CalArena: A Large-Scale Post-Hoc Calibration Benchmark
Pith reviewed 2026-06-29 08:16 UTC · model grok-4.3
The pith
Post-Hoc Improvement in proper scoring rules offers a principled alternative to traditional calibration error estimators for comparing post-hoc methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
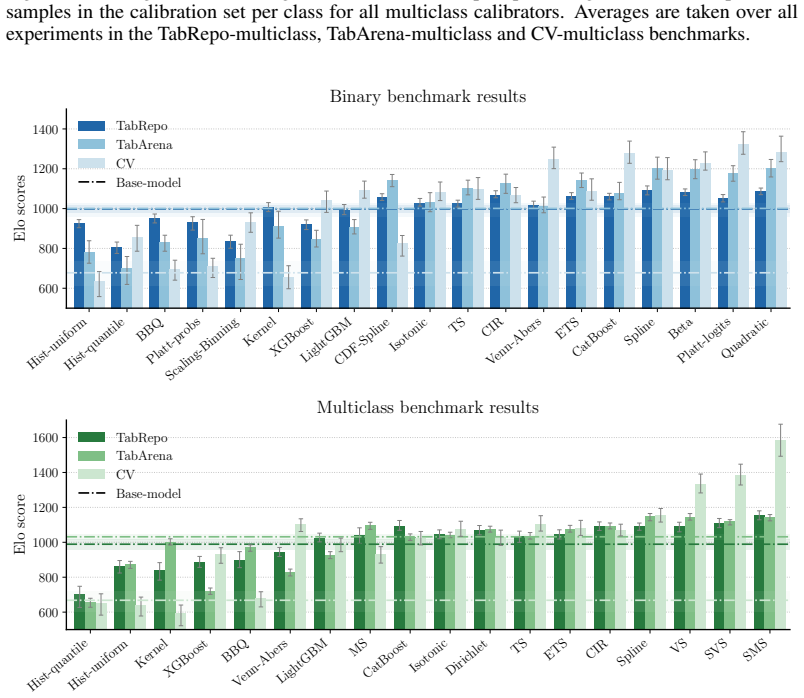
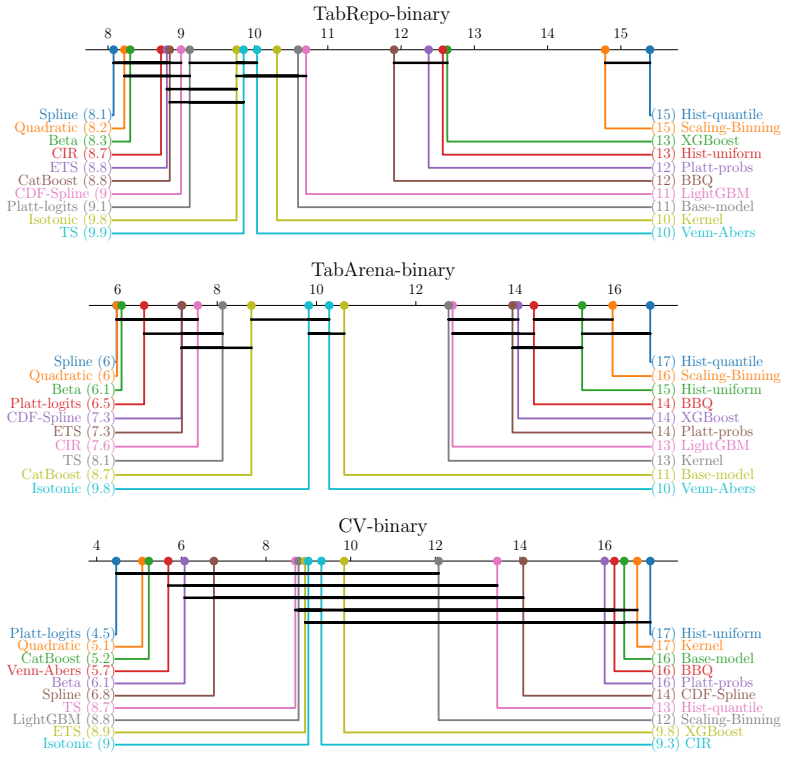
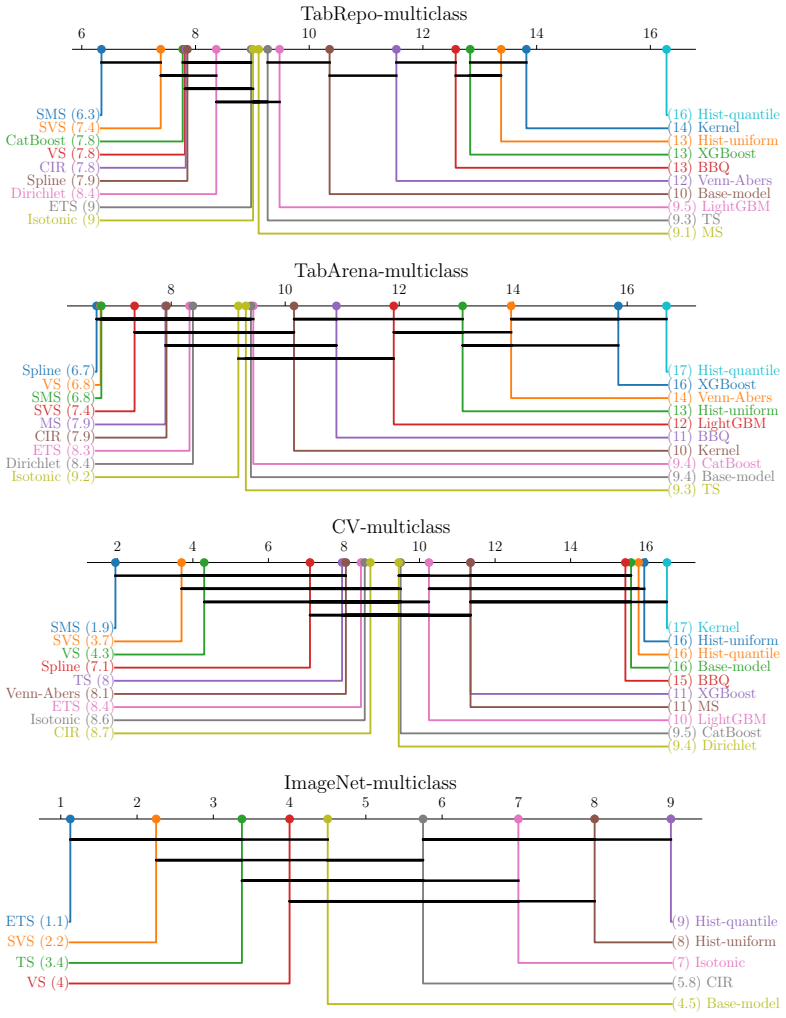
Post-Hoc Improvement (PHI) in proper scoring rules offers a principled alternative to traditional calibration error estimators for comparing post-hoc methods, capturing both calibration quality and potential degradation to the model's predictive performance. Using this framework on a benchmark of nearly 2000 experiments, the results show that smooth calibration functions outperform binning-based approaches, dedicated multiclass methods are essential in high-dimensional settings, and generic machine learning models are not competitive without calibration-specific design.
What carries the argument
Post-Hoc Improvement (PHI), defined as the change in a proper scoring rule value after a post-hoc calibration map is applied to a model's raw predictions.
If this is right
- Smooth calibration functions outperform binning-based approaches across tabular and vision domains.
- Dedicated multiclass methods are essential in high-dimensional output settings.
- Generic machine learning models are not competitive without calibration-specific design.
- A shared benchmark with unified implementations enables reproducible comparison of new calibration methods.
Where Pith is reading between the lines
- Teams deploying models in new domains could first run the released benchmark code on their own data to decide which calibration family to adopt.
- Emphasis on proper scoring rules may shift research attention from isolated calibration-error numbers toward joint calibration-plus-accuracy objectives.
- The same experimental design could be reused to test whether the reported ordering of methods persists on sequential or graph-structured data.
Load-bearing premise
The collection of models, datasets, and calibration implementations chosen for the benchmark is representative enough that the observed patterns will hold for other models and data.
What would settle it
A new collection of models and datasets on which binning-based methods achieve strictly higher PHI scores than smooth functions across multiple proper scoring rules.
Figures
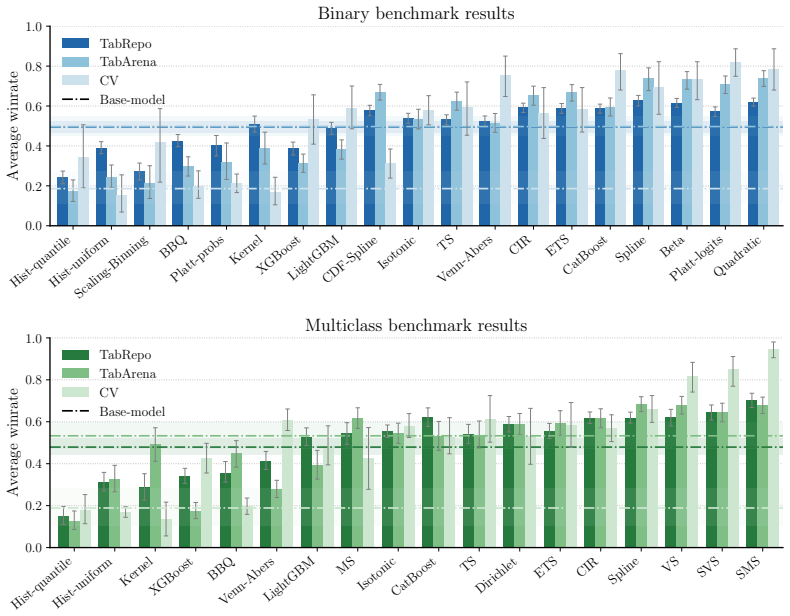
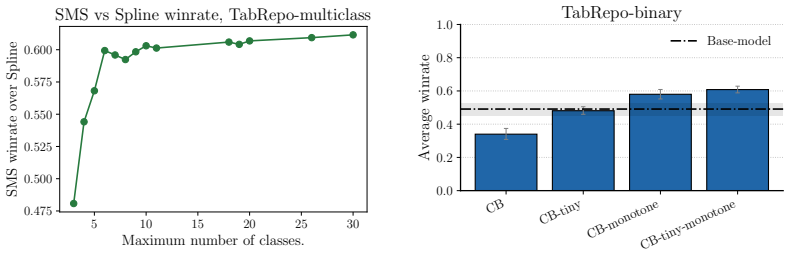

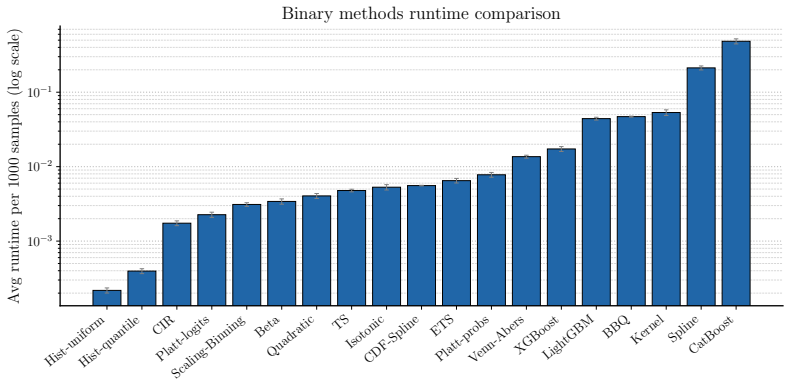

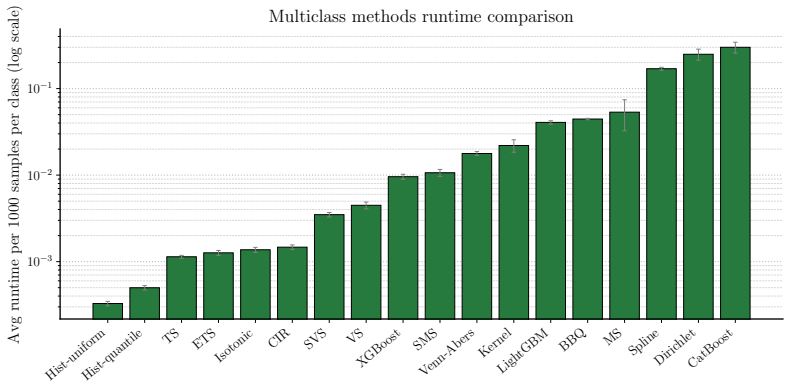
read the original abstract
Reliable probability estimates are critical in many machine learning applications, yet modern classifiers are often poorly calibrated. Post-hoc calibration provides a simple and widely used solution, but the large number of proposed methods, combined with small-scale and inconsistent evaluations, makes it difficult to determine which approaches are truly effective in practice. We introduce a large-scale, standardized benchmark for post-hoc calibration, covering nearly 2000 experiments across tabular and computer vision tasks, including binary, multiclass, and large-scale classification settings. Our benchmark aggregates predictions from a diverse set of classical models, modern deep learning architectures, and foundation models, and provides unified, reproducible implementations of dozens of calibration methods within a common evaluation framework. We argue that Post-Hoc Improvement (PHI) in proper scoring rules offers a principled alternative to traditional calibration error estimators for comparing post-hoc methods, capturing both calibration quality and potential degradation to the model's predictive performance. Using this framework, we conduct the most comprehensive empirical study of post-hoc calibration to date. Our results reveal consistent patterns across domains: smooth calibration functions outperform binning-based approaches, dedicated multiclass methods are essential in high-dimensional settings, and generic machine learning models are not competitive without calibration-specific design. To facilitate future research, we release all data, code, and evaluation tools, providing a plug-and-play benchmark for developing and comparing calibration methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CalArena, a large-scale benchmark for post-hoc calibration methods consisting of nearly 2000 experiments across tabular and computer vision tasks (binary, multiclass, and large-scale settings). It aggregates predictions from classical models, deep architectures, and foundation models, provides unified implementations of dozens of calibration methods, and releases all data, code, and evaluation tools. The central methodological contribution is the proposal of Post-Hoc Improvement (PHI) in proper scoring rules as an alternative to traditional calibration error estimators. Empirical results report consistent patterns: smooth calibration functions outperform binning-based approaches, dedicated multiclass methods are essential in high-dimensional settings, and generic ML models are not competitive without calibration-specific design.
Significance. If the selection of models, datasets, and methods is representative and the experimental controls are adequate, the work supplies a much-needed standardized, reproducible resource for the calibration literature, directly addressing the problem of small-scale and inconsistent prior evaluations. The code and data release is a clear strength that enables plug-and-play future research. The PHI metric is a principled advance because it jointly captures calibration quality and any degradation to predictive performance, unlike isolated calibration-error metrics.
major comments (2)
- [Experimental design / methods for the benchmark construction] The experimental design section provides no coverage analysis, sensitivity study, or explicit justification for the distribution of tasks, architectures, calibration implementations, or output dimensionalities in the ~2000 experiments. This is load-bearing for the generalization claims in the results (smooth functions outperform binning; dedicated multiclass methods essential), because under-sampling of regimes such as extreme class imbalance or very high output dimensionality could render the reported patterns non-robust.
- [Results and evaluation framework] The results and evaluation sections contain no description of statistical testing, variance estimation across runs, or sensitivity checks to implementation choices and hyper-parameters. This directly limits verification of the soundness of the headline empirical patterns and of the superiority claims for PHI over traditional estimators.
minor comments (1)
- [Abstract] The abstract states 'nearly 2000 experiments' without a precise count or breakdown by task type; adding this table or sentence would improve reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Experimental design / methods for the benchmark construction] The experimental design section provides no coverage analysis, sensitivity study, or explicit justification for the distribution of tasks, architectures, calibration implementations, or output dimensionalities in the ~2000 experiments. This is load-bearing for the generalization claims in the results (smooth functions outperform binning; dedicated multiclass methods essential), because under-sampling of regimes such as extreme class imbalance or very high output dimensionality could render the reported patterns non-robust.
Authors: We agree that explicit coverage analysis and sensitivity justification are needed to support the generalization claims. In the revision we will add a new subsection to the experimental design that reports the empirical distribution of experiments across output dimensionality, class imbalance ratios, and task types, together with a brief sensitivity study that re-samples subsets of the benchmark and confirms that the headline patterns (smooth methods outperforming binning; dedicated multiclass methods required at high dimensionality) remain stable. The selection of tasks and models was guided by standard public benchmarks used in prior calibration studies, but we accept that this rationale should be stated more formally. revision: yes
-
Referee: [Results and evaluation framework] The results and evaluation sections contain no description of statistical testing, variance estimation across runs, or sensitivity checks to implementation choices and hyper-parameters. This directly limits verification of the soundness of the headline empirical patterns and of the superiority claims for PHI over traditional estimators.
Authors: We acknowledge the omission. The revised manuscript will expand the evaluation framework section to describe bootstrap-based variance estimation for PHI scores, paired statistical tests (e.g., Wilcoxon signed-rank) for method comparisons, and sensitivity checks to the main hyper-parameters of each calibration method. These additions will allow readers to assess the reliability of the reported superiority of smooth functions and the necessity of dedicated multiclass methods. revision: yes
Circularity Check
Empirical benchmark with no circular derivation chain
full rationale
The paper introduces a large-scale empirical benchmark and argues for PHI as an evaluation metric based on proper scoring rules. No equations, fitted parameters, or self-citations are used to derive results by construction; all claims rest on released data, code, and observed patterns across experiments. This matches the default case of a self-contained empirical study with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dataset of breast ultrasound images.Data in Brief, 28:104863, 2020
Walid Al-Dhabyani, Mohammed Gomaa, Hussien Khaled, and Aly Fahmy. Dataset of breast ultrasound images.Data in Brief, 28:104863, 2020
2020
-
[2]
Improving multi-class calibration through normalization-aware isotonic techniques
Alon Arad and Saharon Rosset. Improving multi-class calibration through normalization-aware isotonic techniques. InInternational Conference on Machine Learning, 2025
2025
-
[3]
Metrics of calibration for probabilistic predictions.Journal of Machine Learning Research, 23(351): 1–54, 2022
Imanol Arrieta-Ibarra, Paman Gujral, Jonathan Tannen, Mark Tygert, and Cherie Xu. Metrics of calibration for probabilistic predictions.Journal of Machine Learning Research, 23(351): 1–54, 2022
2022
-
[4]
Daniel Brunk, George M
Miriam Ayer, H. Daniel Brunk, George M. Ewing, William T. Reid, and Edward Silverman. An empirical distribution function for sampling with incomplete information.The Annals of Mathematical Statistics, 26(4):641–647, 1955
1955
-
[5]
Brenier isotonic regression
Han Bao, Amirreza Eshraghi, and Yutong Wang. Brenier isotonic regression. InInternational Conference on Artificial Intelligence and Statistics, 2026
2026
-
[6]
BEiT: BERT pre-training of image transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BEiT: BERT pre-training of image transformers. InInternational Conference on Learning Representations, 2022
2022
-
[7]
Classifier calibration with ROC-regularized isotonic regression
Eugène Berta, Francis Bach, and Michael Jordan. Classifier calibration with ROC-regularized isotonic regression. InInternational Conference on Artificial Intelligence and Statistics, 2024
2024
-
[8]
Eugène Berta, David Holzmüller, Michael I. Jordan, and Francis Bach. Rethinking early stopping: Refine, then calibrate.arXiv preprint arXiv:2501.19195, 2025
-
[9]
Jordan, and Francis Bach
Eugène Berta, Sacha Braun, David Holzmüller, Michael I. Jordan, and Francis Bach. A variational estimator for Lp calibration errors. InAISTATS Workshop: Towards Trustworthy Predictions: Theory and Applications of Calibration for Modern AI, 2026
2026
-
[10]
Jordan, and Francis Bach
Eugène Berta, David Holzmüller, Michael I. Jordan, and Francis Bach. Structured matrix scaling for multi-class calibration. InInternational Conference on Artificial Intelligence and Statistics, 2026
2026
-
[11]
Smooth ECE: Principled reliability diagrams via kernel smoothing
Jarosław Błasiok and Preetum Nakkiran. Smooth ECE: Principled reliability diagrams via kernel smoothing. InInternational Conference on Learning Representations, 2024
2024
-
[12]
Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[13]
Random forests.Machine Learning, 45(1):5–32, 2001
Leo Breiman. Random forests.Machine Learning, 45(1):5–32, 2001
2001
-
[14]
Reliability, sufficiency, and the decomposition of proper scores.Quarterly Journal of the Royal Meteorological Society, 135(643):1512–1519, 2009
Jochen Bröcker. Reliability, sufficiency, and the decomposition of proper scores.Quarterly Journal of the Royal Meteorological Society, 135(643):1512–1519, 2009. 11
2009
-
[15]
XGBoost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. InInternational Conference on Knowledge Discovery and Data Mining, 2016
2016
-
[16]
Gonzalez, and Ion Stoica
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference. InInternational Conference on Machine Learning, 2024
2024
-
[17]
Statistical comparisons of classifiers over multiple data sets.Journal of Machine Learning Research, 7(1):1–30, 2006
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.Journal of Machine Learning Research, 7(1):1–30, 2006
2006
-
[18]
ImageNet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. InConference on Computer Vision and Pattern Recognition, 2009
2009
-
[19]
Jordan, and Peter V ogel
Timo Dimitriadis, Tilmann Gneiting, Alexander I. Jordan, and Peter V ogel. Evaluating prob- abilistic classifiers: The triptych.International Journal of Forecasting, 40(3):1101–1122, 2024
2024
-
[20]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[21]
AutoGluon-Tabular: Robust and accurate AutoML for structured data
Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, and Alexander Smola. AutoGluon-Tabular: Robust and accurate AutoML for structured data. In ICML Workshop on Automated Machine Learning, 2020
2020
-
[22]
TabArena: A living benchmark for machine learning on tabular data
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. TabArena: A living benchmark for machine learning on tabular data. InAdvances in Neural Information Processing Systems, 2025
2025
-
[23]
EV A: Exploring the limits of masked visual representation learning at scale
Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. EV A: Exploring the limits of masked visual representation learning at scale. InConference on Computer Vision and Pattern Recognition, 2023
2023
-
[24]
Extremely randomized trees.Machine Learning, 63(1):3–42, 2006
Pierre Geurts, Damien Ernst, and Louis Wehenkel. Extremely randomized trees.Machine Learning, 63(1):3–42, 2006
2006
-
[25]
Tilmann Gneiting and Adrian E. Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102(477):359–378, 2007
2007
-
[26]
TabM: Advancing tabular deep learning with parameter-efficient ensembling
Yury Gorishniy, Akim Kotelnikov, and Artem Babenko. TabM: Advancing tabular deep learning with parameter-efficient ensembling. InInternational Conference on Learning Representations, 2025
2025
-
[27]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, Mihir Manium, Rosen Yu, Felix Jablon- ski, Shi Bin Hoo, Anurag Garg, Jake Robertson, Magnus Bühler, Vladyslav Moroshan, Lennart Purucker, Clara Cornu, Lilly Charlotte Wehrhahn, Alessandro Bonetto, Bernhard Schö...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InInternational Conference on Machine Learning, 2017
2017
-
[29]
Calibration of neural networks using splines
Kartik Gupta, Amir Rahimi, Thalaiyasingam Ajanthan, Thomas Mensink, Cristian Sminchis- escu, and Richard Hartley. Calibration of neural networks using splines. InInternational Conference on Learning Representations, 2021
2021
-
[30]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InConference on Computer Vision and Pattern Recognition, 2016
2016
-
[31]
Achim Hekler, Lukas Kuhn, and Florian Buettner. Beyond overconfidence: foundation models redefine calibration in deep neural networks.arXiv preprint arXiv:2506.09593, 2025. 12
-
[32]
Better by default: Strong pre-tuned MLPs and boosted trees on tabular data
David Holzmüller, Léo Grinsztajn, and Ingo Steinwart. Better by default: Strong pre-tuned MLPs and boosted trees on tabular data. InAdvances in Neural Information Processing Systems, 2024
2024
-
[33]
fastai: A layered API for deep learning.Information, 11 (2):108, 2020
Jeremy Howard and Sylvain Gugger. fastai: A layered API for deep learning.Information, 11 (2):108, 2020
2020
-
[34]
Weinberger
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q. Weinberger. Densely connected convolutional networks. InConference on Computer Vision and Pattern Recognition, 2017
2017
-
[35]
LightGBM: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. LightGBM: A highly efficient gradient boosting decision tree. InAdvances in Neural Information Processing Systems, 2017
2017
-
[36]
Kermany, Michael Goldbaum, Wenjia Cai, Carolina C.S
Daniel S. Kermany, Michael Goldbaum, Wenjia Cai, Carolina C.S. Valentim, Huiying Liang, Sally L. Baxter, Alex McKeown, Ge Yang, Xiaokang Wu, Fangbing Yan, Justin Dong, Made K. Prasadha, Jacqueline Pei, Magdalene Y .L. Ting, Jie Zhu, Christina Li, Sierra Hewett, Jason Dong, Ian Ziyar, Alexander Shi, Runze Zhang, Lianghong Zheng, Rui Hou, William Shi, Xin F...
2018
-
[37]
Learning multiple layers of features from tiny images, 2009
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images, 2009
2009
-
[38]
Beta calibration: a well-founded and eas- ily implemented improvement on logistic calibration for binary classifiers
Meelis Kull, Telmo Silva Filho, and Peter Flach. Beta calibration: a well-founded and eas- ily implemented improvement on logistic calibration for binary classifiers. InInternational Conference on Artificial Intelligence and Statistics, 2017
2017
-
[39]
Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with Dirichlet calibration
Meelis Kull, Miquel Perello Nieto, Markus Kängsepp, Telmo Silva Filho, Hao Song, and Peter Flach. Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with Dirichlet calibration. InAdvances in Neural Information Processing Systems, 2019
2019
-
[40]
Liang, and Tengyu Ma
Ananya Kumar, Percy S. Liang, and Tengyu Ma. Verified uncertainty calibration. InAdvances in Neural Information Processing Systems, 2019
2019
-
[41]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[42]
Taking a step back with KCal: Multi-class kernel-based calibration for deep neural networks
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Taking a step back with KCal: Multi-class kernel-based calibration for deep neural networks. InInternational Conference on Learning Representations, 2023
2023
-
[43]
TabPFN unleashed: A scalable and effective solution to tabular classification problems
Siyang Liu and Han-Jia Ye. TabPFN unleashed: A scalable and effective solution to tabular classification problems. InInternational Conference on Machine Learning, 2025
2025
-
[44]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InInternational Conference on Computer Vision, 2021
2021
-
[45]
A convnet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InConference on Computer Vision and Pattern Recognition, 2022
2022
-
[46]
Spline-Based Probability Calibration
Brian Lucena. Spline-based probability calibration.arXiv preprint arXiv:1809.07751, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[47]
Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Alex Labach, Hamidreza Kamkari, Jesse C. Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L. Caterini, and Maksims V olkovs. Tab- DPT: Scaling tabular foundation models on real data. InAdvances in Neural Information Processing Systems, 2025. 13
2025
-
[48]
Valery Manokhin and Daniel Grønhaug. Classifier calibration at scale: An empirical study of model-agnostic post-hoc methods.arXiv preprint arXiv:2601.19944, 2026
-
[49]
Revisiting the calibration of modern neural networks
Matthias Minderer, Josip Djolonga, Rob Romijnders, Frances Hubis, Xiaohua Zhai, Neil Houlsby, Dustin Tran, and Mario Lucic. Revisiting the calibration of modern neural networks. InAdvances in Neural Information Processing Systems, 2021
2021
-
[50]
Zachary Nado, Neil Band, Mark Collier, Josip Djolonga, Michael W. Dusenberry, Sebastian Farquhar, Qixuan Feng, Angelos Filos, Marton Havasi, Rodolphe Jenatton, Ghassen Jerfel, Jeremiah Liu, Zelda Mariet, Jeremy Nixon, Shreyas Padhy, Jie Ren, Tim G. J. Rudner, Faris Sbahi, Yeming Wen, Florian Wenzel, Kevin Murphy, D. Sculley, Balaji Lakshminarayanan, Jaspe...
-
[51]
Obtaining well calibrated probabilities using bayesian binning
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. InAAAI Conference on Artificial Intelligence, 2015
2015
-
[52]
Peter Bjorn Nemenyi.Distribution-Free Multiple Comparisons.Princeton University, 1963
1963
-
[53]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y . Ng. Reading digits in natural images with unsupervised feature learning. InNIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011
2011
-
[54]
Predicting good probabilities with supervised learning
Alexandru Niculescu-Mizil and Rich Caruana. Predicting good probabilities with supervised learning. InInternational Conference on Machine Learning, 2005
2005
-
[55]
Dusenberry, Linchuan Zhang, Ghassen Jerfel, and Dustin Tran
Jeremy Nixon, Michael W. Dusenberry, Linchuan Zhang, Ghassen Jerfel, and Dustin Tran. Mea- suring calibration in deep learning. InConference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2019
2019
-
[56]
Oron and Nancy Flournoy
Assaf P. Oron and Nancy Flournoy. Centered isotonic regression: point and interval estimation for dose–response studies.Statistics in Biopharmaceutical Research, 9(3):258–267, 2017
2017
-
[57]
Sculley, Sebastian Nowozin, Joshua Dillon, Balaji Lakshminarayanan, and Jasper Snoek
Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, D. Sculley, Sebastian Nowozin, Joshua Dillon, Balaji Lakshminarayanan, and Jasper Snoek. Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift. InAdvances in Neural Information Processing Systems, 2019
2019
-
[58]
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.Advances in Large Margin Classifiers, 10(3):61–74, 1999
John Platt. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.Advances in Large Margin Classifiers, 10(3):61–74, 1999
1999
-
[59]
A consistent and differentiable Lp canonical calibration error estimator
Teodora Popordanoska, Raphael Sayer, and Matthew Blaschko. A consistent and differentiable Lp canonical calibration error estimator. InAdvances in Neural Information Processing Systems, 2022
2022
-
[60]
Blaschko
Teodora Popordanoska, Sebastian Gregor Gruber, Aleksei Tiulpin, Florian Buettner, and Matthew B. Blaschko. Consistent and asymptotically unbiased estimation of proper calibration errors. InInternational Conference on Artificial Intelligence and Statistics, 2024
2024
-
[61]
CatBoost: unbiased boosting with categorical features
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin. CatBoost: unbiased boosting with categorical features. InAdvances in Neural Information Processing Systems, 2018
2018
-
[62]
Extending temperature scaling with homoge- nizing maps.Journal of Machine Learning Research, 26(161):1–46, 2025
Christopher Qian, Feng Liang, and Jason Adams. Extending temperature scaling with homoge- nizing maps.Journal of Machine Learning Research, 26(161):1–46, 2025
2025
-
[63]
TabICL: A tabular foundation model for in-context learning on large data
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A tabular foundation model for in-context learning on large data. InInternational Conference on Machine Learning, 2025
2025
-
[64]
TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv:2602.11139, 2026
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv preprint arXiv:2602.11139, 2026. 14
-
[65]
Intra order-preserving functions for calibration of multi-class neural networks
Amir Rahimi, Amirreza Shaban, Ching-An Cheng, Richard Hartley, and Byron Boots. Intra order-preserving functions for calibration of multi-class neural networks. InAdvances in Neural Information Processing Systems, 2020
2020
-
[66]
torchcal: post-hoc calibration on GPU, 2023
Rishabh Ranjan. torchcal: post-hoc calibration on GPU, 2023. URL https://github.com/ rishabh-ranjan/torchcal
2023
-
[67]
Rebecca Roelofs, Nicholas Cain, Jonathon Shlens, and Michael C. Mozer. Mitigating bias in calibration error estimation. InInternational Conference on Artificial Intelligence and Statistics, 2022
2022
-
[68]
TabRepo: A large scale repository of tabular model eval- uations and its AutoML applications
David Salinas and Nick Erickson. TabRepo: A large scale repository of tabular model eval- uations and its AutoML applications. InInternational Conference on Automated Machine Learning, 2024
2024
-
[69]
Axiomatic characterization of the quadratic scoring rule.Experimental Economics, 1(1):43–61, 1998
Reinhard Selten. Axiomatic characterization of the quadratic scoring rule.Experimental Economics, 1(1):43–61, 1998
1998
-
[70]
A benchmark study on calibration
Linwei Tao, Younan Zhu, Haolan Guo, Minjing Dong, and Chang Xu. A benchmark study on calibration. InInternational Conference on Learning Representations, 2024
2024
-
[71]
Terpilowski
Maksim A. Terpilowski. scikit-posthocs: Pairwise multiple comparison tests in Python.Journal of Open Source Software, 4(36):1169, 2019
2019
-
[72]
The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions.Scientific Data, 5(1): 180161, 2018
Philipp Tschandl, Cliff Rosendahl, and Harald Kittler. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions.Scientific Data, 5(1): 180161, 2018
2018
-
[73]
Evaluating model calibration in classification
Juozas Vaicenavicius, David Widmann, Carl Andersson, Fredrik Lindsten, Jacob Roll, and Thomas Schön. Evaluating model calibration in classification. InInternational Conference on Artificial Intelligence and Statistics, 2019
2019
-
[74]
Large-scale probabilistic predictors with and without guarantees of validity
Vladimir V ovk, Ivan Petej, and Valentina Fedorova. Large-scale probabilistic predictors with and without guarantees of validity. InAdvances in Neural Information Processing Systems, 2015
2015
-
[75]
The Caltech-UCSD Birds-200-2011 dataset, 2011
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The Caltech-UCSD Birds-200-2011 dataset, 2011
2011
-
[76]
Non-parametric calibration for classification
Jonathan Wenger, Hedvig Kjellström, and Rudolph Triebel. Non-parametric calibration for classification. InInternational Conference on Artificial Intelligence and Statistics, 2020
2020
-
[77]
Revisiting nearest neighbor for tabular data: A deep tabular baseline two decades later
Han-Jia Ye, Huai-Hong Yin, De-Chuan Zhan, and Wei-Lun Chao. Revisiting nearest neighbor for tabular data: A deep tabular baseline two decades later. InInternational Conference on Learning Representations, 2025
2025
-
[78]
Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers
Bianca Zadrozny and Charles Elkan. Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers. InInternational Conference on Machine Learning, 2001
2001
-
[79]
Transforming classifier scores into accurate multiclass probability estimates
Bianca Zadrozny and Charles Elkan. Transforming classifier scores into accurate multiclass probability estimates. InInternational Conference on Knowledge Discovery and Data Mining, 2002
2002
-
[80]
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks.arXiv preprint arXiv:1605.07146, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.