Optimizing Visual Generative Models via Distribution-wise Rewards
Pith reviewed 2026-07-03 16:37 UTC · model grok-4.3
The pith
Distribution-wise rewards in reinforcement learning allow finetuning of visual generative models to improve quality without losing diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By employing distribution-wise rewards instead of sample-wise ones, along with a subset-replace strategy for efficient computation and reinforcement learning for post-hoc model merging, the method aligns generated samples more closely with real data distributions, resulting in lower FID-50K values and preserved diversity.
What carries the argument
distribution-wise reward that accounts for the overall data distribution of generated samples to guide optimization
If this is right
- Significant improvements in FID-50K metrics, such as from 8.30 to 5.77 for SiT and 3.74 to 3.52 for EDM2
- Enhanced perceptual quality in generated images
- Preservation of sample diversity compared to conventional methods
- Potential reduction in train-inference inconsistency through optimized model merging
Where Pith is reading between the lines
- This could extend to reducing computational costs in other distribution-based evaluation settings
- May suggest similar distribution-focused rewards for reinforcement learning in non-visual generative tasks
- Implies that post-training optimization of merging can serve as a general fix for stochastic training issues
Load-bearing premise
The subset-replace strategy provides accurate distribution-wise reward signals without new biases or loss of mode collapse mitigation.
What would settle it
If experiments on SiT or EDM2 show no FID improvement or reduced diversity after applying the distribution-wise reward method.
Figures






read the original abstract
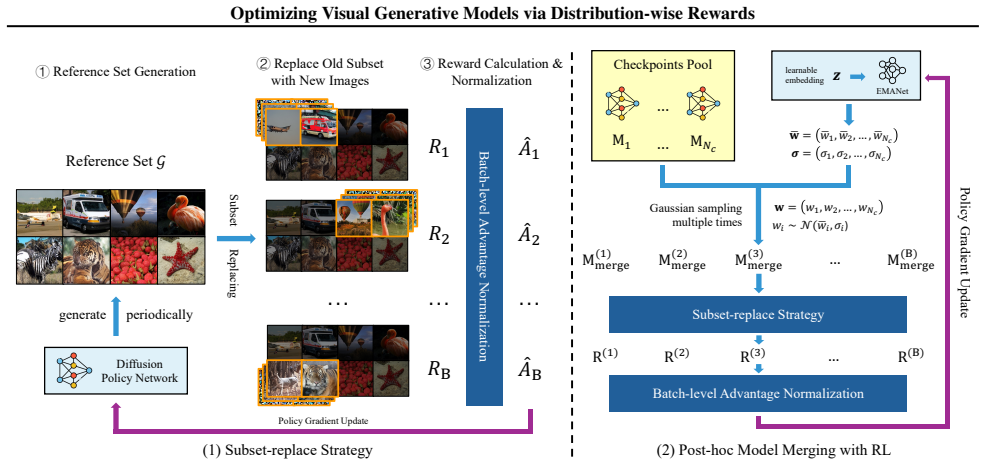
Conventional reinforcement learning strategies for visual generation typically employ sample-wise reward functions, yet this practice frequently results in reward hacking that degrades image diversity and introduces visual anomalies. To address these limitations, we present a novel framework that finetunes generative models using distribution-wise rewards, ensuring better alignment with real-world data distributions. Unlike rewards that evaluate samples individually, distribution-wise reward accounts for the data distribution of the samples, mitigating the mode collapse problem that occurs when all samples optimize towards the same direction independently. To overcome the prohibitive computational cost of estimating these rewards, we introduce a subset-replace strategy that efficiently provides reward signals by updating only a small subset of a generated reference set. Additionally, we apply RL to optimize post-hoc model merging coefficients, potentially mitigating the train-inference inconsistency caused by introducing stochastic differential equation (SDE) in regular RL practices. Extensive experiments show our approach significantly improves FID-50K across various base models, from 8.30 to 5.77 for SiT and from 3.74 to 3.52 for EDM2. Qualitative evaluation also confirms that our method enhances perceptual quality while preserving sample diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for fine-tuning visual generative models with distribution-wise rewards (instead of sample-wise rewards) to reduce reward hacking, mode collapse, and visual anomalies. It introduces a subset-replace strategy to efficiently approximate these rewards by updating only a small subset of a generated reference set, and applies RL to optimize post-hoc model merging coefficients to mitigate train-inference inconsistency from SDE. Experiments claim FID-50K reductions from 8.30 to 5.77 on SiT and from 3.74 to 3.52 on EDM2, plus qualitative gains in perceptual quality while preserving diversity.
Significance. If the subset-replace strategy is shown to yield unbiased distribution-wise reward estimates and the experimental claims are supported by rigorous verification, the approach could meaningfully advance RL-based fine-tuning of generative models by addressing distribution-level alignment and mode collapse. The post-hoc merging optimization is a potentially useful addition for practical deployment.
major comments (2)
- [Methods section (subset-replace strategy)] Methods section (subset-replace strategy): The central claim requires that the subset-replace strategy yields reward signals whose expectation matches the true distribution distance without selection bias or correlation that could re-enable mode collapse. No analysis, proof, or empirical check is supplied that the replacement rule preserves the necessary statistical properties; if approximation error correlates with generation quality, the RL updates optimize a distorted objective.
- [Experiments section] Experiments section: The reported FID improvements (e.g., 8.30→5.77 for SiT) are presented without error bars, ablation studies on subset size or replacement frequency, or verification that distribution-wise rewards were actually computed as claimed. This leaves the quantitative support for the central claims unverified.
minor comments (1)
- [Abstract] Abstract: 'finetunes' should be hyphenated as 'fine-tunes' for consistency with standard usage.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address the major comments point by point below and will revise the paper to incorporate additional analysis and experimental verification.
read point-by-point responses
-
Referee: [Methods section (subset-replace strategy)] Methods section (subset-replace strategy): The central claim requires that the subset-replace strategy yields reward signals whose expectation matches the true distribution distance without selection bias or correlation that could re-enable mode collapse. No analysis, proof, or empirical check is supplied that the replacement rule preserves the necessary statistical properties; if approximation error correlates with generation quality, the RL updates optimize a distorted objective.
Authors: We acknowledge that the submitted manuscript does not contain a formal proof or empirical verification of the statistical properties of the subset-replace strategy. The approach relies on updating a small random subset of the reference set to approximate the distribution-wise reward efficiently. In the revision we will add a dedicated subsection with a proof sketch showing that, under uniform random replacement, the expected value of the approximated reward equals the true distribution distance, together with empirical checks that measure correlation between approximation error and sample quality to confirm the RL objective is not distorted. revision: yes
-
Referee: [Experiments section] Experiments section: The reported FID improvements (e.g., 8.30→5.77 for SiT) are presented without error bars, ablation studies on subset size or replacement frequency, or verification that distribution-wise rewards were actually computed as claimed. This leaves the quantitative support for the central claims unverified.
Authors: We agree that the experimental results would be more convincing with additional statistical controls. The revised manuscript will report FID scores with error bars computed over multiple independent runs, include ablations on subset size and replacement frequency, and provide explicit verification (including pseudocode and timing measurements) that the distribution-wise rewards were computed exactly as described in the methods section using the maintained reference set. revision: yes
Circularity Check
No circularity: experimental results, no derivations or self-referential predictions
full rationale
The paper's central claims rest on experimental FID improvements (e.g., 8.30 to 5.77 for SiT) obtained via a subset-replace strategy for distribution-wise rewards and post-hoc RL merging. No equations, derivations, or fitted parameters are presented that reduce any 'prediction' to the inputs by construction. The subset-replace is described as an efficiency approximation whose statistical properties are asserted but not derived from prior self-citations in a load-bearing way. Results are framed as empirical outcomes rather than self-defined quantities, making the work self-contained against external benchmarks like FID-50K.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Concrete Problems in AI Safety
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schul- man, J., and Man ´e, D. Concrete problems in ai safety. arXiv preprint arXiv:1606.06565,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Balaji, Y ., Nah, S., Huang, X., Vahdat, A., Song, J., Zhang, Q., Kreis, K., Aittala, M., Aila, T., Laine, S., et al. ediff- i: Text-to-image diffusion models with an ensemble of expert denoisers.arXiv preprint arXiv:2211.01324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Barratt, S. and Sharma, R. A note on the inception score. arXiv preprint arXiv:1801.01973,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training Diffusion Models with Reinforcement Learning
Black, K., Janner, M., Du, Y ., Kostrikov, I., and Levine, S. Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Cai, Y ., Liu, S., Tian, C., and Xie, L. Fr\’{e} chet power- scenario distance: A metric for evaluating generative ai models across multiple time-scales in smart grids.arXiv preprint arXiv:2505.08082,
-
[6]
Reinforcement Learning with a Corrupted Reward Channel
Everitt, T., Krakovna, V ., Orseau, L., Hutter, M., and Legg, S. Reinforcement learning with a corrupted reward chan- nel.arXiv preprint arXiv:1705.08417,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Fan, Y . and Lee, K. Optimizing ddpm sampling with short- cut fine-tuning.arXiv preprint arXiv:2301.13362,
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Improved noise schedule for diffusion training.arXiv preprint arXiv:2407.03297,
Hang, T., Gu, S., Geng, X., and Guo, B. Improved noise schedule for diffusion training.arXiv preprint arXiv:2407.03297,
-
[10]
TempFlow-GRPO: When Timing Matters for GRPO in Flow Models
He, X., Fu, S., Zhao, Y ., Li, W., Yang, J., Yin, D., Rao, F., and Zhang, B. Tempflow-grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Hessel, J., Holtzman, A., Forbes, M., Bras, R. L., and Choi, Y . Clipscore: A reference-free evaluation metric for im- age captioning.arXiv preprint arXiv:2104.08718,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Hu, J. Reinforce++: A simple and efficient approach for aligning large language models.arXiv preprint arXiv:2501.03262,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Blue noise for diffusion mod- els
Huang, X., Salaun, C., Vasconcelos, C., Theobalt, C., Oztireli, C., and Singh, G. Blue noise for diffusion mod- els. InACM SIGGRAPH 2024 conference papers, pp. 1–11,
2024
-
[14]
Editing Models with Task Arithmetic
Ilharco, G., Ribeiro, M. T., Wortsman, M., Gururangan, S., Schmidt, L., Hajishirzi, H., and Farhadi, A. Editing mod- els with task arithmetic.arXiv preprint arXiv:2212.04089,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D., and Wilson, A. G. Averaging weights leads to wider optima and better generalization.arXiv preprint arXiv:1803.05407,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Lee, K., Liu, H., Ryu, M., Watkins, O., Du, Y ., Boutilier, C., Abbeel, P., Ghavamzadeh, M., and Gu, S. S. Aligning text- to-image models using human feedback.arXiv preprint arXiv:2302.12192,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Li, J., Cui, Y ., Huang, T., Ma, Y ., Fan, C., Yang, M., and Zhong, Z. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025a. Li, T., Huang, Z., Tao, Q., Wu, Y ., and Huang, X. Trainable weight averaging: Efficient training by optimizing histor- ical solutions. InThe Eleventh International Conference on Le...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Model merging in pre-training of large language models.arXiv preprint arXiv:2505.12082, 2025b
Li, Y ., Ma, Y ., Yan, S., Zhang, C., Liu, J., Lu, J., Xu, Z., Chen, M., Wang, M., Zhan, S., et al. Model merging in pre-training of large language models.arXiv preprint arXiv:2505.12082, 2025b. 10 Optimizing Visual Generative Models via Distribution-wise Rewards Liang, Z., Yuan, Y ., Gu, S., Chen, B., Hang, T., Cheng, M., Li, J., and Zheng, L. Aesthetic ...
-
[19]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Checkpoint merging via bayesian optimization in llm pretraining.arXiv preprint arXiv:2403.19390,
Liu, D., Wang, Z., Wang, B., Chen, W., Li, C., Tu, Z., Chu, D., Li, B., and Sui, D. Checkpoint merging via bayesian optimization in llm pretraining.arXiv preprint arXiv:2403.19390,
-
[21]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y ., Liu, J., Wang, X., Wan, P., Zhang, D., and Ouyang, W. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Ma, N., Tong, S., Jia, H., Hu, H., Su, Y .-C., Zhang, M., Yang, X., Li, Y ., Jaakkola, T., Jia, X., et al. Inference-time scaling for diffusion models beyond scaling denoising steps.arXiv preprint arXiv:2501.09732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Morales-Brotons, D., V ogels, T., and Hendrikx, H. Ex- ponential moving average of weights in deep learning: Dynamics and benefits.arXiv preprint arXiv:2411.18704,
-
[25]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El- Nouby, A., et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Sanyal, S., Neerkaje, A., Kaddour, J., Kumar, A., and Sang- havi, S. Early weight averaging meets high learning rates for llm pre-training.arXiv preprint arXiv:2306.03241,
-
[27]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[30]
Tian, C., Wang, J., Zhao, Q., Chen, K., Liu, J., Liu, Z., Mao, J., Zhao, W. X., Zhang, Z., and Zhou, J. Wsm: Decay- free learning rate schedule via checkpoint merging for llm pre-training.arXiv preprint arXiv:2507.17634,
-
[31]
11 Optimizing Visual Generative Models via Distribution-wise Rewards Tong, C., Guo, Z., Zhang, R., Shan, W., Wei, X., Xing, Z., Li, H., and Heng, P.-A. Delving into rl for image generation with cot: A study on dpo vs. grpo.arXiv preprint arXiv:2505.17017,
-
[32]
Wang, F. and Yu, Z. Coefficients-preserving sampling for re- inforcement learning with flow matching.arXiv preprint arXiv:2509.05952,
-
[33]
Unified Reward Model for Multimodal Understanding and Generation
Wang, Y ., Zang, Y ., Li, H., Jin, C., and Wang, J. Unified re- ward model for multimodal understanding and generation. arXiv preprint arXiv:2503.05236,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Wen, J., Zhong, R., Khan, A., Perez, E., Steinhardt, J., Huang, M., Bowman, S. R., He, H., and Feng, S. Lan- guage models learn to mislead humans via rlhf.arXiv preprint arXiv:2409.12822,
-
[35]
URL https://lilianweng.github.io/posts/ 2024-11-28-reward-hacking/. Wu, X., Hao, Y ., Sun, K., Chen, Y ., Zhu, F., Zhao, R., and Li, H. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341, 2023a. Wu, X., Sun, K., Zhu, F., Zhao, R., and Li, H. Human preference score: Bett...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
DanceGRPO: Unleashing GRPO on Visual Generation
Xue, Z., Wu, J., Gao, Y ., Kong, F., Zhu, L., Chen, M., Liu, Z., Liu, W., Guo, Q., Huang, W., et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Baichuan 2: Open Large-scale Language Models
Yang, A., Xiao, B., Wang, B., Zhang, B., Bian, C., Yin, C., Lv, C., Pan, D., Wang, D., Yan, D., et al. Baichuan 2: Open large-scale language models.arXiv preprint arXiv:2309.10305,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Yu, L., Yu, B., Yu, H., Huang, F., and Li, Y . Language models are super mario: Absorbing abilities from homol- ogous models as a free lunch. InForty-first International Conference on Machine Learning, 2024a. Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., and Xie, S. Representation alignment for generation: Training diffusion transformers is ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:2406.11385 , year=
Zhou, Y ., Song, L., Wang, B., and Chen, W. Metagpt: Merging large language models using model exclusive task arithmetic.arXiv preprint arXiv:2406.11385,
-
[40]
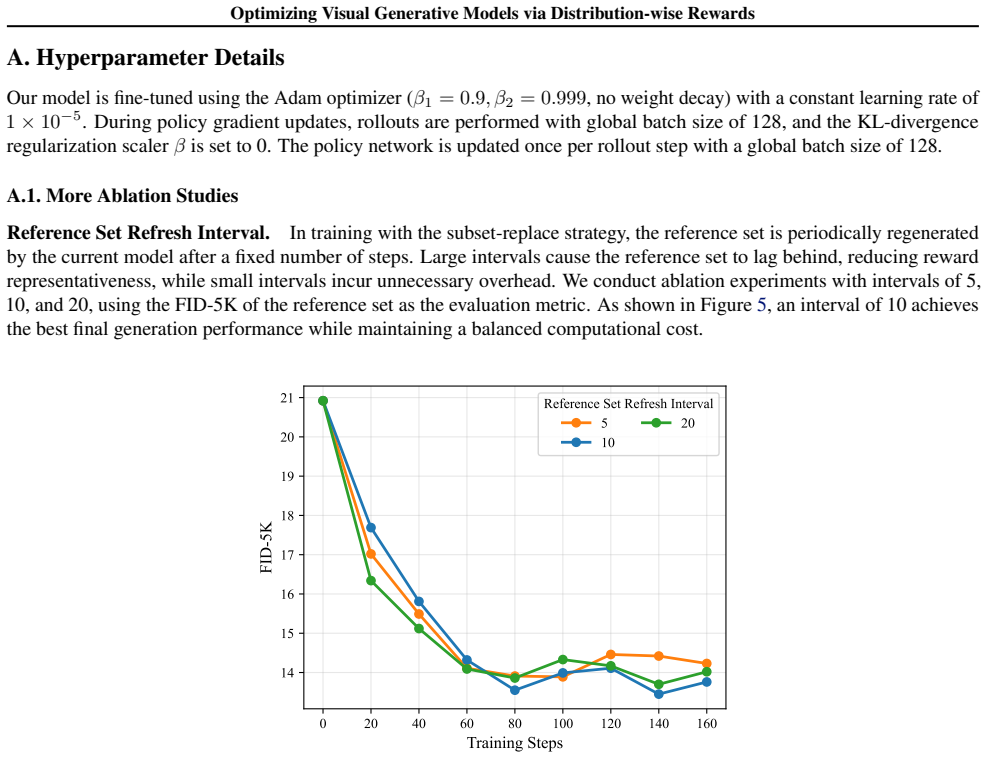
A.1. More Ablation Studies Reference Set Refresh Interval.In training with the subset-replace strategy, the reference set is periodically regenerated by the current model after a fixed number of steps. Large intervals cause the reference set to lag behind, reducing reward representativeness, while small intervals incur unnecessary overhead. We conduct abl...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.