Variance Reduction on the Camera Axis: Multi-View Score Distillation for 3D
Pith reviewed 2026-06-30 05:59 UTC · model grok-4.3
The pith
Aggregating K antithetic views per step at fixed UNet budget reduces variance in score distillation for 3D generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
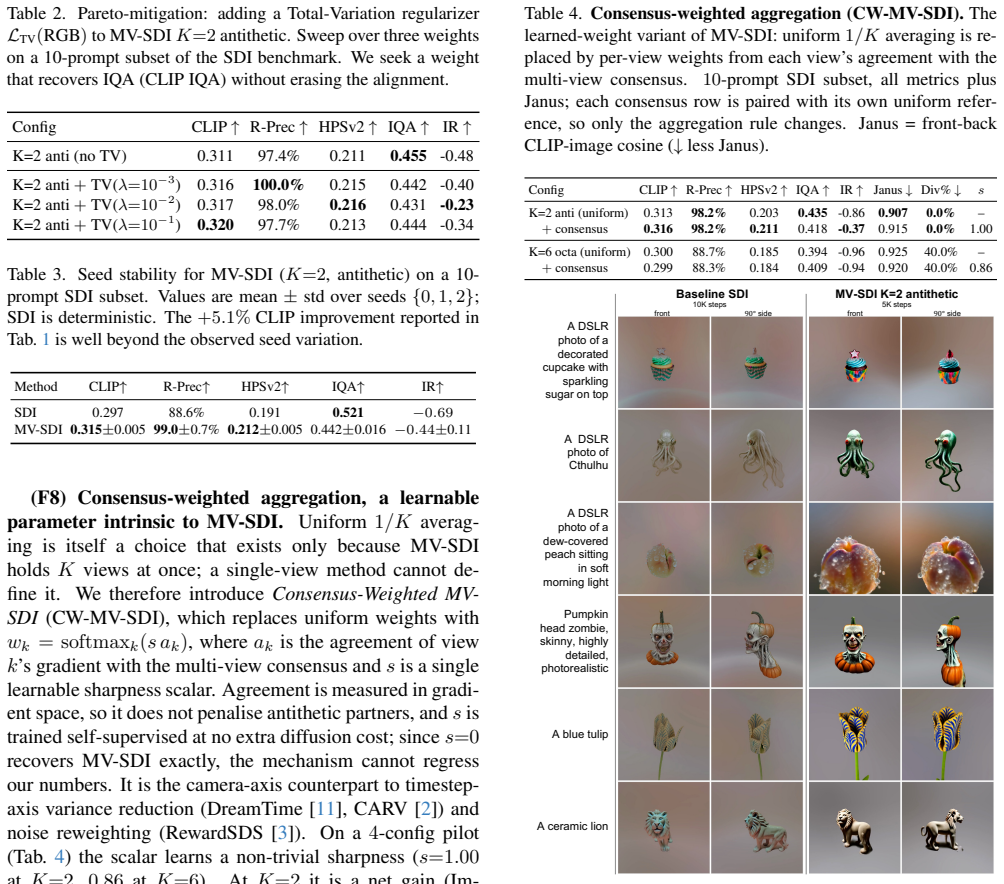
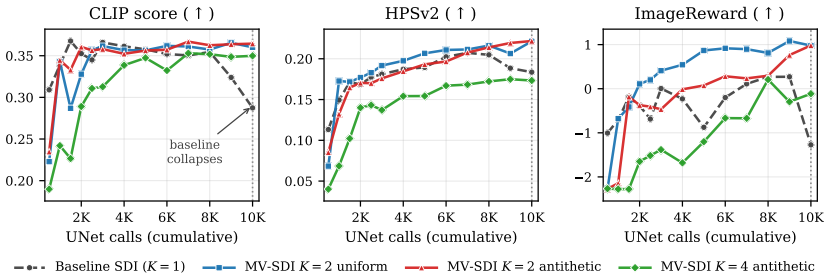
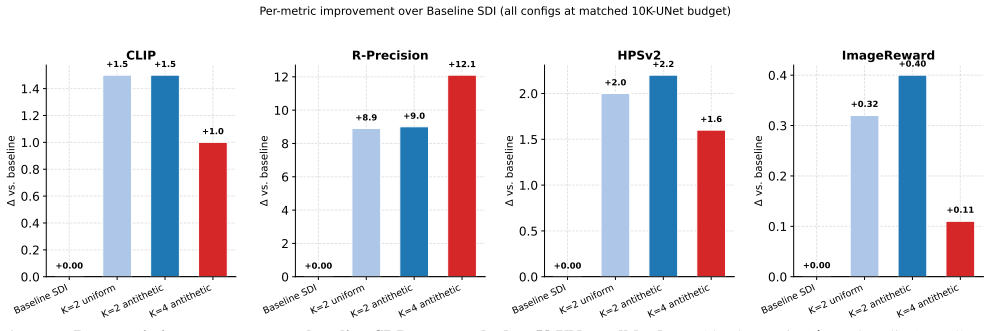
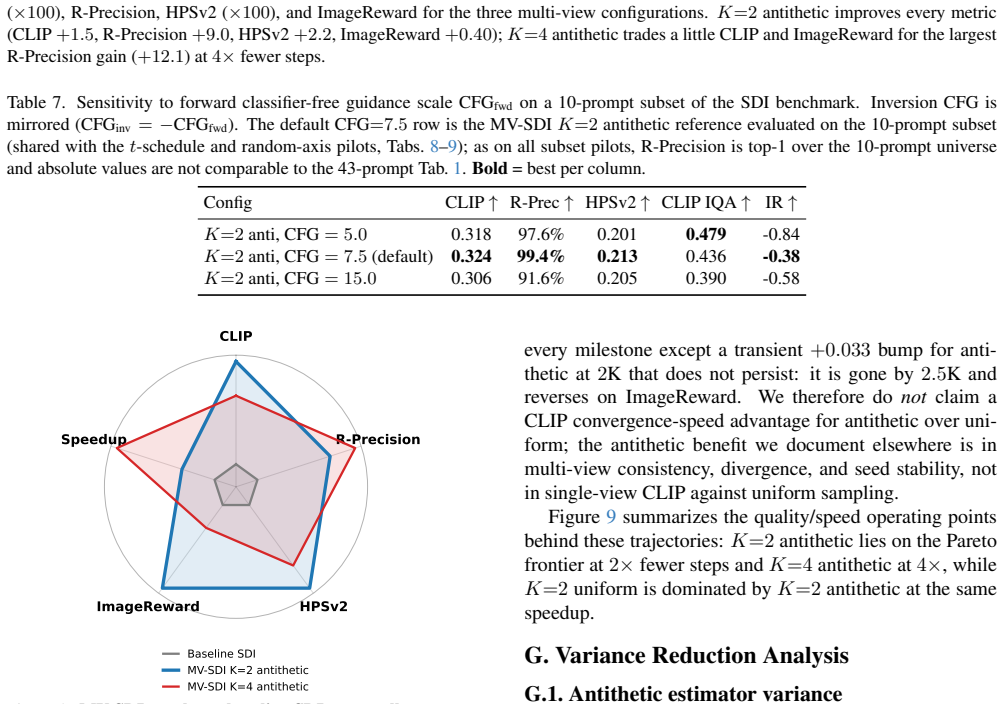
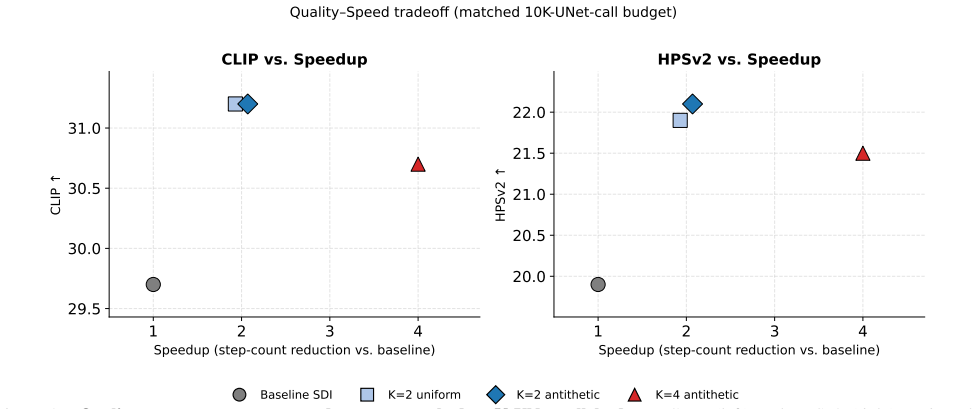
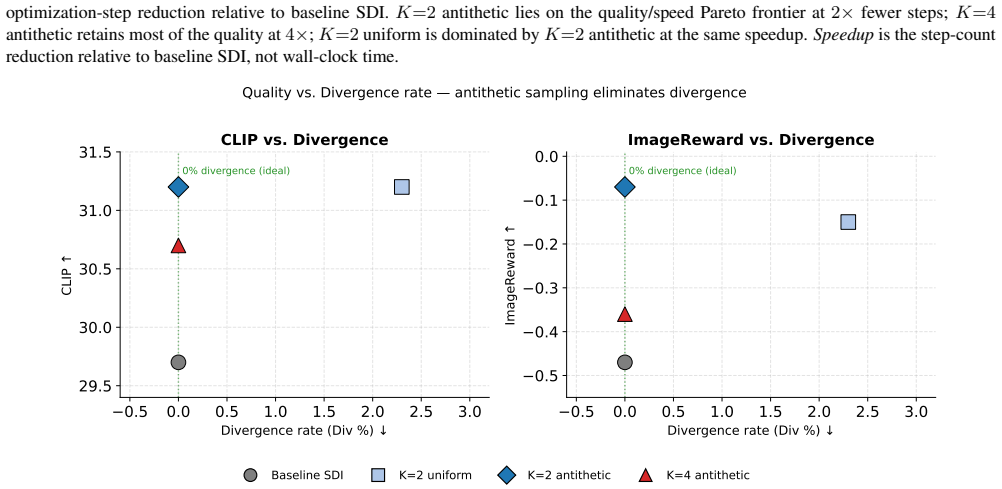
By treating the per-step gradient as one noisy sample from the expectation over views and aggregating K such samples via gradient accumulation while drawing views as antithetic antipodal pairs, Multi-View Aggregated Score Distillation raises CLIP R-Precision from 74.8 percent to 83.8 percent and CLIP score from 0.297 to 0.312 at K=2, with zero divergence and halved steps at fixed 10,000-UNet-call budget; larger K gives further step reduction while remaining above the single-view baseline on every metric.
What carries the argument
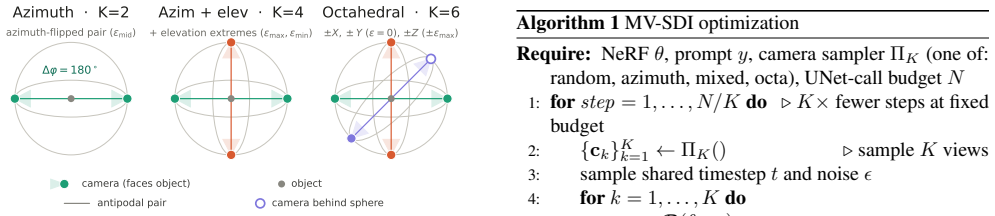
Multi-View Aggregated Score Distillation (MV-SDI) that accumulates gradients from K antithetic antipodal view pairs per step at fixed total UNet budget.
If this is right
- At K=2, CLIP R-Precision rises from 74.8% to 83.8% and CLIP score from 0.297 to 0.312 with 0.0% divergence.
- Optimization steps are halved while total UNet calls stay fixed.
- K=4 delivers fourfold step reduction at R-Precision 86.9% and CLIP score 0.307, still above single-view baseline.
- The method works with gradient-based pipelines including Score Distillation via Inversion.
- No retraining and no multi-view data are required.
Where Pith is reading between the lines
- The same per-step averaging could be applied to other high-variance camera-dependent objectives such as novel-view synthesis or 4D generation.
- Geometric view pairing might substitute for learned multi-view consistency losses in settings where training data are scarce.
- The approach could be combined with existing variance-reduction techniques such as control variates inside the diffusion sampler itself.
Load-bearing premise
That sampling views as antithetic antipodal pairs supplies balanced angular coverage whose gradients can be accumulated without introducing systematic bias into the 3D optimization trajectory.
What would settle it
Running the identical benchmark with K=2 but choosing the two views independently at random instead of as antipodal pairs and finding no gain in R-Precision or CLIP score would show that the reported improvement requires the specific pairing geometry.
Figures












read the original abstract
Score distillation turns a pretrained 2D diffusion model into a 3D generator, but the per-step gradient is estimated from a single randomly chosen view: it is high-variance and blind to global shape consistency. Prior work addresses this by retraining the diffusion prior on multi-view data; this improves consistency but makes the sampling contribution inseparable from prior quality. We instead isolate the sampling axis. The per-step gradient is one noisy sample of an expectation over views; aggregating K samples per step at a fixed total UNet budget reduces variance without touching the prior. We introduce Multi-View Aggregated Score Distillation (MV-SDI), which aggregates gradients from K views per step via gradient accumulation, keeping peak memory unchanged and the 2D prior frozen, and draws views as antithetic antipodal pairs, a prior-independent geometric property, for balanced angular coverage. At a fixed 10,000-UNet-call budget, K=2 raises CLIP R-Precision from 74.8% to 83.8% and CLIP score from 0.297 to 0.312, with consistent gains on HPSv2 and ImageReward and a 0.0% divergence rate on the 43-prompt benchmark; optimization steps halve as a consequence. K=4 gives a fourfold step reduction at R-Precision 86.9% and CLIP 0.307, still well above the single-view baseline on every alignment metric. MV-SDI is compatible with gradient-based score-distillation pipelines, including Score Distillation via Inversion, and requires no retraining and no multi-view data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that score distillation for 3D generation suffers from high-variance single-view gradients; MV-SDI aggregates K per-step gradients via accumulation at fixed total UNet budget, drawing views as antithetic antipodal pairs for balanced coverage, yielding metric gains (CLIP R-Precision 74.8%→83.8% at K=2) without retraining the 2D prior or altering peak memory, and halving optimization steps.
Significance. If the central variance-reduction claim holds, the work isolates a sampling-axis improvement that is compatible with existing score-distillation pipelines (including SDS and SDI) and requires no multi-view data or prior modification; the reported fixed-budget gains on CLIP, HPSv2, and ImageReward metrics, together with 0% divergence on the 43-prompt set, would constitute a practical, low-overhead advance in 3D consistency.
major comments (2)
- [Abstract] Abstract (paragraph on MV-SDI and view drawing): the claim that antithetic antipodal pairs supply 'balanced angular coverage' whose gradients can be accumulated 'without introducing systematic bias' is load-bearing for the assertion that observed gains are pure variance reduction; no derivation is supplied showing that the pair distribution is uniform on SO(3) or that E[aggregated gradient] equals the true multi-view expectation.
- [Methods] Methods (MV-SDI construction): the non-convex 3D optimization trajectory means that correlated gradients from fixed antipodal pairs could systematically under-weight equatorial or asymmetric viewpoints; without an ablation on view-selection bias or a Monte-Carlo analysis of the estimator, it remains possible that the +9 pp R-Precision lift is partly an artifact of the sampling schedule rather than variance reduction alone.
minor comments (2)
- [Results] Results: no error bars or multiple random seeds are reported for the CLIP R-Precision and score numbers, making it impossible to assess whether the reported deltas exceed run-to-run variance.
- [Abstract] Abstract and experiments: the 10,000-UNet-call budget and the exact K=2, K=4 step counts are stated without a table or pseudocode clarifying how the per-step UNet calls are partitioned across the K views while keeping peak memory unchanged.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for clearer theoretical justification of the estimator and potential interactions with the non-convex optimization. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on MV-SDI and view drawing): the claim that antithetic antipodal pairs supply 'balanced angular coverage' whose gradients can be accumulated 'without introducing systematic bias' is load-bearing for the assertion that observed gains are pure variance reduction; no derivation is supplied showing that the pair distribution is uniform on SO(3) or that E[aggregated gradient] equals the true multi-view expectation.
Authors: The estimator remains unbiased because each view in an antithetic pair is drawn from the identical marginal distribution used in the single-view baseline; therefore E[(g(θ) + g(antipode(θ)))/K] equals the true multi-view expectation regardless of whether the overall distribution is uniform on SO(3). The antipodal construction only induces negative correlation that reduces variance. We will insert a short paragraph in the Methods section making this marginal-expectation argument explicit. revision: partial
-
Referee: [Methods] Methods (MV-SDI construction): the non-convex 3D optimization trajectory means that correlated gradients from fixed antipodal pairs could systematically under-weight equatorial or asymmetric viewpoints; without an ablation on view-selection bias or a Monte-Carlo analysis of the estimator, it remains possible that the +9 pp R-Precision lift is partly an artifact of the sampling schedule rather than variance reduction alone.
Authors: Because the per-step estimator is unbiased, the expected gradient at every optimization step matches the single-view case; any trajectory difference arises solely from reduced variance rather than directional bias. The reported gains are consistent across CLIP, HPSv2, ImageReward and zero divergence on the 43-prompt set. Nevertheless, an explicit ablation isolating the pairing strategy would be valuable, and we will add a controlled comparison of antithetic pairs versus independent random views at fixed K=2. revision: partial
Circularity Check
No significant circularity; derivation is self-contained Monte-Carlo variance reduction
full rationale
The paper presents MV-SDI as gradient aggregation over K views drawn as antithetic antipodal pairs, framed as a prior-independent geometric sampling rule that reduces variance at fixed UNet budget. No equations, fitted parameters, or self-citations are shown that reduce the central claim to its own inputs by construction. The reported gains (CLIP R-Precision, etc.) are empirical outcomes on external benchmarks rather than predictions forced by internal definitions. This matches the default case of a non-circular method paper relying on standard sampling principles.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained 2D diffusion models provide usable score estimates for rendered views of 3D objects
Reference graph
Works this paper leans on
-
[1]
Mohammadreza Armandpour, Ali Sadeghian, Huangjie Zheng, Amir Sadeghian, and Mingyuan Zhou. Re-imagine the negative prompt algorithm: Transform 2d diffusion into 3d, alleviate janus problem and beyond.arXiv preprint arXiv:2304.04968, 2023. 3
-
[2]
Variance reduction for expectations with diffusion teachers, 2026
Jesse Bettencourt, Xindi Wu, Matan Atzmon, James Lucas, and Jonathan Lorraine. Variance reduction for expectations with diffusion teachers, 2026. SPIGM Workshop, ICML
2026
-
[3]
Rewardsds: Aligning score distillation via reward-weighted sampling,
Itay Chachy, Guy Yariv, and Sagie Benaim. Rewardsds: Aligning score distillation via reward-weighted sampling,
-
[4]
Fan- tasia3d: Disentangling geometry and appearance for high- quality text-to-3d content creation
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fan- tasia3d: Disentangling geometry and appearance for high- quality text-to-3d content creation. InIEEE/CVF Interna- tional Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 22189–22199. IEEE,
2023
-
[5]
TorchMetrics – measuring reproducibility in Py- Torch.https : / / github
Nicki Skafte Detlefsen, Jiri Borovec, Justus Schock, Ananya Harsh Jha, Teddy Koker, Luca Di Liello, Daniel Stancl, Changsheng Quan, Maxim Grechkin, and William Falcon. TorchMetrics – measuring reproducibility in Py- Torch.https : / / github . com / Lightning - AI / torchmetrics, 2022. 12
2022
-
[6]
Glynn and Roberto Szechtman
Peter W. Glynn and Roberto Szechtman. Some new perspec- tives on the method of control variates.Monte Carlo and Quasi-Monte Carlo Methods, 2002. 2
2002
-
[7]
threestudio: A unified framework for 3d content generation
Yuan-Chen Guo, Ying-Tian Liu, Ruizhi Shao, Christian Laforte, Vikram V oleti, Guan Luo, Chia-Hao Chen, Zi- Xin Zou, Chen Wang, Yan-Pei Cao, and Song-Hai Zhang. threestudio: A unified framework for 3d content generation. https://github.com/threestudio- project/ threestudio, 2023. 4, 12
2023
-
[8]
Hammersley and David C
John M. Hammersley and David C. Handscomb.Monte Carlo methods. Methuen, 1964. 2, 4
1964
-
[9]
LRM: large reconstruction model for single image to 3d
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: large reconstruction model for single image to 3d. InThe Twelfth International Conference on Learn- ing Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[10]
OpenReview.net, 2024. 3
2024
-
[11]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Represen- tations, ICLR 2022, Virtual Event, April 25-29, 2022. Open- Review.net, 2022. 2
2022
-
[12]
Dreamtime: An improved opti- mization strategy for diffusion-guided 3d generation
Yukun Huang, Jianan Wang, Yukai Shi, Boshi Tang, Xian- biao Qi, and Lei Zhang. Dreamtime: An improved opti- mization strategy for diffusion-guided 3d generation. InThe Twelfth International Conference on Learning Representa- tions, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net, 2024. 2, 6
2024
-
[13]
Noise-free score distillation
Oren Katzir, Or Patashnik, Daniel Cohen-Or, and Dani Lischinski. Noise-free score distillation. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net,
2024
-
[14]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139:1– 139:14, 2023. 3
2023
-
[15]
Variational diffusion models
Diederik Kingma and Tim Salimans. Variational diffusion models. InAdvances in Neural Information Processing Sys- tems, pages 21696–21707, 2021. 2
2021
-
[16]
Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model
Jiahao Li, Hao Tan, Kai Zhang, Zexiang Xu, Fujun Luan, Yinghao Xu, Yicong Hong, Kalyan Sunkavalli, Greg Shakhnarovich, and Sai Bi. Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model. In The Twelfth International Conference on Learning Represen- tations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net, 2024. 3
2024
-
[17]
Era3d: High-resolution multiview diffusion using effi- cient row-wise attention
Peng Li, Yuan Liu, Xiaoxiao Long, Feihu Zhang, Cheng Lin, Mengfei Li, Xingqun Qi, Shanghang Zhang, Wei Xue, Wen- han Luo, Ping Tan, Wenping Wang, Qifeng Liu, and Yike Guo. Era3d: High-resolution multiview diffusion using effi- cient row-wise attention. InAdvances in Neural Information Processing Systems 37: Annual Conference on Neural Infor- mation Proces...
2024
-
[18]
Luciddreamer: Towards high-fidelity text-to-3d generation via interval score match- ing
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiao- gang Xu, and Yingcong Chen. Luciddreamer: Towards high-fidelity text-to-3d generation via interval score match- ing. InIEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 6517–6526. IEEE, 2024. 2
2024
-
[19]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Van- couver, BC, Canada, June 17-24, 2023, pages 300–309. IEEE, 2023. 2, 6
2023
-
[20]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InIEEE/CVF Interna- tional Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 9264–9275. IEEE, 2023. 3
2023
-
[21]
Syncdreamer: Gen- erating multiview-consistent images from a single-view im- age
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. Syncdreamer: Gen- erating multiview-consistent images from a single-view im- age. InThe Twelfth International Conference on Learn- ing Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[22]
OpenReview.net, 2024
2024
-
[23]
Wonder3d: Single image to 3d using cross-domain diffu- sion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, and Wenping Wang. Wonder3d: Single image to 3d using cross-domain diffu- sion. InIEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 9970–9980. IEEE, 2024. 3
2024
-
[24]
Greenewald, Vitor Guizilini, Timur M
Artem Lukoianov, Haitz S ´aez de Oc ´ariz Borde, Kristjan H. Greenewald, Vitor Guizilini, Timur M. Bagautdinov, Vin- cent Sitzmann, and Justin M. Solomon. Score distillation via reparametrized DDIM. 2024. 1, 2, 3, 4, 5, 6, 7, 12, 16
2024
-
[25]
Optimal trans- port for rectified flow image editing: Unifying inversion- based and direct methods
Marian Lupascu and Mihai-Sorin Stupariu. Optimal trans- port for rectified flow image editing: Unifying inversion- based and direct methods. InIEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2026, Tucson, AZ, USA, March 6-10, 2026, pages 6764–6774. IEEE, 2026. 19
2026
-
[26]
Scaledreamer: Scalable text-to- 3d synthesis with asynchronous score distillation
Zhiyuan Ma, Yuxiang Wei, Yabin Zhang, Xiangyu Zhu, Zhen Lei, and Lei Zhang. Scaledreamer: Scalable text-to- 3d synthesis with asynchronous score distillation. InCom- puter Vision - ECCV 2024 - 18th European Conference, Mi- lan, Italy, September 29-October 4, 2024, Proceedings, Part VII, pages 1–19. Springer, 2024. 2
2024
-
[27]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis. InComputer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceed- ings, Part I, pages 405–421. Springer, 2020. 2
2020
-
[28]
Instant neural graphics primitives with a multires- olution hash encoding.ACM Trans
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a multires- olution hash encoding.ACM Trans. Graph., 41(4):102:1– 102:15, 2022. 3, 4
2022
-
[29]
Owen.Monte Carlo theory, methods and examples
Art B. Owen.Monte Carlo theory, methods and examples. Self-published / Stanford University, 2013. 2
2013
-
[30]
Barron, and Ben Milden- hall
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion. InThe Eleventh International Conference on Learning Representa- tions, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenRe- view.net, 2023. 2, 3, 7, 16
2023
-
[31]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, ...
2021
-
[32]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 10674– 10685. IEEE, 2022. 2, 12
2022
-
[33]
Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, and Hao Su. Zero123++: a single image to consistent multi-view dif- fusion base model.arXiv preprint arXiv:2310.15110, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Mvdream: Multi-view diffusion for 3d gen- eration
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d gen- eration. InThe Twelfth International Conference on Learn- ing Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[35]
OpenReview.net, 2024. 2, 3
2024
-
[36]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. In9th International Con- ference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. 2
2021
-
[37]
LGM: large multi-view gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. LGM: large multi-view gaussian model for high-resolution 3d content creation. InComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part IV, pages 1–18. Springer, 2024. 3
2024
-
[38]
Dreamgaussian: Generative gaussian splatting for effi- cient 3d content creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for effi- cient 3d content creation. InThe Twelfth International Con- ference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 3
2024
-
[39]
Mvdiffusion: Enabling holistic multi- view image generation with correspondence-aware diffusion
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, and Yasutaka Furukawa. Mvdiffusion: Enabling holistic multi- view image generation with correspondence-aware diffusion. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Sys- tems 2023, NeurIPS 2023, New Orleans, LA, USA, Decem- ber 10 - 16, 2023, 2023. 3
2023
-
[40]
Turner, Zoubin Ghahramani, and Sergey Levine
George Tucker, Surya Bhupatiraju, Shixiang Gu, Richard E. Turner, Zoubin Ghahramani, and Sergey Levine. The mirage of action-dependent baselines in reinforcement learning. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Workshop Track Proceedings. OpenReview.net, 2018. 2
2018
-
[41]
Yeh, and Greg Shakhnarovich
Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A. Yeh, and Greg Shakhnarovich. Score jacobian chaining: Lift- ing pretrained 2d diffusion models for 3d generation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17- 24, 2023, pages 12619–12629. IEEE, 2023. 2, 7
2023
-
[42]
Jianyi Wang, Kelvin C. K. Chan, and Chen Change Loy. Ex- ploring CLIP for assessing the look and feel of images. In Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applica- tions of Artificial Intelligence, IAAI 2023, Thirteenth Sym- posium on Educational Advances in Artificial Intelligence, EAAI...
2023
-
[43]
Imagedream: Image-prompt multi-view diffusion for 3d generation,
Peng Wang and Yichun Shi. Imagedream: Image-prompt multi-view diffusion for 3d generation.arXiv preprint arXiv:2312.02201, 2023. 2, 3
-
[44]
Iandola, Rakesh Ranjan, Yilei Li, Qiang Liu, Zhangyang Wang, and Vikas Chandra
Peihao Wang, Dejia Xu, Zhiwen Fan, Dilin Wang, Sreyas Mohan, Forrest N. Iandola, Rakesh Ranjan, Yilei Li, Qiang Liu, Zhangyang Wang, and Vikas Chandra. Taming mode collapse in score distillation for text-to-3d generation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 9037–9047. IEEE...
2024
-
[45]
Iandola, Rakesh Ranjan, Yilei Li, Qiang Liu, Zhangyang Wang, and Vikas Chandra
Peihao Wang, Zhiwen Fan, Dejia Xu, Dilin Wang, Sreyas Mohan, Forrest N. Iandola, Rakesh Ranjan, Yilei Li, Qiang Liu, Zhangyang Wang, and Vikas Chandra. Steindreamer: Variance reduction for text-to-3d score distillation via stein identity. InInternational Conference on Artificial Intelli- gence and Statistics, AISTATS 2025, Mai Khao, Thailand, 3-5 May 2025...
2025
-
[46]
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, De- cember 10 -...
2023
-
[47]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human prefer- ence score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. InarXiv preprint arXiv:2306.09341, 2023. 4, 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Consistent3d: Towards consistent high-fidelity text-to-3d generation with deterministic sampling prior
Zike Wu, Pan Zhou, Xuanyu Yi, Xiaoding Yuan, and Han- wang Zhang. Consistent3d: Towards consistent high-fidelity text-to-3d generation with deterministic sampling prior. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 9892–9902. IEEE, 2024. 2
2024
-
[49]
Imagere- ward: Learning and evaluating human preferences for text- to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagere- ward: Learning and evaluating human preferences for text- to-image generation. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Infor- mation Processing Systems 2023, NeurIPS 2023, New Or- leans, LA, USA, December 10 ...
2023
-
[50]
Consis- tent flow distillation for text-to-3d generation
Runjie Yan, Yinbo Chen, and Xiaolong Wang. Consis- tent flow distillation for text-to-3d generation. InThe Thir- teenth International Conference on Learning Representa- tions, ICLR 2025, Singapore, April 24-28, 2025. OpenRe- view.net, 2025. 3, 19
2025
-
[51]
Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models
Taoran Yi, Jiemin Fang, Junjie Wang, Guanjun Wu, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Qi Tian, and Xing- gang Wang. Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 6796–6807. IEEE, 2024. 3
2024
-
[52]
Text-to-3d with classifier score distillation
Xin Yu, Yuan-Chen Guo, Yangguang Li, Ding Liang, Song- Hai Zhang, and Xiaojuan Qi. Text-to-3d with classifier score distillation. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 2
2024
-
[53]
Monte carlo estimators for differential light transport.ACM Trans
Tizian Zeltner, S ´ebastien Speierer, Iliyan Georgiev, and Wenzel Jakob. Monte carlo estimators for differential light transport.ACM Trans. Graph., 40(4):78:1–78:16, 2021. 2
2021
-
[54]
HIFA: high- fidelity text-to-3d generation with advanced diffusion guid- ance
Junzhe Zhu, Peiye Zhuang, and Sanmi Koyejo. HIFA: high- fidelity text-to-3d generation with advanced diffusion guid- ance. InThe Twelfth International Conference on Learn- ing Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[55]
OpenReview.net, 2024. 2, 7 A. Implementation Details Hardware and software.All experiments run on a sin- gle NVIDIA H100 (80GB); the full benchmark and abla- tion sweeps use four such GPUs in parallel, one config- uration per GPU. The pipeline is built in threestudio [7] with a frozen Stable Diffusion2.1prior [30]; rendering uses nvdiffrast and nerfacc, a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.