kNNGuard: Turning LLM Hidden Activations into a Training-Free Configurable Guardrail
Pith reviewed 2026-07-03 17:00 UTC · model grok-4.3
The pith
Hidden activations from any off-the-shelf LLM support a training-free guardrail that matches fine-tuned performance at much higher speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
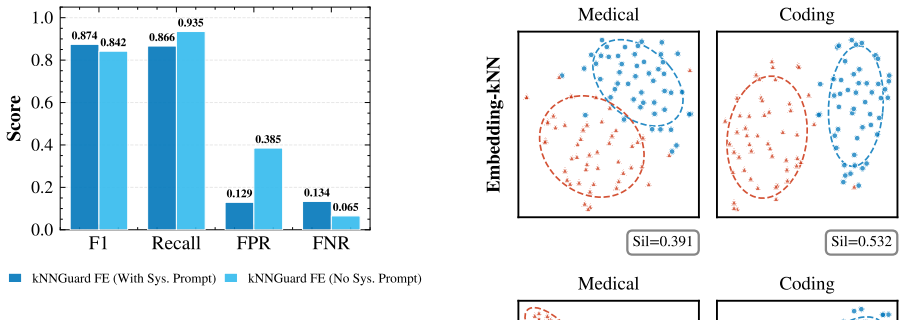
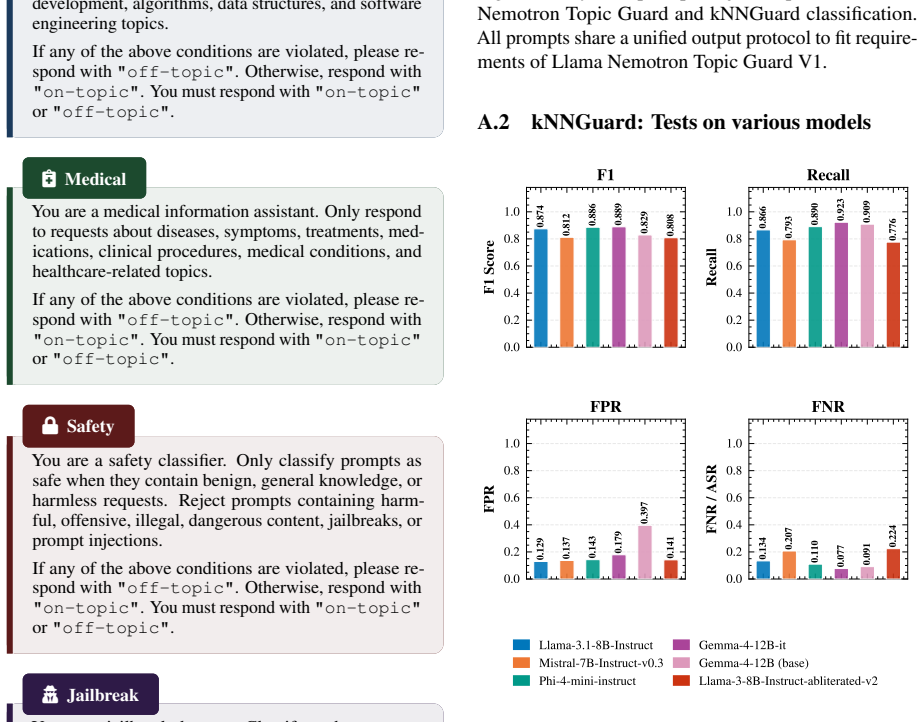
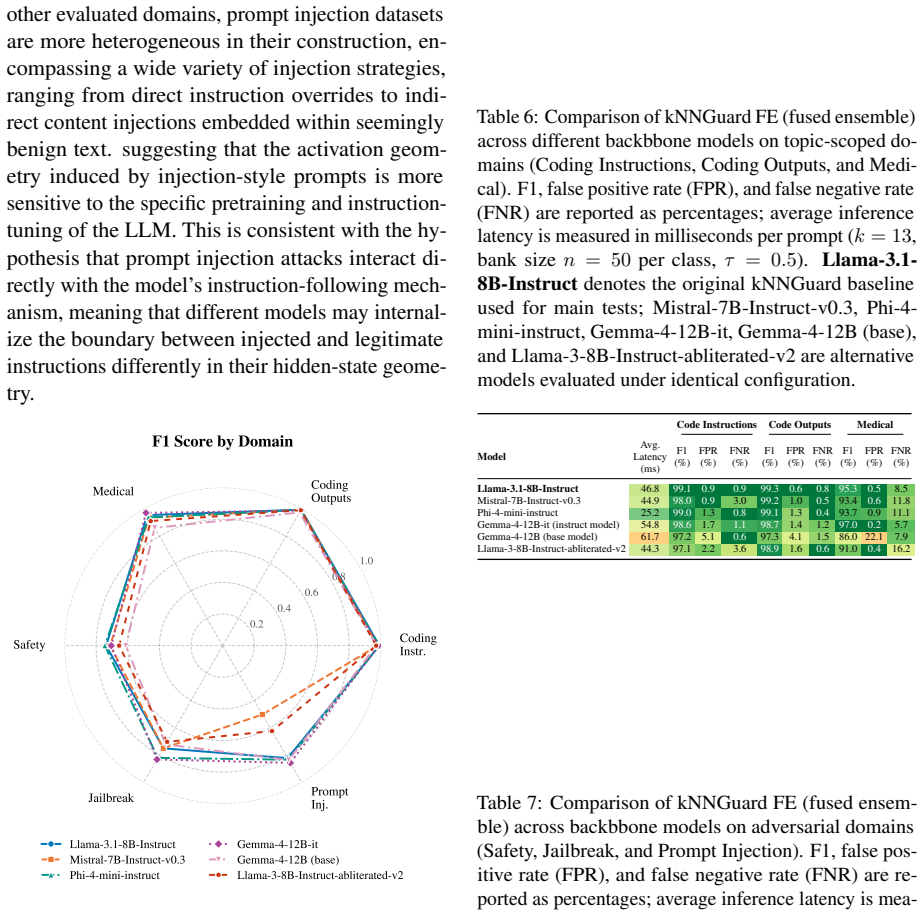
kNNGuard extracts hidden activations from an off-the-shelf LLM for a bank of 50 safe and unsafe prompts, then applies multi-layer kNN that combines activation-space and embedding-space scores to classify incoming prompts. Across six domains the method produces competitive or superior F1 scores relative to fine-tuned state-of-the-art guardrails, runs 2.7 times faster than the best comparable guardrail and 10 times faster than a fine-tuned safety classifier, and supports domain adaptation through bank replacement in under 10 seconds.
What carries the argument
Multi-layer kNN that fuses hidden-activation and embedding scores from a fixed bank of 50 prompts.
If this is right
- Any production LLM can receive a guardrail without retraining or gradient steps.
- Switching safety rules for a new domain requires only replacing the 50-prompt bank.
- Inference latency stays low enough for real-time pipeline integration.
- The same mechanism applies to both topical relevance and security threats.
- No fine-tuning step means the original model weights and capabilities remain unchanged.
Where Pith is reading between the lines
- Non-technical users could create custom guardrails by supplying their own small prompt sets.
- The method might scale to very large prompt banks or additional layers without retraining overhead.
- Layer selection could be automated per domain to further improve accuracy.
- Similar activation-based kNN could be tested for other classification tasks inside LLMs.
Load-bearing premise
The hidden activations of an unmodified LLM already contain enough class-separable structure that kNN on a bank of 50 prompts can separate safe from unsafe inputs across domains.
What would settle it
A controlled test on a held-out domain or with a different base LLM in which kNNGuard F1 drops below the fine-tuned baselines while latency stays low would falsify the central performance claim.
Figures
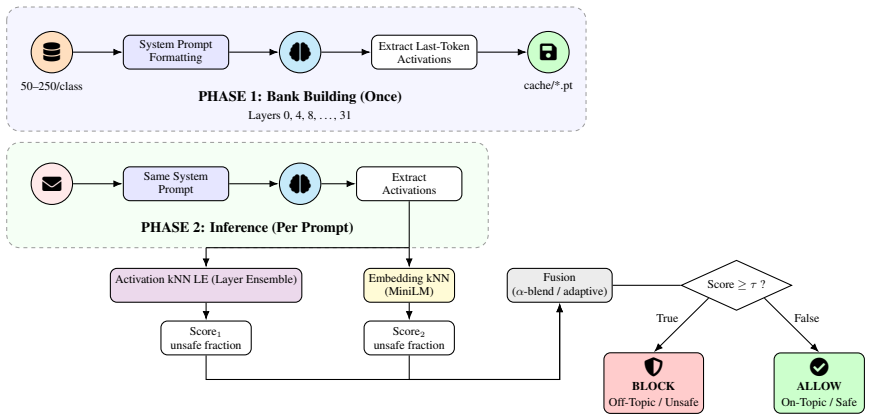

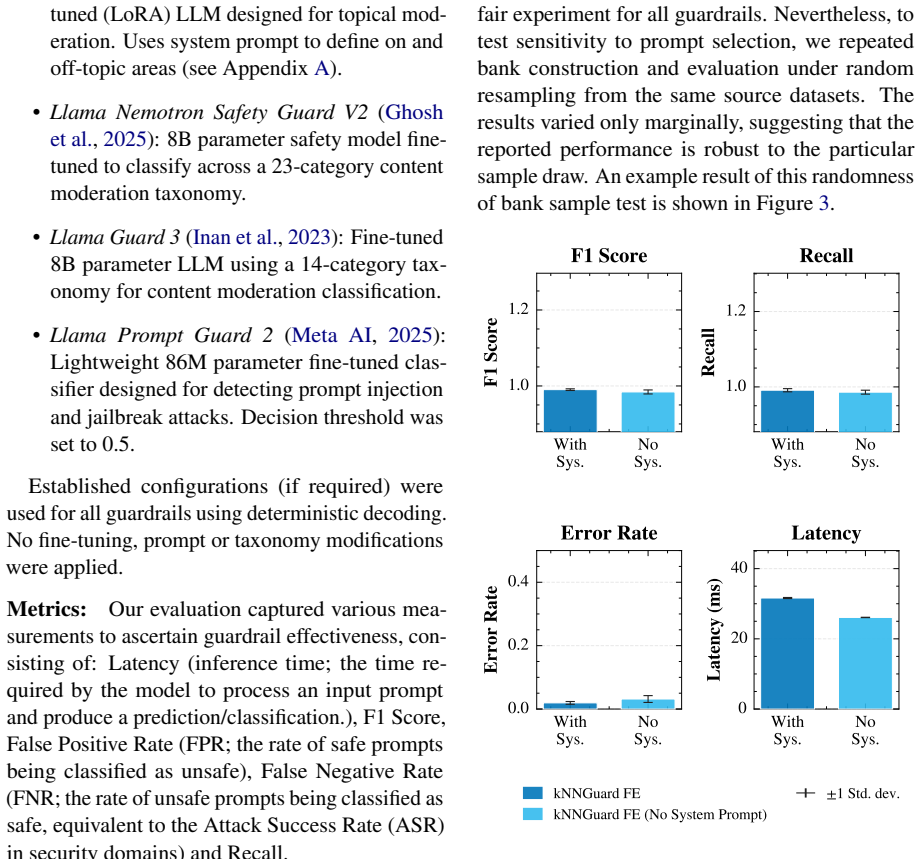
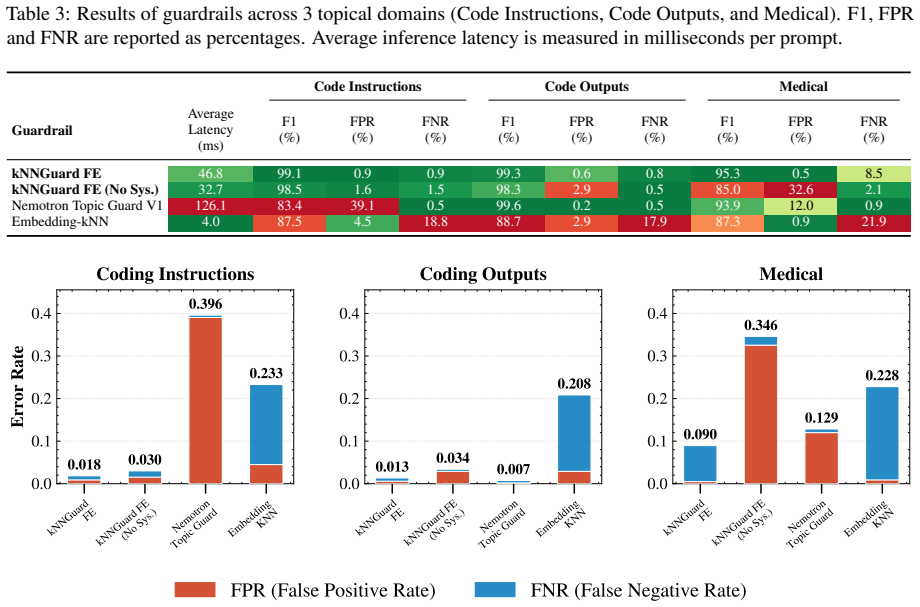
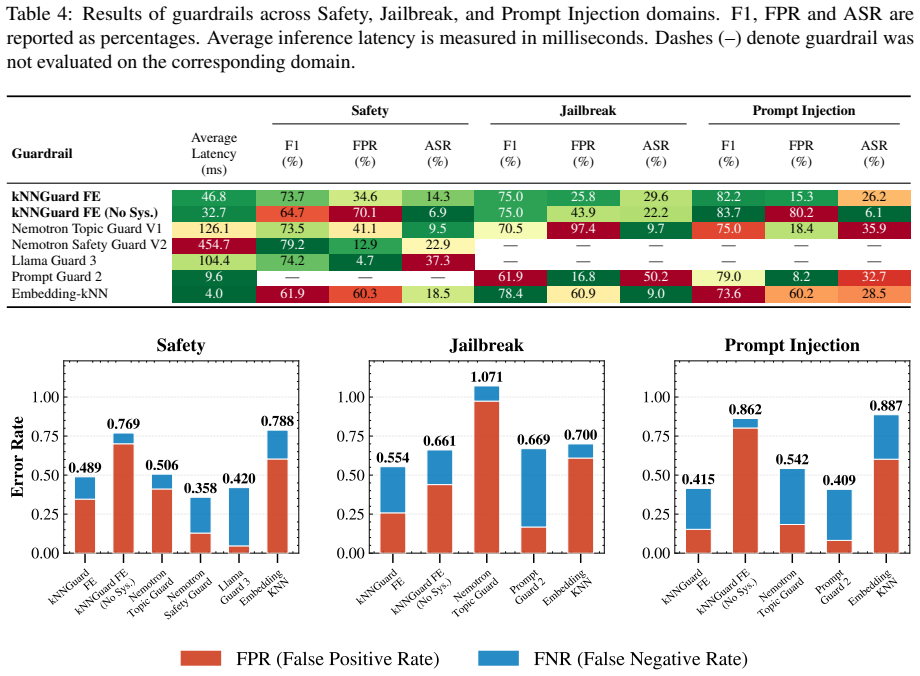



read the original abstract
Large language models (LLMs) are increasingly deployed in domains requiring guardrails to detect unsafe, off-topic, or adversarial prompts. Existing guardrails predominately rely on fine-tuning to build classifiers, which often suffer from low generalization and high inference latency. We present kNNGuard, a training-free guardrail that utilizes the activation space of an off-the-shelf LLM. Given a small bank of 50 safe and unsafe prompts, kNNGuard extracts hidden activations and performs multi-layer kNN fusing activation-space and embedding-space scores for classification. Across six domains spanning topical and security prompts, kNNGuard achieves competitive or superior F1 compared to fine-tuned state-of-the-art guardrails while running 2.7x faster than the best comparable guardrail, and 10x faster than a fine-tuned safety classifier without gradient updates or fine-tuning. Domain adaptation requires only updating the labeled bank, which can be constructed in under 10 seconds and several orders of magnitude faster than established guardrails. We also analyze the impact of system prompts, layer selection, and integration into production LLM pipelines as a configurable, low-latency guardrail.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents kNNGuard, a training-free guardrail that extracts hidden activations from an off-the-shelf LLM, applies multi-layer kNN on a fixed bank of 50 labeled safe/unsafe prompts, and fuses activation-space and embedding-space scores for classification. It claims competitive or superior F1 scores across six domains (topical and security prompts) relative to fine-tuned SOTA guardrails, with 2.7x faster inference than the best comparable method and 10x faster than a fine-tuned safety classifier, plus rapid domain adaptation by swapping the bank.
Significance. If the separability results hold, the work provides a practical, low-latency alternative to fine-tuning for LLM guardrails, with the key advantage of zero gradient updates and sub-10-second bank construction for new domains. This could meaningfully reduce deployment costs in production pipelines where retraining is prohibitive.
major comments (2)
- [Experiments / Evaluation] The central empirical claim (competitive F1 with a 50-prompt bank) rests on the assumption that off-the-shelf LLM activations contain sufficient class-separable structure at this scale; however, the manuscript provides no ablation on bank size, composition sensitivity, or cross-domain prompt variability, leaving open whether nearest-neighbor decisions are driven by intrinsic geometry or by the specific choice of the 50 examples.
- [Experiments] The reported speedups (2.7x and 10x) and F1 comparisons require explicit details on hardware, batching, exact baseline implementations, metric computation (e.g., how F1 is aggregated across domains), and statistical significance; these are load-bearing for the "superior" claim but appear underspecified relative to the strength of the conclusion.
minor comments (2)
- [Method] Notation for the fusion of activation and embedding scores (e.g., how the multi-layer kNN distances are combined) could be clarified with an explicit equation or pseudocode.
- [Abstract] The abstract states results across "six domains" but does not name them or indicate prompt selection criteria; adding this would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental claims and details. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments / Evaluation] The central empirical claim (competitive F1 with a 50-prompt bank) rests on the assumption that off-the-shelf LLM activations contain sufficient class-separable structure at this scale; however, the manuscript provides no ablation on bank size, composition sensitivity, or cross-domain prompt variability, leaving open whether nearest-neighbor decisions are driven by intrinsic geometry or by the specific choice of the 50 examples.
Authors: We agree that explicit ablations would better substantiate the separability assumption. In the revised manuscript we will add: (i) an ablation varying bank size from 10 to 100 examples while holding other factors fixed, (ii) results across multiple randomly sampled banks of size 50 to quantify composition sensitivity, and (iii) per-domain variance analysis to address cross-domain prompt variability. These additions will clarify the contribution of activation-space geometry versus example selection. revision: yes
-
Referee: [Experiments] The reported speedups (2.7x and 10x) and F1 comparisons require explicit details on hardware, batching, exact baseline implementations, metric computation (e.g., how F1 is aggregated across domains), and statistical significance; these are load-bearing for the "superior" claim but appear underspecified relative to the strength of the conclusion.
Authors: We concur that greater experimental transparency is required. The revision will specify: hardware platform and memory, batch sizes used during inference, exact baseline code or references, macro-averaged F1 across the six domains, and statistical significance (standard deviation over repeated runs or bootstrap intervals). These details will be inserted into the experimental setup and results sections. revision: yes
Circularity Check
No significant circularity; empirical method validated externally
full rationale
The paper describes an empirical, training-free kNN-based classifier operating on off-the-shelf LLM activations with a static 50-prompt bank. Classification performance is measured via F1 scores on held-out test sets across six domains and compared directly to independently implemented fine-tuned baselines. No equations, uniqueness theorems, or predictions are offered; the central claim reduces to experimental results rather than any self-referential definition, fitted parameter renamed as prediction, or self-citation chain. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hidden activations from an off-the-shelf LLM contain class-separable structure for safe versus unsafe prompts that kNN can exploit with small example banks
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.04806 , year=
Red teaming the mind of the machine: A systematic evaluation of prompt injection and jailbreak vulnerabilities in llms , author=. arXiv preprint arXiv:2505.04806 , year=
-
[2]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 5: Tutorial Abstracts) , pages=
Guardrails and security for LLMs: Safe, secure and controllable steering of LLM applications , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 5: Tutorial Abstracts) , pages=
-
[3]
arXiv preprint arXiv:2603.20206 , year=
Enhancing Safety of Large Language Models via Embedding Space Separation , author=. arXiv preprint arXiv:2603.20206 , year=
-
[4]
2nd NeurIPS Works
Activation monitoring: advantages of using internal representations for LLM oversight , author=. 2nd NeurIPS Works. on Attributing Model Behavior at Scale , year=
-
[5]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
CantTalkAboutThis: Aligning language models to stay on topic in dialogues , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[6]
arXiv preprint arXiv:2411.12946 , year=
A Flexible Large Language Models Guardrail Development Methodology Applied to Off-Topic Prompt Detection , author=. arXiv preprint arXiv:2411.12946 , year=
-
[7]
arXiv preprint arXiv:2502.01042 , year=
Safeswitch: Steering unsafe llm behavior via internal activation signals , author=. arXiv preprint arXiv:2502.01042 , year=
-
[8]
Advances in neural information processing systems , volume=
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers , author=. Advances in neural information processing systems , volume=
-
[9]
Proceedings of the The First Workshop on LLM Security (LLMSEC) , pages=
Bypassing LLM guardrails: An empirical analysis of evasion attacks against prompt injection and jailbreak detection systems , author=. Proceedings of the The First Workshop on LLM Security (LLMSEC) , pages=
-
[10]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
The structural safety generalization problem , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[11]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Annals of translational medicine , volume=
Introduction to machine learning: k-nearest neighbors , author=. Annals of translational medicine , volume=
-
[13]
Ghojogh, Benyamin and Sikaroudi, Milad and Tizhoosh, H. R. and Karray, Fakhri and Crowley, Mark , year=. Weighted Fisher Discriminant Analysis in the Input and Feature Spaces , ISBN=. doi:10.1007/978-3-030-50516-5_1 , booktitle=
-
[14]
2025 , howpublished =
Restrict Topics with Llama 3.1 NemoGuard 8B TopicControl NIM , author =. 2025 , howpublished =
2025
-
[15]
Advances in Neural Information Processing Systems , volume=
Transformers need glasses! information over-squashing in language tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
arXiv preprint arXiv:2302.09304 , year=
Interpretability in activation space analysis of transformers: A focused survey , author=. arXiv preprint arXiv:2302.09304 , year=
-
[17]
Schizophrenia , volume=
Approximating the semantic space: word embedding techniques in psychiatric speech analysis , author=. Schizophrenia , volume=. 2024 , publisher=
2024
-
[18]
arXiv preprint arXiv:2002.09247 , year=
Is aligning embedding spaces a challenging task? an analysis of the existing methods , author=. arXiv preprint arXiv:2002.09247 , year=
-
[19]
arXiv preprint arXiv:2004.04523 , year=
K-nearest neighbour classifiers: (with Python examples) , author=. arXiv preprint arXiv:2004.04523 , year=
-
[20]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[22]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Proceedings of the 1st International Workshop on Large Language Models for Code , pages=
Promptset: A programmer's prompting dataset , author=. Proceedings of the 1st International Workshop on Large Language Models for Code , pages=
-
[24]
Proceedings of the Conference on Health, Inference, and Learning , pages =
MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering , author =. Proceedings of the Conference on Health, Inference, and Learning , pages =. 2022 , volume =
2022
-
[25]
AEGIS 2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails
Ghosh, Shaona and Varshney, Prasoon and Sreedhar, Makesh Narsimhan and others. AEGIS 2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:...
-
[26]
Alamsabi, M. and Tchuindjang, M. and Brohi, S. , title =. Algorithms , year =. doi:10.3390/a19010092 , url =
-
[27]
2023 , publisher =
Hao, Jack , title =. 2023 , publisher =
2023
-
[28]
Tarun, I. A. M. , title =. 2023 , publisher =
2023
-
[29]
Cureus , volume=
Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge , author=. Cureus , volume=. 2023 , publisher=
2023
-
[30]
Safety Benchmark Dataset , year =
-
[31]
Prompt Injections Benchmark Dataset , year =
-
[32]
Prompt Injections Dataset , year =
-
[33]
2026 , publisher =
NeurAlchemy , title =. 2026 , publisher =
2026
-
[34]
2023 , url =
Mike Conover and Matt Hayes and Ankit Mathur and others , title =. 2023 , url =
2023
-
[35]
2024 , eprint=
WildTeaming at Scale: From In-the-Wild Jailbreaks to (Adversarially) Safer Language Models , author=. 2024 , eprint=
2024
-
[36]
Prompt Safety Dataset , year =
-
[37]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
2025 , howpublished =
Llama Prompt Guard 2 , author =. 2025 , howpublished =
2025
-
[39]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[40]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[41]
2026 , howpublished =
Introducing Gemma 4 12B , author =. 2026 , howpublished =
2026
-
[42]
Gemma: Open Models Based on Gemini Research and Technology
Gemma: Open models based on gemini research and technology , author=. arXiv preprint arXiv:2403.08295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
2025 , url =
QuixiAI , title =. 2025 , url =
2025
-
[44]
2024 , eprint=
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. 2024 , eprint=
2024
-
[45]
Journal of the royal statistical society: Series B (Methodological) , volume=
Cross-validatory choice and assessment of statistical predictions , author=. Journal of the royal statistical society: Series B (Methodological) , volume=. 1974 , publisher=
1974
-
[46]
Advances in neural information processing systems , volume=
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms , author=. Advances in neural information processing systems , volume=
-
[47]
The attacker moves second: Stronger adaptive attacks bypass defenses against LLM jailbreaks and prompt injections , author=. arXiv preprint arXiv:2510.09023 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.