CRUMB: Efficient Prior Fitted Network Inference via Distributionally Matched Context Batching
Pith reviewed 2026-06-27 13:43 UTC · model grok-4.3
The pith
CRUMB enables scalable PFN inference on large tabular datasets by clustering test queries and selecting small MMD-matched training subsets for each cluster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
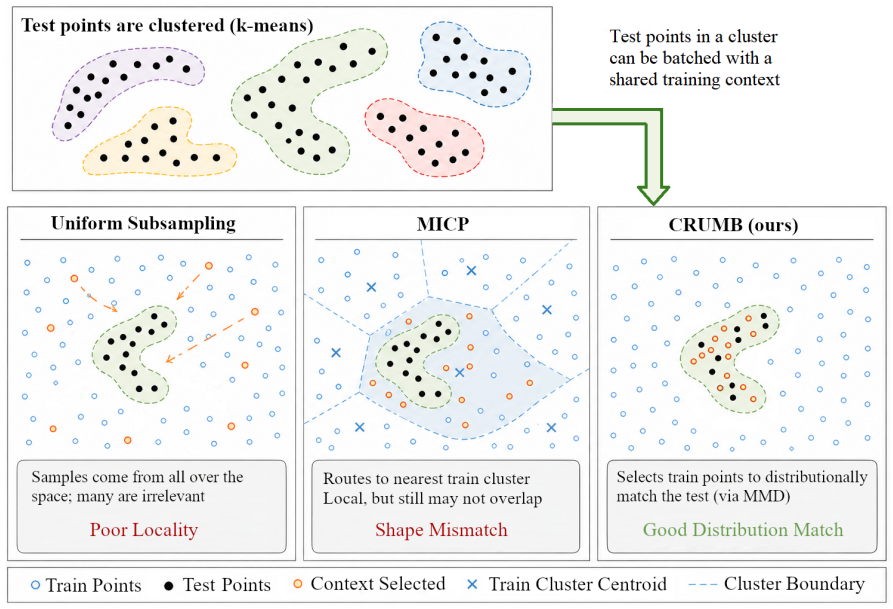
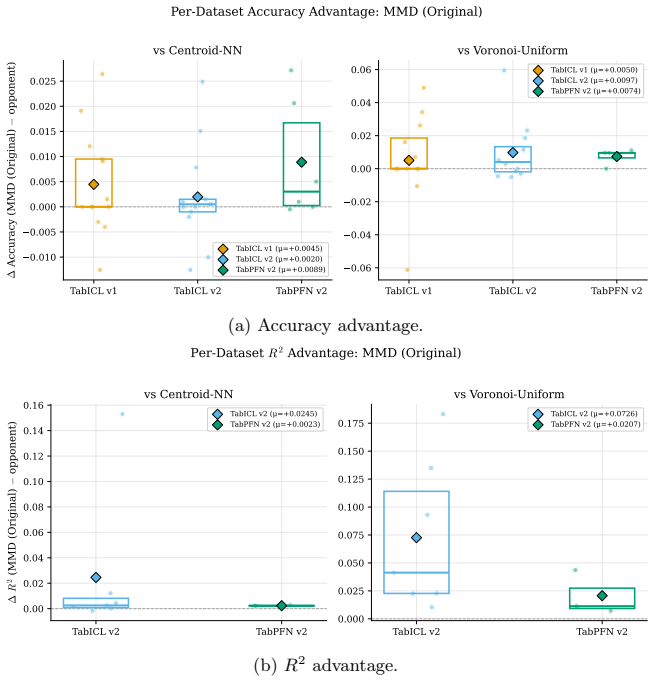
CRUMB is a three-stage inference wrapper that clusters test queries, selects a small training subset for each cluster by greedily minimising maximum mean discrepancy to the cluster, and performs exact PFN inference on the resulting reduced-context batches; evaluated on the 51-dataset TabArena benchmark across TabPFNv2, TabICLv1 and TabICLv2, the procedure outperforms comparable state-of-the-art context selection strategies and maintains accuracy under covariate drift because the MMD step aligns the supplied context distribution to each test batch.
What carries the argument
Greedy MMD-minimisation step that selects a distributionally matched training subset for each test-query cluster.
If this is right
- PFN inference becomes practical for training sets whose size would otherwise make full-context self-attention prohibitive.
- The same wrapper can be applied to any existing PFN architecture without retraining or architectural changes.
- Covariate drift between training and test data is mitigated because each selected context is explicitly matched to its test cluster.
- Inference cost scales with the number of clusters rather than the full training-set size.
Where Pith is reading between the lines
- The clustering-plus-MMD pattern could be tested on other in-context learners that also suffer quadratic attention costs.
- Replacing the greedy selection with an exact set-cover formulation might further reduce context size while preserving the same accuracy guarantee.
- Online settings could update the selected subsets incrementally as new test queries arrive rather than reclustering from scratch.
Load-bearing premise
That subsets chosen by greedy MMD minimisation will yield PFN predictions at least as accurate as the full training set or other selection heuristics.
What would settle it
On a large tabular dataset, accuracy of CRUMB falls below both full-context PFN inference and a strong non-MMD baseline when measured on held-out queries.
Figures











read the original abstract
Prior-fitted networks (PFNs) are a promising class of tabular foundation models that perform in-context learning, whereby the entire labelled training set is supplied as context, and predictions for test queries are produced in a single forward pass. However, the quadratically scaling self-attention mechanism in many PFN architectures makes inference prohibitive for very large training datasets. We propose CRUMB (Clustered Retrieval Using Minimised-MMD Batching), a three-stage inference wrapper that (i) clusters the test queries, (ii) selects a small, distributionally matched training subset for each cluster by greedily minimising the maximum mean discrepancy (MMD), and (iii) runs exact PFN inference on each reduced-context batch. CRUMB is architecture-agnostic and requires no retraining. On the 51-dataset TabArena benchmark, evaluated across three PFN architectures (TabPFNv2, TabICLv1, TabICLv2), we show that CRUMB outperforms similar state-of-the-art context selection strategies. We also show that CRUMB is resilient to covariate drift, as the MMD-minimisation step naturally helps align the training context distribution to match the current test batch distributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CRUMB, a three-stage inference-time wrapper for prior-fitted networks (PFNs) that (i) clusters test queries, (ii) greedily selects small training subsets per cluster by minimizing maximum mean discrepancy (MMD) to the test distribution, and (iii) runs exact PFN inference on the reduced contexts. It claims that this architecture-agnostic method outperforms existing context-selection baselines on the 51-dataset TabArena benchmark across TabPFNv2, TabICLv1 and TabICLv2, while also conferring resilience to covariate drift via the distributional matching step.
Significance. If the reported gains prove robust, the work would supply a practical, training-free route to scaling PFN inference beyond the quadratic cost of self-attention, thereby extending the applicability of tabular foundation models to large or drifting datasets.
major comments (2)
- [Experimental Results] Experimental Results section: the central claim of outperformance on TabArena is stated without any accompanying tables, figures, error bars, statistical tests or ablation results, rendering it impossible to verify effect sizes, significance, or sensitivity to implementation choices in the MMD procedure.
- [Method] Method section (three-stage procedure): the greedy MMD-minimization step is described only at high level; no specification of the kernel, the precise selection criterion, stopping rule, or complexity analysis is given, which directly affects the weakest assumption that the selected subsets will preserve or improve predictive accuracy relative to the full context.
minor comments (1)
- The abstract refers to 'TabICLv1, TabICLv2' without citation or expansion; full references should be supplied on first use.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We agree that both the Experimental Results and Method sections require substantial elaboration to support the claims and ensure reproducibility. We will revise the manuscript to address these points fully.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: the central claim of outperformance on TabArena is stated without any accompanying tables, figures, error bars, statistical tests or ablation results, rendering it impossible to verify effect sizes, significance, or sensitivity to implementation choices in the MMD procedure.
Authors: We acknowledge this limitation in the current manuscript. The Experimental Results section will be expanded in the revision to include full tables of performance metrics on all 51 TabArena datasets for CRUMB and the baselines across the three PFN architectures, with standard error bars, paired statistical significance tests (e.g., Wilcoxon signed-rank), and dedicated ablation studies on MMD kernel bandwidth, subset size, and clustering parameters. This will enable direct verification of effect sizes and sensitivity. revision: yes
-
Referee: [Method] Method section (three-stage procedure): the greedy MMD-minimization step is described only at high level; no specification of the kernel, the precise selection criterion, stopping rule, or complexity analysis is given, which directly affects the weakest assumption that the selected subsets will preserve or improve predictive accuracy relative to the full context.
Authors: We agree that the current high-level description is insufficient. The revised Method section will specify the MMD kernel (Gaussian RBF with median heuristic for bandwidth), the precise greedy selection procedure (iterative addition of the point that most reduces MMD until a target subset size or MMD threshold is reached), the stopping rule, and a complexity analysis (quadratic in context size per cluster). These details will be accompanied by pseudocode and a brief justification that the distributional matching preserves relevant statistics for PFN in-context learning. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes CRUMB as a three-stage inference-time wrapper (clustering test queries, greedy MMD-minimization for context subset selection, then PFN inference) that is architecture-agnostic and requires no retraining. All load-bearing claims are empirical benchmark results on the external 51-dataset TabArena suite across three PFN architectures, plus a qualitative statement on drift resilience. No equations, self-definitional reductions, fitted-input predictions, or load-bearing self-citations appear in the derivation; the method is presented as a practical wrapper whose performance is measured against independent baselines rather than being forced by internal definitions or prior author results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tabpfn: A transformer that solves small tabular classification problems in a second, 2023
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second, 2023. URLhttps://arxiv.org/abs/2207. 01848
2023
-
[2]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
2025
-
[3]
Why tabular foundation models should be a research priority.arXiv preprint arXiv:2405.01147, 2024
Boris Van Breugel and Mihaela Van Der Schaar. Why tabular foundation models should be a research priority.arXiv preprint arXiv:2405.01147, 2024
arXiv 2024
-
[4]
Catboost: unbiased boosting with categorical features, 2019
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Dorogush, and Andrey Gulin. Catboost: unbiased boosting with categorical features, 2019. URL https://arxiv.org/abs/1706. 09516
2019
-
[5]
XGBoost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 785–794. ACM, August 2016. doi: 10.1145/2939672.2939785. URLhttp://dx.doi.org/10.1145/ 2939672.2939785
-
[6]
Han-Jia Ye, Si-Yang Liu, and Wei-Lun Chao. A closer look at tabpfn v2: Understanding its strengths and extending its capabilities.arXiv preprint arXiv:2502.17361, 2025
arXiv 2025
-
[7]
Realistic evaluation of tabpfn v2 in open environments.arXiv preprint arXiv:2505.16226, 2025
Zi-Jian Cheng, Zi-Yi Jia, Zhi Zhou, Yu-Feng Li, and Lan-Zhe Guo. Realistic evaluation of tabpfn v2 in open environments.arXiv preprint arXiv:2505.16226, 2025
arXiv 2025
-
[8]
Tabflex: Scaling tabular learning to millions with linear attention, 2025
Yuchen Zeng, Tuan Dinh, Wonjun Kang, and Andreas C Mueller. Tabflex: Scaling tabular learning to millions with linear attention, 2025. URLhttps://arxiv.org/abs/2506.05584
arXiv 2025
-
[9]
Retrieval and fine-tuning for in-context tabular models, 2024
Valentin Thomas, Junwei Ma, Rasa Hosseinzadeh, Keyvan Golestan, Guangwei Yu, Maksims Volkovs, and Anthony Caterini. Retrieval and fine-tuning for in-context tabular models, 2024. URLhttps: //arxiv.org/abs/2406.05207
arXiv 2024
-
[10]
Tunetables: Context optimization for scalable prior-data fitted networks, 2024
Benjamin Feuer, Robin Tibor Schirrmeister, Valeriia Cherepanova, Chinmay Hegde, Frank Hutter, Micah Goldblum, Niv Cohen, and Colin White. Tunetables: Context optimization for scalable prior-data fitted networks, 2024. URLhttps://arxiv.org/abs/2402.11137. 11
arXiv 2024
-
[11]
Tabarena: A living benchmark for machine learning on tabular data, 2025
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. Tabarena: A living benchmark for machine learning on tabular data, 2025. URLhttps://arxiv.org/abs/2506.16791
Pith/arXiv arXiv 2025
-
[12]
Chunked tabpfn: Exact training-free in-context learning for long-context tabular data, 2025
Renat Sergazinov and Shao-An Yin. Chunked tabpfn: Exact training-free in-context learning for long-context tabular data, 2025. URLhttps://arxiv.org/abs/2509.00326
Pith/arXiv arXiv 2025
-
[13]
Tabpfn-2.5: Advancing the state of the art in tabular foundation models, 2026
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, Mihir Manium, Rosen Yu, Felix Jablonski, Shi Bin Hoo, Anurag Garg, Jake Robertson, Magnus Bühler, Vladyslav Moroshan, Lennart Purucker, Clara Cornu, Lilly Charlotte Wehrhahn, Alessandro Bonetto, Bernhard Schölk...
Pith/arXiv arXiv 2026
-
[14]
When do neural nets outperform boosted trees on tabular data? Advances in Neural Information Processing Systems, 36:76336–76369, 2023
Duncan McElfresh, Sujay Khandagale, Jonathan Valverde, Vishak Prasad C, Ganesh Ramakrishnan, Micah Goldblum, and Colin White. When do neural nets outperform boosted trees on tabular data? Advances in Neural Information Processing Systems, 36:76336–76369, 2023
2023
-
[15]
Tabicl: A tabular foundation model for in-context learning on large data, 2025
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. Tabicl: A tabular foundation model for in-context learning on large data, 2025. URLhttps://arxiv.org/abs/2502.05564
Pith/arXiv arXiv 2025
-
[16]
Tabiclv2: A better, faster, scalable, and open tabular foundation model, 2026
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. Tabiclv2: A better, faster, scalable, and open tabular foundation model, 2026. URLhttps://arxiv.org/abs/2602.11139
arXiv 2026
-
[17]
Xiyuan Zhang, Danielle C Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W Mahoney, et al. Mitra: Mixed synthetic priors for enhancing tabular foundation models.arXiv preprint arXiv:2510.21204, 2025
arXiv 2025
-
[18]
Tabpfn-wide: Continued pre-training for extreme feature counts.arXiv preprint arXiv:2510.06162, 2025
Christopher Kolberg, Jules Kreuer, Jonas Huurdeman, Sofiane Ouaari, Katharina Eggensperger, and Nico Pfeifer. Tabpfn-wide: Continued pre-training for extreme feature counts.arXiv preprint arXiv:2510.06162, 2025
arXiv 2025
-
[19]
Benjamin Feuer, Chinmay Hegde, and Niv Cohen. Scaling tabpfn: Sketching and feature selection for tabular prior-data fitted networks.arXiv preprint arXiv:2311.10609, 2023
arXiv 2023
-
[20]
Drift-resilient tabpfn: In-context learning temporal distribution shifts on tabular data.Advances in Neural Information Processing Systems, 37:98742–98781, 2024
Kai Helli, David Schnurr, Noah Hollmann, Samuel Müller, and Frank Hutter. Drift-resilient tabpfn: In-context learning temporal distribution shifts on tabular data.Advances in Neural Information Processing Systems, 37:98742–98781, 2024
2024
-
[21]
Mixture of in-context prompters for tabular pfns, 2024
Derek Xu, Olcay Cirit, Reza Asadi, Yizhou Sun, and Wei Wang. Mixture of in-context prompters for tabular pfns, 2024. URLhttps://arxiv.org/abs/2405.16156
arXiv 2024
-
[22]
In-context data distillation with tabpfn.arXiv preprint arXiv:2402.06971, 2024
Junwei Ma, Valentin Thomas, Guangwei Yu, and Anthony Caterini. In-context data distillation with tabpfn.arXiv preprint arXiv:2402.06971, 2024
arXiv 2024
-
[23]
Sha Lu, Jixue Liu, Stefan Peters, Thuc Duy Le, Craig Xie, Lin Liu, and Jiuyong Li. ulead-tabpfn: Uncertainty-aware dependency-based anomaly detection with tabpfn.arXiv preprint arXiv:2604.20255, 2026
Pith/arXiv arXiv 2026
-
[24]
Borgwardt, Malte J
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.J. Mach. Learn. Res., 13(null):723–773, March 2012. ISSN 1532-4435
2012
-
[25]
Improving predictive inference under covariate shift by weighting the log- likelihood function.Journal of Statistical Planning and Inference, 90:227–244, 2000
Hidetoshi Shimodaira. Improving predictive inference under covariate shift by weighting the log- likelihood function.Journal of Statistical Planning and Inference, 90:227–244, 2000. URL https: //api.semanticscholar.org/CorpusID:286122993
2000
-
[26]
A scalable approach to covariate and concept drift management via adaptive data segmentation
Vennela Yarabolu, Govind Waghmare, Sonia Gupta, and Siddhartha Asthana. A scalable approach to covariate and concept drift management via adaptive data segmentation. InProceedings of the 8th International Conference on Data Science and Management of Data (12th ACM IKDD CODS and 30th COMAD), CODS-COMAD Dec ’24, page 84–92. ACM, December 2024. doi: 10.1145/...
-
[27]
Stuart P. Lloyd. Least squares quantization in pcm.IEEE Trans. Inf. Theory, 28:129–136, 1982. URL https://api.semanticscholar.org/CorpusID:10833328
1982
-
[28]
K-means++: The advantages of careful seeding
David Arthur and Sergei Vassilvitskii. K-means++: The advantages of careful seeding. volume 8, pages 1027–1035, 01 2007. doi: 10.1145/1283383.1283494
-
[29]
Optimally-weighted herding is bayesian quadrature, 2016
Ferenc Huszár and David Duvenaud. Optimally-weighted herding is bayesian quadrature, 2016. URL https://arxiv.org/abs/1204.1664
Pith/arXiv arXiv 2016
-
[30]
Super-samples from kernel herding, 2012
Yutian Chen, Max Welling, and Alex Smola. Super-samples from kernel herding, 2012. URLhttps: //arxiv.org/abs/1203.3472
Pith/arXiv arXiv 2012
-
[31]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. In J. Platt, D. Koller, Y. Singer, and S. Roweis, editors,Advances in Neural Information Processing Systems, volume 20. Curran Associates, Inc., 2007. URL https://proceedings.neurips.cc/paper_files/paper/2007/ file/013a006f03dbc5392effeb8f18fda755-Paper.pdf
2007
-
[32]
Daniel Whiteson. HIGGS. UCI Machine Learning Repository, 2014. DOI: https://doi.org/10.24432/C5V312
-
[33]
Five balltree construction algorithms
Stephen M Omohundro. Five balltree construction algorithms. 1989
1989
-
[34]
A survey on nearest neighbor search methods.International Journal of Computer Applications, 95(25), 2014
Mohammad Reza Abbasifard, Bijan Ghahremani, and Hassan Naderi. A survey on nearest neighbor search methods.International Journal of Computer Applications, 95(25), 2014. 13 A Experimental Details A.1 Models We evaluate three PFN architectures, all loaded from publicly released checkpoints without modification: • TabPFNv2.12-layer, 6-head transformer (d=192...
2014
-
[35]
Greedy kernel herding that iteratively selects the training point minimising the empirical MMD between the growing context set and the test cluster (Algorithm 1)
MMD herding(default). Greedy kernel herding that iteratively selects the training point minimising the empirical MMD between the growing context set and the test cluster (Algorithm 1)
-
[36]
This mirrors the routing mechanism of MICP, but applied to test-side rather than train-side clusters
Centroid-NN.Select the n training points nearest (inℓ2) to the test-cluster centroid. This mirrors the routing mechanism of MICP, but applied to test-side rather than train-side clusters
-
[37]
typical cost
Voronoi-Uniform.The K test-cluster centroids induce a Voronoi partition of the training set: each training point is assigned to its nearest centroid. For clusterk, we then uniformly subsamplen points from the Voronoi cellVk = {xi ∈ D train : k = arg minj∥xi −c j∥}. This guarantees that the selected context lies in the same region of feature space as the t...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.