EurekAgent: Agent Environment Engineering is All You Need For Autonomous Scientific Discovery
Pith reviewed 2026-06-27 06:33 UTC · model grok-4.3
The pith
By engineering the agent environment along four dimensions, LLM agents reach new state-of-the-art results on math, kernel, and ML tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
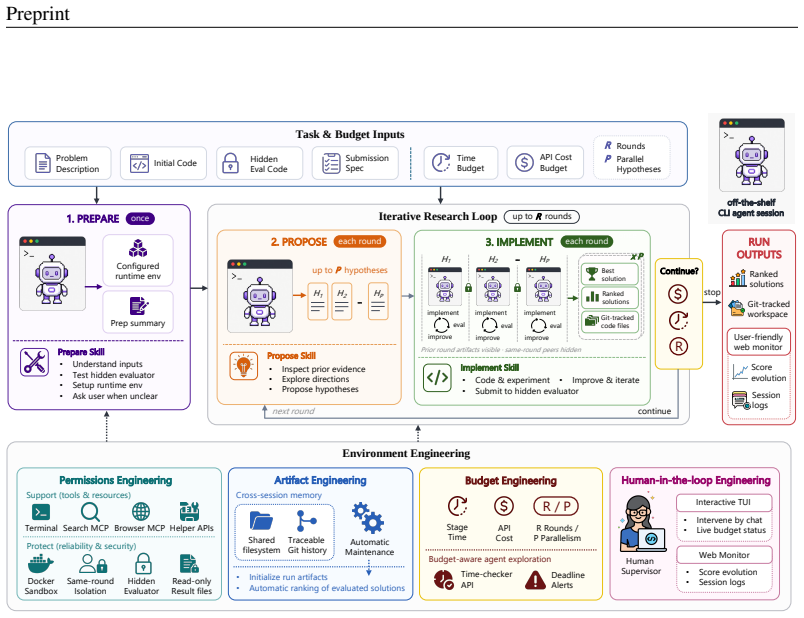
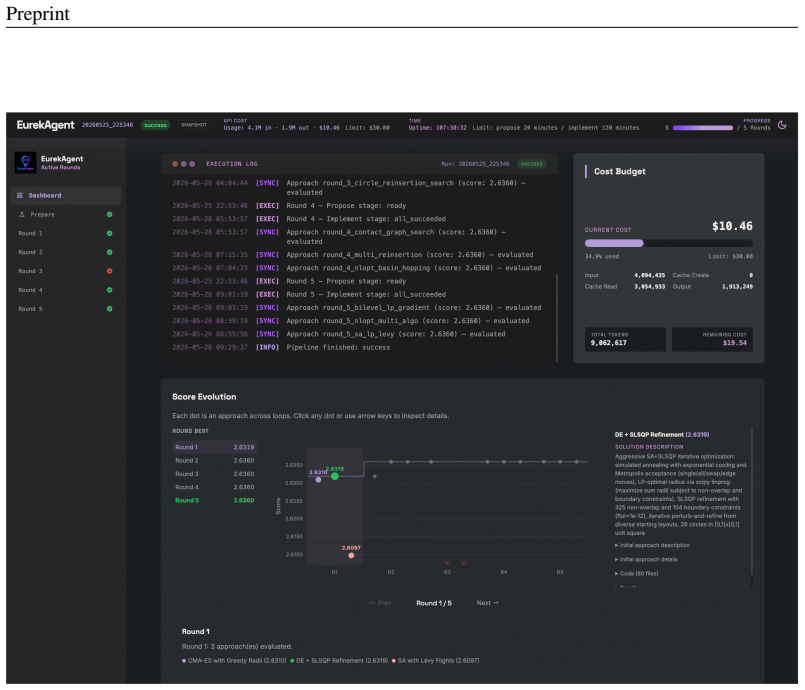
EurekAgent engineers its operating environment along four dimensions: permissions engineering for bounded execution and isolated evaluation, artifact engineering via filesystems and Git-based collaboration, budget engineering for cost-aware exploration, and human-in-the-loop engineering for easy supervision. This produces new state-of-the-art results on mathematics, kernel engineering, and machine learning tasks, including a new optimum for 26-circle packing discovered for less than eleven dollars in total API cost.
What carries the argument
Four-dimensional environment engineering (permissions, artifacts, budget, human-in-the-loop) that amplifies productive behaviors such as open-ended exploration and collaboration while suppressing reward hacking and high-friction oversight.
If this is right
- Agents reach new best-known results on circle-packing problems.
- Complex math discoveries can be completed for under eleven dollars in API cost.
- The same environment controls improve outcomes on kernel engineering and machine learning benchmarks.
- Research attention moves from prescribing agent workflows to designing supporting environments.
Where Pith is reading between the lines
- The same four controls could be tested on non-scientific tasks such as code refactoring or experimental design in chemistry.
- Removing any one dimension and measuring the drop in performance would show which controls matter most.
- Pairing the environment with stronger base models should further reduce the cost per discovery.
Load-bearing premise
That shaping permissions, artifacts, budgets, and human oversight is enough by itself to make agents reliably productive without extra workflow rules or domain tuning.
What would settle it
Running EurekAgent on a new optimization task where it fails to match or beat prior agent or human results while staying under the claimed budget.
Figures


read the original abstract
LLM-based agents have shown increasing potential in automating scientific discovery. Given an optimizable metric and an execution environment, they can propose, validate, and iterate scientific solutions, and have produced results that outperform human-designed approaches. As model capabilities continue to improve, we argue that the bottleneck for autonomous scientific discovery is shifting from prescribing agent workflows to designing agent environments: the resources, constraints, and interfaces that shape agent behavior. We frame this as environment engineering: building environments that amplify productive behaviors, such as open-ended exploration, systematic artifact management, and inter-agent collaboration, while suppressing harmful behaviors, such as reward hacking and high-friction human oversight. We present EurekAgent, an environment-engineered agent system for metric-driven autonomous scientific discovery. EurekAgent engineers the environment along four dimensions: permissions engineering for bounded agent execution and isolated evaluation; artifact engineering for filesystem and Git-based collaboration; budget engineering for budget-aware exploration; and human-in-the-loop engineering for easy human supervision and intervention. EurekAgent sets new state-of-the-art results on multiple mathematics, kernel engineering, and machine learning tasks, including new state-of-the-art 26-circle packing results discovered with less than $11 in total API cost. We open-source our code and results, and call for environment engineering as a core research direction for developing reliable autonomous research agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that the bottleneck for LLM-based agents in autonomous scientific discovery is shifting from workflow design to environment engineering. It introduces EurekAgent, which engineers the agent environment along four dimensions (permissions for bounded execution, artifacts for filesystem/Git collaboration, budget for cost-aware exploration, and human-in-the-loop for supervision) to amplify productive behaviors and suppress harmful ones. The system reports new state-of-the-art results across mathematics, kernel engineering, and machine learning tasks, including a new record for 26-circle packing discovered at under $11 total API cost, and releases the code and results.
Significance. If the results hold under independent verification via the open-sourced code, the work is significant for redirecting research attention toward systematic environment design as a core lever for reliable autonomous agents. The explicit framing of four engineering dimensions and the low-cost empirical outcome provide a concrete, falsifiable starting point for the field.
major comments (2)
- [Abstract and Introduction] Abstract and Introduction: the central claim that environment engineering along the four dimensions 'is all you need' (i.e., suffices without additional workflow-level innovations) is load-bearing for the title and argument; the results section should contain explicit ablations or controlled comparisons to non-engineered baselines to substantiate the attribution rather than resting solely on end-to-end task performance.
- [Results] Results (circle-packing experiment): the new 26-circle SOTA claim is a flagship outcome, but the manuscript must specify the prior best-known configuration, the exact objective metric, verification protocol, and the role of each of the four engineering dimensions in reaching it; without these, the cost figure alone does not fully support the environment-engineering thesis.
minor comments (2)
- [Methods] The four dimensions are introduced clearly in the abstract but would benefit from a consolidated table or diagram in the methods section that maps each dimension to the specific mechanisms used to amplify or suppress behaviors.
- [Conclusion] The open-sourcing statement is welcome; the paper should include a short reproducibility checklist (exact API versions, seed settings, and evaluation scripts) to make the released artifacts immediately usable.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the potential significance of the work if the results hold under verification. We respond to each major comment below and commit to revisions that directly address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and Introduction] Abstract and Introduction: the central claim that environment engineering along the four dimensions 'is all you need' (i.e., suffices without additional workflow-level innovations) is load-bearing for the title and argument; the results section should contain explicit ablations or controlled comparisons to non-engineered baselines to substantiate the attribution rather than resting solely on end-to-end task performance.
Authors: We agree that the central claim requires stronger attribution and that end-to-end performance alone is insufficient. The revised manuscript will add explicit ablations and controlled comparisons in the Results section, including runs against non-engineered baselines (e.g., standard agent frameworks without permissions, artifact, budget, or human-in-the-loop engineering). These will quantify the contribution of the four dimensions and support the 'is all you need' framing. revision: yes
-
Referee: [Results] Results (circle-packing experiment): the new 26-circle SOTA claim is a flagship outcome, but the manuscript must specify the prior best-known configuration, the exact objective metric, verification protocol, and the role of each of the four engineering dimensions in reaching it; without these, the cost figure alone does not fully support the environment-engineering thesis.
Authors: We agree that additional specification is required to link the outcome to the environment-engineering thesis. The revised Results section will explicitly state the prior best-known configuration, the exact objective metric, the verification protocol (leveraging the open-sourced code), and a breakdown of how each of the four dimensions contributed to the low-cost discovery. These details will be added to substantiate the claim. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents EurekAgent as an empirical agent system whose central claim rests on reported task performance (including 26-circle packing at <$11 cost) rather than any mathematical derivation chain. No equations, fitted parameters, predictions, or first-principles results are described that could reduce to the inputs by construction. The four environment-engineering dimensions are presented as design choices whose sufficiency is evaluated experimentally, with code and results open-sourced for external verification. No self-citations, ansatzes, or uniqueness theorems appear as load-bearing elements in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Environment engineering is the shifting bottleneck for autonomous scientific discovery with LLM agents.
Reference graph
Works this paper leans on
-
[1]
Adaevolve: Adaptive llm driven zeroth-order optimization.arXiv preprint arXiv:2602.20133,
Mert Cemri, Shubham Agrawal, Akshat Gupta, Shu Liu, Audrey Cheng, Qiuyang Mang, Ashwin Naren, Lutfi Eren Erdogan, Koushik Sen, Matei Zaharia, et al. Adaevolve: Adaptive llm driven zeroth-order optimization.arXiv preprint arXiv:2602.20133,
-
[2]
Mle-bench: Evaluating machine learn- ing agents on machine learning engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, et al. Mle-bench: Evaluating machine learn- ing agents on machine learning engineering. InInternational Conference on Learning Represen- tations, volume 2025, pp. 50466–50494,
2025
-
[3]
Jiefeng Chen, Bhavana Dalvi Mishra, Jaehyun Nam, Rui Meng, Tomas Pfister, and Jinsung Yoon. Mars: Modular agent with reflective search for automated ai research.arXiv preprint arXiv:2602.02660,
-
[4]
The minimum overlap problem revisited.arXiv preprint arXiv:1609.08000,
Jan Kristian Haugland. The minimum overlap problem revisited.arXiv preprint arXiv:1609.08000,
-
[5]
Aide: Ai-driven exploration in the space of code.arXiv preprint arXiv:2502.13138,
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Jacenko, and Yuxiang Wu. Aide: Ai-driven exploration in the space of code.arXiv preprint arXiv:2502.13138,
-
[6]
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. Shinkaevolve: Towards open-ended and sample-efficient program evolution.arXiv preprint arXiv:2509.19349,
-
[7]
URLhttps://arxiv.org/abs/2510.26144. Jiaqi Liu, Shi Qiu, Mairui Li, Bingzhou Li, Haonian Ji, Siwei Han, Xinyu Ye, Peng Xia, Zihan Dong, Congyu Zhang, et al. Autoresearchclaw: Self-reinforcing autonomous research with human-ai collaboration.arXiv preprint arXiv:2605.20025, 2026a. Shu Liu, Shubham Agarwal, Monishwaran Maheswaran, Mert Cemri, Zhifei Li, Qiuy...
-
[8]
Ziming Luo, Atoosa Kasirzadeh, and Nihar B Shah. The more you automate, the less you see: Hidden pitfalls of ai scientist systems.arXiv preprint arXiv:2509.08713,
-
[9]
Alexander Novikov, Ngân V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131,
-
[10]
Kernelbench: Can llms write efficient gpu kernels?arXiv preprint arXiv:2502.10517,
Anne Ouyang, Simon Guo, Simran Arora, Alex L Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. Kernelbench: Can llms write efficient gpu kernels?arXiv preprint arXiv:2502.10517,
-
[11]
Yunjia Qi, Hao Peng, Xiaozhi Wang, Amy Xin, Youfeng Liu, Bin Xu, Lei Hou, and Juanzi Li. Agen- tif: Benchmarking instruction following of large language models in agentic scenarios.arXiv preprint arXiv:2505.16944,
-
[12]
Ao Qu, Han Zheng, Zijian Zhou, Yihao Yan, Yihong Tang, Shao Yong Ong, Fenglu Hong, Kaichen Zhou, Chonghe Jiang, Minwei Kong, et al. Coral: Towards autonomous multi-agent evolution for open-ended discovery.arXiv preprint arXiv:2604.01658,
-
[13]
Chunhui Wan, Xunan Dai, Zhuo Wang, Minglei Li, Yanpeng Wang, Yinan Mao, Yu Lan, and Zhi- wen Xiao
URLhttps: //github.com/algorithmicsuperintelligence/openevolve. Chunhui Wan, Xunan Dai, Zhuo Wang, Minglei Li, Yanpeng Wang, Yinan Mao, Yu Lan, and Zhi- wen Xiao. Loongflow: Directed evolutionary search via a cognitive plan-execute-summarize paradigm.arXiv preprint arXiv:2512.24077,
-
[14]
Thetaevolve: Test-time learning on open problems.arXiv preprint arXiv:2511.23473,
Yiping Wang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Yang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, et al. Thetaevolve: Test-time learning on open problems.arXiv preprint arXiv:2511.23473,
-
[15]
URL https://arxiv.org/abs/2606.07591. Xu Yang, Xiao Yang, Shikai Fang, Bowen Xian, Yuante Li, Jian Wang, Minrui Xu, Haoran Pan, Xinpeng Hong, Weiqing Liu, et al. R&d-agent: Automating data-driven ai solution building through llm-powered automated research, development, and evolution.arXiv e-prints, pp. arXiv– 2505,
-
[16]
Learning to discover at test time.arXiv preprint arXiv:2601.16175,
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, et al. Learning to discover at test time.arXiv preprint arXiv:2601.16175,
-
[17]
Aibuildai: An ai agent for automati- cally building ai models.arXiv preprint arXiv:2604.14455,
Ruiyi Zhang, Peijia Qin, Qi Cao, Li Zhang, and Pengtao Xie. Aibuildai: An ai agent for automati- cally building ai models.arXiv preprint arXiv:2604.14455,
-
[18]
Xinyu Zhu, Yuzhu Cai, Zexi Liu, Bingyang Zheng, Cheng Wang, Rui Ye, Jiaao Chen, Hanrui Wang, Wei-Chen Wang, Yuzhi Zhang, et al. Toward ultra-long-horizon agentic science: Cognitive accu- mulation for machine learning engineering.arXiv preprint arXiv:2601.10402,
-
[19]
Here,Rdenotes the maximum number of propose–implement iteration rounds, andPdenotes the maximum number of parallel implementation sessions spawned in each implement stage
11 Preprint A EUREKAGENTHYPERPARAMETERSETTINGS Table 5 summarizes the EUREKAGENThyperparameters used in our experiments. Here,Rdenotes the maximum number of propose–implement iteration rounds, andPdenotes the maximum number of parallel implementation sessions spawned in each implement stage. TaskR P t propose timplement Notes Circle Packing 5 3 20 min 120...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.