STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
Pith reviewed 2026-06-26 21:07 UTC · model grok-4.3
The pith
STARE stabilizes LLM policy entropy during RL by reweighting token advantages via batch surprisal quantiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
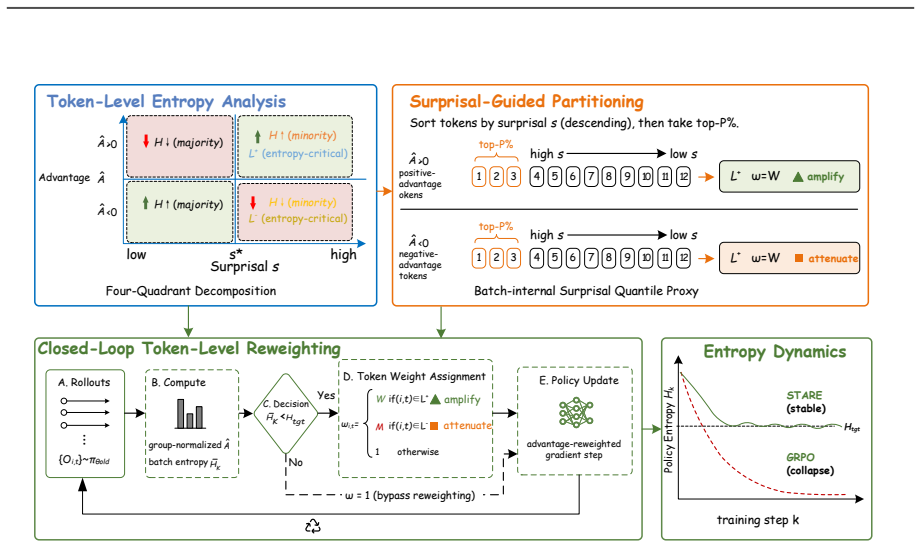
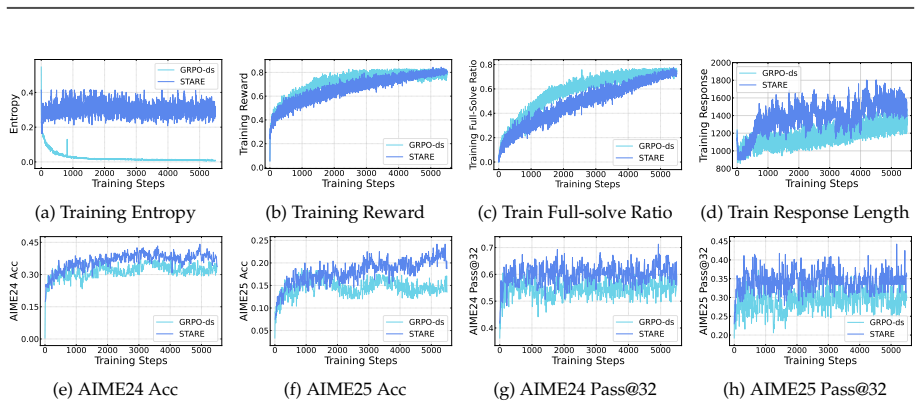
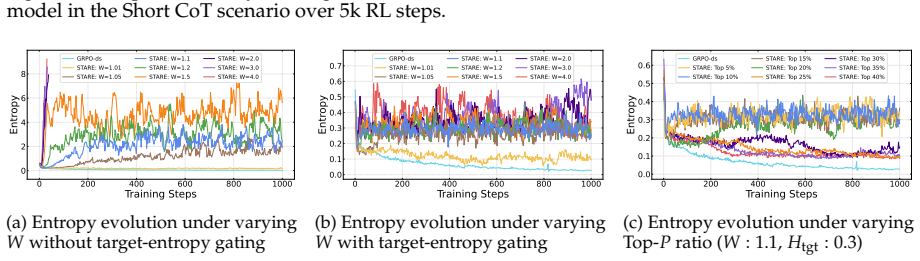
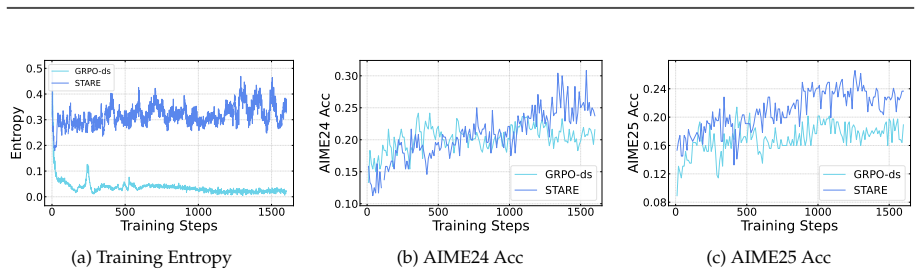
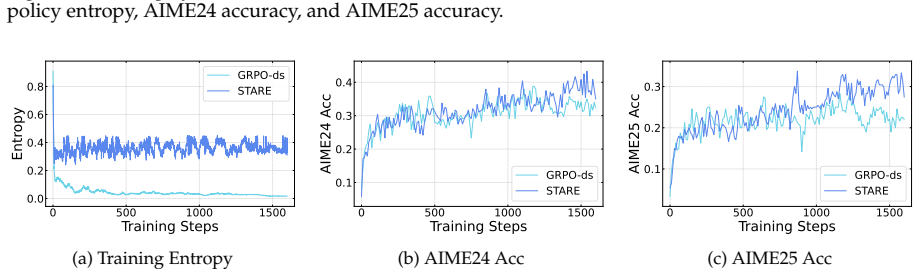
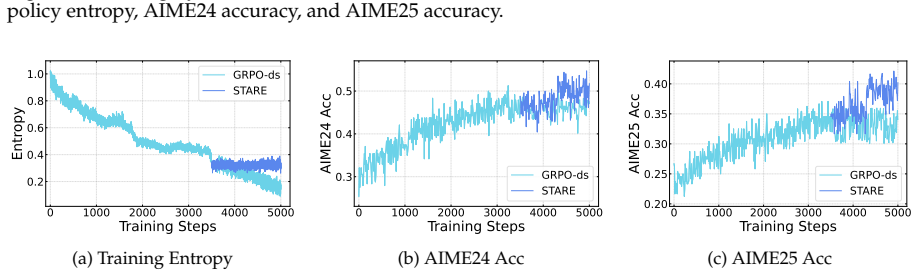
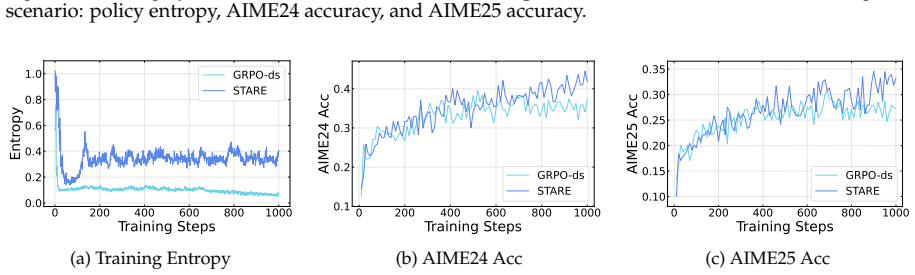
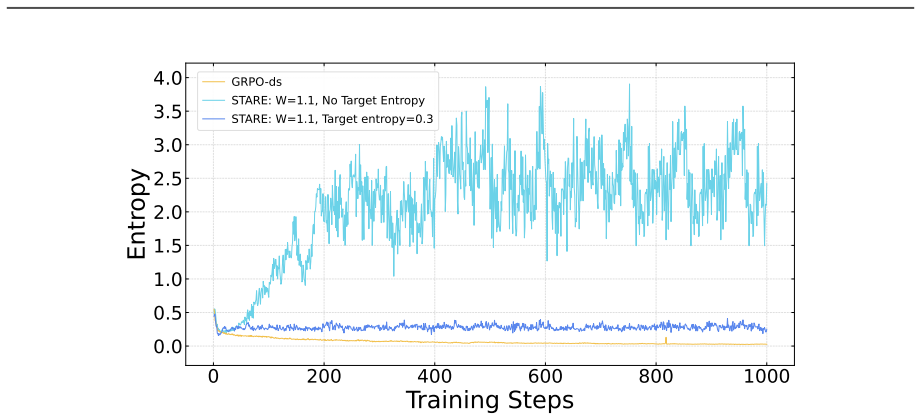
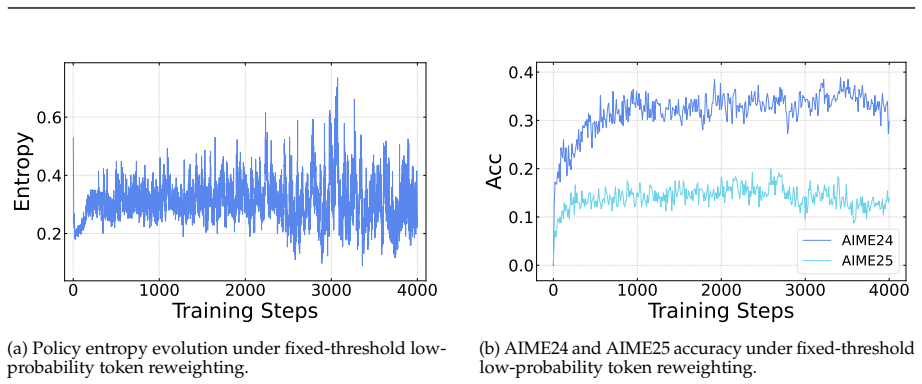
First-order analysis shows per-token entropy variation equals trajectory-level advantage multiplied by an entropy sensitivity function over the next-token distribution, yielding an advantage-surprisal four-quadrant structure and near-criticality property. STARE mitigates the resulting mismatch by identifying entropy-critical token subsets via batch-internal surprisal quantiles, selectively reweighting their effective advantages, and adding a target-entropy closed-loop gate, which sustains stable RL training over thousands of steps while keeping policy entropy in the target band across 1.5B-to-32B models and Short CoT, Long CoT, and Multi-Turn Tool Use tasks.
What carries the argument
Surprisal-guided token-level advantage reweighting that uses batch-internal surprisal quantiles to adjust advantages only for entropy-critical tokens together with a target-entropy closed-loop gate.
If this is right
- STARE sustains stable RL training over thousands of steps while maintaining policy entropy within the target band.
- On AIME24 and AIME25 it outperforms DAPO and other baselines by 4-8 percent average accuracy.
- Reflection tokens and response length grow in tandem, indicating sustained exploration-exploitation balance.
- The gains hold across model scales from 1.5B to 32B and across Short CoT, Long CoT, and Multi-Turn Tool Use task families.
Where Pith is reading between the lines
- The same quantile-based reweighting may transfer to other advantage estimators beyond GRPO without major changes.
- Keeping entropy stable could support longer training runs or larger batch sizes before collapse occurs.
- The four-quadrant decomposition offers a template for diagnosing similar stability problems in other token-level policy updates.
Load-bearing premise
The first-order gradient analysis correctly identifies the token-level credit assignment mismatch whose four-quadrant structure can be mitigated by batch-internal surprisal quantile reweighting without introducing new instabilities.
What would settle it
Apply the reweighting rule to a GRPO run on AIME24 or AIME25 and check whether policy entropy remains inside the target band for thousands of steps while accuracy gains disappear when the quantile reweighting is ablated.
Figures






read the original abstract
Reinforcement Learning with Verifiable Rewards algorithms like GRPO have emerged as the dominant post-training paradigm for complex reasoning in LLMs, yet commonly suffer from policy entropy collapse during training. We conduct a first-order gradient analysis of token-level entropy dynamics under GRPO and identify a token-level credit assignment mismatch: the per-token entropy variation decomposes into the product of the trajectory-level advantage and an entropy sensitivity function over the next-token distribution, yielding an advantage-surprisal four-quadrant structure and a near-criticality property. Motivated by it, we propose STARE (Surprisal-guided Token-level Advantage Reweighting for policy Entropy stability), which identifies entropy-critical token subsets via batch-internal surprisal quantiles, selectively reweights their effective advantages, and incorporates a target-entropy closed-loop gate for stable entropy regulation. Across model scales from 1.5B to 32B and three task families (Short CoT, Long CoT, and Multi-Turn Tool Use), STARE sustains stable RL training over thousands of steps while maintaining policy entropy within the target band. On AIME24 and AIME25, STARE outperforms DAPO and other competitive baselines by 4%-8% in average accuracy, with reflection tokens and response length growing in tandem, indicating sustained exploration-exploitation balance that further unlocks RL training potential.Code is available at https://github.com/hp-luo/STARE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a first-order gradient analysis of token-level entropy dynamics under GRPO reveals an advantage-surprisal four-quadrant credit-assignment mismatch; STARE mitigates this via batch-internal surprisal quantile reweighting of advantages plus a target-entropy closed-loop gate, yielding stable entropy over thousands of steps and 4-8% accuracy gains on AIME24/AIME25 versus DAPO and other baselines across 1.5B-32B models and Short/Long CoT plus multi-turn tasks.
Significance. If the first-order analysis holds under realistic update sizes and the gains prove robust, STARE would supply a practical, token-level mechanism for entropy regulation in verifiable-reward RL, potentially extending the usable training horizon for reasoning models while preserving exploration; the public code release is a clear strength for verification.
major comments (2)
- [Gradient analysis (abstract and §3)] Gradient analysis section (first-order decomposition of per-token entropy variation): the claim that the product of trajectory-level advantage and entropy sensitivity yields a stable four-quadrant structure rests on local linearity and constant advantage; under GRPO's non-negligible per-step policy shifts this approximation can break because higher-order curvature of the entropy surface and updated-policy dependence of advantages invalidate the quadrant classification and the derived quantile reweighting rule.
- [Experiments section] Empirical results (AIME24/AIME25 tables): the 4-8% average accuracy improvement is reported without statistical significance tests, number of independent runs, or ablations that isolate the surprisal-quantile reweighting from the entropy gate, so attribution of gains to the proposed mechanism remains unverified.
minor comments (2)
- [Abstract] The abstract states results across 'three task families' but does not name them explicitly; adding the names (Short CoT, Long CoT, Multi-Turn Tool Use) in the opening paragraph would improve clarity.
- [Method overview] Notation for the entropy sensitivity function and surprisal quantiles is introduced without an explicit equation reference in the summary; a single displayed equation linking advantage, surprisal, and reweighting factor would aid readers.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Gradient analysis (abstract and §3)] Gradient analysis section (first-order decomposition of per-token entropy variation): the claim that the product of trajectory-level advantage and entropy sensitivity yields a stable four-quadrant structure rests on local linearity and constant advantage; under GRPO's non-negligible per-step policy shifts this approximation can break because higher-order curvature of the entropy surface and updated-policy dependence of advantages invalidate the quadrant classification and the derived quantile reweighting rule.
Authors: The first-order analysis is explicitly an approximation intended to yield design insight, consistent with standard practice in RL theory. We agree that higher-order curvature and policy dependence can perturb the exact quadrants in finite updates. In revision we will add a paragraph in §3 quantifying the approximation regime (via local Lipschitz bounds on the entropy Hessian) and note that the reweighting rule is motivated rather than derived as exact; we retain the empirical validation across scales as primary support. revision: yes
-
Referee: [Experiments section] Empirical results (AIME24/AIME25 tables): the 4-8% average accuracy improvement is reported without statistical significance tests, number of independent runs, or ablations that isolate the surprisal-quantile reweighting from the entropy gate, so attribution of gains to the proposed mechanism remains unverified.
Authors: We agree that the current reporting lacks statistical rigor and component ablations. In the revised version we will rerun the AIME24/25 evaluations with at least three independent seeds, report mean ± std, add paired t-tests or Wilcoxon tests against baselines, and include an ablation table that disables the quantile reweighting and the entropy gate independently while keeping all other hyperparameters fixed. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's load-bearing step is a first-order gradient decomposition of per-token entropy variation into (trajectory advantage) imes (entropy sensitivity over next-token distribution), which directly produces the four-quadrant structure and near-criticality property by algebraic identity. This is an independent mathematical analysis of GRPO dynamics, not a self-definition, fitted parameter renamed as prediction, or self-citation chain. STARE's quantile reweighting and closed-loop gate are design choices motivated by the decomposition rather than reducing to it by construction. No self-citations appear load-bearing; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
-
[2]
URL https://hkunlp. github. io/blog/2025/Polaris,
2025
- [3]
-
[5]
Do NOT think that much for 2+3=? on the overthinking of long reasoning models
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Do NOT think that much for 2+3=? on the overthinking of long reasoning models. In Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19,
2025
-
[6]
URL https://openreview.net/forum?id=MSbU3L7V00
OpenReview.net, 2025b. URL https://openreview.net/forum?id=MSbU3L7V00. Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Wayne Xin Zhao, Zhenliang Zhang, and Furu Wei. Reasoning with exploration: An entropy perspective. CoRR, abs/2506.14758,
-
[7]
Reasoning with Exploration: An Entropy Perspective
doi: 10.48550/ ARXIV .2506.14758. URLhttps://doi.org/10.48550/arXiv.2506.14758. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language mo...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.14758
-
[10]
URL https://doi.org/10.1038/s41586-024-07421-0
doi: 10.1038/S41586-024-07421-0. URL https://doi.org/10.1038/s41586-024-07421-0 . Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms,
-
[11]
URL https://arxiv.org/abs/2504.11536. 11 Xiaoliang Fu, Jiaye Lin, Yangyi Fang, Chaowen Hu, Cong Qin, Zekai Shao, Binbin Zheng, Lu Pan, and Ke Zeng. From log π to π: Taming divergence in soft clipping via bilateral decoupled decay of probability gradient weight,
-
[12]
Leo Gao, John Schulman, and Jacob Hilton
URL https://arxiv.org/abs/2603.14389. Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA , pp. 10835–10866,
Pith/arXiv arXiv 2023
-
[13]
URL https://proceedings.mlr.press/v202/gao23h.html. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948,
-
[14]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, pp. 1856–1865,
2018
-
[15]
URL http://proceedings.mlr.press/v80/haarnoja18b.html. Zhezheng Hao, Hong Wang, Haoyang Liu, Jian Luo, Jiarui Yu, Hande Dong, Qiang Lin, Can Wang, and Jiawei Chen. Rethinking entropy interventions in rlvr: An entropy change perspective. arXiv preprint arXiv:2510.10150,
-
[16]
Rewarding the unlikely: Lifting grpo beyond distribu- tion sharpening
Andre Wang He, Daniel Fried, and Sean Welleck. Rewarding the unlikely: Lifting grpo beyond distribu- tion sharpening. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 25559–25571, 2025a. Bingxiang He, Zekai Qu, Zeyuan Liu, Yinghao Chen, Yuxin Zuo, Cheng Qian, Kaiyan Zhang, Weize Chen, Chaojun Xiao, Ganqu Cui, ...
arXiv 2025
-
[17]
Skywork Open Reasoner 1 Technical Report
doi: 10.18653/V1/2024.ACL-LONG.211. URL https://doi.org/10.18653/v1/2024.acl-long.211. Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, et al. Skywork open reasoner 1 technical report. arXiv preprint arXiv:2505.22312, 2025c. Yuhang He, Haodong Wu, Siyi Liu, Hongyu Ge, Hange Zhou,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.211 2024
-
[18]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874,
-
[19]
Low-probability tokens sustain exploration in reinforcement learning with verifiable reward
Guanhua Huang, Tingqiang Xu, Mingze Wang, Qi Yi, Xue Gong, Siheng Li, Ruibin Xiong, Kejiao Li, Yuhao Jiang, and Bo Zhou. Low-probability tokens sustain exploration in reinforcement learning with verifiable reward. arXiv preprint arXiv:2510.03222,
-
[20]
Renren Jin, Pengzhi Gao, Yuqi Ren, Zhuowen Han, Tongxuan Zhang, Wuwei Huang, Wei Liu, Jian Luan, and Deyi Xiong. Revisiting entropy in reinforcement learning for large reasoning models.arXiv preprint arXiv:2511.05993,
-
[21]
Courville, and Nicolas Le Roux
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron C. Courville, and Nicolas Le Roux. Vineppo: Refining credit assignment in RL training of llms. In Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025,
2025
-
[22]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay V
URL https://openreview.net/forum?id=Myx2kJFzAn. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay V . Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. In Advances in Neural Inform...
2022
-
[23]
URL http://papers.nips.cc/paper_files/paper/2022/hash/ 18abbeef8cfe9203fdf9053c9c4fe191-Abstract-Conference.html. 12 Shiqi Liu, Zeyu He, Guojian Zhan, Letian Tao, Zhilong Zheng, Jiang Wu, Yinuo Wang, Yang Guan, Kehua Sheng, Bo Zhang, et al. Stapo: Stabilizing reinforcement learning for llms by silencing rare spurious tokens. arXiv preprint arXiv:2602.15620,
Pith/arXiv arXiv 2022
-
[24]
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583,
-
[25]
Arena learning: Build data flywheel for llms post-training via simulated chatbot arena
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Qingwei Lin, Jianguang Lou, Shifeng Chen, Yansong Tang, and Weizhu Chen. Arena learning: Build data flywheel for llms post-training via simulated chatbot arena. arXiv preprint arXiv:2407.10627, 2024a. Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Qingwei Lin, Jianguang Lou, Shifeng Chen, Yansong Tang, and Weizhu C...
-
[26]
Wizardcoder: Empowering code large language models with evol- instruct
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol- instruct. In International Conference on Learning Representations, volume 2024, pp. 27168–27188, 2024c. Xinji Mai, Haotian Xu, Zhong-Zhi Li, Weinong Wang, Jian Hu, Yingying ...
arXiv 2024
-
[27]
Transformer-based language model surprisal predicts human reading times best with about two billion training tokens
Byung-Doh Oh and William Schuler. Transformer-based language model surprisal predicts human reading times best with about two billion training tokens. In Findings of the association for computational linguistics: EMNLP 2023, pp. 1915–1921,
2023
-
[28]
URLhttps: //arxiv.org/abs/2402.02255. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qi...
-
[29]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
URL https://arxiv.org/abs/2412.15115. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
-
[30]
URL https://arxiv.org/abs/2402.03300. Qiannan Shen and Jing Zhang. Ai-enhanced disaster risk prediction with explainable shap analysis: A multi-class classification approach using xgboost. In 2026 5th International Symposium on Computer Applications and Information Technology (ISCAIT), pp. 692–698. IEEE,
Pith/arXiv arXiv 2026
-
[31]
URL https://arxiv.org/abs/2509.20712. Sijun Tan, Michael Luo, Justin Wong, Colin Cai, Xiaoxiang Shi, William Yuan Tang, Manan Roongta, Tianjun Zhang, Li Erran Li, Raluca Ada Popa, and Ion Stoica. Deepscaler: Effective RL scaling of reasoning models via iterative context lengthening,
-
[32]
URL https://openreview.net/forum?id= I6GzDCne7U. 13 Xinyu Tang, Yuliang Zhan, Zhixun Li, Wayne Xin Zhao, Zhenduo Zhang, Zujie Wen, Zhiqiang Zhang, and Jun Zhou. Rethinking sample polarity in reinforcement learning with verifiable rewards. arXiv preprint arXiv:2512.21625,
-
[33]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, Haiqing Guo, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haotian Yao, Haotian Zhao, Haoyu Lu, Haoze Li, Haoz...
-
[34]
URL https://arxiv.org/abs/2505.09388. Tencent Hunyuan Team, Ao Liu, Botong Zhou, Can Xu, Chayse Zhou, ChenChen Zhang, Chengcheng Xu, Chenhao Wang, Decheng Wu, Dengpeng Wu, et al. Hunyuan-turbos: Advancing large language models through mamba-transformer synergy and adaptive chain-of-thought. arXiv preprint arXiv:2505.15431, 2025b. Jiakang Wang, Runze Liu, ...
-
[36]
Zhiheng Xi, Xin Guo, Yang Nan, Enyu Zhou, Junrui Shen, Wenxiang Chen, Jiaqi Liu, Jixuan Huang, Zhihao Zhang, Honglin Guo, et al. Bapo: Stabilizing off-policy reinforcement learning for llms via balanced policy optimization with adaptive clipping. arXiv preprint arXiv:2510.18927,
-
[37]
Wizardlm: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions. In International Conference on Learning Representations, volume 2024, pp. 30745–30766,
2024
-
[38]
Wujiang Xu, Wentian Zhao, Zhenting Wang, Yu-Jhe Li, Can Jin, Mingyu Jin, Kai Mei, Kun Wang, and Dimitris N. Metaxas. EPO: entropy-regularized policy optimization for LLM agents reinforcement learning. CoRR, abs/2509.22576,
-
[40]
Kai Yang, Xin Xu, Yangkun Chen, Weijie Liu, Jiafei Lyu, Zichuan Lin, Deheng Ye, and Saiyong Yang
URL https://arxiv.org/abs/2409.12122. Kai Yang, Xin Xu, Yangkun Chen, Weijie Liu, Jiafei Lyu, Zichuan Lin, Deheng Ye, and Saiyong Yang. Entropic: Towards stable long-term training of llms via entropy stabilization with proportional-integral control. arXiv preprint arXiv:2511.15248, 2025a. Tao Yang, Xiaopu Zhang, Junjie Xiao, Jianzhun Qian, Ning Bian, Jing...
-
[42]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
URL https://arxiv.org/abs/2503.14476. Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? CoRR, abs/2504.13837, 2025a. doi: 10.48550/ARXIV .2504.13837. URL https://doi.org/10.48550/ arXiv.2504.13837. Yu Yue, Yufeng Yua...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[43]
URL https: //arxiv.org/abs/2508.05988. Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization. arXiv preprint arXiv:2507.18071,
-
[44]
Offseeker: Online reinforcement learning is not all you need for deep research agents
Yuhang Zhou, Kai Zheng, Qiguang Chen, Mengkang Hu, Qingfeng Sun, Can Xu, and Jingjing Chen. Offseeker: Online reinforcement learning is not all you need for deep research agents. arXiv preprint arXiv:2601.18467,
-
[45]
The surprising effectiveness of negative reinforcement in llm reasoning
Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng. The surprising effectiveness of negative reinforcement in llm reasoning. ArXiv, abs/2506.01347,
-
[46]
15 Appendix Appendix Contents A Related Work 18 B Additional Experiments and Analysis on STARE 19 B.1 STARE vs
URL https: //api.semanticscholar.org/CorpusID:279075301. 15 Appendix Appendix Contents A Related Work 18 B Additional Experiments and Analysis on STARE 19 B.1 STARE vs. GRPO-ds: Detailed Comparison across Diverse Scenarios and Model Scales in RL Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 B.2 Valid...
2023
-
[47]
Meanwhile, the accuracy of GRPO-ds on AIME24 and AIME25 peaks around step 1000 and subsequently saturates, fluctuating without further improvement (Figure 3(e)-(f)), thereby indicating premature convergence of the policy distribution. In contrast, STARE stabilizes the policy entropy near Htgt = 0.3 through token-level advantage reweighting and closed-loop...
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.