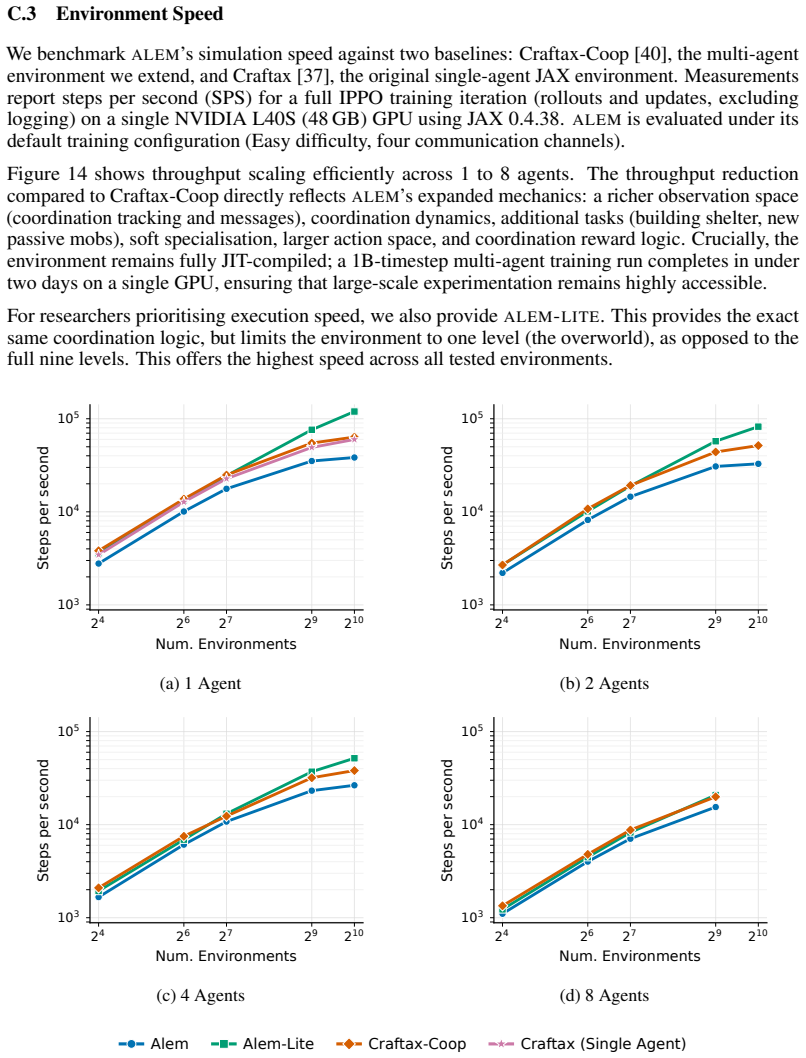
Benchmarking Open-Ended Multi-Agent Coordination in Language Agents
Pith reviewed 2026-06-27 19:17 UTC · model grok-4.3
The pith
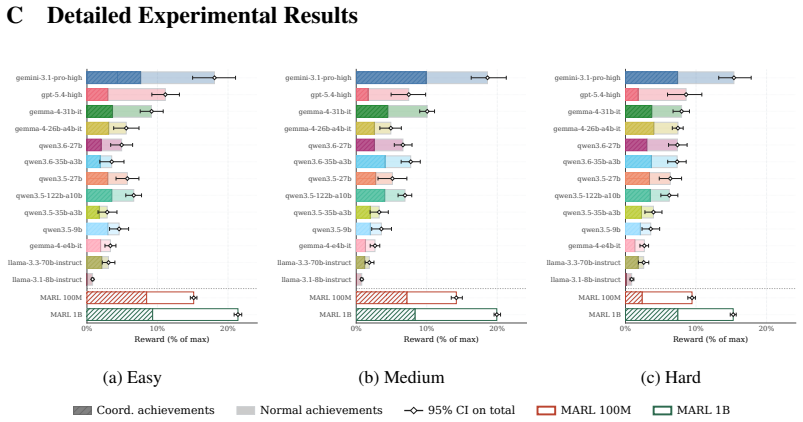
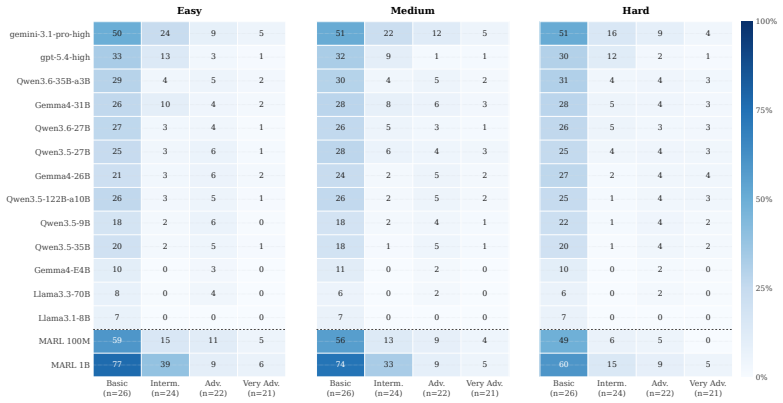
Current LLM agents average only 6 percent normalized return on open-ended multi-agent coordination tasks and show that individual competence does not produce coordination competence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
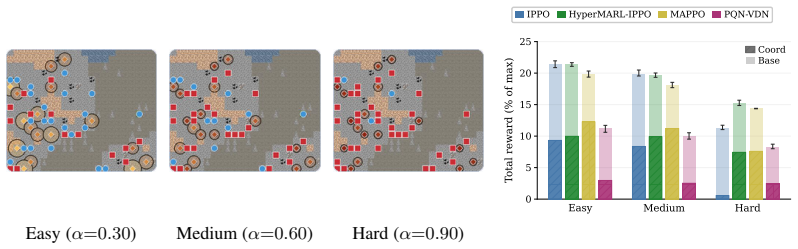
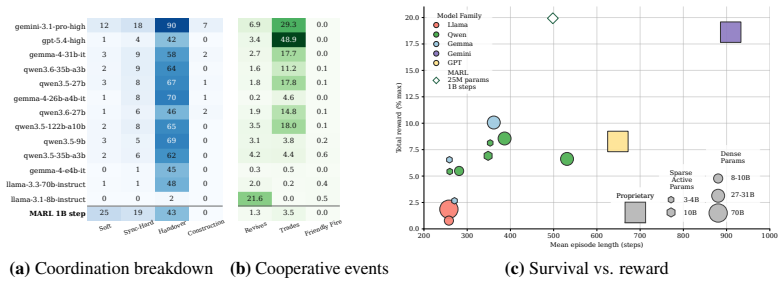
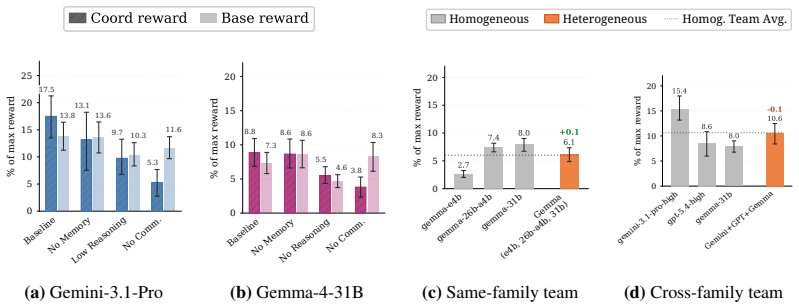
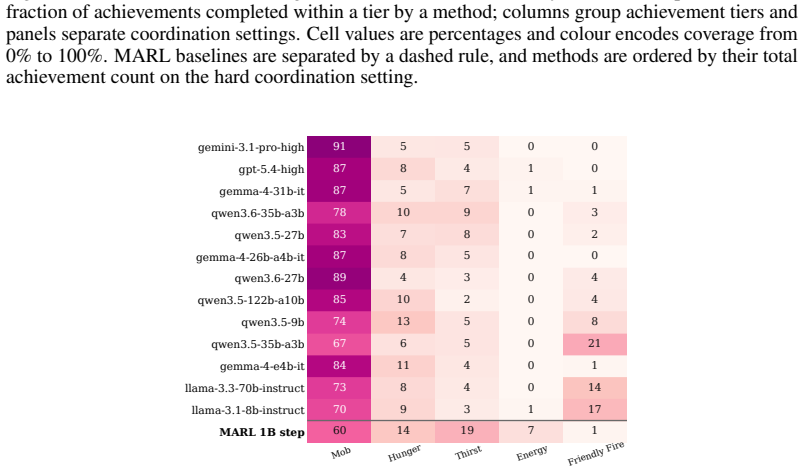
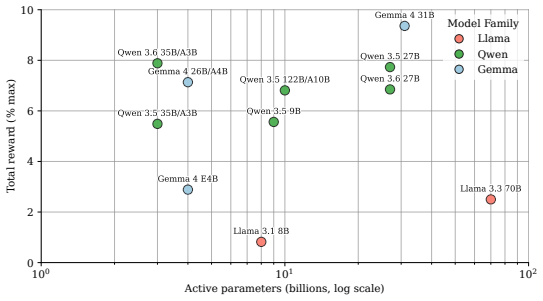
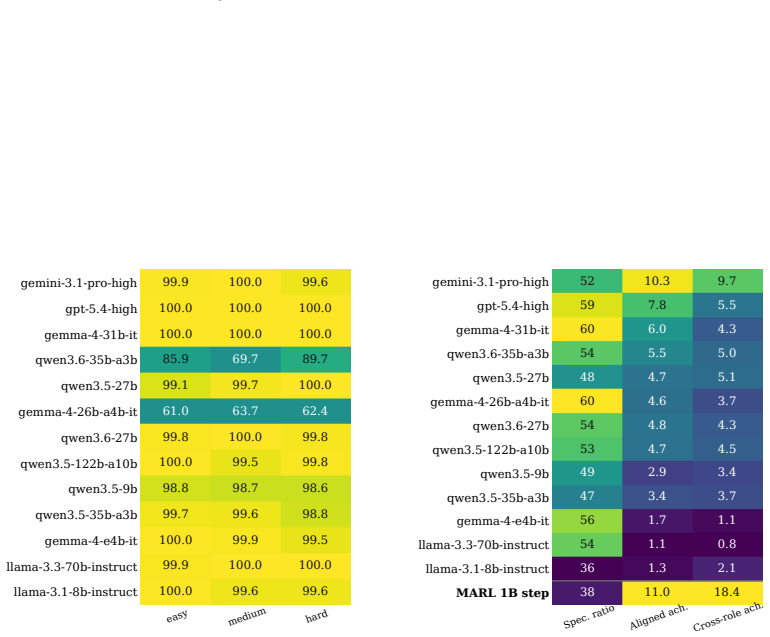
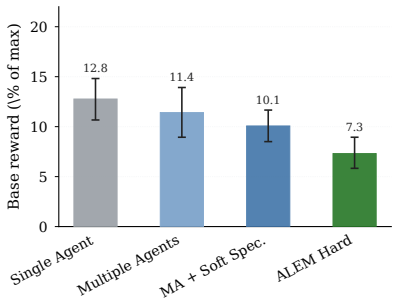
Current LLM agents remain far from solving ALEM, averaging only ~6% normalised return, but their failures are not uniform. On the hardest coordination setting, zero-shot Gemini-3.1-Pro-High approaches MARL agents trained for one billion steps, while GPT-5.4-High achieves strong base-task reward but much lower coordination reward. This contrast shows that individual task competence does not imply coordination competence. Ablations show that communication is the largest contributor to coordination, while memory and reasoning help when used to maintain multi-step plans. Overall, our results identify coordination as a distinct bottleneck for frontier LLM agents, separate from single-agent capabi
What carries the argument
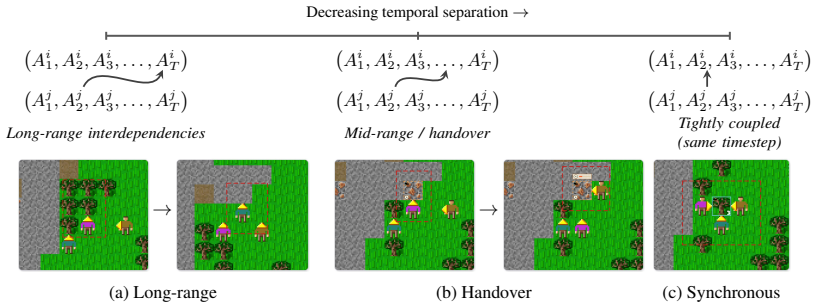
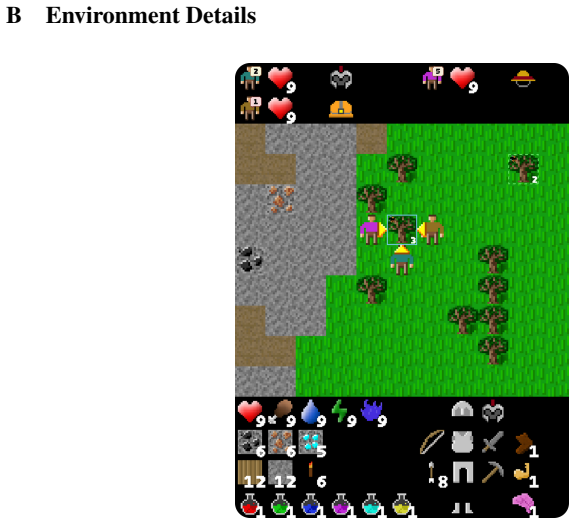
ALEM, a JAX-based benchmark embedding procedurally generated coordination tasks, soft specialisation, communication, and controllable difficulty into a long-horizon survival world with exploration, crafting, trading, and combat.
If this is right
- Models must be evaluated on separate base-task and coordination reward components rather than aggregate return alone.
- Adding explicit communication channels produces the largest immediate gain in team performance.
- Memory and reasoning modules improve results only when they are used to sustain multi-step shared plans across agents.
- Trained MARL agents remain the performance ceiling, so zero-shot LLM teams have substantial room for improvement.
- The benchmark supplies a controlled testbed for training agents that allocate roles and execute joint plans.
Where Pith is reading between the lines
- Single-agent scaling curves alone are unlikely to close the coordination gap without targeted multi-agent training regimes.
- ALEM-style environments could be used to generate synthetic coordination trajectories for fine-tuning or reinforcement learning from human feedback.
- If the separation between task and coordination competence holds, hybrid systems that pair a strong single-agent planner with a lightweight coordinator may outperform end-to-end language agents.
- Real-world deployments in collaborative robotics or game environments will need similar decomposed reward signals to diagnose coordination failures.
Load-bearing premise
The procedurally generated tasks and controllable difficulty settings inside ALEM capture the coordination demands that matter for real deployment of language agents.
What would settle it
A single new model that scores above 50 percent normalised return on the hardest ALEM setting while scoring below 10 percent on matched single-agent versions of the same tasks would falsify the claim that coordination forms a distinct bottleneck.
Figures

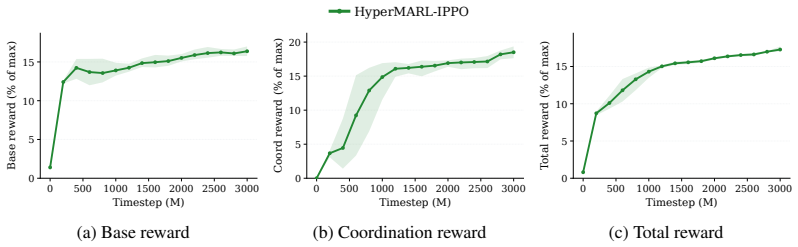
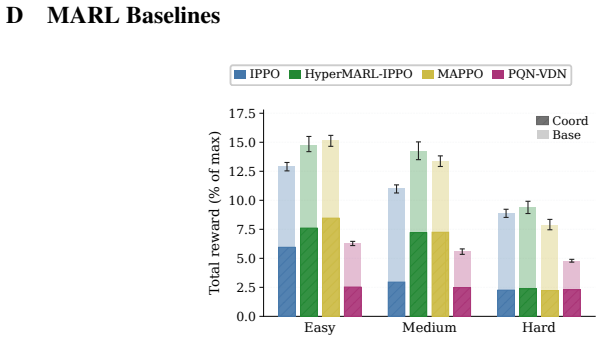
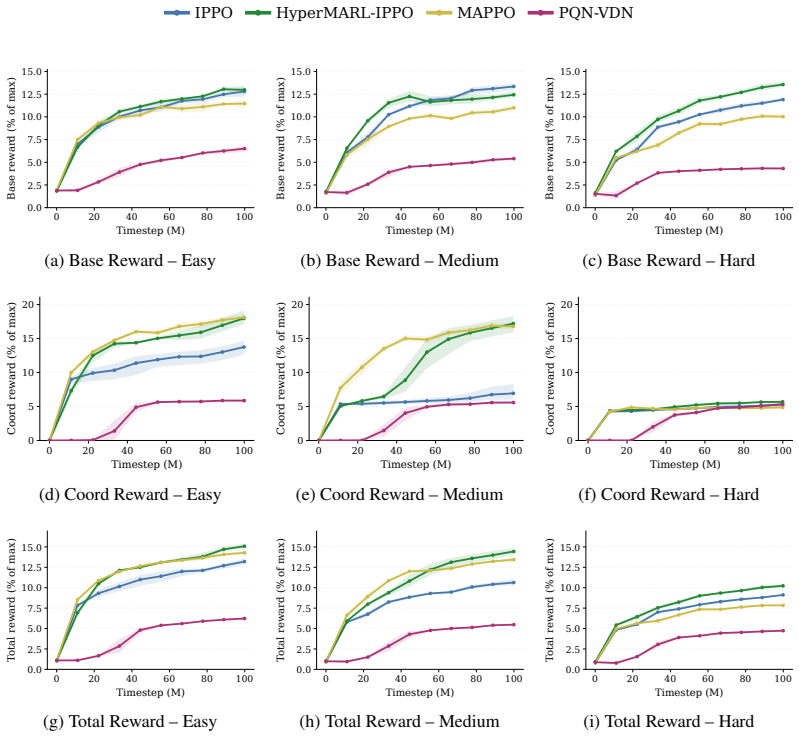
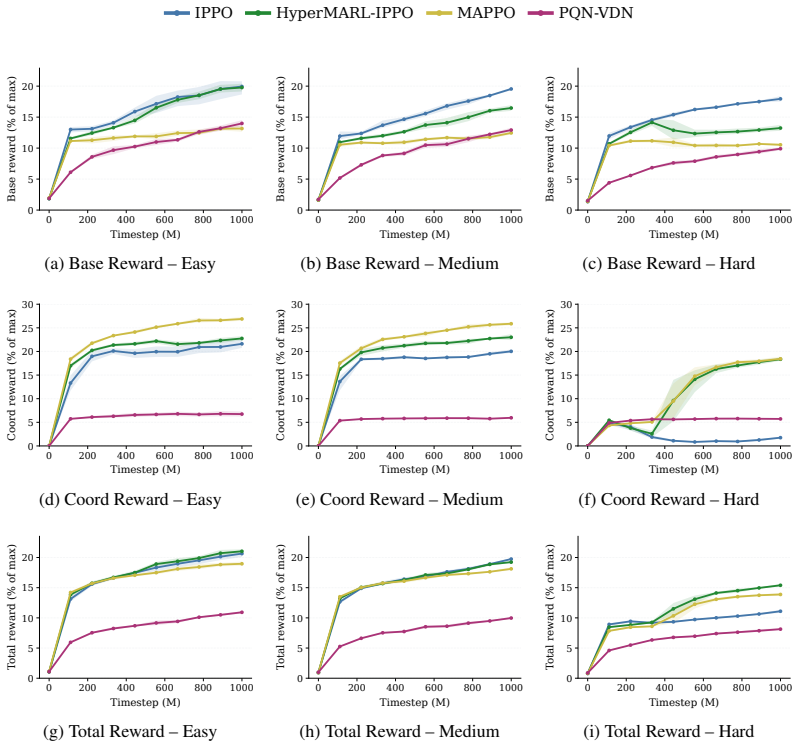
read the original abstract
As language models are increasingly deployed as autonomous agents, they must coordinate with others over long horizons in open-ended interactive tasks. Yet existing evaluations rarely test these demands together, instead emphasising single-agent tasks, short interactions, or highly structured multi-agent settings. We introduce $alem$, a JAX-based benchmark for open-ended multi-agent coordination built on Craftax-like dynamics. Alem embeds procedurally generated coordination tasks, soft specialisation, communication, and controllable coordination difficulty into a long-horizon survival world with exploration, crafting, trading, and combat. We evaluate $13$ modern LLMs zero-shot within homogeneous teams, with trained MARL agents as reference points. Current LLM agents remain far from solving alem, averaging only ~6% normalised return, but their failures are not uniform. On the hardest coordination setting, zero-shot Gemini-3.1-Pro-High approaches MARL agents trained for one billion steps, while GPT-5.4-High achieves strong base-task reward but much lower coordination reward. This contrast shows that individual task competence does not imply coordination competence. Ablations show that communication is the largest contributor to coordination, while memory and reasoning help when used to maintain multi-step plans. Overall, our results identify coordination as a distinct bottleneck for frontier LLM agents, separate from single-agent capabilities. Alem makes this bottleneck measurable and provides a controlled testbed for developing agents that communicate, allocate roles, and execute shared plans. Code is available at https://github.com/alem-world/alem-env.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ALEM, a JAX-based benchmark for open-ended multi-agent coordination in language agents built on Craftax-like dynamics. It embeds procedurally generated coordination tasks, soft specialisation, communication, and controllable difficulty into a long-horizon survival world. Zero-shot evaluation of 13 LLMs yields ~6% average normalised return; contrasts (e.g., Gemini-3.1-Pro-High nearing MARL on hardest settings while GPT-5.4-High shows strong base-task but low coordination reward) and ablations on communication/memory/reasoning support the claim that coordination is a distinct bottleneck separate from single-agent capabilities. Code is released at https://github.com/alem-world/alem-env.
Significance. If the benchmark's reward decomposition and procedural mechanics validly isolate multi-agent coordination demands, the work would supply a reproducible, controllable testbed that exposes a gap not captured by single-agent or structured MARL evaluations, with the open-source JAX implementation providing a concrete strength for follow-on research.
major comments (2)
- [Abstract] Abstract: the claim that 'individual task competence does not imply coordination competence' rests on the reported contrast between base-task reward and coordination reward (e.g., GPT-5.4-High). Without single-agent ablations or non-coordinating strategy baselines demonstrating that base-task rewards cannot be obtained independently of the soft-specialisation and trading mechanics, the observed gap could reflect the procedural generator's reward partitioning rather than a distinct agent limitation.
- [Experimental results] Experimental results (implied §4–5): the concrete performance numbers (~6% normalised return, model-specific contrasts, ablation effects) are presented without error bars, episode counts, data-exclusion rules, or full protocol for task generation and difficulty settings, undermining assessment of whether the claimed distinctions between models and between base vs. coordination reward are statistically reliable.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate the revisions we will make to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'individual task competence does not imply coordination competence' rests on the reported contrast between base-task reward and coordination reward (e.g., GPT-5.4-High). Without single-agent ablations or non-coordinating strategy baselines demonstrating that base-task rewards cannot be obtained independently of the soft-specialisation and trading mechanics, the observed gap could reflect the procedural generator's reward partitioning rather than a distinct agent limitation.
Authors: We agree that additional evidence would strengthen the claim that the observed gap reflects a distinct agent limitation rather than an artifact of the reward design. The paper's reward decomposition is intended to separate base-task performance from coordination-specific rewards through the procedural generation of tasks requiring soft specialisation and trading. However, to directly address this, we will include single-agent ablations (evaluating agents in isolation on base tasks) and non-coordinating strategy baselines in the revised manuscript. This will demonstrate that base-task rewards can indeed be achieved without coordination mechanics, supporting that the gap in multi-agent settings is due to coordination challenges. revision: yes
-
Referee: [Experimental results] Experimental results (implied §4–5): the concrete performance numbers (~6% normalised return, model-specific contrasts, ablation effects) are presented without error bars, episode counts, data-exclusion rules, or full protocol for task generation and difficulty settings, undermining assessment of whether the claimed distinctions between models and between base vs. coordination reward are statistically reliable.
Authors: We acknowledge the importance of reporting statistical details for reproducibility and reliability assessment. The current manuscript presents average normalised returns but omits error bars and episode counts. We will revise the experimental results section to include error bars (e.g., standard error across episodes), the number of episodes evaluated per model, data-exclusion rules if any, and a detailed protocol for task generation and difficulty settings. This will allow readers to better assess the statistical significance of the model contrasts and ablation effects. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation
full rationale
The paper introduces the ALEM benchmark and reports direct empirical results from running 13 LLMs and trained MARL agents on procedurally generated tasks. No equations, fitted parameters, or derivations are present in the provided text. Claims such as 'individual task competence does not imply coordination competence' rest on observed performance contrasts rather than any reduction to inputs by construction. No self-citations or ansatzes are invoked as load-bearing steps. The evaluation is self-contained against external agent runs and does not rename known results or smuggle assumptions via prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Language models can be deployed as zero-shot autonomous agents in interactive environments through standard prompting without task-specific fine-tuning.
- domain assumption MARL agents trained for one billion steps constitute a meaningful performance ceiling for the coordination tasks in ALEM.
invented entities (1)
-
ALEM benchmark environment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Melting pot 2.0.arXiv preprint arXiv:2211.13746, 2022
John P Agapiou, Alexander Sasha Vezhnevets, Edgar A Duéñez-Guzmán, Jayd Matyas, Yi- ran Mao, Peter Sunehag, Raphael Köster, Udari Madhushani, Kavya Kopparapu, Ramona Comanescu, et al. Melting pot 2.0.arXiv preprint arXiv:2211.13746, 2022
arXiv 2022
-
[2]
Deep reinforcement learning at the edge of the statistical precipice.Advances in Neural Information Processing Systems, 2021
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville, and Marc G Belle- mare. Deep reinforcement learning at the edge of the statistical precipice.Advances in Neural Information Processing Systems, 2021
2021
-
[3]
Llm-coordination: evaluating and analyzing multi-agent coordination abilities in large language models
Saaket Agashe, Yue Fan, Anthony Reyna, and Xin Eric Wang. Llm-coordination: evaluating and analyzing multi-agent coordination abilities in large language models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 8038–8057, 2025
2025
-
[4]
The hanabi challenge: A new frontier for ai research.Artificial Intelligence, 280:103216, 2020
Nolan Bard, Jakob N Foerster, Sarath Chandar, Neil Burch, Marc Lanctot, H Francis Song, Emilio Parisotto, Vincent Dumoulin, Subhodeep Moitra, Edward Hughes, et al. The hanabi challenge: A new frontier for ai research.Artificial Intelligence, 280:103216, 2020
2020
-
[5]
The arcade learning environment: An evaluation platform for general agents.Journal of artificial intelligence research, 47:253–279, 2013
Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents.Journal of artificial intelligence research, 47:253–279, 2013
2013
-
[6]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman- Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URLhttp://github.com/jax-ml/jax
2018
-
[7]
Superhuman ai for heads-up no-limit poker: Libratus beats top professionals.Science, 359(6374):418–424, 2018
Noam Brown and Tuomas Sandholm. Superhuman ai for heads-up no-limit poker: Libratus beats top professionals.Science, 359(6374):418–424, 2018
2018
-
[8]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[9]
Deep blue.Artificial intelligence, 134(1-2):57–83, 2002
Murray Campbell, A Joseph Hoane Jr, and Feng-hsiung Hsu. Deep blue.Artificial intelligence, 134(1-2):57–83, 2002
2002
-
[10]
On the utility of learning about humans for human-ai coordination.Advances in neural information processing systems, 32, 2019
Micah Carroll, Rohin Shah, Mark K Ho, Tom Griffiths, Sanjit Seshia, Pieter Abbeel, and Anca Dragan. On the utility of learning about humans for human-ai coordination.Advances in neural information processing systems, 32, 2019
2019
-
[11]
MLE-bench: Evaluating machine learning agents on machine learning engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Aleksander Madry, and Lilian Weng. MLE-bench: Evaluating machine learning agents on machine learning engineering. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview...
2025
-
[12]
Christian Schroeder De Witt, Tarun Gupta, Denys Makoviichuk, Viktor Makoviychuk, Philip HS Torr, Mingfei Sun, and Shimon Whiteson. Is independent learning all you need in the starcraft multi-agent challenge?arXiv preprint arXiv:2011.09533, 2020
arXiv 2011
-
[13]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[14]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. InForty-first International Conference on Machine Learning, 2023
2023
-
[15]
Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning.Advances in Neural Information Processing Systems, 36:37567–37593, 2023
Benjamin Ellis, Jonathan Cook, Skander Moalla, Mikayel Samvelyan, Mingfei Sun, Anuj Mahajan, Jakob Foerster, and Shimon Whiteson. Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning.Advances in Neural Information Processing Systems, 36:37567–37593, 2023. 11
2023
-
[16]
Simplifying deep temporal difference learning
Matteo Gallici, Mattie Fellows, Benjamin Ellis, Bartomeu Pou, Ivan Masmitja, Jakob Nicolaus Foerster, and Mario Martin. Simplifying deep temporal difference learning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[17]
Overcookedv2: Rethinking overcooked for zero-shot coordination
Tobias Gessler, Tin Dizdarevic, Ani Calinescu, Benjamin Ellis, Andrei Lupu, and Jakob Nicolaus Foerster. Overcookedv2: Rethinking overcooked for zero-shot coordination. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=hlvLM3GX8R
2025
-
[18]
Gemini 3.1 pro model card
Google DeepMind. Gemini 3.1 pro model card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/, February 2026
2026
-
[19]
Gemma 4 model card
Google DeepMind. Gemma 4 model card. https://ai.google.dev/gemma/docs/core/ model_card_4, April 2026. Accessed: 2026-04-25
2026
-
[20]
Thomas Grady, Kip Parker, Iliyan Zarov, Henry Course, Chengxi Taylor, and Ross Taylor. Kellybench: A benchmark for long-horizon sequential decision making.arXiv preprint arXiv:2604.27865, 2026
Pith/arXiv arXiv 2026
-
[21]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[22]
Florian Grötschla, Luis Müller, Jan Tönshoff, Mikhail Galkin, and Bryan Perozzi. Agentsnet: Coordination and collaborative reasoning in multi-agent llms.arXiv preprint arXiv:2507.08616, 2025
arXiv 2025
-
[23]
Large language model based multi-agents: a survey of progress and challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: a survey of progress and challenges. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 8048–8057, 2024
2024
-
[24]
Benchmarking the spectrum of agent capabilities
Danijar Hafner. Benchmarking the spectrum of agent capabilities. InInternational Con- ference on Learning Representations, 2022. URL https://openreview.net/forum?id= 1W0z96MFEoH
2022
-
[25]
Multi- agent risks from advanced ai.arXiv preprint arXiv:2502.14143, 2025
Lewis Hammond, Alan Chan, Jesse Clifton, Jason Hoelscher-Obermaier, Akbir Khan, Euan McLean, Chandler Smith, Wolfram Barfuss, Jakob Foerster, Tomáš Gavenˇciak, et al. Multi- agent risks from advanced ai.arXiv preprint arXiv:2502.14143, 2025
arXiv 2025
-
[26]
Dynamic programming for partially observable stochastic games
Eric A Hansen, Daniel S Bernstein, and Shlomo Zilberstein. Dynamic programming for partially observable stochastic games. InAAAI, volume 4, pages 709–715, 2004
2004
-
[27]
Muyu He, Adit Jain, Anand Kumar, Vincent Tu, Soumyadeep Bakshi, Sachin Patro, and Nazneen Rajani. yc−bench : Benchmarking ai agents for long-term planning and consistent execution.arXiv preprint arXiv:2604.01212, 2026
arXiv 2026
-
[28]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023
2023
-
[29]
Position: Open-endedness is essential for artificial superhuman intelligence
Edward Hughes, Michael D Dennis, Jack Parker-Holder, Feryal Behbahani, Aditi Mavalankar, Yuge Shi, Tom Schaul, and Tim Rocktäschel. Position: Open-endedness is essential for artificial superhuman intelligence. InProceedings of the 41st International Conference on Machine Learn- ing, volume 235 ofProceedings of Machine Learning Research, pages 20597–20616....
2024
-
[30]
Gpudrive: Data-driven, multi-agent driving simulation at 1 million fps
Saman Kazemkhani, Aarav Pandya, Daphne Cornelisse, Brennan Shacklett, and Eugene Vinitsky. Gpudrive: Data-driven, multi-agent driving simulation at 1 million fps. InPro- ceedings of the International Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/2408.01584. 12
arXiv 2025
-
[31]
Measuring ai ability to complete long tasks.arXiv preprint arXiv:2503.14499, 352, 2025
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney V on Arx, et al. Measuring ai ability to complete long tasks.arXiv preprint arXiv:2503.14499, 352, 2025
arXiv 2025
-
[32]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[33]
Scalable evaluation of multi-agent reinforcement learning with melting pot
Joel Z Leibo, Edgar A Dueñez-Guzman, Alexander Vezhnevets, John P Agapiou, Peter Sunehag, Raphael Koster, Jayd Matyas, Charlie Beattie, Igor Mordatch, and Thore Graepel. Scalable evaluation of multi-agent reinforcement learning with melting pot. InInternational conference on machine learning, pages 6187–6199. PMLR, 2021
2021
-
[34]
Stateful active facilitator: Co- ordination and environmental heterogeneity in cooperative multi-agent reinforcement learn- ing
Dianbo Liu, Vedant Shah, Oussama Boussif, Cristian Meo, Anirudh Goyal, Tianmin Shu, Michael Curtis Mozer, Nicolas Heess, and Yoshua Bengio. Stateful active facilitator: Co- ordination and environmental heterogeneity in cooperative multi-agent reinforcement learn- ing. InThe Eleventh International Conference on Learning Representations, 2023. URL https://o...
2023
-
[35]
Towards end-to-end automation of ai research.Nature, 651(8107):914–919, 2026
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. Towards end-to-end automation of ai research.Nature, 651(8107):914–919, 2026
2026
-
[36]
The interdisciplinary study of coordination.ACM Computing Surveys (CSUR), 26(1):87–119, 1994
Thomas W Malone and Kevin Crowston. The interdisciplinary study of coordination.ACM Computing Surveys (CSUR), 26(1):87–119, 1994
1994
-
[37]
Craftax: A lightning-fast benchmark for open-ended reinforcement learning
Michael Matthews, Michael Beukman, Benjamin Ellis, Mikayel Samvelyan, Matthew Jackson, Samuel Coward, and Jakob Foerster. Craftax: A lightning-fast benchmark for open-ended reinforcement learning. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[38]
The influence of scaffolds on coordination scaling laws in LLM agents
Mariana Meireles, Niklas Lauffer, Rupali Bhati, and Cameron Allen. The influence of scaffolds on coordination scaling laws in LLM agents. InWorkshop on Scaling Environments for Agents,
-
[39]
URLhttps://openreview.net/forum?id=E9whrbtgUA
-
[40]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332, 2021
Pith/arXiv arXiv 2021
-
[41]
Multi- agent craftax: Benchmarking open-ended multi-agent reinforcement learning at the hyperscale
Bassel Al Omari, Michael Matthews, Alexander Rutherford, and Jakob Nicolaus Foerster. Multi- agent craftax: Benchmarking open-ended multi-agent reinforcement learning at the hyperscale. arXiv preprint arXiv:2511.04904, 2025
arXiv 2025
-
[42]
Introducing gpt-5.4
OpenAI. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4/ , March 2026
2026
-
[43]
BALROG: Benchmarking agentic LLM and VLM reasoning on games
Davide Paglieri, Bartłomiej Cupiał, Samuel Coward, Ulyana Piterbarg, Maciej Wolczyk, Akbir Khan, Eduardo Pignatelli, Łukasz Kuci ´nski, Lerrel Pinto, Rob Fergus, Jakob Nicolaus Foerster, Jack Parker-Holder, and Tim Rocktäschel. BALROG: Benchmarking agentic LLM and VLM reasoning on games. InThe Thirteenth International Conference on Learning Representations,
-
[44]
URLhttps://openreview.net/forum?id=fp6t3F669F
-
[45]
Qwen3.6-Plus: Towards real world agents, April 2026
Qwen Team. Qwen3.6-Plus: Towards real world agents, April 2026. URL https://qwen.ai/ blog?id=qwen3.6
2026
-
[46]
Jaxmarl: Multi-agent rl environments and algorithms in jax.Advances in Neural Information Processing Systems, 37:50925–50951, 2024
Alexander Rutherford, Benjamin Ellis, Matteo Gallici, Jonathan Cook, Andrei Lupu, Garðar Ingvarsson, Timon Willi, Ravi Hammond, Akbir Khan, Christian S de Witt, et al. Jaxmarl: Multi-agent rl environments and algorithms in jax.Advances in Neural Information Processing Systems, 37:50925–50951, 2024
2024
-
[47]
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder de Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philip H. S. Torr, Jakob Foerster, and Shimon Whiteson. The starcraft multi-agent challenge. InProceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’19, page 2186–2188, Richland, ...
2019
-
[48]
Harvard university press, 1980
Thomas C Schelling.The Strategy of Conflict: with a new Preface by the Author. Harvard university press, 1980
1980
-
[49]
Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Si- mon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
2020
-
[50]
The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity
Parshin Shojaee, Seyed Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum? id=Y...
2026
-
[51]
The illusion of diminishing returns: Measuring long horizon execution in LLMs
Akshit Sinha, Arvindh Arun, Shashwat Goel, Steffen Staab, and Jonas Geiping. The illusion of diminishing returns: Measuring long horizon execution in LLMs. InThe Fourteenth Inter- national Conference on Learning Representations, 2026. URL https://openreview.net/ forum?id=3lm8lWYxiq
2026
-
[52]
Cambridge University Press, 2004
Brian Skyrms.The stag hunt and the evolution of social structure. Cambridge University Press, 2004
2004
-
[53]
Joseph Suarez, Yilun Du, Phillip Isola, and Igor Mordatch. Neural mmo: A massively multiagent game environment for training and evaluating intelligent agents.arXiv preprint arXiv:1903.00784, 2019
Pith/arXiv arXiv 1903
-
[54]
Neural mmo 2.0: a massively multi-task addition to massively multi-agent learning.Advances in Neural Information Processing Systems, 36:50094–50104, 2023
Joseph Suarez, David Bloomin, Kyoung Whan Choe, Hao Xiang Li, Ryan Sullivan, Nishaanth Kanna, Daniel Scott, Rose Shuman, Herbie Bradley, Louis Castricato, et al. Neural mmo 2.0: a massively multi-task addition to massively multi-agent learning.Advances in Neural Information Processing Systems, 36:50094–50104, 2023
2023
-
[55]
Collab-overcooked: Benchmarking and evaluating large language models as collaborative agents
Haochen Sun, Shuwen Zhang, Lujie Niu, Lei Ren, Hao Xu, Hao Fu, Fangkun Zhao, Caixia Yuan, and Xiaojie Wang. Collab-overcooked: Benchmarking and evaluating large language models as collaborative agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 4922–4951, 2025
2025
-
[56]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[57]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[58]
Hypermarl: Adaptive hypernetworks for multi-agent rl
Kale-ab Abebe Tessera, Arrasy Rahman, Amos Storkey, and Stefano V Albrecht. Hypermarl: Adaptive hypernetworks for multi-agent rl. InThe Thirty-ninth Annual Conference on Neu- ral Information Processing Systems, 2025. URL https://openreview.net/forum?id= 56CgYnf9Dr
2025
-
[59]
Probing dec-POMDP reasoning in cooperative MARL
Kale-ab Abebe Tessera, Leonard Hinckeldey, Riccardo Zamboni, David Abel, and Amos Storkey. Probing dec-POMDP reasoning in cooperative MARL. InThe 25th International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS), Oral, 2026
2026
-
[60]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[61]
Grandmaster level in starcraft ii using multi-agent reinforcement learning.nature, 575(7782):350–354, 2019
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Jun- young Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning.nature, 575(7782):350–354, 2019
2019
-
[62]
V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https: //openreview.net/forum?id=ehfRiF0R3a
2024
-
[63]
Wei Wang, Dan Zhang, Tao Feng, Boyan Wang, and Jie Tang. Battleagentbench: A benchmark for evaluating cooperation and competition capabilities of language models in multi-agent systems.arXiv preprint arXiv:2408.15971, 2024. 14
arXiv 2024
-
[64]
Weixuan Wang, Dongge Han, Daniel Madrigal Diaz, Jin Xu, Victor Rühle, and Saravan Rajmohan. Odysseybench: Evaluating llm agents on long-horizon complex office application workflows.arXiv preprint arXiv:2508.09124, 2025
arXiv 2025
-
[65]
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066, 2025
Pith/arXiv arXiv 2025
-
[66]
LLM- powered decentralized generative agents with adaptive hierarchical knowledge graph for co- operative planning
Hanqing Yang, Jingdi Chen, Marie Siew, Tania Lorido Botran, and Carlee Joe-Wong. LLM- powered decentralized generative agents with adaptive hierarchical knowledge graph for co- operative planning. InThe First MARW: Multi-Agent AI in the Real World Workshop at AAAI 2025, 2025. URLhttps://openreview.net/forum?id=l9QUw0oUTa
2025
-
[67]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview. net/forum?id=WE_vluYUL-X
2023
-
[68]
Eric Ye, Ren Tao, and Natasha Jaques. An efficient open world environment for multi-agent social learning.arXiv preprint arXiv:2508.15679, 2025
arXiv 2025
-
[69]
The surprising effectiveness of ppo in cooperative multi-agent games.Advances in neural information processing systems, 35:24611–24624, 2022
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games.Advances in neural information processing systems, 35:24611–24624, 2022
2022
-
[70]
Yinger Zhang, Shutong Jiang, Renhao Li, Jianhong Tu, Yang Su, Lianghao Deng, Xudong Guo, Chenxu Lv, and Junyang Lin. Deepplanning: Benchmarking long-horizon agentic planning with verifiable constraints.arXiv preprint arXiv:2601.18137, 2026
arXiv 2026
-
[71]
Yujie Zhao, Boqin Yuan, Junbo Huang, Haocheng Yuan, Zhongming Yu, Haozhou Xu, Lanxiang Hu, Abhilash Shankarampeta, Zimeng Huang, Wentao Ni, et al. Ama-bench: Evaluating long- horizon memory for agentic applications.arXiv preprint arXiv:2602.22769, 2026
Pith/arXiv arXiv 2026
-
[72]
Multiagentbench: Evaluating the collaboration and competition of llm agents
Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Yang, Shuyi Guo, Daisy Zhe Wang, Zhenhailong Wang, Cheng Qian, Robert Tang, Heng Ji, et al. Multiagentbench: Evaluating the collaboration and competition of llm agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8580–8622, 2025. 15...
2025
-
[73]
By default it also optionally includes the full action catalogue with natural-language descriptions, game and coordination mechanics
System prompt:The system prompt is shared across all time steps for an agent and defines the agent identity and role, the team size, the objective, and the rules needed to act in the environment. By default it also optionally includes the full action catalogue with natural-language descriptions, game and coordination mechanics
-
[74]
Observation from k step(s) ago
Observation and Action History:The observation and action history is a rolling sequence of recent messages from the environment and the agent itself. The observation messages contain previous observations, labelled as “Observation from k step(s) ago”, and the action messages contain the action previously taken by the agent. When memory and commu- nication...
-
[75]
The agent is then prompted to respond with an action
Current Observation and Action Space:The current observation message contains textual descriptions of: achievement progress, current level, nearby terrain, items and enemies, visible coordination opportunities and requirements, teammate status, agent stats, vitals and inventory. The agent is then prompted to respond with an action. By default, the call to...
-
[76]
Gather wood -> place a table -> craft a wood pickaxe; craft a wood sword early if combat is likely
-
[77]
Mine stone and coal -> place a furnace -> craft iron tools and iron armour
-
[78]
The ladder only becomes usable after enough monsters on that level have been killed
To descend: stand on the`ladder_down`tile (visible in your observation when close) and use the Descend action. The ladder only becomes usable after enough monsters on that level have been killed. Only one agent needs to use Descend/Ascend -- all teammates are teleported with them. </game_rules> <achievements> ## Achievements Collect Wood Place Table Eat C...
-
[79]
(Required) Exactly one action from the available action list: <action>YOUR_CHOSEN_ACTION</action>
-
[80]
Teammates can only act on what you tell them
(Optional) Broadcast to teammates, up to 400 chars. Teammates can only act on what you tell them. Be specific (e.g.'Dig on tree next turn','Ladder at 5NE','Need 2 wood'). Reply to teammates' requests. <communication>YOUR_MESSAGE</communication>
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.