BMCR: Adaptive Backbone Module Composition via Reinforcement Learning for Remote Sensing Object Detection
Pith reviewed 2026-06-28 02:49 UTC · model grok-4.3
The pith
BMCR dynamically composes CNN and ViT modules via reinforcement learning for adaptive remote sensing object detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
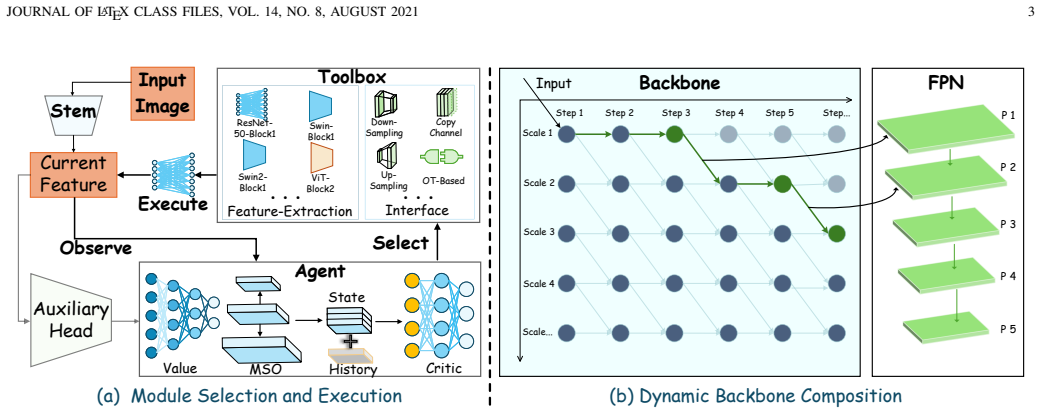
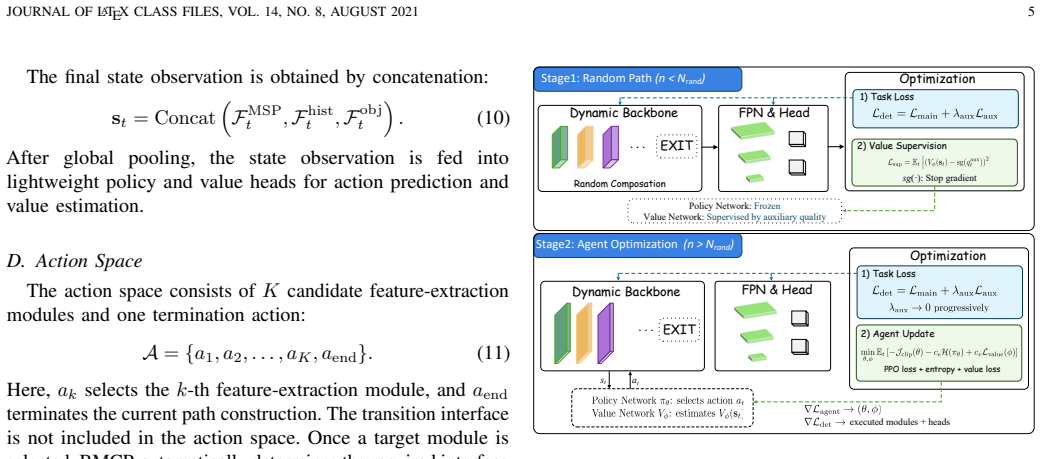
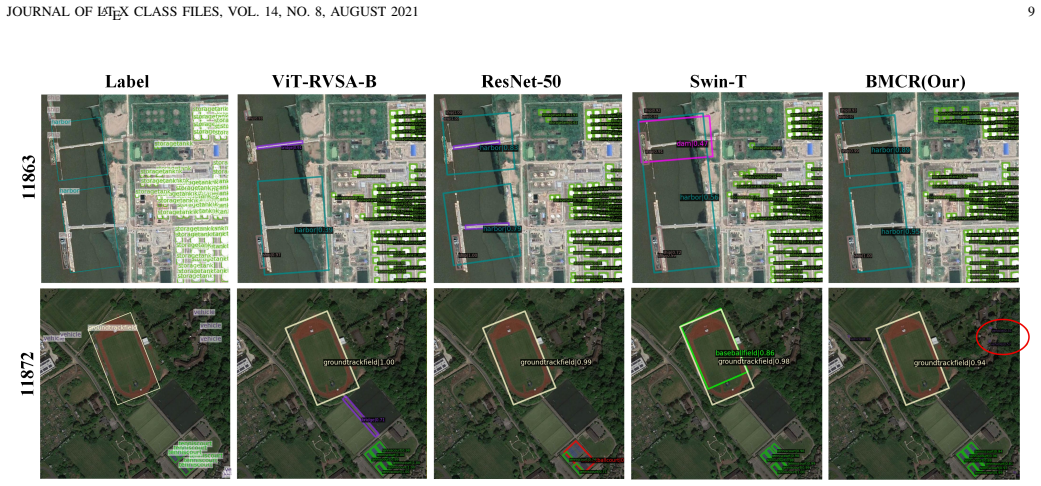
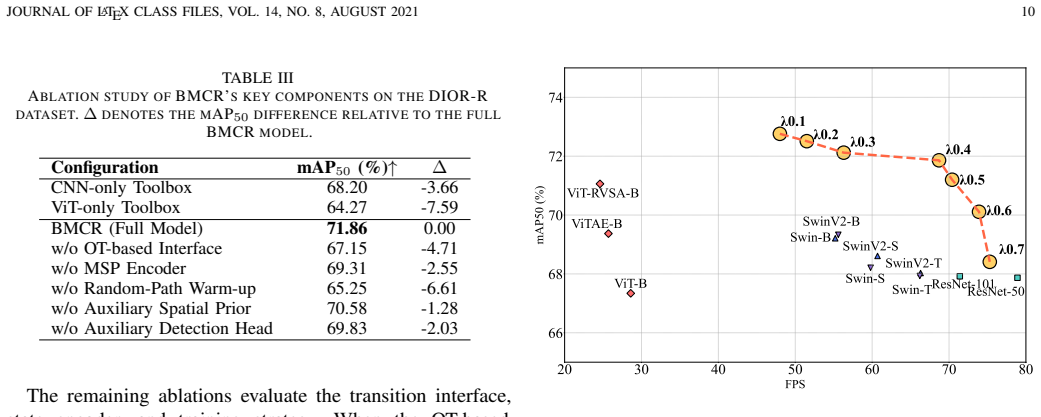
BMCR decomposes representative CNN and ViT backbones into reusable functional modules encapsulated with structural, semantic, and computational metadata, bridges them via a lightweight Optimal Transport transition interface that aligns grid-based and token-based representations in a distribution-aware way, and formulates composition as a sequential decision process solved by a policy network that selects modules according to intermediate multi-scale observations, with Adaptive Module Cooperative Optimization coordinating updates to achieve 79.31 percent, 73.41 percent and 71.86 percent mAP on DOTA-v1.0, DOTA-v1.5 and DIOR-R.
What carries the argument
The reinforcement learning policy network that progressively selects task-relevant modules from the extensible toolbox, coordinated by AMCO and enabled by the Optimal Transport transition interface for cross-family alignment.
Load-bearing premise
The Optimal Transport based transition interface can align grid-based CNN features with token-based ViT representations in a distribution-aware manner that preserves spatial consistency and enables effective cross-family module composition without introducing errors that offset the adaptive gains.
What would settle it
An experiment showing BMCR mAP on DOTA-v1.0, DOTA-v1.5 or DIOR-R falling below the strongest static or dynamic baseline by the reported margins would falsify the performance claim.
Figures




read the original abstract
In remote sensing object detection, Convolutional Neural Networks (CNNs) excel at capturing local details while Vision Transformers (ViTs) are better at global context modeling. However, existing detectors typically rely on a single fixed backbone or a manually designed hybrid architecture, and thus fail to adaptively exploit these complementary strengths across inputs of diverse complexity. To address this limitation, we propose Backbone Module Composition via Reinforcement Learning (BMCR). BMCR dynamically assembles input-adaptive inference paths from reusable modules decomposed from off-the-shelf CNN and ViT backbones. To enable such cross-family composition, we first construct an extensible module toolbox. Specifically, we decompose representative CNN and ViT backbones into reusable functional modules and encapsulate each module with explicit structural, semantic, and computational metadata for compatibility-aware assembly. To bridge the gap between grid-based CNN features and token-based ViT representations, we design a lightweight Optimal Transport (OT) based transition interface that ensures distribution-aware alignment while respecting spatial consistency. The backbone composition process is then formulated as a sequential decision problem, in which a policy network progressively selects task-relevant modules according to intermediate multi-scale observations. To stabilize the joint optimization of reusable modules and the routing policy, we further develop an Adaptive Module Cooperative Optimization (AMCO) strategy that coordinates module updating, routing exploration, and reward assignment during training. On DOTA-v1.0, DOTA-v1.5 and DIOR-R, BMCR achieves 79.31\%, 73.41\% and 71.86\% mAP, respectively, surpassing strong static and dynamic baselines by up to 2.5 points while maintaining competitive efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BMCR for remote sensing object detection, which decomposes off-the-shelf CNN and ViT backbones into reusable modules stored in an extensible toolbox, employs a lightweight Optimal Transport based transition interface to align grid-based CNN features with token-based ViT representations, formulates backbone composition as a sequential decision process solved by a policy network, and introduces an Adaptive Module Cooperative Optimization (AMCO) strategy to jointly train the modules and routing policy. It reports mAP values of 79.31%, 73.41% and 71.86% on DOTA-v1.0, DOTA-v1.5 and DIOR-R respectively, claiming gains of up to 2.5 points over strong static and dynamic baselines while preserving efficiency.
Significance. If the central claim of effective cross-family adaptive composition is substantiated, the work would be significant for remote sensing detection by providing a principled mechanism to exploit complementary local-detail and global-context strengths on a per-input basis rather than relying on fixed or manually designed hybrids.
major comments (2)
- [Abstract] Abstract: the performance claims (79.31% mAP on DOTA-v1.0 etc.) and superiority statements are presented without any experimental protocol, baseline definitions, statistical tests, ablation studies, or implementation details, so the central empirical claim cannot be evaluated.
- [Abstract] Abstract: the Optimal Transport based transition interface and AMCO strategy are described only at high level with no equations, pseudocode, or formal definitions, preventing assessment of whether the alignment preserves spatial consistency or whether the reward signal is independent of fitted quantities.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our submission. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims (79.31% mAP on DOTA-v1.0 etc.) and superiority statements are presented without any experimental protocol, baseline definitions, statistical tests, ablation studies, or implementation details, so the central empirical claim cannot be evaluated.
Authors: The abstract is designed to be a concise summary of the paper's contributions and results, adhering to typical length constraints. The full experimental protocol, baseline definitions, statistical tests, ablation studies, and implementation details are thoroughly described in Sections 4.1 through 4.4 of the manuscript. We believe the central claims can be evaluated from the complete paper, and the abstract highlights the key outcomes. revision: no
-
Referee: [Abstract] Abstract: the Optimal Transport based transition interface and AMCO strategy are described only at high level with no equations, pseudocode, or formal definitions, preventing assessment of whether the alignment preserves spatial consistency or whether the reward signal is independent of fitted quantities.
Authors: Similar to the performance claims, the abstract provides a high-level overview of the proposed OT-based transition interface and AMCO strategy. Detailed equations, formal definitions, pseudocode (including Algorithm 1), and discussions on spatial consistency and reward signal independence are presented in Sections 3.2 and 3.4 of the manuscript. These sections allow for full assessment of the technical aspects. revision: no
Circularity Check
No significant circularity identified
full rationale
The abstract and available text describe BMCR at a conceptual level (module decomposition from CNN/ViT backbones, OT-based transition interface, policy network for sequential decisions, and AMCO for joint optimization) without presenting any equations, fitted parameters, or derivations. No self-citations, uniqueness theorems, or ansatzes are quoted that reduce a claimed prediction or result to an input by construction. The reported mAP gains are presented as empirical outcomes on DOTA and DIOR-R datasets rather than tautological outputs of the method's own definitions. Absent specific technical details or equations from the full manuscript that exhibit reduction (e.g., reward signal equaling a fitted quantity), no load-bearing circular steps exist.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Artificial intelligence to advance earth observation: A review of models, recent trends, and pathways forward,
D. Tuia, K. Schindler, B. Demir, X. X. Zhu, M. Kochupillai, S. D ˇzeroski, J. N. van Rijn, H. H. Hoos, F. Del Frate, M. Datcuet al., “Artificial intelligence to advance earth observation: A review of models, recent trends, and pathways forward,”IEEE Geoscience and Remote Sensing Magazine, 2024
2024
-
[2]
Open high-resolution satellite imagery: The worldstrat dataset–with application to super-resolution,
J. Cornebise, I. Or ˇsoli´c, and F. Kalaitzis, “Open high-resolution satellite imagery: The worldstrat dataset–with application to super-resolution,” in Advances in Neural Information Processing Systems, vol. 35, 2022, pp. 25 979–25 991
2022
-
[3]
Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery,
X. Guo, J. Lao, B. Dang, Y . Zhang, L. Yu, L. Ru, L. Zhong, Z. Huang, K. Wu, D. Hu, H. He, J. Wang, J. Chen, M. Yang, Y . Zhang, and Y . Li, “Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, June 2024...
2024
-
[4]
Ringmo: A remote sensing foundation model with masked image modeling,
X. Sun, P. Wang, W. Lu, Z. Zhu, X. Lu, Q. He, J. Li, X. Rong, Z. Yang, H. Chang, Q. He, G. Yang, R. Wang, J. Lu, and K. Fu, “Ringmo: A remote sensing foundation model with masked image modeling,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–22, 2023
2023
-
[5]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[6]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
2021
-
[7]
A battle of network structures: An empirical study of CNN, transformer, and MLP,
Y . Zhao, G. Wang, C. Tang, C. Luo, W. Zeng, and Z.-J. Zha, “A battle of network structures: An empirical study of CNN, transformer, and MLP,” arXiv preprint arXiv:2108.13002, 2021
arXiv 2021
-
[8]
Dynamicvis: An efficient and general visual foundation model for remote sensing image understanding,
K. Chen, C. Liu, B. Chen, W. Li, Z. Zou, and Z. Shi, “Dynamicvis: An efficient and general visual foundation model for remote sensing image understanding,”arXiv preprint arXiv:2503.16426, 2025
arXiv 2025
-
[9]
Fastervit: Fast vision transformers with hierarchical attention,
A. Hatamizadeh, G. Heinrich, H. Yin, A. Tao, J. M. Alvarez, J. Kautz, and P. Molchanov, “Fastervit: Fast vision transformers with hierarchical attention,” inInternational Conference on Learning Representations, B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, Eds., vol. 2024, 2024, pp. 29 368–29 391
2024
-
[10]
Path-restore: Learning network path selection for image restoration,
K. Yu, X. Wang, C. Dong, X. Tang, and C. C. Loy, “Path-restore: Learning network path selection for image restoration,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 7078–7092, 2022
2022
-
[11]
Pathnet: Path- selective point cloud denoising,
Z. Wei, H. Chen, L. Nan, J. Wang, J. Qin, and M. Wei, “Pathnet: Path- selective point cloud denoising,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 6, pp. 4426–4442, 2024
2024
-
[12]
Deep learning in multimodal remote sensing data fusion: A comprehen- sive review,
J. Li, D. Hong, L. Gao, J. Yao, K. Zheng, B. Zhang, and J. Chanussot, “Deep learning in multimodal remote sensing data fusion: A comprehen- sive review,”International Journal of Applied Earth Observation and Geoinformation, vol. 112, p. 102926, 2022
2022
-
[13]
Efficient adaptive feature fusion network for remote-sensing image super-resolution,
S. Hao, S. Liu, X. Jia, H. Lu, and Y . He, “Efficient adaptive feature fusion network for remote-sensing image super-resolution,”IEEE Signal Processing Letters, 2024
2024
-
[14]
DOTA: A large-scale dataset for object detection in aerial images,
G.-S. Xia, X. Bai, J. Ding, Z. Zhu, S. Belongie, J. Luo, M. Datcu, M. Pelillo, and L. Zhang, “DOTA: A large-scale dataset for object detection in aerial images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 3974–3983
2018
-
[15]
Branchynet: Fast inference via early exiting from deep neural networks,
S. Teerapittayanon, B. McDanel, and H.-T. Kung, “Branchynet: Fast inference via early exiting from deep neural networks,” inInternational Conference on Pattern Recognition. IEEE, 2016, pp. 2464–2469
2016
-
[16]
Beem: Boosting performance of early exit dnns using multi-exit classifiers as experts,
D. J. Bajpai and M. K. Hanawal, “Beem: Boosting performance of early exit dnns using multi-exit classifiers as experts,” inInternational Conference on Learning Representations, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., vol. 2025, 2025, pp. 62 520–62 535
2025
-
[17]
Skipnet: Learning dynamic routing in convolutional networks,
X. Wang, F. Yu, Z.-Y . Dou, T. Darrell, and J. E. Gonzalez, “Skipnet: Learning dynamic routing in convolutional networks,” inProceedings of the European Conference on Computer Vision, 2018, pp. 409–424
2018
-
[18]
Not all layers of llms are necessary during inference,
S. Fan, X. Jiang, X. Li, X. Meng, P. Han, S. Shang, A. Sun, Y . Wang, and Z. Wang, “Not all layers of llms are necessary during inference,” arXiv preprint arXiv:2403.02181, 2024
arXiv 2024
-
[19]
Skipdiff: Adaptive skip diffusion model for high-fidelity perceptual image super-resolution,
X. Luo, Y . Xie, Y . Qu, and Y . Fu, “Skipdiff: Adaptive skip diffusion model for high-fidelity perceptual image super-resolution,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 5, 2024, pp. 4017–4025
2024
-
[20]
Dynamic convolution: Attention over convolution kernels,
Y . Chen, X. Dai, M. Liu, D. Chen, L. Yuan, and Z. Liu, “Dynamic convolution: Attention over convolution kernels,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 030–11 039
2020
-
[21]
Deformable convolutional networks,
J. Dai, H. Qi, Y . Xiong, Y . Li, G. Zhang, H. Hu, and Y . Wei, “Deformable convolutional networks,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2017, pp. 764–773
2017
-
[22]
Internimage: Exploring large-scale vision foundation models with deformable convolutions,
W. Wang, J. Dai, Z. Chen, Z. Huang, Z. Li, X. Zhu, X. Hu, T. Lu, L. Lu, H. Liet al., “Internimage: Exploring large-scale vision foundation models with deformable convolutions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14 408–14 419
2023
-
[23]
Lsknet: Large selective kernel network for remote sensing object detection,
Y . Li, Q. Hou, and Z. Zheng, “Lsknet: Large selective kernel network for remote sensing object detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4–6
2023
-
[24]
Transxnet: learning both global and local dynamics with a dual dynamic token mixer for visual recognition,
M. Lou, S. Zhang, H.-Y . Zhou, S. Yang, C. Wu, and Y . Yu, “Transxnet: learning both global and local dynamics with a dual dynamic token mixer for visual recognition,”IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[25]
Vision transformer adapter for dense predictions,
Z. Chen, Y . Duan, W. Wang, J. He, T. Lu, J. Dai, and Y . Qiao, “Vision transformer adapter for dense predictions,” inInternational Conference on Learning Representations, 2023
2023
-
[26]
Conformer: Local features coupling global representations for visual recognition,
Z. Peng, W. Huang, S. Gu, L. Xie, Y . Wang, J. Jiao, and Q. Ye, “Conformer: Local features coupling global representations for visual recognition,”arXiv preprint arXiv:2105.03889, 2021
arXiv 2021
-
[27]
Coatnet: Marrying convolution and attention for all data sizes,
Z. Dai, H. Liu, Q. V . Le, and M. Tan, “Coatnet: Marrying convolution and attention for all data sizes,”Advances in Neural Information Processing Systems, vol. 34, pp. 3965–3977, 2021
2021
-
[28]
Next-ViT: Next generation vision transformer for efficient deployment in realistic industrial scenarios,
J. Li, X. Xia, W. Li, H. Li, X. Wang, X. Xiao, R. Wang, M. Zheng, and X. Pan, “Next-ViT: Next generation vision transformer for efficient deployment in realistic industrial scenarios,”CoRR, 2022
2022
-
[29]
Cta-net: A CNN-transformer aggregation network for improving multi-scale feature extraction,
C. Meng, J. Yang, W. Lin, B. Liu, H. Zhang, Z. Ganet al., “Cta-net: A CNN-transformer aggregation network for improving multi-scale feature extraction,”arXiv preprint arXiv:2410.11428, 2024
arXiv 2024
-
[30]
Learning when and where to zoom with deep reinforcement learning,
B. Uzkent and S. Ermon, “Learning when and where to zoom with deep reinforcement learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 12 345–12 354
2020
-
[31]
Deep reinforcement learning for band selection in hyperspectral image classification,
L. Mou, S. Saha, Y . Hua, F. Bovolo, L. Bruzzone, and X. X. Zhu, “Deep reinforcement learning for band selection in hyperspectral image classification,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2021
2021
-
[32]
Seeing beyond the patch: Scale-adaptive semantic segmentation of high-resolution remote sensing imagery based on reinforcement learning,
Y . Liu, S. Shi, J. Wang, and Y . Zhong, “Seeing beyond the patch: Scale-adaptive semantic segmentation of high-resolution remote sensing imagery based on reinforcement learning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 16 868–16 878. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14
2023
-
[33]
Scale-aware deep reinforcement learning for high resolution remote sensing imagery classification,
Y . Liu, Y . Zhong, S. Shi, and L. Zhang, “Scale-aware deep reinforcement learning for high resolution remote sensing imagery classification,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 209, pp. 296–311, 2024
2024
-
[34]
On learning intrinsic rewards for policy gradient methods,
Z. Zheng, J. Oh, and S. Singh, “On learning intrinsic rewards for policy gradient methods,” inAdvances in Neural Information Processing Systems, 2018, pp. 4649–4659
2018
-
[35]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10 012–10 022
2021
-
[36]
Swin transformer v2: Scaling up capacity and resolution,
Z. Liu, H. Hu, Y . Lin, Z. Yao, Z. Xie, Y . Wei, J. Ning, Y . Cao, Z. Zhang, L. Donget al., “Swin transformer v2: Scaling up capacity and resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 009–12 019
2022
-
[37]
Vitae: Vision transformer advanced by exploring intrinsic inductive bias,
Y . Xu, Q. Zhang, J. Zhang, and D. Tao, “Vitae: Vision transformer advanced by exploring intrinsic inductive bias,”Advances in Neural Information Processing Systems, vol. 34, pp. 28 522–28 535, 2021
2021
-
[38]
An empirical study of remote sensing pretraining,
D. Wang, J. Zhang, B. Du, G.-S. Xia, and D. Tao, “An empirical study of remote sensing pretraining,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, 2022
2022
-
[39]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132–7141
2018
-
[40]
Coordinate attention for efficient mobile network design,
Q. Hou, C. Wang, D. Cheng, X. Cai, G. Xu, and Y . Wang, “Coordinate attention for efficient mobile network design,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 310–14 320
2021
-
[41]
Prox- imal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[42]
Object detection in aerial images: A large-scale benchmark and challenges,
J. Ding, N. Xue, G.-S. Xia, X. Bai, W. Yang, M. Y . Yang, S. Belongie, J. Luo, M. Datcu, M. Pelillo, and L. Zhang, “Object detection in aerial images: A large-scale benchmark and challenges,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 11, pp. 7778–7796, 2022
2022
-
[43]
Object detection in optical remote sensing images: A survey and a new benchmark,
K. Li, G. Wan, G. Cheng, L. Meng, and J. Han, “Object detection in optical remote sensing images: A survey and a new benchmark,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 159, pp. 296–307, 2020
2020
-
[44]
FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery,
X. Sun, P. Wang, Z. Yan, F. Xu, R. Wang, W. Diao, J. Chen, J. Li, Y . Feng, T. Xuet al., “FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 184, pp. 116–130, 2022
2022
-
[45]
Emo2-DETR: Efficient-matching oriented object detection with transformers,
Z. Hu, K. Gao, X. Zhang, J. Wang, H. Wang, Z. Yang, C. Li, and W. Li, “Emo2-DETR: Efficient-matching oriented object detection with transformers,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–14, 2023
2023
-
[46]
Oriented R-CNN for object detection,
X. Xie, G. Cheng, J. Wang, X. Yao, and J. Han, “Oriented R-CNN for object detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, October 2021, pp. 3520–3529
2021
-
[47]
Orientedformer: An end-to-end transformer-based oriented object detector in remote sensing images,
J. Zhao, Z. Ding, Y . Zhou, H. Zhu, W.-L. Du, R. Yao, and A. El Sad- dik, “Orientedformer: An end-to-end transformer-based oriented object detector in remote sensing images,”IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[48]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition challenge,”International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015
2015
-
[49]
Poly kernel inception network for remote sensing detection,
X. Cai, Q. Lai, Y . Wang, W. Wang, Z. Sun, and Y . Yao, “Poly kernel inception network for remote sensing detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 706–27 716
2024
-
[50]
Advancing plain vision transformer toward remote sensing foundation model,
D. Wang, Q. Zhang, Y . Xu, J. Zhang, B. Du, D. Tao, and L. Zhang, “Advancing plain vision transformer toward remote sensing foundation model,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–15, 2022
2022
-
[51]
Adaptive rotated convolution for rotated object detection,
Y . Pu, Y . Wang, Z. Xia, Y . Han, Y . Wang, W. Gan, Z. Wang, S. Song, and G. Huang, “Adaptive rotated convolution for rotated object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6589–6600
2023
-
[52]
Learning roi transformer for oriented object detection in aerial images,
J. Ding, N. Xue, Y . Long, G.-S. Xia, and Q. Lu, “Learning roi transformer for oriented object detection in aerial images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2844–2853
2019
-
[53]
A billion-scale foundation model for remote sensing images,
K. Cha, J. Seo, and T. Lee, “A billion-scale foundation model for remote sensing images,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024
2024
-
[54]
The kfiou loss for rotated object detection,
X. Yang, Y . Zhou, G. Zhang, J. Yang, W. Wang, J. Yan, X. Zhang, and Q. Tian, “The kfiou loss for rotated object detection,”arXiv preprint arXiv:2201.12558, 2022
arXiv 2022
-
[55]
Rqformer: Rotated query transformer for end-to-end oriented object detection,
J. Zhao, Z. Ding, Y . Zhou, H. Zhu, W.-L. Du, R. Yao, and A. El Saddik, “Rqformer: Rotated query transformer for end-to-end oriented object detection,”Expert Systems with Applications, vol. 266, p. 126034, 2025
2025
-
[56]
A unified remote sensing object detector based on fourier contour parametric learning,
T. Zhang, Y . Zhuang, G. Wang, H. Chen, L. Li, and J. Li, “A unified remote sensing object detector based on fourier contour parametric learning,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–25, 2025
2025
-
[57]
Ars-DETR: Aspect ratio-sensitive detection transformer for aerial oriented object detection,
Y . Zeng, Y . Chen, X. Yang, Q. Li, and J. Yan, “Ars-DETR: Aspect ratio-sensitive detection transformer for aerial oriented object detection,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–15, 2024
2024
-
[58]
Strip r-CNN: Large strip convolution for remote sensing object detection,
X. Yuan, Z. Zheng, Y . Li, X. Liu, L. Liu, X. Li, Q. Hou, and M.- M. Cheng, “Strip r-CNN: Large strip convolution for remote sensing object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 15, 2026, pp. 12 259–12 267
2026
-
[59]
Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement,
W. Kool, H. Van Hoof, and M. Welling, “Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement,” inProceedings of the International Conference on Machine Learning. PMLR, 2019, pp. 3499–3508. Wenlin Liureceived his BS degree from the Nanjing University of Aeronautics and Astronautics in 2021, and he is cur...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.