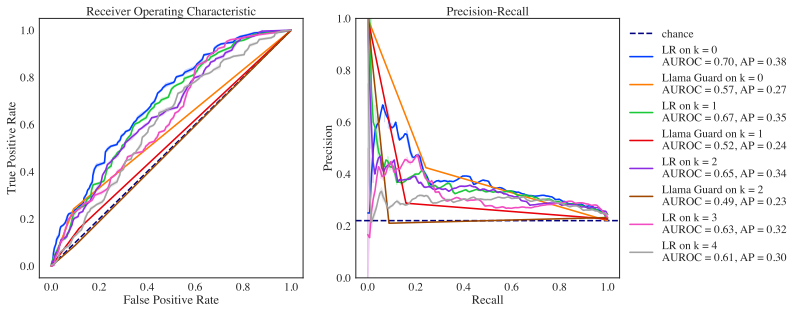
- Detection remains possible from the first few turns, before harmful output is generated.
- The geometric signal is robust across different embedding models.
- Theoretical bounds relate minimum prefix length to reliable detection probability.
Where Pith is reading between the lines
- The same trajectory geometry could be tested on other gradual intent shifts such as persuasion or deception beyond jailbreaks.
- Layering the geometric monitor with existing content filters would create a two-stage defense that acts on dynamics first.
- Deployment would require checking whether the signal persists when conversations span multiple unrelated topics.
Load-bearing premise
The residual geometric signal after removing the number-of-turns confound genuinely reflects adversarial intent rather than other unmeasured properties such as topic or user style.
What would settle it
A controlled experiment in which non-adversarial conversations matched for topic, length, and style produce the same geometric features as adversarial ones, driving classifier accuracy to chance.
Figures
read the original abstract
Multi-turn jailbreak attacks on large language models (LLMs) reveal a mismatch in current guardrails: they operate on individual turns, while attacks unfold as trajectories across conversations. We propose a shift from content to dynamics, modeling conversations as paths in representation space and asking whether adversarial intent is encoded early in their geometry. We introduce PsychoPass, a framework that extracts geometric features from conversation trajectories in embedding space to predict a potential attack before harmful content is produced. These features achieve near-perfect performance in na\"ive classifiers, which is largely explained by the inclusion of number of turns as a feature. After removing this confound, a smaller but consistent geometric signal remains, with classification performance that does not depend meaningfully on encoder choice. Crucially, this signal appears early in the conversation: attack outcomes remain above chance from short prefixes alone, more reliably than baseline guardrails. A supporting theoretical analysis explains these findings via a decomposition of length and shape, a detection bound based on prefix length, and encoder invariance. Together, these results show that adversarial conversations leave an early, representation-robust geometric fingerprint suitable for online monitoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multi-turn jailbreak attacks leave an early geometric fingerprint in LLM conversation trajectories in embedding space. Naive classifiers achieve near-perfect accuracy largely from the scalar feature of turn count, but after removing this confound a smaller consistent geometric signal remains whose performance is independent of encoder choice; this signal appears in short prefixes and outperforms baseline guardrails. A supporting theoretical analysis decomposes trajectories into length and shape, derives a prefix-length detection bound, and establishes encoder invariance, supporting the conclusion that adversarial conversations produce a representation-robust geometric signal suitable for online monitoring.
Significance. If the residual geometric signal after turn-count removal can be shown to encode adversarial intent rather than topic or style confounds, the work would offer a novel shift from per-turn content-based guardrails to trajectory dynamics, with potential for early detection before harmful output. The claimed encoder invariance and theoretical decomposition of length versus shape would be notable strengths if rigorously established; the early-prefix result would be practically relevant for online monitoring if the signal is not an artifact of unmeasured covariates.
major comments (2)
- [Abstract / §4] Abstract and experimental sections: the procedure for removing the number-of-turns confound is not described (no equation, algorithm, or statistical test is given for isolating the residual geometric signal), nor is dataset construction detailed to ensure adversarial and benign trajectories are matched on topic or user style. This is load-bearing for the central claim that a consistent geometric signal remains after confound removal.
- [Theoretical Analysis] Theoretical analysis: the decomposition into length and shape, the prefix-length detection bound, and the encoder-invariance argument address only the turns confound and representation choice; they contain no argument or test showing that the residual geometry is independent of topic or phrasing differences that systematically distinguish jailbreak prompts from benign conversations.
minor comments (2)
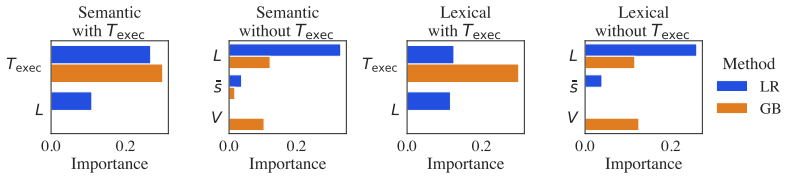
- [§3] Notation for geometric features (e.g., path curvature or embedding distances) should be defined explicitly with reference to the embedding model and distance metric used.
- [Abstract / Results] The abstract states performance 'does not depend meaningfully on encoder choice' but provides no quantitative comparison (e.g., accuracy deltas or statistical test) across encoders; a table or figure would clarify this.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our presentation and analysis. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and experimental sections: the procedure for removing the number-of-turns confound is not described (no equation, algorithm, or statistical test is given for isolating the residual geometric signal), nor is dataset construction detailed to ensure adversarial and benign trajectories are matched on topic or user style. This is load-bearing for the central claim that a consistent geometric signal remains after confound removal.
Authors: We agree that the confound-removal procedure requires an explicit description. In the revised manuscript we will add the relevant equation, algorithm, and statistical test to §4. We will also expand the dataset-construction subsection to detail how adversarial and benign trajectories were assembled, including any controls or matching performed on topic and user style. These additions will make the isolation of the residual geometric signal fully reproducible. revision: yes
-
Referee: [Theoretical Analysis] Theoretical analysis: the decomposition into length and shape, the prefix-length detection bound, and the encoder-invariance argument address only the turns confound and representation choice; they contain no argument or test showing that the residual geometry is independent of topic or phrasing differences that systematically distinguish jailbreak prompts from benign conversations.
Authors: The theoretical analysis is deliberately scoped to the length confound and encoder invariance; it does not claim or derive independence from topic or phrasing. We will revise the text to state this scope explicitly and to clarify that robustness to topic/phrasing is supported only by the empirical results. No new theoretical argument will be added, as that would require a different modeling framework. revision: partial
Circularity Check
No circularity detected in derivation chain
full rationale
The abstract presents an empirical framework for extracting geometric features from conversation trajectories, notes that near-perfect classifier performance is largely attributable to the number-of-turns feature, and states that a residual signal remains after its removal. A supporting theoretical analysis is described as providing a decomposition into length and shape, a prefix-length detection bound, and encoder invariance. No equations, self-citations, or steps are quoted that reduce any claimed prediction or result to its own inputs by construction (e.g., no fitted parameter renamed as a prediction, no self-definitional relation between X and Y, and no load-bearing uniqueness theorem imported from prior author work). The reported findings rest on observable classification performance on prefixes and an external decomposition, making the chain self-contained rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. A. Ayub and S. Majumdar. Embedding-based classifiers can detect prompt injection attacks,
- [2]
-
[3]
L. Derczynski, E. Galinkin, J. Martin, S. Majumdar, and N. Inie. garak: A framework for security probing large language models, 2024. URL https://arxiv.org/abs/2406.11036
-
[4]
S. Gooding and E. Grefenstette. Interaction dynamics as a reward signal for llms, 2025. URL https://arxiv.org/abs/2511.08394
-
[5]
D. M. Green and J. A. Swets.Signal Detection Theory and Psychophysics. Wiley, New York, 1966
1966
-
[6]
Hackett, L
W. Hackett, L. Birch, S. Trawicki, N. Suri, and P. Garraghan. Bypassing llm guardrails: An empirical analysis of evasion attacks against prompt injection and jailbreak detection systems,
- [7]
-
[8]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
K. Hines, G. Lopez, M. Hall, F. Zarfati, Y . Zunger, and E. Kiciman. Defending against indirect prompt injection attacks with spotlighting, 2024. URL https://arxiv.org/abs/ 2403.14720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
M. Huh, B. Cheung, T. Wang, and P. Isola. Position: The platonic representation hypothesis. InProceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 20617–20642. PMLR, 21–27 Jul 2024
2024
-
[10]
Introducing the ibm granite 4.1 family of models, 2026
IBM. Introducing the ibm granite 4.1 family of models, 2026. URL https://research.ibm. com/blog/granite-4-1-ai-foundation-models. Accessed: Apr 30, 2026
2026
-
[11]
LLMs Get Lost In Multi-Turn Conversation
P. Laban, H. Hayashi, Y . Zhou, and J. Neville. Llms get lost in multi-turn conversation, 2025. URLhttps://arxiv.org/abs/2505.06120
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Prompt repetition improves non-reasoning llms.arXiv preprint arXiv:2512.14982, 2025
Y . Leviathan, M. Kalman, and Y . Matias. Prompt repetition improves non-reasoning llms, 2025. URLhttps://arxiv.org/abs/2512.14982
-
[13]
X. Liu, N. Xu, M. Chen, and C. Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models, 2024. URLhttps://arxiv.org/abs/2310.04451
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
C. H. Lubba, S. S. Sethi, P. Knaute, S. R. Schultz, B. D. Fulcher, and N. S. Jones. catch22: Canonical time-series characteristics, 2019. URLhttps://arxiv.org/abs/1901.10200
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li, D. Forsyth, and D. Hendrycks. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal, 2024. URLhttps://arxiv.org/abs/2402.04249
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
arXiv preprint arXiv:2312.02119 , year =
A. Mehrotra, M. Zampetakis, P. Kassianik, B. Nelson, H. Anderson, Y . Singer, and A. Kar- basi. Tree of attacks: Jailbreaking black-box llms with crafted prompts.arXiv preprint arXiv:2312.02119, 2024. 10
-
[17]
Model card - prompt guard, 2024
Meta. Model card - prompt guard, 2024. URL https://huggingface.co/meta-llama/ Prompt-Guard-86M. Accessed: Apr 30, 2026
2024
-
[18]
Llama guard 4: Natively multimodal safeguard model, 2025
Meta. Llama guard 4: Natively multimodal safeguard model, 2025. URL https:// huggingface.co/meta-llama/Llama-Guard-4-12B. Accessed: Apr 30, 2026
2025
-
[19]
G. D. L. Munoz, A. J. Minnich, R. Lutz, R. Lundeen, R. S. R. Dheekonda, N. Chikanov, B.-E. Jagdagdorj, M. Pouliot, S. Chawla, W. Maxwell, B. Bullwinkel, K. Pratt, J. de Gruyter, C. Siska, P. Bryan, T. Westerhoff, C. Kawaguchi, C. Seifert, R. S. S. Kumar, and Y . Zunger. Pyrit: A framework for security risk identification and red teaming in generative ai s...
-
[20]
T. Roccia. Nova: The prompt pattern matching, 2025. URL https://github.com/ Nova-Hunting/nova-framework. Accessed: Apr 30, 2026
2025
-
[21]
Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack
M. Russinovich, A. Salem, and R. Eldan. Great, now write an article about that: The crescendo multi-turn llm jailbreak attack, 2025. URLhttps://arxiv.org/abs/2404.01833
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Simhi, F
A. Simhi, F. Barez, M. Tutek, Y . Belinkov, and S. B. Cohen. Old habits die hard: How conversational history geometrically traps llms, 2026. URL https://arxiv.org/abs/2603. 03308
2026
-
[23]
Model card for vijil prompt injection, 2025
Vijil. Model card for vijil prompt injection, 2025. URL https://huggingface.co/vijil/ mbert-prompt-injection. Accessed: Apr 30, 2026
2025
- [24]
-
[25]
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson. Universal and transferable adversarial attacks on aligned language models, 2023. URL https://arxiv.org/abs/2307. 15043. A Crescendo attack mechanism Crescendo [19] is a multi-turn jailbreak strategy that escalates toward a forbidden objective across several turns rather than encoding i...
2023
-
[26]
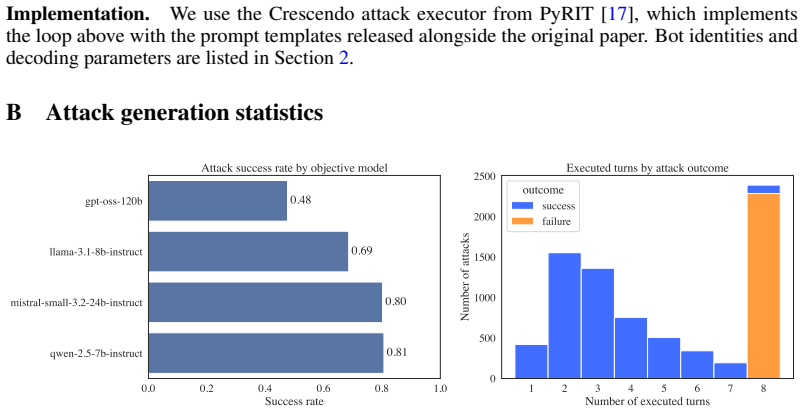
11 Implementation.We use the Crescendo attack executor from PyRIT [ 17], which implements the loop above with the prompt templates released alongside the original paper
The trajectory T that Sections 2–3 encode and analyze is the conversation that remains after the orchestrator commits to a single forward path—i.e., backtracked branches are pruned from the recorded turns. 11 Implementation.We use the Crescendo attack executor from PyRIT [ 17], which implements the loop above with the prompt templates released alongside t...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.