Narrative Knowledge Weaver: Narrative-Centric Retrieval-Augmented Reasoning for Long-Form Text Understanding
Pith reviewed 2026-06-28 02:14 UTC · model grok-4.3
The pith
Narrative Knowledge Weaver aligns textual evidence with facts, graphs, profiles, interactions, episodes, and storylines to improve reasoning over evolving story worlds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
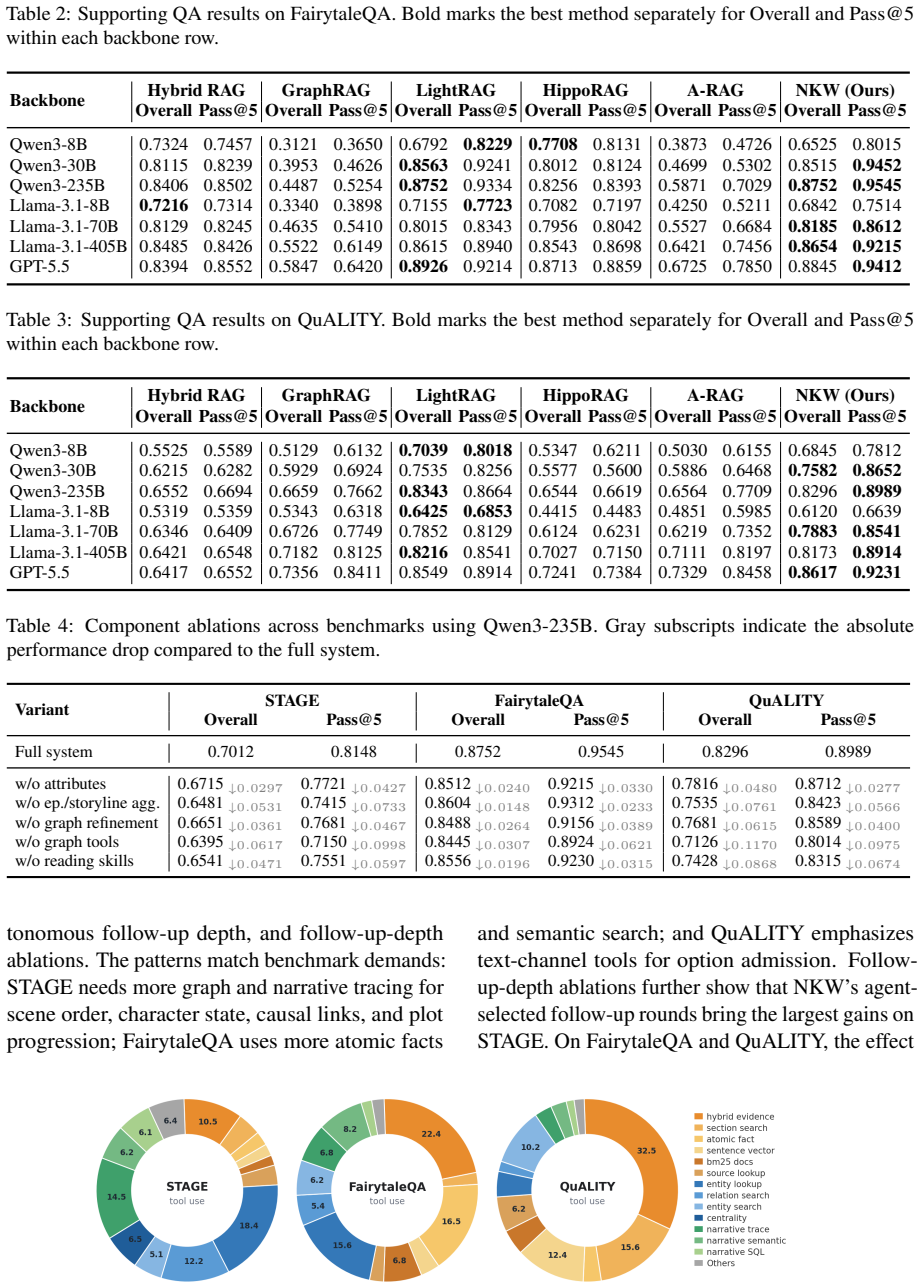
Narrative Knowledge Weaver is a source-grounded framework that aligns textual evidence, atomic facts, canonical graph structure, entity profiles, interactions, episodes, and storylines. At query time, NKW uses text, graph, and narrative tools with post-retrieval reading skills to assemble evidence and audit actor, scope, polarity, state, and temporal constraints. Across STAGE, FairytaleQA, and QuALITY, NKW is strongest on screenplay-level story-world QA while remaining competitive on more passage-centered benchmarks. Ablations, question-type analyses, graph-asset statistics, and case studies show complementary benefits for character, scene, temporal, causal, and narrative-progression reasoni
What carries the argument
The Narrative Knowledge Weaver framework, which aligns multiple evidence layers and applies constraint-auditing tools during retrieval to capture how evidence functions in a narrative.
If this is right
- Strongest performance appears on screenplay-level story-world QA tasks that track multiple evolving elements.
- Competitive results hold on passage-centered benchmarks that rely less on narrative dynamics.
- Ablations indicate complementary gains for character, scene, temporal, causal, and narrative-progression reasoning.
- Graph-asset statistics provide measurable support for the aligned evidence structure.
Where Pith is reading between the lines
- The layered alignment approach might apply to other domains with evolving evidence, such as legal case files or medical histories.
- Constraint auditing could reduce errors when models must track state changes across long documents outside fiction.
- Testing the framework on datasets with explicit temporal or causal structures would show whether the benefits generalize beyond the reported benchmarks.
Load-bearing premise
Aligning textual evidence, atomic facts, graph structures, entity profiles, interactions, episodes, and storylines plus auditing actor, scope, polarity, state, and temporal constraints will reliably capture how evidence functions inside a narrative.
What would settle it
A new screenplay-style benchmark where NKW shows no advantage over standard retrieval-augmented methods on questions that require tracking evolving character states, causal chains, and temporal positions.
Figures

read the original abstract
Long-form narrative QA requires reasoning over evolving story worlds rather than isolated passages: answers may depend on earlier goals, changing character states, social relations, causal triggers, temporal position, and later consequences. Existing retrieval and graph-augmented generation methods improve evidence access, but their units--chunks, entities, relations, summaries, or tool actions--do not directly encode how evidence functions in a story. We introduce Narrative Knowledge Weaver(NKW), a source-grounded framework that aligns textual evidence, atomic facts, canonical graph structure, entity profiles, interactions, episodes, and storylines. At query time, NKW uses text, graph, and narrative tools with post-retrieval reading skills to assemble evidence and audit actor, scope, polarity, state, and temporal constraints. Across STAGE, FairytaleQA, and QuALITY, NKW is strongest on screenplay-level story-world QA while remaining competitive on more passage-centered benchmarks. Ablations, question-type analyses, graph-asset statistics, and case studies show complementary benefits for character, scene, temporal, causal, and narrative-progression reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Narrative Knowledge Weaver (NKW), a source-grounded framework for long-form narrative QA. It aligns textual evidence, atomic facts, canonical graph structure, entity profiles, interactions, episodes, and storylines, then applies text/graph/narrative tools with post-retrieval auditing of actor/scope/polarity/state/temporal constraints to model evidence function in evolving story worlds. Experiments across STAGE, FairytaleQA, and QuALITY report strongest results on screenplay-level story-world QA while remaining competitive on passage-centered benchmarks, with ablations, question-type analyses, graph statistics, and case studies cited as supporting evidence.
Significance. If the performance differences prove robust and attributable to the narrative-centric alignment and auditing rather than retrieval volume or dataset artifacts, the work could advance RAG methods by providing explicit machinery for story-world dynamics (state changes, causal triggers, temporal position). The inclusion of ablations and case studies would strengthen claims about complementary benefits for character, scene, temporal, causal, and progression reasoning.
major comments (2)
- [Abstract, paragraph 2] Abstract, paragraph 2: The claim that multi-layer alignment plus constraint auditing 'reliably capture how evidence functions inside a narrative' is load-bearing for the central contribution, yet the description provides no concrete mechanism for conflict resolution across layers (textual evidence vs. graph vs. profiles vs. episodes) or for how the auditing step alters downstream reasoning outputs; without this, gains on screenplay QA could stem from other factors.
- [Abstract] Abstract: No experimental details, ablation tables, dataset statistics, error bars, or graph-asset numbers are visible, preventing verification that reported performance differences support the narrative-centric design over prior chunk/entity/relation methods or rule out dataset bias.
Simulated Author's Rebuttal
We appreciate the referee's comments and provide point-by-point responses below. We are prepared to make revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, paragraph 2] Abstract, paragraph 2: The claim that multi-layer alignment plus constraint auditing 'reliably capture how evidence functions inside a narrative' is load-bearing for the central contribution, yet the description provides no concrete mechanism for conflict resolution across layers (textual evidence vs. graph vs. profiles vs. episodes) or for how the auditing step alters downstream reasoning outputs; without this, gains on screenplay QA could stem from other factors.
Authors: We thank the referee for highlighting this. The abstract condenses the framework description. The full paper details the mechanisms for multi-layer alignment, including conflict resolution across textual, graph, and narrative layers via the tool-based assembly and constraint auditing, as well as how auditing affects reasoning by enforcing consistency checks. To address the concern, we will revise the abstract to provide a more concrete, albeit brief, indication of these processes. revision: yes
-
Referee: [Abstract] Abstract: No experimental details, ablation tables, dataset statistics, error bars, or graph-asset numbers are visible, preventing verification that reported performance differences support the narrative-centric design over prior chunk/entity/relation methods or rule out dataset bias.
Authors: Abstracts have strict length constraints and standardly focus on high-level claims rather than detailed experimental data, which are instead reported in the body of the paper, including ablation studies, dataset statistics, error bars, and graph asset numbers. These elements allow readers to assess the robustness of the performance differences and the role of the narrative-centric design. We do not plan to expand the abstract with such details. revision: no
Circularity Check
No circularity: empirical system description with no load-bearing derivations or self-referential reductions
full rationale
The provided abstract and manuscript excerpt describe an empirical framework (NKW) that aligns multiple narrative layers and applies post-retrieval auditing, then reports benchmark performance. No equations, parameter-fitting steps, uniqueness theorems, or self-citations appear in the text. The central claims rest on system design choices and observed results rather than any quantity that reduces by construction to its own inputs. This is the most common honest finding for a retrieval-augmented QA paper whose contribution is architectural and experimental.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang
Constructing inferences during narrative text comprehension.Psychological Review, 101(3):371– 395. Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2025. LightRAG: Simple and fast retrieval- augmented generation. InFindings of the Associa- tion for Computational Linguistics: EMNLP 2025, pages 10746–10761. Association for Computational Linguistic...
arXiv 2025
-
[2]
Tom Trabasso and Paul van den Broek
STAGE: A full-screenplay benchmark for reasoning over evolving stories.arXiv preprint arXiv:2601.08510. Tom Trabasso and Paul van den Broek. 1985. Causal thinking and the representation of narrative events. Journal of Memory and Language, 24(5):612–630. Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2023. Interleaving retrieva...
Pith/arXiv arXiv 1985
-
[3]
InProceedings of the 60th Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 447–460, Dublin, Ireland
Fantastic questions and where to find them: FairytaleQA – an authentic dataset for narrative com- prehension. InProceedings of the 60th Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 447–460, Dublin, Ireland. Association for Computational Linguistics. Yuan Yao, Deming Ye, Peng Li, Xu Han, Yankai Lin, Zheng...
2019
-
[4]
Query decomposition.The evaluation wrap- per submits the question, document identifier, answer format, and retrieval budget to NKW. The query is decomposed into retrieval intents over canonical entities, relations, atomic facts, and narrative units, so the first evidence pass can address both local factual grounding and higher-level narrative context
-
[5]
In the query-time tool taxonomy, this step con- sists of: entity_search;entity_lookup; relation_search;atomic_fact_search; narrative_semantic_search
Forced graph–fact and narrative recall.Be- fore the tool agent starts, NKW runs a manda- tory first-pass recall step over the canonical graph, atomic facts, and semantic narrative units. In the query-time tool taxonomy, this step con- sists of: entity_search;entity_lookup; relation_search;atomic_fact_search; narrative_semantic_search. This mandatory step ...
-
[6]
These assembly and indexing steps are not counted as separate tool calls
Candidate evidence assembly.The system enriches retrieved entities with attributes and query-relevant atomic facts, keeps relation can- didates from both entity- and relation-centered retrieval, attaches available source-text evi- dence through provenance indices, and prepares source chunks for grounding. These assembly and indexing steps are not counted ...
-
[7]
Each round scores the cur- rent packet, optionally builds a pruned packet, checks answerability, and stops without tool calls when the packet is already answerable
Tool-agent refinement.The tool agent is in- serted after first-pass retrieval and before final prompt construction. Each round scores the cur- rent packet, optionally builds a pruned packet, checks answerability, and stops without tool calls when the packet is already answerable. Otherwise, it plans at most five tool calls for the current evidence gaps. T...
-
[8]
Dynamic packing then con- structs the final prompt sections for entities, re- lations, narrative items, source text chunks, op- tional tool-text evidence, and references
Evidence-board construction.Returned tool evidence can add entities, relations, narrative items, or compact tool-text evidence, subject to channel-specific edit switches and added- evidence budgets. Dynamic packing then con- structs the final prompt sections for entities, re- lations, narrative items, source text chunks, op- tional tool-text evidence, and...
-
[9]
is_correct
Reading-skill selection and finalization.Read- ing skills are selected after retrieval and pack- ing, with at most three skills injected into the final prompt. They do not retrieve new evi- dence; they instruct the final reader how to com- pare the assembled packet for option admission, 14 causal/quest reasoning, character mental state, theme or implicati...
1990
-
[10]
, and Krippendorff’sαis α= 1− Do De . Because α measures how much the annotators agree beyond what would be expected by random labeling, it is well suited for evaluating the reliabil- ity of repeated stochastic LLM judgments. Table B.1: Internal agreement of the correctness evalua- tor across five independent judgments. Pairwise agree- ment is averaged ov...
arXiv 1988
-
[11]
is_continuity
(173 scenes), naive all-pairs checking would require 173×172/2 pairwise decisions, whereas our entity-based filtering produces on the order of 1,500–2,000 candidates. The agent can further tighten this set by incorporating additional priors such as semantic similarity between scene summaries and constraints on script-order distance (e.g., only considering...
-
[12]
Whether every neighboring scene pair has explicit source-grounded support
-
[13]
Whether the chain depends on a weak bridge scene that should be split
-
[14]
Whether shared entities, locations, objects, and occasions remain compatible across the chain
-
[15]
Whether any source-grounded fact contradicts reuse of the same setup
-
[16]
coherence_score
Whether the chain is redundant, over-extended, or should be merged with another chain. Return JSON fields: { "coherence_score": 0.0-1.0, "confidence": 0.0-1.0, "decision": "keep" | "split" | "drop", "weak_edges": [ ["scene_A", "scene_B"] ], "suggested_splits": [ ["scene_A", "scene_B"], ["scene_C"] ], "rationale": "brief rationale" } D.2 Character State Tr...
-
[17]
Timeline Swimlane View.A global character–scene matrixshowing all characters (rows) across all scenes (columns). This view of- fers a high-level visualization of appearance fre- quency, co-occurrence structure, and participa- 25 Figure D.1:Timeline Swimlane View.A screenplay-wide character–scene matrix enabling global inspection of appearance patterns. ti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.