FARM: Find Anything using Relational Spatial Memory
Pith reviewed 2026-06-27 03:49 UTC · model grok-4.3
The pith
FARM retrieves objects from relational language queries by building a real-time memory that explicitly grounds spatial constraints with object symbols and predicates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
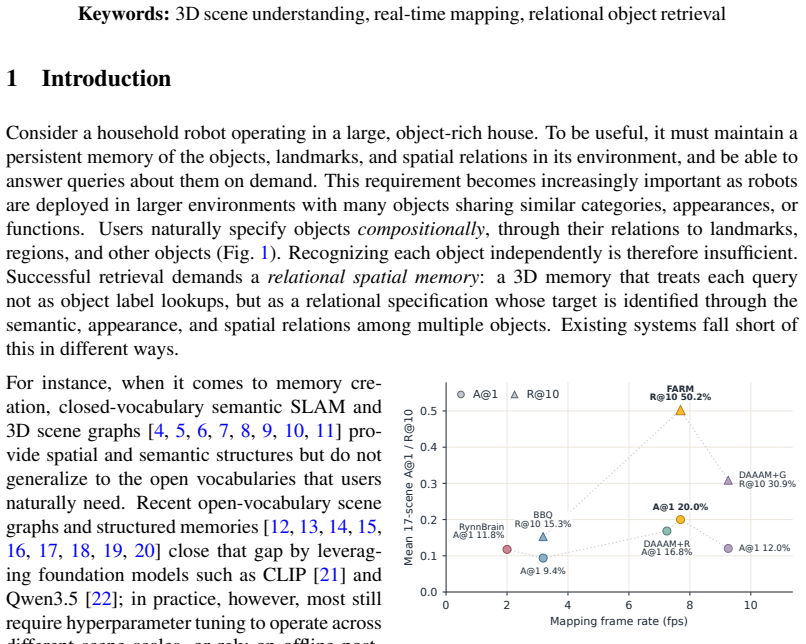
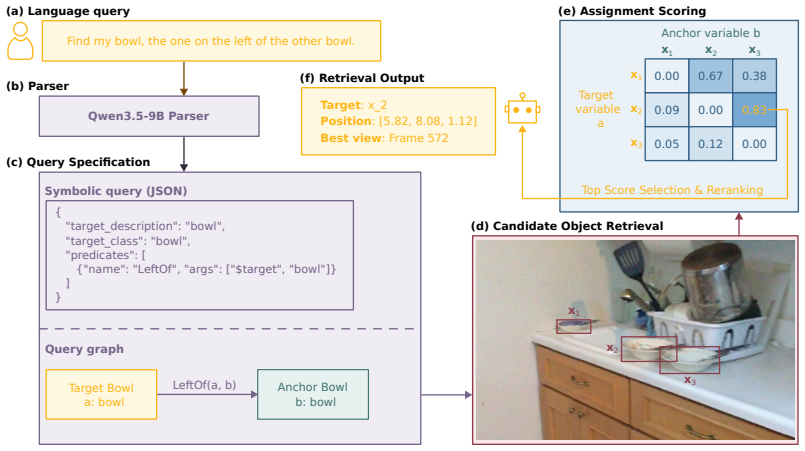
FARM builds, in real time at 5-10 Hz, a compact, open-vocabulary, object-level memory with geometry, visual-language descriptors, and viewpoint evidence. At query time, FARM uses VLMs to parse the query and score visual evidence, while grounding spatial constraints explicitly through object symbols and relational predicates. This structured use of VLMs enables more accurate and robust retrieval than end-to-end reasoning over frame histories or scene-graph context.
What carries the argument
The relational spatial memory that stores objects as symbols together with relational predicates, allowing VLMs to ground spatial constraints explicitly rather than through end-to-end frame or graph reasoning.
If this is right
- Recall@5 rises 164% and Recall@10 rises 224% relative to prior methods across the test set.
- A final VLM reranking stage raises Accuracy@1 by an additional 35%.
- The memory runs at 5-10 Hz and supports real-time closed-loop control on a quadrupedal robot with onboard compute.
Where Pith is reading between the lines
- The explicit symbolic layer may make it easier to inspect or correct individual retrieval failures without retraining the entire system.
- Because the memory is built incrementally from observations, the same structure could be extended to multi-session mapping without reprocessing all prior frames.
- Integration with symbolic planners would let the robot treat the stored predicates as facts for generating sequences of actions that satisfy relational instructions.
Load-bearing premise
Explicitly grounding spatial constraints through object symbols and relational predicates using VLMs produces more accurate retrieval than end-to-end reasoning over frame histories or scene-graph context.
What would settle it
An experiment on the same 44k queries and 67 scenes in which an end-to-end VLM method over frame histories or scene graphs matches or exceeds FARM's reported Recall@5 and Recall@10.
Figures







read the original abstract
Robots operating in homes, warehouses, and other object-rich environments need memory systems that can find specific object instances on demand. Object-level memory alone is often insufficient: scenes contain many plausibly matching objects, and users refer to the target through relations to landmarks and surrounding objects (e.g. ``the tall lamp below the dartboard and to the left of the poster''), demanding a relational spatial memory that supports retrieval through semantic, appearance, and spatial predicates over objects. To achieve this, we present FARM (Find Anything using Relational Spatial Memory), which builds, in real time at 5-10 Hz, a compact, open-vocabulary, object-level memory with geometry, visual-language descriptors, and viewpoint evidence. At query time, FARM uses VLMs to parse the query and score visual evidence, while grounding spatial constraints explicitly through object symbols and relational predicates. This structured use of VLMs enables more accurate and robust retrieval than end-to-end reasoning over frame histories or scene-graph context. In experiments on 44k language queries spanning 67 indoor and outdoor scenes, ranging from 15 to 15,000 m^2, FARM improves Recall@5 and Recall@10 over prior methods by 164% and 224%, and a final VLM reranking stage improves Accuracy@1 by 35%, while running in real time. We further demonstrate closed-loop deployment on a quadrupedal robot using onboard sensors and compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FARM, a real-time (5-10 Hz) open-vocabulary object-level memory system that augments geometry and visual-language descriptors with explicit relational spatial predicates. At query time, VLMs parse language queries into object symbols and relational constraints, which are then used to score and retrieve instances; a final VLM reranking stage is applied. On a benchmark of 44k language queries across 67 indoor/outdoor scenes (15–15,000 m²), the method reports 164% and 224% gains in Recall@5 and Recall@10 over prior methods, plus a 35% Accuracy@1 lift from reranking, and demonstrates closed-loop deployment on a quadruped.
Significance. If the reported gains are shown to arise specifically from the explicit relational grounding rather than from VLM access alone, the approach could offer a practical, scalable alternative to end-to-end frame-history or scene-graph reasoning for language-driven object retrieval in large environments. The real-time construction and onboard-robot demonstration are concrete strengths.
major comments (2)
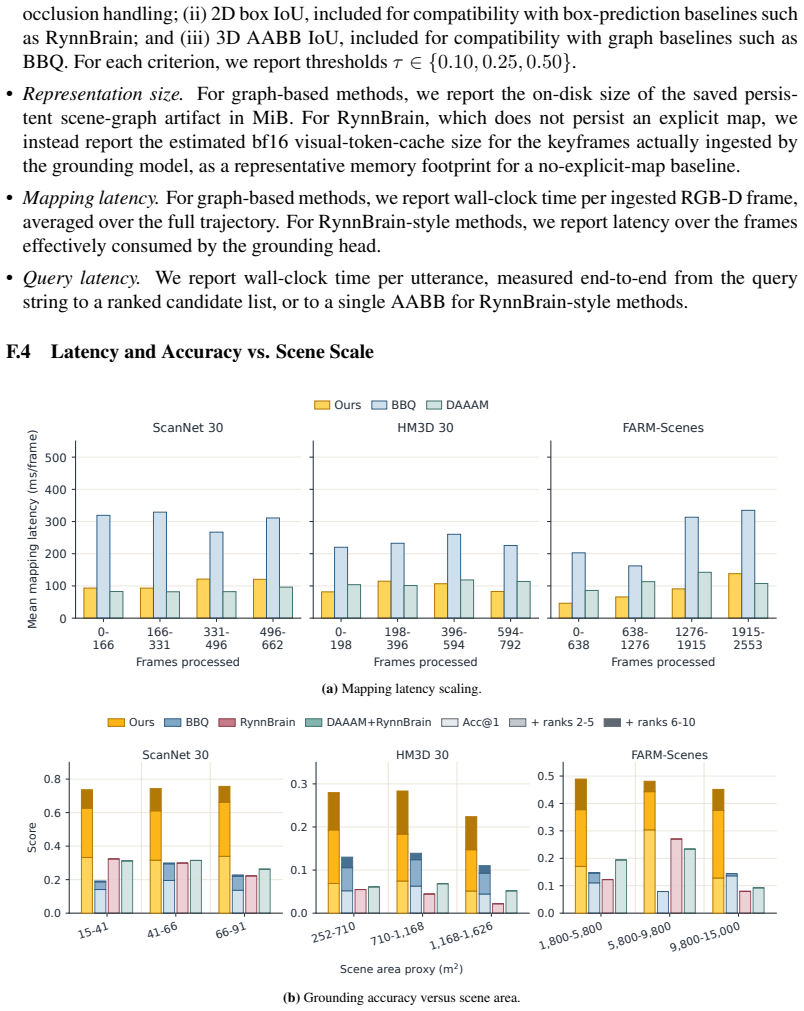
- [Abstract and experimental evaluation (no numbered section or equation supplied)] The abstract and experimental claims assert that 'structured use of VLMs' via object symbols and relational predicates outperforms end-to-end reasoning, yet no section confirms that the prior-method baselines were given identical VLM backbones, identical object detections, or identical visual-language descriptors. Without this control, the 164%/224% Recall lifts cannot be attributed to the relational structure.
- [Experimental evaluation (no numbered section or table supplied)] The 44k-query benchmark is presented without any description of the query-generation protocol, baseline implementations, error bars, statistical tests, or data-exclusion criteria. These omissions make the headline numbers impossible to interpret or reproduce.
minor comments (1)
- [Abstract] The abstract states scene sizes range 'from 15 to 15,000 m^2' but supplies no per-scene breakdown or correlation between scene scale and performance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental controls and reproducibility. We address each major comment below and will revise the manuscript accordingly to strengthen the attribution of results and provide missing methodological details.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation (no numbered section or equation supplied)] The abstract and experimental claims assert that 'structured use of VLMs' via object symbols and relational predicates outperforms end-to-end reasoning, yet no section confirms that the prior-method baselines were given identical VLM backbones, identical object detections, or identical visual-language descriptors. Without this control, the 164%/224% Recall lifts cannot be attributed to the relational structure.
Authors: We agree that the current manuscript does not explicitly document identical VLM backbones and descriptors across all baselines, which limits causal attribution to the relational predicates. In revision we will add a new subsection under Experimental Evaluation that (a) tabulates the exact VLM, detection, and descriptor inputs supplied to each baseline, (b) clarifies where end-to-end methods necessarily differ by design, and (c) reports an additional controlled ablation that isolates the relational grounding component while holding other inputs fixed. revision: yes
-
Referee: [Experimental evaluation (no numbered section or table supplied)] The 44k-query benchmark is presented without any description of the query-generation protocol, baseline implementations, error bars, statistical tests, or data-exclusion criteria. These omissions make the headline numbers impossible to interpret or reproduce.
Authors: The referee correctly identifies that these protocol details are absent from the submitted manuscript. We will expand the Experimental Evaluation section with: (1) the full query-generation procedure and any filtering rules, (2) implementation specifics and hyper-parameters for every baseline, (3) standard-error bars together with paired statistical tests (e.g., McNemar or Wilcoxon) on the Recall metrics, and (4) explicit data-exclusion criteria. These additions will be placed in both the main text and an expanded supplementary table. revision: yes
Circularity Check
No circularity: empirical system with independent experimental claims
full rationale
The paper presents FARM as an engineering system for relational spatial memory and supports its claims solely through empirical evaluation on 44k language queries across 67 scenes. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The performance deltas (Recall@5/10 lifts, Acc@1 improvement from reranking) are reported as direct experimental outcomes rather than results forced by construction from inputs or prior self-work. The comparison to baselines is presented as an external benchmark; any concerns about VLM parity in baselines fall under experimental design rather than circular reduction of the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLMs can parse queries and score visual evidence accurately enough to support relational retrieval
- domain assumption Object symbols and relational predicates can be grounded explicitly from the memory to improve accuracy over end-to-end methods
invented entities (1)
-
FARM relational spatial memory structure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Un- dersander, W. Galuba, A. Westbury, A. X. Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai.arXiv preprint arXiv:2109.08238, 2021
Pith/arXiv arXiv 2021
-
[2]
J. Frey, T. Tuna, F. Fu, K. Patterson, T. Xu, M. Fallon, C. Cadena, and M. Hutter. Grandtour: A legged robotics dataset in the wild for multi-modal perception and state estimation, 2026. URLhttps://arxiv.org/abs/2602.18164. *Equal contribution (Turcan Tuna and Jonas Frey)
arXiv 2026
-
[3]
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner. Scannet: Richly- annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5828–5839, 2017
2017
-
[4]
Rosinol, A
A. Rosinol, A. Violette, M. Abate, N. Hughes, Y . Chang, J. Shi, A. Gupta, and L. Carlone. Kimera: From slam to spatial perception with 3d dynamic scene graphs.The International Journal of Robotics Research, 40(12-14):1510–1546, 2021
2021
-
[5]
Hughes, Y
N. Hughes, Y . Chang, and L. Carlone. Hydra: A real-time spatial perception system for 3D scene graph construction and optimization. 2022
2022
-
[6]
J. Strader, N. Hughes, W. Chen, A. Speranzon, and L. Carlone. Indoor and outdoor 3d scene graph generation via language-enabled spatial ontologies.IEEE Robotics and Automation Letters, 9(6):4886–4893, 2024. doi:10.1109/LRA.2024.3384084
-
[7]
Armeni, Z.-Y
I. Armeni, Z.-Y . He, J. Gwak, A. R. Zamir, M. Fischer, J. Malik, and S. Savarese. 3d scene graph: A structure for unified semantics, 3d space, and camera. InProceedings of the IEEE International Conference on Computer Vision, pages 5664–5673, 2019
2019
-
[8]
T. Gervet, S. Chintala, D. Batra, J. Malik, and D. S. Chaplot. Navigating to objects in the real world.Science Robotics, 8(79):eadf6991, 2023. doi:10.1126/scirobotics.adf6991. URL https://www.science.org/doi/abs/10.1126/scirobotics.adf6991
-
[9]
X. Liu, G. V . Nardari, F. Cladera, Y . Tao, A. Zhou, T. Donnelly, C. Qu, S. W. Chen, R. A. F. Romero, C. J. Taylor, and V . Kumar. Large-scale autonomous flight with real-time semantic slam under dense forest canopy.IEEE Robotics and Automation Letters, 7(2):5512–5519,
-
[10]
doi:10.1109/LRA.2022.3154047
-
[11]
Y . Tao, X. Liu, I. Spasojevic, S. Agarwal, and V . Kumar. 3d active metric-semantic slam.IEEE Robotics and Automation Letters, 9(3):2989–2996, 2024. doi:10.1109/LRA.2024.3363542
-
[12]
Hou, C.-Y
H.-Y . Hou, C.-Y . Lee, M. Sonogashira, and Y . Kawanishi. FROSS: Faster-than-Real-Time Online 3D Semantic Scene Graph Generation from RGB-D Images. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 28818–28827, Octo- ber 2025
2025
-
[13]
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5021–5028. IEEE, 2024
2024
-
[14]
L. Schmid, M. Abate, Y . Chang, and L. Carlone. Khronos: A unified approach for spatio- temporal metric-semantic slam in dynamic environments. InProc. of Robotics: Science and Systems (RSS), Delft, Netherlands, July 2024. doi:10.15607/RSS.2024.XX.081
- [15]
-
[16]
S. Linok, T. Zemskova, S. Ladanova, R. Titkov, D. Yudin, M. Monastyrny, and A. Valenkov. Beyond bare queries: Open-vocabulary object grounding with 3d scene graph. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13582–13589, 2025. doi: 10.1109/ICRA55743.2025.11128059
-
[17]
Saxena, B
S. Saxena, B. Buchanan, C. Paxton, P. Liu, B. Chen, N. Vaskevicius, L. Palmieri, J. Francis, and O. Kroemer. Grapheqa: Using 3d semantic scene graphs for real-time embodied question answering. 2025
2025
-
[18]
C. D. Hsu and P. Chaudhari. Asset-centric metric-semantic maps of indoor environments,
-
[19]
URLhttps://arxiv.org/abs/2510.10778
-
[20]
S. Bharadwaj, Z. Ma, A. Ghosh, S. Seshan, and A. Rowe. Flame3d: Zero-shot compositional reasoning of 3d scenes with agentic language models, 2026. URLhttps://arxiv.org/ abs/2605.09218
Pith/arXiv arXiv 2026
-
[21]
D. Maggio, Y . Chang, N. Hughes, M. Trang, D. Griffith, C. Dougherty, E. Cristofalo, L. Schmid, and L. Carlone. Clio: Real-time task-driven open-set 3d scene graphs.IEEE Robotics and Automation Letters, 9(10):8921–8928, 2024. doi:10.1109/LRA.2024.3451395
-
[22]
Zhang, A
C. Zhang, A. Delitzas, F. Wang, R. Zhang, X. Ji, M. Pollefeys, and F. Engelmann. Open- V ocabulary Functional 3D Scene Graphs for Real-World Indoor Spaces. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[23]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[24]
Q. Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026. URLhttps://qwen.ai/blog?id=qwen3.5
2026
-
[25]
R. Dang, J. Guo, B. Hou, S. Leng, K. Li, X. Li, J. Liu, Y . Mao, Z. Wang, Y . Yuan, M. Zhu, X. Lin, Y . Bai, Q. Jiang, Y . Zhao, M. Zeng, J. Gao, Y . Jiang, J. Cen, S. Huang, L. Wang, W. Zhang, C. Liu, J. Yang, S. Lu, and D. Zhao. Rynnbrain: Open embodied foundation models. arXiv preprint arXiv:2602.14979v1, 2026. URLhttps://arxiv.org/abs/2602.14979v1
arXiv 2026
-
[26]
H. Yuan, Z. Liu, J. Zhou, H. Qian, Y . Shu, N. Sebe, J.-R. Wen, and Z. Dou. Think with videos for agentic long-video understanding, 2025. URLhttps://arxiv.org/abs/2506.10821
arXiv 2025
-
[27]
G. Team, P. Georgiev, V . I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[28]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[29]
Singh et al
A. Singh et al. Openai gpt-5 system card, 2026. URLhttps://arxiv.org/abs/2601. 03267
2026
-
[30]
E. C. Tolman. Cognitive maps in rats and men.Psychological Review, 55(4):189–208, July
-
[31]
doi:10.1037/h0061626
-
[32]
J. O’Keefe and J. Dostrovsky. The hippocampus as a spatial map. preliminary evidence from unit activity in the freely-moving rat.Brain Research, 34(1):171–175, 1971. ISSN 0006-8993. doi:https://doi.org/10.1016/0006-8993(71)90358-1. URLhttps://www.sciencedirect. com/science/article/pii/0006899371903581
-
[33]
P. Lavenex, P. B. Lavenex, and D. G. Amaral. Spatial relational learning persists following neonatal hippocampal lesions in macaque monkeys.Nature Neuroscience, 10(2):234–239, Feb. 2007. doi:10.1038/nn1820. 11
-
[34]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, O. H´enaff, J. Harmsen, A. Steiner, and X. Zhai. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[35]
M. Li, Y . Zhang, D. Long, K. Chen, S. Song, S. Bai, Z. Yang, P. Xie, A. Yang, D. Liu, J. Zhou, and J. Lin. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of- the-art multimodal retrieval and ranking.arXiv, 2026
2026
-
[36]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[37]
Q. Team. Qwen3.5-omni technical report, 2026. URLhttps://arxiv.org/abs/2604. 15804
2026
-
[38]
Achlioptas, A
P. Achlioptas, A. Abdelreheem, F. Xia, M. Elhoseiny, and L. J. Guibas. ReferIt3D: Neural listeners for fine-grained 3d object identification in real-world scenes. In16th European Con- ference on Computer Vision (ECCV), 2020
2020
-
[39]
H. Zhang, N. Zantout, P. Kachana, J. Zhang, and W. Wang. Iref-vla: A benchmark for interactive referential grounding with imperfect language in 3d scenes. In2025 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 1677–1683, 2025. doi: 10.1109/ICRA55743.2025.11127464
-
[40]
J. Frey, T. Tuna, L. F. T. Fu, C. Weibel, K. Patterson, B. Krummenacher, M. M¨uller, J. Nubert, M. Fallon, C. Cadena, and M. Hutter. Boxi: Design Decisions in the Context of Algorithmic Performance for Robotics. InProceedings of Robotics: Science and Systems, Los Angeles, United States, July 2025. *Equal contribution (Jonas Frey and Turcan Tuna and Frank Fu)
2025
-
[41]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Cou- prie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski. DINOv3, 2025. URLhttps: //arxiv.org/...
Pith/arXiv arXiv 2025
-
[42]
L. Lian, Y . Ding, Y . Ge, S. Liu, H. Mao, B. Li, M. Pavone, M.-Y . Liu, T. Darrell, A. Yala, and Y . Cui. Describe anything: Detailed localized image and video captioning.arXiv preprint arXiv:2504.16072, 2025
arXiv 2025
-
[43]
A. Wang, L. Liu, H. Chen, Z. Lin, J. Han, and G. Ding. Yoloe: Real-time seeing anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 24591–24602, October 2025
2025
-
[44]
Raffel, N
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020. URLhttp://jmlr.org/papers/v21/ 20-074.html
2020
-
[45]
D. Z. Chen, A. X. Chang, and M. Nießner. Scanrefer: 3d object localization in rgb-d scans us- ing natural language. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XX 16, pages 202–221. Springer, 2020
2020
-
[46]
Z. Fu, R. Zurbr ¨ugg, K. Qu, M. Pollefeys, M. Hutter, H. Blum, and Z. Bauer. Funfact: Building probabilistic functional 3d scene graphs via factor-graph reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026. 12
2026
-
[47]
T. Winograd. Understanding natural language.Cognitive Psychology, 3(1):1–191, 1972. ISSN 0010-0285. doi:https://doi.org/10.1016/0010-0285(72)90002-3. URLhttps://www. sciencedirect.com/science/article/pii/0010028572900023
-
[48]
J. Shi, H. Zhang, and J. Li. Explainable and explicit visual reasoning over scene graphs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[49]
M. G. Sethuraman, A. Payani, F. Fekri, and J. C. Kerce. Visual question answering based on formal logic. In2021 20th IEEE International Conference on Machine Learning and Applica- tions (ICMLA), pages 952–957, 2021. doi:10.1109/ICMLA52953.2021.00157
-
[50]
D. Ekpo, M. Levy, S. Suri, C. Huynh, A. Swaminathan, and A. Shrivastava. Verigraph: Scene graphs for execution verifiable robot planning. InProceedings of the IEEE International Con- ference on Robotics and Automation (ICRA), 2026
2026
-
[51]
A. Ray, C. Bradley, L. Carlone, and N. Roy. Task and motion planning in hierarchical 3D scene graphs. Inisrr, 2024
2024
-
[52]
A. Ray, J. Arkin, H. Biggie, C. Fan, L. Carlone, and N. Roy. Structured interfaces for automated reasoning with 3d scene graphs, 2025. URLhttps://arxiv.org/abs/2510.16643
arXiv 2025
-
[53]
Z. Dai, A. Asgharivaskasi, T. Duong, S. Lin, M.-E. Tzes, G. Pappas, and N. Atanasov. Optimal scene graph planning with large language model guidance. In2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 14062–14069, 2024. doi: 10.1109/ICRA57147.2024.10610599
-
[54]
Y . Zhu, J. Tremblay, S. Birchfield, and Y . Zhu. Hierarchical planning for long-horizon manip- ulation with geometric and symbolic scene graphs. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 6541–6548, 2021. doi:10.1109/ICRA48506.2021. 9561548
-
[55]
K. Kask, R. Dechter, J. Larrosa, and A. Dechter. Unifying tree decompositions for reasoning in graphical models.Artificial Intelligence, 166(1):165–193, 2005. ISSN 0004-3702. doi:https:// doi.org/10.1016/j.artint.2005.04.004. URLhttps://www.sciencedirect.com/science/ article/pii/S0004370205000639
-
[56]
B. Yi, C. M. Kim, J. Kerr, G. Wu, R. Feng, A. Zhang, J. Kulhanek, H. Choi, Y . Ma, M. Tancik, and A. Kanazawa. Viser: Imperative, web-based 3d visualization in python.arXiv preprint arXiv:2507.22885, 2025
arXiv 2025
-
[57]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll´ar, and R. Girshick. Segment anything.arXiv:2304.02643, 2023
Pith/arXiv arXiv 2023
-
[58]
X. Puig, E. Undersander, A. Szot, M. D. Cote, R. Partsey, J. Yang, R. Desai, A. W. Clegg, M. Hlavac, T. Min, T. Gervet, V . V ondruˇs, V .-P. Berges, J. Turner, O. Maksymets, Z. Kira, M. Kalakrishnan, J. Malik, D. S. Chaplot, U. Jain, D. Batra, A. Rai, and R. Mottaghi. Habitat 3.0: A co-habitat for humans, avatars and robots, 2023. 13 Supplementary Materi...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.