Review Residuals: Update-Conditioned Residual Gating for Transformers
Pith reviewed 2026-07-01 06:36 UTC · model grok-4.3
The pith
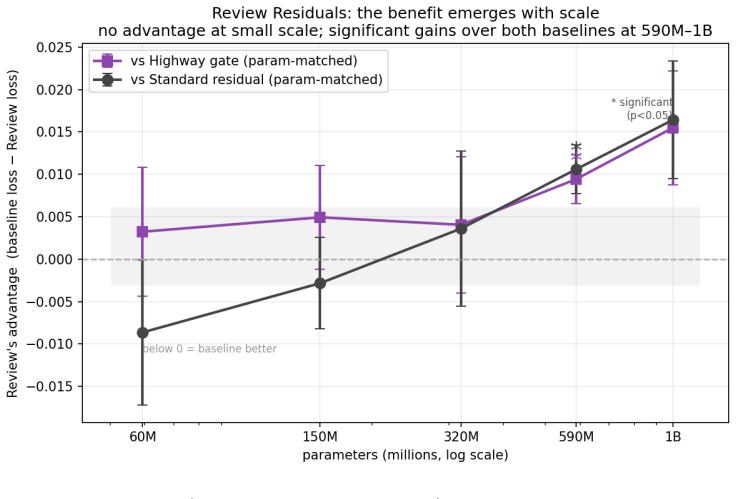
Review Residuals replace the fixed add-1 in residual connections with a gate that sees both the current state and the proposed update, producing gains that emerge at 590M parameters and widen at 1B.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Review Residuals replace the fixed coefficient of one in residual connections with a learned, input-dependent gate conditioned on both the current hidden state and the proposed update from the sublayer. This yields two results: an additive formulation trains stably at arbitrary depth while a convex formulation reintroduces vanishing gradients, and the performance benefit over standard residuals and Highway gates emerges only at large scale and increases with model size.
What carries the argument
The update-conditioned gate r_l = sigmoid(W[RMSNorm(h_{l-1}), RMSNorm(u_l)]) that multiplies the proposed update u_l before adding it to the previous state h_{l-1}.
If this is right
- Transformers can be trained stably to greater depths using the additive Review Residual form.
- Performance advantages of update-conditioned gating increase rather than diminish as model size grows from 590M to 1B parameters.
- Parameter-matched comparisons show statistical significance (p<0.05) favoring Review Residuals at large scales.
- Small models (60M) show no benefit, indicating the mechanism's utility is scale-dependent.
Where Pith is reading between the lines
- The same update-conditioning principle could be tested in non-residual components such as attention or feed-forward layers.
- If update quality becomes more variable at larger scales, explicit review gates may become a general requirement rather than an optional refinement.
- The depth-stability result suggests that any gating method intended for very deep networks should preserve an identity path rather than rely on convex combinations.
Load-bearing premise
The performance differences arise specifically from conditioning the gate on the proposed update rather than from other differences in training procedure, initialization, or hyperparameter tuning, and the multi-seed statistical tests adequately control for run-to-run variance.
What would settle it
A 1B-parameter replication in which a gate conditioned only on the state (without the update) matches or exceeds the update-conditioned version would show that conditioning on the update is not the source of the reported benefit.
Figures

read the original abstract
Residual connections add every sublayer's proposed update with a fixed coefficient of one; the network never evaluates whether an update is reliable before committing it. Drawing on the human-factors principle of independent verification, we introduce Review Residuals, which scale each update by a learned, input-dependent gate conditioned on both the current state and the proposed update: h_l = h_{l-1} + r_l * u_l with r_l = sigmoid(W[RMSNorm(h_{l-1}), RMSNorm(u_l)]). Conditioning the gate on the update is the property that distinguishes it from prior gated and scaled residuals. We report two findings. First, a depth-stability result: a convex (Highway-style) form of the gate reintroduces vanishing gradients and fails to train beyond ~20 layers, whereas the additive, identity-preserving form trains stably at all depths we tested. Second, an emergence-with-scale result: trained from scratch across five sizes (60M-1B parameters, multi-seed), Review Residuals show no advantage at small scale but at 590M significantly outperform both a parameter-matched Highway gate and a parameter-matched standard residual (p<0.05), with a larger advantage at 1B. The benefit grows with model size rather than shrinking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Review Residuals, a modification to residual connections in Transformers where the update u_l is scaled by a gate r_l = sigmoid(W [RMSNorm(h_{l-1}), RMSNorm(u_l)]), conditioned on both the previous state and the proposed update. It claims two results: (1) an additive form of the gate enables stable training at arbitrary depths unlike a convex Highway-style gate, and (2) when trained from scratch on models from 60M to 1B parameters with multiple seeds, Review Residuals show no benefit at small scales but significantly outperform parameter-matched Highway and standard residual connections at 590M and 1B scales (p<0.05), with the advantage increasing with scale.
Significance. If the experimental comparisons are properly controlled, the emergence-with-scale finding would be notable, as it identifies a residual formulation whose benefits appear only at larger model sizes rather than diminishing, potentially offering a practical improvement for training large Transformers. The depth-stability result reinforces the importance of preserving the identity path in gated residuals. The multi-seed experiments and reported p<0.05 tests are a strength.
major comments (1)
- [Abstract] Abstract: The abstract states that Review Residuals 'significantly outperform both a parameter-matched Highway gate and a parameter-matched standard residual (p<0.05)' at 590M and larger at 1B, but provides no explicit confirmation that all training details (optimizer, learning rate schedule, initialization, data ordering, normalization placement) were held identical across the three residual variants. Without this, the scale-dependent outperformance cannot be confidently attributed to the update-conditioning mechanism.
minor comments (1)
- [Abstract] Abstract: The notation for the gate input concatenation is written as W[RMSNorm(h_{l-1}), RMSNorm(u_l)], which could be clarified as concatenation before the linear projection.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit confirmation of experimental controls. We address the concern below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that Review Residuals 'significantly outperform both a parameter-matched Highway gate and a parameter-matched standard residual (p<0.05)' at 590M and larger at 1B, but provides no explicit confirmation that all training details (optimizer, learning rate schedule, initialization, data ordering, normalization placement) were held identical across the three residual variants. Without this, the scale-dependent outperformance cannot be confidently attributed to the update-conditioning mechanism.
Authors: We agree that the abstract should explicitly state the controls. The full methods section already specifies that all three residual variants were trained under identical conditions: the same optimizer (AdamW), learning-rate schedule, initialization scheme, data ordering, batch size, and normalization placement, with only the residual formulation differing. To address the referee's point directly in the abstract, we will add the clause 'with all other training details held identical across variants' to the relevant sentence. This makes the attribution to the update-conditioning mechanism unambiguous without altering any results or claims. revision: yes
Circularity Check
No circularity: empirical comparisons rest on direct training runs, not self-referential definitions or fitted inputs
full rationale
The paper introduces a gated residual form and reports scale-dependent performance differences from multi-seed training experiments across model sizes. No equations are presented that define a quantity in terms of itself, no fitted parameters are relabeled as predictions, and no load-bearing claims rely on self-citations or uniqueness theorems imported from prior author work. The depth-stability and emergence-with-scale findings are framed as outcomes of the reported training procedure rather than algebraic identities, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Gate projection matrix W
axioms (2)
- domain assumption RMSNorm produces suitable normalized inputs for the gate
- standard math Sigmoid produces a valid scaling factor in [0,1]
Reference graph
Works this paper leans on
-
[1]
A. Vaswani et al. Attention Is All You Need.NeurIPS, 2017. arXiv:1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
K. He, X. Zhang, S. Ren, J. Sun. Deep Residual Learning for Image Recognition.CVPR, 2016. arXiv:1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
R. K. Srivastava, K. Greff, J. Schmidhuber. Highway Networks. arXiv:1505.00387, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[4]
T. Bachlechner et al. ReZero is All You Need.UAI, 2021. arXiv:2003.04887
-
[5]
H. Touvron et al. Going Deeper with Image Transformers (CaiT / LayerScale).ICCV, 2021. arXiv:2103.17239
-
[6]
Fixup Initialization: Residual Learning Without Normalization
H. Zhang, Y. N. Dauphin, T. Ma. Fixup Initialization.ICLR, 2019. arXiv:1901.09321
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[7]
H. Wang et al. DeepNet: Scaling Transformers to 1,000 Layers. arXiv:2203.00555, 2022
-
[8]
Kimi Team. Attention Residuals. arXiv:2603.15031, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Root Mean Square Layer Normalization
B. Zhang, R. Sennrich. Root Mean Square Layer Normalization.NeurIPS, 2019. arXiv:1910.07467
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[10]
Decoupled Weight Decay Regularization
I. Loshchilov, F. Hutter. Decoupled Weight Decay Regularization (AdamW).ICLR, 2019. arXiv:1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[11]
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
R. Eldan, Y. Li. TinyStories. arXiv:2305.07759, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
A. Graves. Adaptive Computation Time for Recurrent Neural Networks. arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [13]
-
[14]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer et al. Outrageously Large Neural Networks: The Sparsely-Gated MoE Layer.ICLR, 2017. arXiv:1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
D. Raposo et al. Mixture-of-Depths. arXiv:2404.02258, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
arXiv preprint arXiv:2002.04745 , year=
R. Xiong et al. On Layer Normalization in the Transformer Architecture.ICML, 2020. arXiv:2002.04745
-
[17]
J. L. Ba, J. R. Kiros, G. E. Hinton. Layer Normalization. arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
D. J. Simons, C. F. Chabris. Gorillas in Our Midst: Sustained Inattentional Blindness for Dynamic Events.Perception, 28(9):1059–1074, 1999. 6
1999
-
[19]
Kramer.The Operator’s Guide to AI Agents
K. Kramer.The Operator’s Guide to AI Agents. NeraTech LLC, 2026. (Bounded-intelligence thesis; reliability via engineered verification.)
2026
-
[20]
Reason.Human Error
J. Reason.Human Error. Cambridge University Press, 1990
1990
-
[21]
K. E. Weick, K. M. Sutcliffe.Managing the Unexpected. Jossey-Bass, 2007
2007
-
[22]
Department of Energy.Human Performance Improvement Handbook, DOE-HDBK-1028-2009, 2009
U.S. Department of Energy.Human Performance Improvement Handbook, DOE-HDBK-1028-2009, 2009. 7
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.