OffQ: Taming Structured Outliers in LLM Quantization by Offsetting
Pith reviewed 2026-06-27 22:35 UTC · model grok-4.3
The pith
Rotating activations to pack outliers into one channel then absorbing it via shared offset enables uniform 4-bit LLM quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
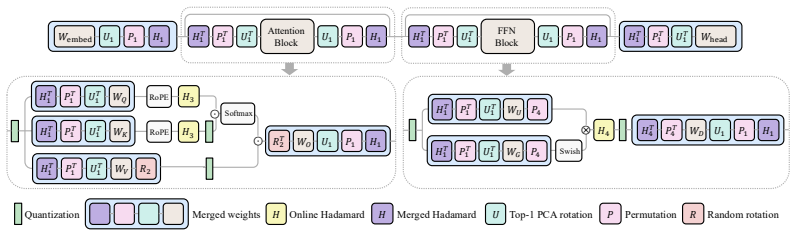
OffQ first identifies a low-dimensional outlier subspace in the activations using a proposed top-1 PCA, and then concentrates high-magnitude activations into 1 channel via rotation. OffQ then absorbs this concentrated outlier channel by converting its magnitude into a shared offset, thereby reducing the standard deviation of the activations. This offsetting strategy enables effective W4A4KV4 quantization of LLMs using deployment-friendly uniform-grid and uniform-precision quantization.
What carries the argument
The offsetting mechanism that isolates the outlier subspace via top-1 PCA, rotates to concentrate high-magnitude values into one channel, and converts that channel into a shared offset.
If this is right
- LLMs achieve effective 4-bit quantization for weights, activations, and KV caches using only uniform grids and uniform precision.
- The method avoids per-tensor adjustments that would defeat the uniform-grid goal.
- Accuracy improves consistently over prior outlier-handling baselines across multiple LLM architectures and evaluation benchmarks.
- Low-bit efficiency is preserved because the offset is shared and requires no additional per-channel storage or computation at inference.
Where Pith is reading between the lines
- The same rotation-plus-offset pattern might apply to outlier patterns in non-transformer models such as convolutional networks.
- Hardware designs could add native support for a single shared offset per tensor to further speed up the resulting 4-bit kernels.
- Testing the method at 3-bit or 2-bit widths would show whether the concentration step scales before the offset itself becomes too coarse.
Load-bearing premise
The low-dimensional outlier subspace identified by top-1 PCA can be rotated to concentrate all high-magnitude values into a single channel whose magnitude can be removed by a shared offset without unacceptable distortion.
What would settle it
Quantizing an LLM such as Llama to W4A4KV4 after the rotation and offset step and measuring whether perplexity on WikiText or accuracy on MMLU drops by more than a few percent relative to the 16-bit baseline.
Figures

read the original abstract
Low-bit quantization has been widely adopted to accelerate the inference of large language models (LLMs) by significantly reducing computational cost and memory usage. However, activation outliers pose a major challenge to effective quantization, often leading to notable performance degradation. In this paper, we introduce OffQ, a method designed to mitigate activation outliers in low-bit quantization through a novel offsetting mechanism. Specifically, OffQ first identifies a low-dimensional outlier subspace in the activations using a proposed top-1 PCA, and then concentrates high-magnitude activations into 1 channel via rotation. OffQ then absorbs this concentrated outlier channel by converting its magnitude into a shared offset, thereby reducing the standard deviation of the activations. This offsetting strategy enables effective W4A4KV4 quantization of LLMs using deployment-friendly uniform-grid and uniform-precision quantization. Extensive experiments across diverse LLM architectures and benchmarks demonstrate that OffQ outperforms state-of-the-art baselines, consistently improving model accuracy while preserving low-bit efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OffQ, a quantization technique for LLMs that identifies a low-dimensional outlier subspace in activations via top-1 PCA, rotates the tensor to concentrate high-magnitude values into a single channel, and absorbs that channel by converting its magnitude into a shared offset subtracted from the entire tensor. This is claimed to reduce activation standard deviation enough to enable effective W4A4KV4 quantization under deployment-friendly uniform-grid and uniform-precision schemes, with experiments showing consistent accuracy gains over baselines across LLM architectures and benchmarks.
Significance. If the core offsetting mechanism holds without introducing unacceptable distortion or requiring non-uniform adjustments, the result would be significant for practical LLM deployment, as it would allow standard uniform 4-bit quantization to achieve competitive accuracy without custom hardware or per-tensor zero-points.
major comments (1)
- [Method description (top-1 PCA and rotation step)] Method description (top-1 PCA and rotation step): the central claim that top-1 PCA isolates the outlier subspace such that a single rotation concentrates every high-magnitude activation into one channel (whose value can then be replaced by a shared offset) is load-bearing but unsupported by any derivation or analysis. If outlier energy has components orthogonal to the top eigenvector, post-rotation channels will retain large values; subtracting one shared offset cannot recenter all of them without either increasing range in other channels or requiring per-channel adjustments, directly contradicting the uniform-grid, uniform-precision premise.
minor comments (1)
- [Abstract] Abstract: the statement that experiments demonstrate consistent improvement would be strengthened by explicit mention of the specific models, bit-width configurations, and evaluation metrics used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. Below we respond point-by-point to the single major comment.
read point-by-point responses
-
Referee: Method description (top-1 PCA and rotation step): the central claim that top-1 PCA isolates the outlier subspace such that a single rotation concentrates every high-magnitude activation into one channel (whose value can then be replaced by a shared offset) is load-bearing but unsupported by any derivation or analysis. If outlier energy has components orthogonal to the top eigenvector, post-rotation channels will retain large values; subtracting one shared offset cannot recenter all of them without either increasing range in other channels or requiring per-channel adjustments, directly contradicting the uniform-grid, uniform-precision premise.
Authors: We agree that the manuscript presents the top-1 PCA choice primarily through empirical motivation rather than a formal derivation or proof that all outlier energy lies exactly along the leading eigenvector. The approach is grounded in the documented low-rank structure of activation outliers in LLMs (as referenced in the related-work section), and the rotation is defined to align the dominant principal direction with a single coordinate axis. We will revise the method section to include (i) a quantitative report of the fraction of activation variance captured by the top-1 component across layers and models and (ii) a short discussion of the residual approximation error when the outlier subspace is not perfectly one-dimensional. Regarding the orthogonal-component concern, the shared-offset step is applied after rotation precisely to recenter the now-concentrated channel; any residual orthogonal energy remains in the other channels but, per our measurements, exhibits substantially lower magnitude, allowing the subsequent uniform 4-bit grid to operate without per-channel zero-points. The experimental tables demonstrate that this suffices for the reported accuracy recovery. We therefore view the referee’s observation as identifying a useful clarification rather than an outright contradiction, and the planned additions will make the supporting evidence explicit. revision: partial
Circularity Check
No circularity: procedural method with no self-referential equations or load-bearing self-citations
full rationale
The paper presents OffQ as an algorithmic pipeline (top-1 PCA to identify outlier subspace, rotation to concentrate into one channel, conversion of that channel's magnitude into a shared offset) without any equations, fitted parameters renamed as predictions, or self-citations that justify the core steps. The abstract and description treat the approach as a sequence of operations whose effectiveness is evaluated empirically on benchmarks, not derived from first principles that loop back to the inputs. No load-bearing claim reduces by construction to its own definition or prior self-citation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Framequant: Flexible low-bit quantization for transformers
Harshavardhan Adepu, Zhanpeng Zeng, Li Zhang, and Vikas Singh. Framequant: Flexible low-bit quantization for transformers. InProceedings of International Conference on Machine Learning (ICML), 2024
2024
-
[2]
KurTail : Kurtosis-based LLM quantization
Mohammad Sadegh Akhondzadeh, Aleksandar Bojchevski, Evangelos Eleftheriou, and Martino Dazzi. KurTail : Kurtosis-based LLM quantization. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 17404–17419, Suzhou, China, 2025. Association for Computational Linguistics
2025
-
[3]
Quantization error propagation: Revisiting layer-wise post-training quantization
Yamato Arai and Yuma Ichikawa. Quantization error propagation: Revisiting layer-wise post-training quantization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[4]
Quantization error propagation: Revisiting layer-wise post-training quantization
Yamato Arai and Yuma Ichikawa. Quantization error propagation: Revisiting layer-wise post-training quantization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[5]
Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Maximilian L. Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman. SliceGPT: Compress large language models by deleting rows and columns. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[6]
QUIK: Towards end-to-end 4-bit inference on generative large language models
Saleh Ashkboos, Ilia Markov, Elias Frantar, Tingxuan Zhong, Xincheng Wang, Jie Ren, Torsten Hoefler, and Dan Alistarh. QUIK: Towards end-to-end 4-bit inference on generative large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 3355–3371, Miami, Florida, USA, 2024. Association for Computati...
2024
-
[7]
Quarot: Outlier-free 4-bit inference in rotated llms
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms. Advances in Neural Information Processing Systems, 37:100213–100240, 2024
2024
-
[8]
Castro, Torsten Hoefler, and Dan Alistarh
Saleh Ashkboos, Mahdi Nikdan, Soroush Tabesh, Roberto L. Castro, Torsten Hoefler, and Dan Alistarh. HALO: Hadamard-assisted lower-precision optimization for LLMs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[9]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. InThirty-Fourth AAAI Conference on Artificial Intelligence, 2020
2020
-
[10]
Understanding and overcoming the chal- lenges of efficient transformer quantization
Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. Understanding and overcoming the chal- lenges of efficient transformer quantization. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7947–7969, 2021
2021
-
[11]
PyramidKV: Dynamic KV cache compression based on pyramidal information funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, and Wen Xiao. PyramidKV: Dynamic KV cache compression based on pyramidal information funneling. InSecond Conference on Language Modeling, 2025
2025
-
[12]
Quip: 2-bit quantization of large language models with guarantees, 2024
Jerry Chee, Yaohui Cai, V olodymyr Kuleshov, and Christopher De Sa. Quip: 2-bit quantization of large language models with guarantees, 2024
2024
-
[13]
Efficien- tQAT: Efficient quantization-aware training for large language models
Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, and Ping Luo. Efficien- tQAT: Efficient quantization-aware training for large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10081–10100, Vienna, Austria, 2025. Association for Computational L...
2025
-
[14]
Rotate, clip, and partition: Towards W2A4KV4 quantization by integrating rotation and learnable non-uniform quantizer
Euntae Choi, Sumin Song, Woosang Lim, and Sungjoo Yoo. Rotate, clip, and partition: Towards W2A4KV4 quantization by integrating rotation and learnable non-uniform quantizer. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 7568–7590, Suzhou, China, 2025. Association for Computational Linguistics
2025
-
[15]
BoolQ: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), ...
2019
-
[16]
Association for Computational Linguistics. 10
-
[17]
Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018
2018
-
[18]
Vision transformers need registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[19]
Llm.int8(): 8-bit matrix multiplication for transformers at scale.Advances in neural information processing systems, 35:30318–30332, 2022
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Llm.int8(): 8-bit matrix multiplication for transformers at scale.Advances in neural information processing systems, 35:30318–30332, 2022
2022
-
[20]
Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh
Tim Dettmers, Ruslan A. Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. SpQR: A sparse-quantized representation for near- lossless LLM weight compression. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[21]
BitDistiller: Unleashing the potential of sub-4-bit LLMs via self-distillation
DaYou Du, Yijia Zhang, Shijie Cao, Jiaqi Guo, Ting Cao, Xiaowen Chu, and Ningyi Xu. BitDistiller: Unleashing the potential of sub-4-bit LLMs via self-distillation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 102–116, Bangkok, Thailand, 2024. Association for Computational Linguistics
2024
-
[22]
OPTQ: Accurate quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. OPTQ: Accurate quantization for generative pre-trained transformers. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[23]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
LQ-loRA: Low-rank plus quantized matrix decomposition for efficient language model finetuning
Han Guo, Philip Greengard, Eric Xing, and Yoon Kim. LQ-loRA: Low-rank plus quantized matrix decomposition for efficient language model finetuning. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[25]
Zipcache: Accurate and efficient KV cache quantization with salient token identification
Yefei He, Luoming Zhang, Weijia Wu, Jing Liu, Hong Zhou, and Bohan Zhuang. Zipcache: Accurate and efficient KV cache quantization with salient token identification. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[26]
Mahoney, Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Richard Charles Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Sophia Shao, Kurt Keutzer, and Amir Gholami. KVQuant: Towards 10 million context length LLM inference with KV cache quantization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[27]
Mlwq: Efficient small language model deployment via multi-level weight quantization
Chun Hu, Junhui He, Shangyu Wu, Yuxin He, Chun Jason Xue, and Qingan Li. Mlwq: Efficient small language model deployment via multi-level weight quantization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 8078–8088, 2025
2025
-
[28]
OSTQuant: Refining large language model quantization with orthogonal and scaling transformations for better distribution fitting
Xing Hu, Yuan Cheng, Dawei Yang, Zhixuan Chen, Zukang Xu, JiangyongYu, XUCHEN, Zhihang Yuan, Zhe jiang, and Sifan Zhou. OSTQuant: Refining large language model quantization with orthogonal and scaling transformations for better distribution fitting. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[29]
Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, and Xi- aojuan Qi. Billm: Pushing the limit of post-training quantization for llms.arXiv preprint arXiv:2402.04291, 2024
-
[30]
SliM-LLM: Salience-driven mixed-precision quantization for large language models
Wei Huang, Haotong Qin, Yangdong Liu, Yawei Li, Qinshuo Liu, Xianglong Liu, Luca Benini, Michele Magno, Shiming Zhang, and Xiaojuan Qi. SliM-LLM: Salience-driven mixed-precision quantization for large language models. InProceedings of the 42nd International Conference on Machine Learning, pages 25672–25692. PMLR, 2025
2025
-
[31]
Quantization and training of neural networks for efficient integer- arithmetic-only inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer- arithmetic-only inference. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2704–2713, 2018
2018
-
[32]
Understanding and improving knowledge distillation for quantization aware training of large transformer encoders
Minsoo Kim, Sihwa Lee, Suk-Jin Hong, Du-Seong Chang, and Jungwook Choi. Understanding and improving knowledge distillation for quantization aware training of large transformer encoders. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6713–6725, Abu Dhabi, United Arab Emirates, 2022. Association for Computat...
2022
-
[33]
Mahoney, and Kurt Keutzer
Sehoon Kim, Coleman Richard Charles Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, and Kurt Keutzer. SqueezeLLM: Dense and sparse quantization, 2024
2024
-
[34]
Mahoney, and Kurt Keutzer
Sehoon Kim, Coleman Richard Charles Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, and Kurt Keutzer. SqueezeLLM: Dense-and-sparse quantization. InProceedings of the 41st International Conference on Machine Learning, pages 23901–23923. PMLR, 2024
2024
-
[35]
Quantizing deep convolutional networks for efficient inference: A whitepaper
Raghuraman Krishnamoorthi. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv preprint arXiv:1806.08342, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
give me BF16 or give me death
Eldar Kurtic, Alexandre Noll Marques, Shubhra Pandit, Mark Kurtz, and Dan Alistarh. “give me BF16 or give me death”? accuracy-performance trade-offs in LLM quantization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 26872–26886, Vienna, Austria, 2025. Association for Computational ...
2025
-
[37]
Flexround: Learnable rounding based on element-wise division for post-training quantization
Jung Hyun Lee, Jeonghoon Kim, Se Jung Kwon, and Dongsoo Lee. Flexround: Learnable rounding based on element-wise division for post-training quantization. InInternational Conference on Machine Learning, pages 18913–18939. PMLR, 2023
2023
-
[38]
Rethinking residual errors in compensation-based LLM quantization
Shuaiting Li, Juncan Deng, Kedong Xu, Rongtao Deng, Hong Gu, Minghan Jiang, Haibin Shen, and Kejie Huang. Rethinking residual errors in compensation-based LLM quantization. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[39]
GPTAQ: Efficient finetuning-free quantization for asymmetric calibration
Yuhang Li, Ruokai Yin, Donghyun Lee, Shiting Xiao, and Priyadarshini Panda. GPTAQ: Efficient finetuning-free quantization for asymmetric calibration. InForty-second International Conference on Machine Learning, 2025
2025
-
[40]
Duquant: Distributing outliers via dual transformation makes stronger quantized llms
Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Ying Wei. Duquant: Distributing outliers via dual transformation makes stronger quantized llms. Advances in Neural Information Processing Systems, 37:87766–87800, 2024
2024
-
[41]
Awq: Activation-aware weight quantization for llm compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration. InMLSys, 2024
2024
-
[42]
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving.Proceedings of Machine Learning and Systems, 7, 2025
Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, and Song Han. Qserve: W4a8kv4 quantization and system co-design for efficient llm serving.Proceedings of Machine Learning and Systems, 7, 2025
2025
-
[43]
QLLM: Accurate and efficient low-bitwidth quantization for large language models
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, and Bohan Zhuang. QLLM: Accurate and efficient low-bitwidth quantization for large language models. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[44]
Vptq: Extreme low-bit vector post-training quantization for large language models
Yifei Liu, Jicheng Wen, Yang Wang, Shengyu Ye, Li Lyna Zhang, Ting Cao, Cheng Li, and Mao Yang. Vptq: Extreme low-bit vector post-training quantization for large language models. InThe 2024 Conference on Empirical Methods in Natural Language Processing, 2024
2024
-
[45]
LLM-QAT: Data-free quantization aware training for large language models
Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. LLM-QAT: Data-free quantization aware training for large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 467–484, Bangkok, Thailand, 2024. Association for Computationa...
2024
-
[46]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. InInternational Conference on Machine Learning, pages 32332–32344. PMLR, 2024
2024
-
[47]
Spinquant: LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: LLM quantization with learned rotations. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[48]
Affinequant: Affine transformation quantization for large language models
Yuexiao Ma, Huixia Li, Xiawu Zheng, Feng Ling, Xuefeng Xiao, Rui Wang, Shilei Wen, Fei Chao, and Rongrong Ji. Affinequant: Affine transformation quantization for large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[49]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In International Conference on Learning Representations, 2017. 12
2017
-
[50]
Llama 3.2: Revolutionizing edge ai and vision with open, customizable models
Meta AI. Llama 3.2: Revolutionizing edge ai and vision with open, customizable models. https: //ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/ , 2024. Accessed: 2026-05-05
2024
-
[51]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391, Brussels, Belgium, 2018. Association for Computational Linguistics
2018
-
[52]
Muller, Philippe Bich, Jiawei Zhuang, Ahmet Celik, Luca Benfenati, and Lukas Cavigelli
Lorenz K. Muller, Philippe Bich, Jiawei Zhuang, Ahmet Celik, Luca Benfenati, and Lukas Cavigelli. Sinq: Sinkhorn-normalized quantization for calibration-free low-precision llm weights, 2025
2025
-
[53]
Self-distilled quantization: Achieving high compression rates in transformer-based language models
James O’Neill and Sourav Dutta. Self-distilled quantization: Achieving high compression rates in transformer-based language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1329–1339, Toronto, Canada, 2023. Association for Computational Linguistics
2023
-
[54]
Automatic differentiation in pytorch
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017
2017
-
[55]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
2025
-
[56]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.arXiv preprint arXiv:1907.10641, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[57]
Social iqa: Commonsense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Commonsense reasoning about social interactions. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4463–4473, 2019
2019
-
[58]
Nestquant: nested lattice quantization for matrix products and LLMs
Semyon Savkin, Eitan Porat, Or Ordentlich, and Yury Polyanskiy. Nestquant: nested lattice quantization for matrix products and LLMs. InForty-second International Conference on Machine Learning, 2025
2025
-
[59]
Resq: Mixed-precision quantization of large language models with low-rank residuals
Utkarsh Saxena, Sayeh Sharify, Kaushik Roy, and Xin Wang. Resq: Mixed-precision quantization of large language models with low-rank residuals. InForty-second International Conference on Machine Learning, 2025
2025
-
[60]
Omniquant: Omnidirectionally calibrated quantization for large language models
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[61]
Dartquant: Efficient rotational distribution calibration for LLM quantization
Yuantian Shao, Yuanteng Chen, Peisong Wang, Jianlin Yu, Jing Lin, Yiwu Yao, Zhihui Wei, and Jian Cheng. Dartquant: Efficient rotational distribution calibration for LLM quantization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[62]
NSNQuant: A double normalization approach for calibration-free low-bit vector quantization of KV cache
Donghyun Son, Euntae Choi, and Sungjoo Yoo. NSNQuant: A double normalization approach for calibration-free low-bit vector quantization of KV cache. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[63]
Accurate kv cache quantization with outlier tokens tracing
Yi Su, Yuechi Zhou, Quantong Qiu, Juntao Li, Qingrong Xia, Ping Li, Xinyu Duan, Zhefeng Wang, and Min Zhang. Accurate kv cache quantization with outlier tokens tracing. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12895–12915, 2025
2025
-
[64]
Massive activations in large language models
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models. InFirst Conference on Language Modeling, 2024
2024
-
[65]
Flatquant: Flatness matters for LLM quantization
Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, JiaxinHu, Xianzhi Yu, Lu Hou, Chun Yuan, Xin Jiang, Wulong Liu, and Jun Yao. Flatquant: Flatness matters for LLM quantization. In Forty-second International Conference on Machine Learning, 2025
2025
-
[66]
CUTLASS, 2023
Vijay Thakkar, Pradeep Ramani, Cris Cecka, Aniket Shivam, Honghao Lu, Ethan Yan, Jack Kosaian, Mark Hoemmen, Haicheng Wu, Andrew Kerr, Matt Nicely, Duane Merrill, Dustyn Blasig, Aditya Atluri, Fengqi Qiao, Piotr Majcher, Paul Springer, Markus Hohnerbach, Jin Wang, and Manish Gupta. CUTLASS, 2023. 13
2023
-
[67]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
QuIP$\#$: Even better LLM quantization with hadamard incoherence and lattice codebooks
Albert Tseng, Jerry Chee, Qingyao Sun, V olodymyr Kuleshov, and Christopher De Sa. QuIP$\#$: Even better LLM quantization with hadamard incoherence and lattice codebooks. InForty-first International Conference on Machine Learning, 2024
2024
-
[69]
Qtip: Quantization with trellises and incoherence processing.Advances in Neural Information Processing Systems, 37:59597–59620, 2024
Albert Tseng, Qingyao Sun, David Hou, and Christopher De. Qtip: Quantization with trellises and incoherence processing.Advances in Neural Information Processing Systems, 37:59597–59620, 2024
2024
-
[70]
Gptvq: The blessing of dimensionality in llm quantization.arXiv preprint arXiv:2402.15319, 2024
Mart van Baalen, Andrey Kuzmin, Markus Nagel, Peter Couperus, Cedric Bastoul, Eric Mahurin, Tijmen Blankevoort, and Paul Whatmough. Gptvq: The blessing of dimensionality in llm quantization.arXiv preprint arXiv:2402.15319, 2024
-
[71]
Bitnet: Scaling 1-bit transformers for large language models, 2023
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. Bitnet: Scaling 1-bit transformers for large language models, 2023
2023
-
[72]
Sinder: Repairing the singular defects of dinov2
Haoqi Wang, Tong Zhang, and Mathieu Salzmann. Sinder: Repairing the singular defects of dinov2. In European Conference on Computer Vision, pages 20–35. Springer, 2024
2024
-
[73]
Demystifying singular defects in large language models
Haoqi Wang, Tong Zhang, and Mathieu Salzmann. Demystifying singular defects in large language models. InForty-second International Conference on Machine Learning, 2025
2025
-
[74]
Outlier suppression: Pushing the limit of low-bit transformer language models
Xiuying Wei, Yunchen Zhang, Xiangguo Zhang, Ruihao Gong, Shanghang Zhang, Qi Zhang, Fengwei Yu, and Xianglong Liu. Outlier suppression: Pushing the limit of low-bit transformer language models. Advances in Neural Information Processing Systems, 35:17402–17414, 2022
2022
-
[75]
Outlier suppression+: Accurate quantization of large language models by equivalent and effective shifting and scaling
Xiuying Wei, Yunchen Zhang, Yuhang Li, Xiangguo Zhang, Ruihao Gong, Jinyang Guo, and Xianglong Liu. Outlier suppression+: Accurate quantization of large language models by equivalent and effective shifting and scaling. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1648–1665, Singapore, 2023. Association fo...
2023
-
[76]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the-art...
2020
-
[77]
DFRot: Achieving outlier-free and massive activation-free for rotated LLMs with refined rotation
Jingyang Xiang and Sai Qian Zhang. DFRot: Achieving outlier-free and massive activation-free for rotated LLMs with refined rotation. InSecond Conference on Language Modeling, 2025
2025
-
[78]
SmoothQuant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. InProceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[79]
Onebit: Towards extremely low-bit large language models
Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, and Wanxiang Che. Onebit: Towards extremely low-bit large language models. InAdvances in Neural Information Processing Systems, pages 66357–66382, 2024
2024
-
[80]
CRVQ: Channel-relaxed vector quantization for extreme compression of LLMs.Transactions of the Association for Computational Linguistics (TACL), 13: 1488–1506, 2025
Yuzhuang Xu, Shiyu Ji, Qingfu Zhu, and Wanxiang Che. CRVQ: Channel-relaxed vector quantization for extreme compression of LLMs.Transactions of the Association for Computational Linguistics (TACL), 13: 1488–1506, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.