GeoRouteNet: Geometry-Enhanced Non-Autoregressive Neural Solver for the Traveling Salesman Problem
Pith reviewed 2026-06-26 09:25 UTC · model grok-4.3
The pith
GeoRouteNet shows geometry enhancements and multi-candidate RL let non-autoregressive models solve Euclidean TSP with low optimality gaps and fast inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
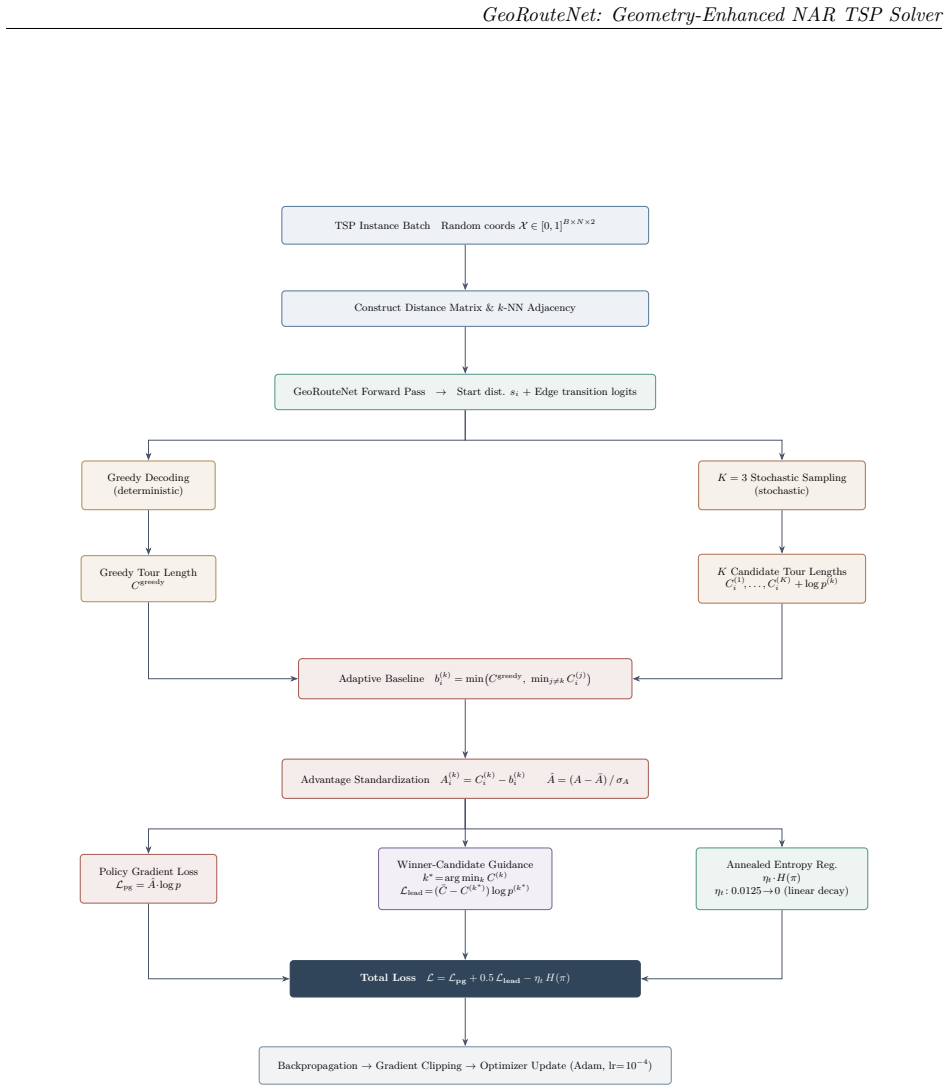
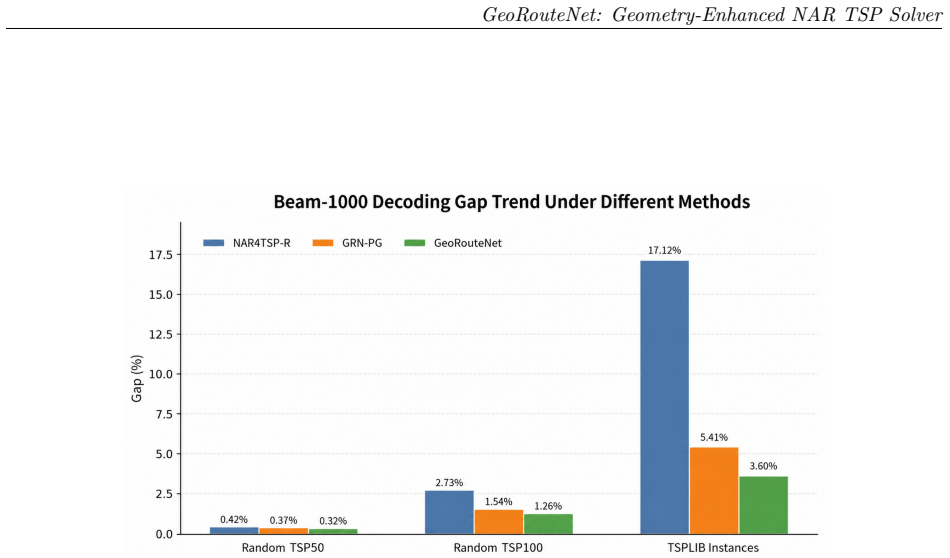
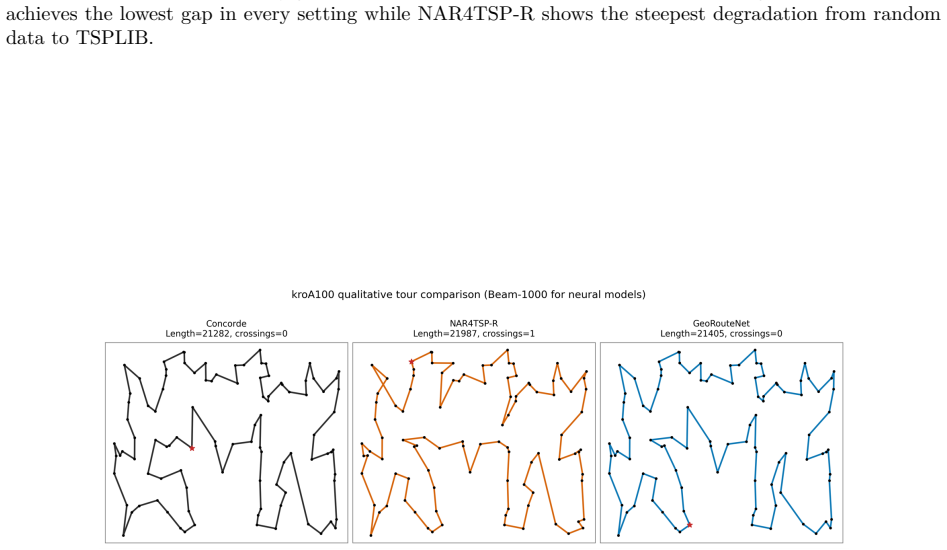
GeoRouteNet incorporates centered node features, learnable radial distance basis functions, distance-aware graph attention with explicit edge messaging, LayerNorm-SwiGLU feed-forward blocks, and cross-layer attentive residual mixing, trained via multi-candidate self-comparison RL that samples multiple candidate tours per instance, constructs adaptive baselines from greedy and peer candidates, and adds winner-candidate guidance with annealed entropy regularization. On 10,000 random TSP50 instances this yields a 0.32 percent optimality gap under Beam-1000 decoding; on TSP100 the gap is 1.26 percent. On 27 stratified TSPLIB EUC_2D instances the overall gap falls from 17.12 percent (prior NAR re
What carries the argument
Geometry-enhanced encoder that uses centered features, learnable radial distance basis functions, and distance-aware graph attention with explicit edge messaging, paired with multi-candidate self-comparison reinforcement learning that builds adaptive baselines from multiple sampled tours.
If this is right
- Non-autoregressive TSP solvers reach sub-2 percent optimality gaps on random instances up to size 100 when equipped with explicit geometric encoding.
- Geometric structure improvements account for most of the gain on real-world distributions while multi-candidate training provides further stabilization.
- Batch inference throughput can exceed that of established solvers such as Concorde and LKH3 on batches of TSP instances.
- Ablation results show the geometric encoder and multi-candidate RL are complementary rather than redundant.
Where Pith is reading between the lines
- The same distance-aware attention and radial basis approach could transfer to other geometric routing problems such as vehicle routing or capacitated variants.
- Explicit modeling of pairwise distances may be a general requirement for scaling non-autoregressive methods beyond synthetic uniform data.
- The reported throughput advantage suggests the architecture could support real-time routing decisions in logistics settings where exact solvers are too slow.
Load-bearing premise
The added geometric components supply enough inductive bias to improve cross-scale and cross-distribution generalization in non-autoregressive TSP solvers.
What would settle it
Running GeoRouteNet on a fresh collection of TSPLIB EUC_2D instances drawn from the same stratified distribution and checking whether the optimality gap stays below 5 percent would directly test the claimed generalization improvement.
Figures


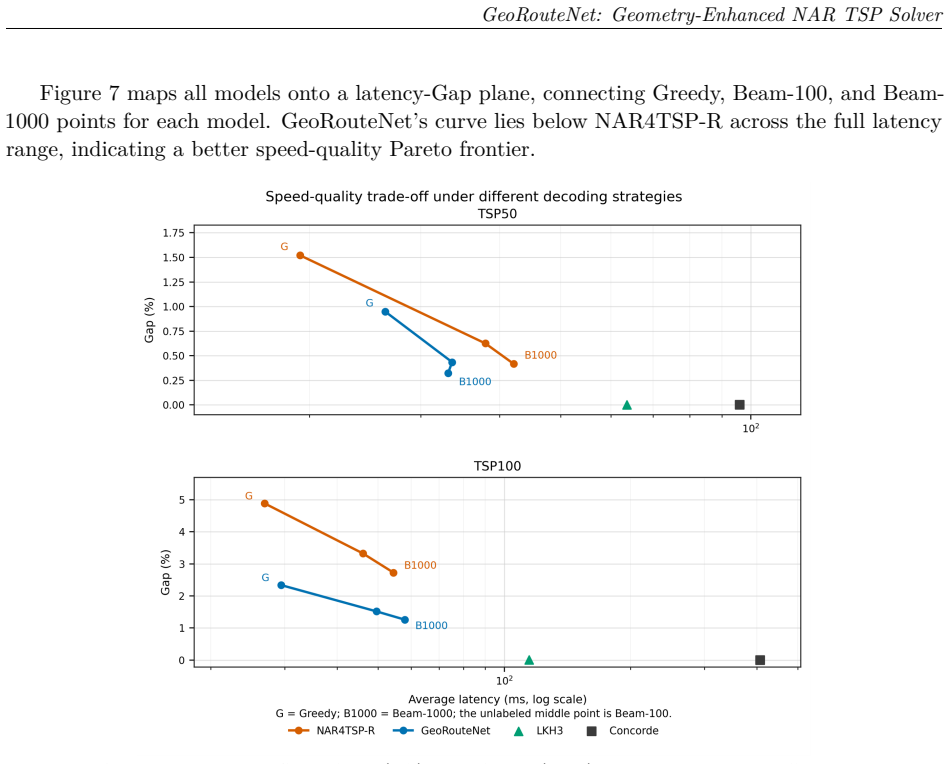
read the original abstract
The traveling salesman problem (TSP) is a canonical NP-hard combinatorial optimization benchmark that tests the representational capacity and generalization of neural solvers. While non-autoregressive (NAR) approaches offer parallel inference, they often lack sufficient geometric inductive bias and stable training signals, leading to degraded performance under cross-scale and cross-distribution shifts. We propose GeoRouteNet, a geometry-enhanced NAR neural solver for Euclidean TSP. On the model side, GeoRouteNet incorporates centered node features, learnable radial distance basis functions, distance-aware graph attention with explicit edge messaging, LayerNorm-SwiGLU feed-forward blocks, and cross-layer attentive residual mixing. On the training side, we design multi-candidate self-comparison reinforcement learning (MCS-RL), which samples multiple candidate tours per instance, constructs adaptive baselines from greedy and peer candidates, and adds winner-candidate guidance with annealed entropy regularization. On 10,000 random TSP50 instances, GeoRouteNet achieves a 0.32% optimality gap under Beam-1000 decoding. On TSP100, the gap is 1.26%. On 27 stratified TSPLIB EUC_2D instances, the overall gap drops from 17.12% (NAR4TSP reproduction) to 3.60%, while batch inference throughput substantially exceeds that of Concorde and LKH3. Ablation studies confirm that geometric structure enhancement and multi-candidate training are complementary: structure improvements dominate cross-distribution gains, while MCS-RL further stabilizes solution quality when paired with a strong geometric encoder.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GeoRouteNet, a geometry-enhanced non-autoregressive neural solver for Euclidean TSP. It augments a NAR encoder with centered node features, learnable radial distance basis functions, distance-aware graph attention with explicit edge messaging, LayerNorm-SwiGLU blocks, and cross-layer attentive residual mixing. Training employs multi-candidate self-comparison reinforcement learning (MCS-RL) that samples multiple tours per instance, builds adaptive baselines from greedy and peer candidates, and applies winner guidance with annealed entropy. Reported results include 0.32% optimality gap on 10,000 random TSP50 instances and 1.26% on TSP100 under Beam-1000 decoding; on 27 stratified TSPLIB EUC_2D instances the gap falls from 17.12% (NAR4TSP reproduction) to 3.60%, with batch throughput exceeding Concorde and LKH3. Ablations attribute cross-distribution gains primarily to the geometric modules while MCS-RL stabilizes quality.
Significance. If the numerical results and the attribution of TSPLIB gains to geometric inductive bias hold after verification, the work would advance NAR TSP solvers by supplying concrete evidence that explicit geometric structure (centered features, radial basis, distance-aware attention) improves cross-scale and cross-distribution generalization. The explicit separation of structure versus training effects in the ablations, together with the throughput comparisons, supplies falsifiable claims that can be tested on additional real-world instances.
major comments (2)
- [Ablation studies] Ablation studies (abstract): the claim that geometric structure improvements dominate the TSPLIB gap reduction (17.12% to 3.60%) is load-bearing for the central generalization argument. The manuscript must confirm that model width, depth, training steps, optimizer, and all MCS-RL hyperparameters remain fixed when the geometric modules (centered features, radial basis functions, distance-aware attention) are removed; otherwise the observed improvement cannot be attributed to the inductive bias.
- [Experiments] Experiments section (random-instance and TSPLIB results): the optimality gaps (0.32% TSP50, 1.26% TSP100, 3.60% TSPLIB) are the primary evidence for the performance claims, yet the abstract and results supply no information on the exact optimality verifier, whether gaps are averaged over multiple independent runs with reported variance or error bars, or any post-hoc instance filtering. These details are required to establish the data-to-claim link.
minor comments (1)
- [Abstract] The abstract states that batch inference throughput substantially exceeds Concorde and LKH3; a table or figure with concrete tokens-per-second or tours-per-second numbers on identical hardware would strengthen the practical-advantage claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. Below we address the two major comments point by point, providing clarifications and committing to revisions where needed to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Ablation studies] Ablation studies (abstract): the claim that geometric structure improvements dominate the TSPLIB gap reduction (17.12% to 3.60%) is load-bearing for the central generalization argument. The manuscript must confirm that model width, depth, training steps, optimizer, and all MCS-RL hyperparameters remain fixed when the geometric modules (centered features, radial basis functions, distance-aware attention) are removed; otherwise the observed improvement cannot be attributed to the inductive bias.
Authors: The ablation experiments were performed with model width, depth, training steps, optimizer, and all MCS-RL hyperparameters held exactly constant; only the geometric modules were removed or disabled. This controlled setup is described in the experiments section, allowing direct attribution of the TSPLIB gains to the inductive biases. To make the control explicit for readers, we will add a clarifying sentence in the ablation subsection. revision: yes
-
Referee: [Experiments] Experiments section (random-instance and TSPLIB results): the optimality gaps (0.32% TSP50, 1.26% TSP100, 3.60% TSPLIB) are the primary evidence for the performance claims, yet the abstract and results supply no information on the exact optimality verifier, whether gaps are averaged over multiple independent runs with reported variance or error bars, or any post-hoc instance filtering. These details are required to establish the data-to-claim link.
Authors: All optimality gaps are computed against exact solutions from the Concorde solver. The reported figures are means over the full sets of 10,000 random instances and 27 TSPLIB instances from a single training run, with no post-hoc filtering of instances. We will revise the experimental section and abstract to state the verifier, the single-run averaging, and the absence of filtering. revision: yes
Circularity Check
No significant circularity in claimed generalization or ablations
full rationale
The provided abstract and context describe an empirical neural solver with geometric modules and an MCS-RL training procedure. Reported optimality gaps are measured against external optima (Concorde/LKH3 or known TSPLIB solutions) on held-out random instances and cross-distribution TSPLIB cases. No equations, self-citations, or derivations are shown that reduce a claimed result to its own fitted inputs by construction. MCS-RL uses model samples for adaptive baselines, but this is standard on-policy RL and does not force the external optimality gaps. Ablation claims attribute gains to geometric bias vs. MCS-RL without evidence of capacity or regime changes that would create definitional equivalence. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable radial distance basis function coefficients
- weights inside distance-aware graph attention and LayerNorm-SwiGLU blocks
axioms (2)
- domain assumption Euclidean TSP instances possess geometric structure that can be directly exploited by node centering, radial basis functions, and edge-distance messaging to improve non-autoregressive performance
- domain assumption Multi-candidate self-comparison reinforcement learning supplies stable training signals that complement geometric encoding
Reference graph
Works this paper leans on
-
[1]
Applegate, Robert E
David L. Applegate, Robert E. Bixby, Vašek Chvátal, and William J. Cook.The Traveling Salesman Problem: A Computational Study. Princeton University Press, 2006
2006
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Dynamic programming treatment of the travelling salesman problem.Journal of the ACM, 9(1):61–63, 1962
Richard Bellman. Dynamic programming treatment of the travelling salesman problem.Journal of the ACM, 9(1):61–63, 1962
1962
-
[4]
Neural Combinatorial Optimization with Reinforcement Learning
Irwan Bello, Hieu Pham, Quoc V. Le, Mohammad Norouzi, and Samy Bengio. Neural combinatorial optimization with reinforcement learning.arXiv preprint arXiv:1611.09940, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Solution of a large-scale traveling-salesman problem.Journal of the Operations Research Society of America, 2(4):393–410, 1954
George Dantzig, Ray Fulkerson, and Selmer Johnson. Solution of a large-scale traveling-salesman problem.Journal of the Operations Research Society of America, 2(4):393–410, 1954
1954
-
[6]
Michael Held and Richard M. Karp. A dynamic programming approach to sequencing problems. Journal of the Society for Industrial and Applied Mathematics, 10(1):196–210, 1962
1962
-
[7]
An effective implementation of the Lin-Kernighan traveling salesman heuristic
Keld Helsgaun. An effective implementation of the Lin-Kernighan traveling salesman heuristic. European Journal of Operational Research, 126(1):106–130, 2000
2000
-
[8]
An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems
Keld Helsgaun. An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems. Technical report, Roskilde University, 2017
2017
-
[9]
Xinyu Jiang, Yuxiang Wu, Yanzhen Wang, and Yu Zhang. Bridging large language models and optimization: A unified framework for text-attributed combinatorial optimization.arXiv preprint arXiv:2408.12214, 2024
-
[10]
Joshi, Thomas Laurent, and Xavier Bresson
Chaitanya K. Joshi, Thomas Laurent, and Xavier Bresson. An efficient graph convolutional network technique for the travelling salesman problem.arXiv preprint arXiv:1906.01227, 2019
-
[11]
Joshi, Quentin Cappart, Louis-Martin Rousseau, and Thomas Laurent
Chaitanya K. Joshi, Quentin Cappart, Louis-Martin Rousseau, and Thomas Laurent. Learning the travelling salesperson problem requires rethinking generalization.Constraints, 27(1-2): 70–98, 2022
2022
-
[12]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), 2015
2015
-
[13]
Attention, learn to solve routing problems! InInternational Conference on Learning Representations (ICLR), 2019
Wouter Kool, Herke van Hoof, and Max Welling. Attention, learn to solve routing problems! InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[14]
POMO: Policy optimization with multiple optima for reinforcement learning
Yeong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Yoon, Youngjune Gwon, and Seungjai Min. POMO: Policy optimization with multiple optima for reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. 18 GeoRouteNet: Geometry-Enhanced NAR TSP Solver
2020
-
[15]
Lawler, Jan Karel Lenstra, Alexander H
Eugene L. Lawler, Jan Karel Lenstra, Alexander H. G. Rinnooy Kan, and David B. Shmoys, editors.The Traveling Salesman Problem: A Guided Tour of Combinatorial Optimization. Wiley, 1985
1985
-
[16]
Kernighan
Shen Lin and Brian W. Kernighan. An effective heuristic algorithm for the traveling-salesman problem.Operations Research, 21(2):498–516, 1973
1973
-
[17]
TSPLIB: A traveling salesman problem library.ORSA Journal on Computing, 3(4):376–384, 1991
Gerhard Reinelt. TSPLIB: A traveling salesman problem library.ORSA Journal on Computing, 3(4):376–384, 1991
1991
-
[18]
GLU Variants Improve Transformer
Noam Shazeer. GLU variants improve Transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[19]
DIFUSCO: Graph-based diffusion solvers for combinatorial optimization
Zhiqing Sun and Yiming Yang. DIFUSCO: Graph-based diffusion solvers for combinatorial optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[20]
Gomez, ŁukaszKaiser, andIlliaPolosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, ŁukaszKaiser, andIlliaPolosukhin. Attentionisallyouneed. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[21]
Graph attention networks
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[22]
Pointer Networks
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer Networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[23]
An efficient diffusion-based non-autoregressive solver for traveling salesman problem
Mingzheng Wang, You Zhou, Zhiguang Cao, Yubin Xiao, Xuan Wu, Wei Pang, Yanchun Jiang, Hui Yang, Peng Zhao, and Yongsheng Li. An efficient diffusion-based non-autoregressive solver for traveling salesman problem. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), pages 1469–1480, 2025
2025
-
[24]
Reinforcement learning-based nonautoregressive solver for traveling salesman problems.IEEE Transactions on Neural Networks and Learning Systems, 36(7):13402–13416, 2025
Yubin Xiao, Di Wang, Bin Li, Huanhuan Chen, Wei Pang, Xuan Wu, Hao Li, Dong Xu, Yanchun Liang, and You Zhou. Reinforcement learning-based nonautoregressive solver for traveling salesman problems.IEEE Transactions on Neural Networks and Learning Systems, 36(7):13402–13416, 2025
2025
-
[25]
ReEvo: Large language models as hyper-heuristics with reflective evolution
Haotian Ye, Jie Wang, Zhiguang Cao, Federico Berto, Chuanbo Hua, Haeyeon Kim, Jinkyoo Park, and Guojie Song. ReEvo: Large language models as hyper-heuristics with reflective evolution. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 19
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.