DRFusion: Drift-Resilient Temporally Consistent Infrared-Visible Video Fusion
Pith reviewed 2026-06-29 22:35 UTC · model grok-4.3
The pith
A diffusion model for infrared-visible video fusion prevents drifting by reframing temporal consistency as spectral filtering of motion history.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
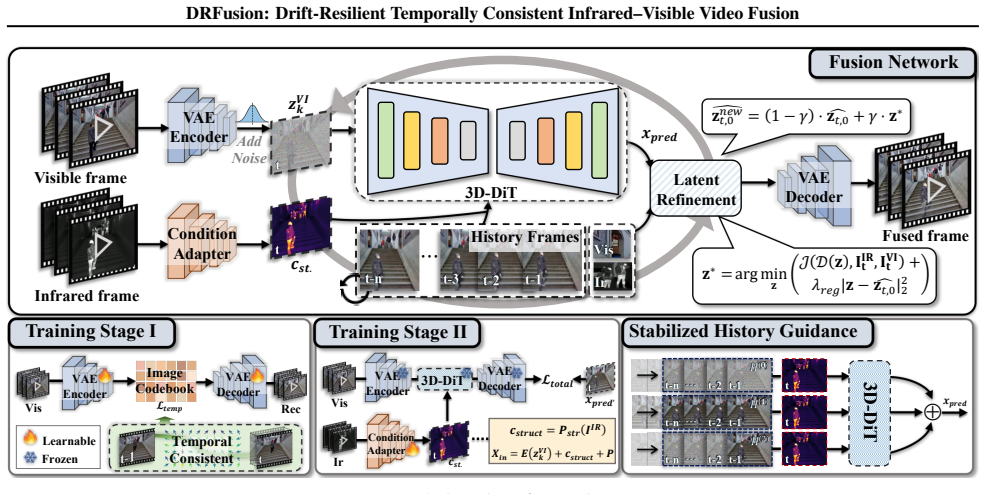
By introducing Stabilized History Guidance and Soft Temporal Anchoring the authors reformulate temporal consistency as spectral filtering that aggregates motion dynamics without rigid alignment; a Decoupled Structure-Motion Adaptation strategy then bridges pre-trained diffusion priors with structural constraints through two-stage training and latent refinement, yielding state-of-the-art fusion quality and temporal stability on infrared-visible video.
What carries the argument
Stabilized History Guidance and Soft Temporal Anchoring, which together treat temporal consistency as spectral filtering to aggregate motion implicitly without optical-flow alignment.
If this is right
- The method produces fused videos that remain temporally stable over extended sequences without accumulating minor artifacts.
- Fusion quality and temporal stability both reach state-of-the-art levels on standard benchmarks.
- Pre-trained diffusion priors can be adapted to video fusion through two-stage training and latent refinement without explicit optical-flow computation.
- Dynamic scenes receive comprehensive infrared-visible perception without ghosting or geometric distortion.
Where Pith is reading between the lines
- The same spectral-filtering view of history could be applied to other autoregressive diffusion tasks such as video generation or enhancement.
- Removing the need for optical flow may simplify pipelines that currently combine separate flow estimation and fusion stages.
- Longer-term stability could support downstream tasks that require consistent fused video over minutes rather than seconds.
Load-bearing premise
The assumption that reframing temporal consistency as spectral filtering via Stabilized History Guidance and Soft Temporal Anchoring will prevent error accumulation and drifting when extending diffusion models to autoregressive video settings.
What would settle it
A long infrared-visible video sequence in which visible artifacts still grow frame by frame despite the Stabilized History Guidance and Soft Temporal Anchoring modules.
Figures






read the original abstract
Infrared and visible video fusion is essential for achieving comprehensive perception in dynamic scenes. However, maintaining temporal consistency remains a formidable challenge. Conventional methods relying on optical flow often suffer from geometric rigidity and ghosting artifacts. Moreover, standard diffusion-based fusion models typically operate in a frame-by-frame manner; when extended to autoregressive settings, they lack intrinsic temporal constraints and are prone to severe error accumulation and drifting, where minor artifacts amplify over time. To address these limitations, we propose a drift-resilient video fusion method that reformulates the task as history-conditioned motion generation. We introduce Stabilized History Guidance and Soft Temporal Anchoring to reframe temporal consistency as spectral filtering, implicitly aggregating motion dynamics without rigid alignment. Furthermore, our Decoupled Structure-Motion Adaptation strategy bridges pre-trained priors and structural constraints via two-stage training and latent refinement. Extensive experiments demonstrate that our method achieves state-of-the-art performance in both fusion quality and temporal stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DRFusion, a drift-resilient method for infrared-visible video fusion. It reformulates the task as history-conditioned motion generation and introduces Stabilized History Guidance and Soft Temporal Anchoring to treat temporal consistency as spectral filtering (implicitly aggregating motion dynamics without rigid optical-flow alignment). A Decoupled Structure-Motion Adaptation strategy with two-stage training and latent refinement bridges pre-trained diffusion priors to structural constraints. Extensive experiments, including ablations, quantitative temporal metrics (temporal variance, flicker indices), and long-sequence evaluations, are reported to demonstrate state-of-the-art performance in both fusion quality and temporal stability.
Significance. If the reported results hold, the work advances video fusion by mitigating error accumulation and drifting when extending frame-wise diffusion models to autoregressive video settings, a practical issue for dynamic-scene perception. The history-conditioned spectral-filtering approach and two-stage adaptation provide a concrete, experimentally validated alternative to optical-flow-based consistency. Credit is due for the inclusion of ablations, direct temporal-stability metrics, and long-sequence testing, which directly address the central claim rather than relying on qualitative assertions alone.
major comments (2)
- [§3.2] §3.2 (Stabilized History Guidance): the claim that the mechanism reframes temporal consistency as spectral filtering and thereby prevents drifting is presented as a modeling choice whose effectiveness is demonstrated experimentally; however, the manuscript does not supply a formal frequency-domain analysis or proof that the guidance operator is guaranteed to suppress low-frequency drift accumulation across arbitrary sequence lengths.
- [Table 2] Table 2 (quantitative comparisons): while SOTA numbers are reported, the table does not indicate whether competing methods were re-trained or evaluated under identical autoregressive settings and sequence lengths; this detail is load-bearing for the cross-method temporal-stability claim.
minor comments (3)
- The abstract states that 'extensive experiments demonstrate SOTA performance' yet supplies no dataset names or metric definitions; moving a one-sentence summary of the evaluation protocol into the abstract would improve readability.
- [Figure 4] Figure 4 (qualitative results): several frames exhibit minor color shifts between IR and visible modalities that are not discussed; a short note on whether these are artifacts or expected behavior would clarify interpretation.
- [§4.3] §4.3 (ablation study): the 'w/o Soft Temporal Anchoring' row reports a temporal-variance increase but does not state the number of runs or standard deviation; adding error bars or run counts would strengthen the ablation.
Simulated Author's Rebuttal
Thank you for the constructive feedback and positive assessment of our work. We address each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Stabilized History Guidance): the claim that the mechanism reframes temporal consistency as spectral filtering and thereby prevents drifting is presented as a modeling choice whose effectiveness is demonstrated experimentally; however, the manuscript does not supply a formal frequency-domain analysis or proof that the guidance operator is guaranteed to suppress low-frequency drift accumulation across arbitrary sequence lengths.
Authors: We agree that no formal frequency-domain analysis or mathematical proof of guaranteed drift suppression is provided. The spectral-filtering interpretation is presented as a conceptual reframing of the Stabilized History Guidance and Soft Temporal Anchoring design, whose practical effectiveness is shown via quantitative temporal metrics and long-sequence tests. We will add a clarifying sentence in §3.2 stating that this view is interpretive and not accompanied by a formal guarantee. revision: yes
-
Referee: [Table 2] Table 2 (quantitative comparisons): while SOTA numbers are reported, the table does not indicate whether competing methods were re-trained or evaluated under identical autoregressive settings and sequence lengths; this detail is load-bearing for the cross-method temporal-stability claim.
Authors: All competing methods were re-implemented and evaluated under the identical autoregressive protocol and sequence lengths used for DRFusion. This detail was omitted from the table caption for space but will be added explicitly, together with a corresponding statement in the experimental setup. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on experimental validation of fusion quality and temporal stability metrics (temporal variance, flicker indices, long-sequence evaluations) rather than any derivation that reduces to fitted parameters or self-citations by construction. The modeling choices (Stabilized History Guidance, Soft Temporal Anchoring, Decoupled Structure-Motion Adaptation) are presented as architectural decisions whose effectiveness is asserted via ablations and quantitative results on external benchmarks; no equations, parameter-fitting steps, or uniqueness theorems are shown to be self-referential or load-bearing on prior author work. The derivation chain is therefore self-contained against the reported empirical evidence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Y ., Yang, C., Rao, A., Liang, Z., Wang, Y ., Qiao, Y ., Agrawala, M., Lin, D., and Dai, B. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Li, H., Xu, T., Wu, X.-J., Lu, J., and Kittler, J. Lrrnet: A novel representation learning guided fusion network for infrared and visible images.IEEE transactions on pattern analysis and machine intelligence, 45(9):11040–11052, 2023a. Li, X., Zou, Y ., Liu, J., Jiang, Z., Ma, L., Fan, X., and Liu, R. From text to pixels: A context-aware semantic synergy s...
-
[3]
Liu, J., Li, X., Wang, Z., Jiang, Z., Zhong, W., Fan, W., and Xu, B. Promptfusion: Harmonized semantic prompt learning for infrared and visible image fusion.IEEE/CAA Journal of Automatica Sinica, 2024a. 9 DRFusion: Drift-Resilient Temporally Consistent Infrared–Visible Video Fusion Liu, J., Zhang, B., Mei, Q., Li, X., Zou, Y ., Jiang, Z., Ma, L., Liu, R.,...
-
[4]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., et al. Make-a- video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
History-Guided Video Diffusion
Song, K., Chen, B., Simchowitz, M., Du, Y ., Tedrake, R., and Sitzmann, V . History-guided video diffusion.arXiv preprint arXiv:2502.06764,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Tang, L., Li, C., and Ma, J. Mask-difuser: A masked diffu- sion model for unified unsupervised image fusion.IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025a. Tang, L., Wang, Y ., Gong, M., Li, Z., Deng, Y ., Yi, X., Li, C., Xu, H., Zhang, H., and Ma, J. Videofusion: A spatio- temporal collaborative network for multi-modal video fusi...
-
[7]
Wang, Y ., Miao, L., Zhou, Z., Zhang, L., and Qiao, Y . Infrared and visible image fusion with language- driven loss in clip embedding space.arXiv preprint arXiv:2402.16267,
-
[8]
Efficient rectified flow for image fusion.arXiv preprint arXiv:2509.16549,
Wang, Z., Zhang, J., Guan, T., Zhou, Y ., Li, X., Dong, M., and Liu, J. Efficient rectified flow for image fusion.arXiv preprint arXiv:2509.16549,
-
[9]
Metafu- sion: Infrared and visible image fusion via meta-feature embedding from object detection
Zhao, W., Xie, S., Zhao, F., He, Y ., and Lu, H. Metafu- sion: Infrared and visible image fusion via meta-feature embedding from object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13955–13965, 2023a. Zhao, Z., Xu, S., Zhang, C., Liu, J., Li, P., and Zhang, J. Didfuse: Deep image decomposition for inf...
-
[10]
Cddfuse: Correlation-driven dual-branch feature decomposition for multi-modality im- age fusion
Zhao, Z., Bai, H., Zhang, J., Zhang, Y ., Xu, S., Lin, Z., Tim- ofte, R., and Van Gool, L. Cddfuse: Correlation-driven dual-branch feature decomposition for multi-modality im- age fusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5906– 5916, 2023b. Zhao, Z., Bai, H., Zhu, Y ., Zhang, J., Xu, S., Zhang, Y ., Z...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.