Generative Archetype-Grounded Item Representations for Sequential Recommendation
Pith reviewed 2026-06-27 11:22 UTC · model grok-4.3
The pith
GenAIR creates LLM-generated descriptions of an item's ideal target audience and calibrates the resulting embeddings against real user interactions to strengthen sequential recommendation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
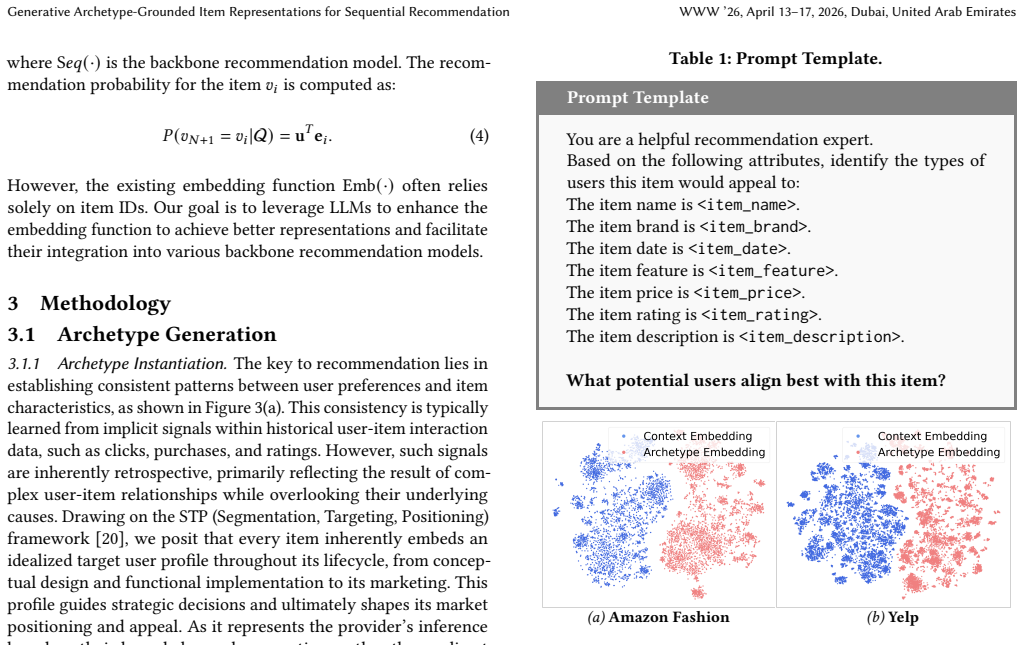
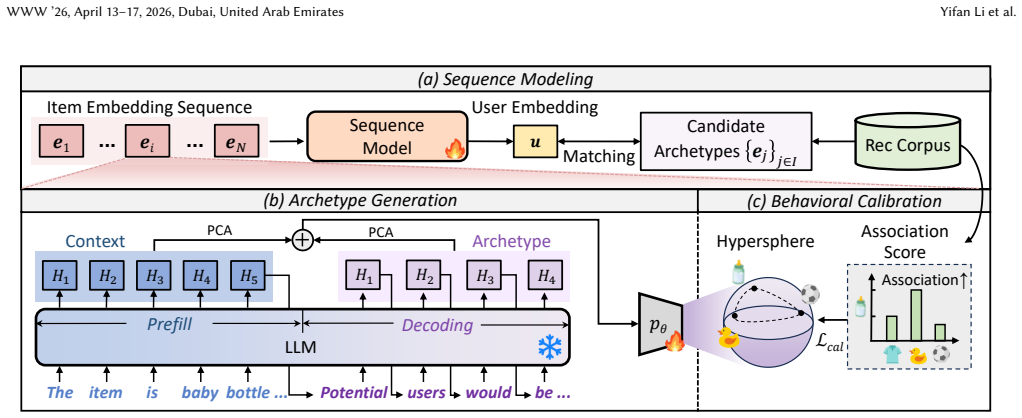
GenAIR leverages an LLM to infer textual descriptions of the archetype representing the conceptual profile of an item's ideal target audience from metadata, extracts the corresponding embeddings in a single forward pass, and grounds these generative archetypes in real-world behavior through a calibration objective that explicitly incorporates behavioral signals from actual interactions to adjust the structure of the embedding space.
What carries the argument
The generative archetype (an LLM-produced textual profile of the item's ideal target audience) together with the behavioral calibration objective that realigns embeddings to empirical interaction patterns.
If this is right
- Most existing sequential recommendation architectures can adopt the new item representations without any change to their internal design or training loops.
- The added representations raise next-item prediction accuracy across multiple base models on three real-world datasets.
- The method runs efficiently because archetype embeddings are obtained in a single LLM forward pass plus a lightweight calibration step.
- The embedding space is explicitly pulled toward both semantic item identity and observed behavioral regularities.
Where Pith is reading between the lines
- The same archetype-plus-calibration pattern could supply priors for cold-start items whose interaction histories are still empty.
- If audience profiles prove stable across domains, the technique might transfer to session-based or cross-domain recommendation without retraining the LLM component.
- Extending the calibration objective to include temporal or multi-behavior signals could further tighten the link between generated archetypes and evolving user preferences.
Load-bearing premise
An LLM can reliably produce archetype descriptions from item metadata that meaningfully capture the conceptual profile of the ideal target audience, and the behavioral calibration objective can adjust embeddings to reflect empirical patterns without introducing new biases or losing useful semantic structure.
What would settle it
Running the same sequential models on the three evaluation datasets with and without GenAIR yields no consistent lift in next-item prediction metrics, or the calibrated archetype embeddings show no measurable alignment with observed user behavior distributions.
Figures


read the original abstract
Sequential recommendation aims to predict users' next interaction with items by analyzing their historical behavior. However, the limited quality of item representations remains a critical bottleneck. While pre-trained large language models (LLMs) can provide rich semantic representations, existing approaches only rely on static encoding of fixed attributes, overlooking the crucial role of target audiences in defining item identity. Moreover, the semantic space struggles to reflect actual user behavior, resulting in a significant gap between semantic representations and behavioral patterns. To address these limitations, we propose GenAIR, a general framework that empowers sequential recommendation with Generative Archetype-grounded Item Representations. Specifically, we first leverage an LLM to analyze item metadata and infer textual description of the Archetype, which represents the conceptual profile of the item's ideal target audience. We then extract the corresponding embeddings in a single forward pass. Further, to ground these generative archetypes in real-world behavior, we introduce a behavioral calibration objective, which explicitly incorporates behavioral signals from actual interactions. This objective adjusts the structure of the embedding space to reflect empirical patterns. GenAIR enables seamless integration with most existing models while maintaining high efficiency. Comprehensive experiments conducted on three real-world datasets demonstrate that GenAIR significantly improves the performance of various sequential recommendation models and consistently outperforms state-of-the-art baseline approaches. Implementation codes are available at https://github.com/AI-Santiago/GenAIR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GenAIR, a general framework for sequential recommendation that first uses an LLM to analyze item metadata and generate textual archetype descriptions representing the conceptual profile of each item's ideal target audience, extracts the corresponding embeddings in a single forward pass, and then applies a behavioral calibration objective that incorporates signals from actual user interactions to adjust the embedding space. The framework is designed for seamless integration with existing sequential models while remaining efficient, and the abstract claims that comprehensive experiments on three real-world datasets show consistent performance improvements over various sequential recommenders and state-of-the-art baselines.
Significance. If the empirical claims hold under rigorous evaluation, the work could meaningfully address the semantic-behavioral gap in item representations by grounding LLM-generated audience profiles in observed interactions, offering a general and efficient augmentation for sequential recommendation pipelines. The explicit separation of generative archetype construction from behavioral calibration is a clear conceptual contribution if the calibration step demonstrably preserves semantic utility without introducing new biases.
major comments (1)
- Abstract: the central claim of significant and consistent performance gains on three datasets is asserted without any reported metrics, baseline descriptions, ablation results, statistical tests, or experimental protocol details, rendering the primary empirical contribution impossible to assess from the provided text.
Simulated Author's Rebuttal
We thank the referee for their review. The single major comment concerns the level of detail in the abstract; we address it directly below and agree that a revision is warranted.
read point-by-point responses
-
Referee: [—] Abstract: the central claim of significant and consistent performance gains on three datasets is asserted without any reported metrics, baseline descriptions, ablation results, statistical tests, or experimental protocol details, rendering the primary empirical contribution impossible to assess from the provided text.
Authors: We agree that the abstract, as currently written, states the empirical outcome at a high level without quantitative support. The detailed results (including specific metrics such as HR@10 and NDCG@10 improvements, the three datasets, the full set of baselines, ablation studies, and statistical significance tests) appear in Sections 4 and 5. To make the primary claim assessable from the abstract itself, we will revise it to report the key performance gains on the three datasets and name the main sequential models and SOTA baselines used. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's method generates archetype text via LLM from item metadata, extracts embeddings in one pass, and applies an explicit behavioral calibration objective on interaction data to adjust the embedding space. This is a constructive pipeline that augments representations with new semantic and empirical signals rather than re-expressing fitted parameters or prior outputs as predictions. No equations, objectives, or claims reduce by construction to the inputs (e.g., no archetype ratio defined from the calibration itself), and the abstract presents the calibration as an independent addition. The central performance claim rests on downstream experiments, not tautological identity with the generation step. No self-citation chains or uniqueness theorems are invoked in the provided text.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Archetype
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[2]
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, and Siva Reddy. 2024. LLM2Vec: Large language models are secretly powerful text encoders. InFirst Conference on Language Modeling
2024
-
[3]
Jiangxia Cao, Xin Cong, Jiawei Sheng, Tingwen Liu, and Bin Wang. 2022. Con- trastive cross-domain sequential recommendation. InProceedings of the 31st ACM International Conference on Information and Knowledge Management. 138–147
2022
-
[4]
Yankai Chen, Quoc-Tuan Truong, Xin Shen, Jin Li, and Irwin King. 2024. Shopping trajectory representation learning with pre-training for e-commerce customer understanding and recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 385–396
2024
-
[5]
Yankai Chen, Quoc-Tuan Truong, Xin Shen, Ming Wang, Jin Li, Jim Chan, and Irwin King. 2023. Topological representation learning for e-commerce shopping behaviors.Proceedings of the 19th International Workshop on Mining and Learning with Graphs
2023
-
[6]
Hui Fang, Danning Zhang, Yiheng Shu, and Guibing Guo. 2020. Deep learning for sequential recommendation: Algorithms, influential factors, and evaluations. ACM Transactions on Information Systems(2020), 1–42
2020
-
[7]
Luis Gonzalo Sanchez Giraldo, Murali Rao, and Jose C Principe. 2014. Measures of entropy from data using infinitely divisible kernels.IEEE Transactions on Information Theory(2014), 535–548
2014
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[9]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
Pith/arXiv arXiv 2025
-
[10]
Jesse Harte, Wouter Zorgdrager, Panos Louridas, Asterios Katsifodimos, Diet- mar Jannach, and Marios Fragkoulis. 2023. Leveraging large language models for sequential recommendation. InProceedings of the 17th ACM Conference on Recommender Systems. 1096–1102
2023
-
[11]
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative filtering. InProceedings of the 26th International Conference on World Wide Web. 173–182
2017
-
[12]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[13]
In4th International Conference on Learning Representations
Session-based recommendations with recurrent neural networks. In4th International Conference on Learning Representations
-
[14]
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley
-
[15]
Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952(2024)
Pith/arXiv arXiv 2024
-
[16]
Guoqing Hu, An Zhang, Shuo Liu, Zhibo Cai, Xun Yang, and Xiang Wang. 2025. AlphaFuse: Learn ID embeddings for sequential recommendation in null space of language embeddings. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1614–1623
2025
-
[17]
Jun Hu, Wenwen Xia, Xiaolu Zhang, Chilin Fu, Weichang Wu, Zhaoxin Huan, Ang Li, Zuoli Tang, and Jun Zhou. 2024. Enhancing sequential recommendation via llm-based semantic embedding learning. InCompanion Proceedings of the ACM on Web Conference 2024. 103–111
2024
-
[18]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. 2024. Openai o1 system card.arXiv preprint arXiv:2412.16720(2024)
Pith/arXiv arXiv 2024
-
[19]
Seongwon Jang, Hoyeop Lee, Hyunsouk Cho, and Sehee Chung. 2020. Cities: Contextual inference of tail-item embeddings for sequential recommendation. In 2020 IEEE International Conference on Data Mining. 202–211
2020
-
[20]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE International Conference on Data Mining. 197–206
2018
-
[21]
Kibum Kim, Dongmin Hyun, Sukwon Yun, and Chanyoung Park. 2023. Melt: Mutual enhancement of long-tailed user and item for sequential recommendation. InProceedings of the 46th International ACM SIGIR conference on Research and Development in Information Retrieval. 68–77
2023
-
[22]
Philip Kotler and Sidney J Levy. 1969. Broadening the concept of marketing. Journal of Marketing(1969), 10–15
1969
-
[23]
Muyang Li, Zijian Zhang, Xiangyu Zhao, Wanyu Wang, Minghao Zhao, Runze Wu, and Ruocheng Guo. 2023. AutoMLP: Automated MLP for sequential recom- mendations. InProceedings of the ACM Web Conference 2023. 1190–1198
2023
-
[24]
Yaoyiran Li, Xiang Zhai, Moustafa Alzantot, Keyi Yu, Ivan Vulić, Anna Korhonen, and Mohamed Hammad. 2024. Calrec: Contrastive alignment of generative llms for sequential recommendation. InProceedings of the 18th ACM Conference on Recommender Systems. 422–432
2024
-
[25]
Yuhan Li, Xinni Zhang, Linhao Luo, Heng Chang, Yuxiang Ren, Irwin King, and Jia Li. 2025. G-refer: Graph retrieval-augmented large language model for explainable recommendation. InProceedings of the ACM on Web Conference 2025. 240–251
2025
-
[26]
Dugang Liu, Shenxian Xian, Xiaolin Lin, Xiaolian Zhang, Hong Zhu, Yuan Fang, Zhen Chen, and Zhong Ming. 2024. A practice-friendly two-stage LLM-enhanced paradigm in sequential recommendation.arXiv preprint arXiv:2406.00333(2024)
arXiv 2024
-
[27]
Jiahong Liu, Zexuan Qiu, Zhongyang Li, Quanyu Dai, Wenhao Yu, Jieming Zhu, Minda Hu, Menglin Yang, Tat-Seng Chua, and Irwin King. 2025. A survey of personalized large language models: Progress and future directions.arXiv preprint arXiv:2502.11528(2025)
arXiv 2025
-
[28]
Qidong Liu, Feng Tian, Qinghua Zheng, and Qianying Wang. 2023. Disentan- gling interest and conformity for eliminating popularity bias in session-based recommendation.Knowledge and Information Systems(2023), 2645–2664
2023
-
[29]
Qidong Liu, Xian Wu, Wanyu Wang, Yejing Wang, Yuanshao Zhu, Xiangyu Zhao, Feng Tian, and Yefeng Zheng. 2025. LLMEmb: Large language model can be a good embedding generator for sequential recommendation. InProceedings of the AAAI Conference on Artificial Intelligence. 12183–12191
2025
-
[30]
Qidong Liu, Xian Wu, Yejing Wang, Zijian Zhang, Feng Tian, Yefeng Zheng, and Xiangyu Zhao. 2024. LLM-ESR: Large language models enhancement for long-tailed sequential recommendation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. 26701–26727
2024
-
[31]
Qidong Liu, Fan Yan, Xiangyu Zhao, Zhaocheng Du, Huifeng Guo, Ruiming Tang, and Feng Tian. 2023. Diffusion augmentation for sequential recommendation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 1576–1586
2023
-
[32]
Zhiwei Liu, Yongjun Chen, Jia Li, Philip S Yu, Julian McAuley, and Caiming Xiong. 2021. Contrastive self-supervised sequential recommendation with robust augmentation.arXiv preprint arXiv:2108.06479(2021)
arXiv 2021
-
[33]
Ziru Liu, Shuchang Liu, Zijian Zhang, Qingpeng Cai, Xiangyu Zhao, Kesen Zhao, Lantao Hu, Peng Jiang, and Kun Gai. 2024. Sequential recommendation for optimizing both immediate feedback and long-term retention. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1872–1882
2024
-
[34]
Ziru Liu, Jiejie Tian, Qingpeng Cai, Xiangyu Zhao, Jingtong Gao, Shuchang Liu, Dayou Chen, Tonghao He, Dong Zheng, Peng Jiang, and Kun Gai. 2023. Multi- Task Recommendations with Reinforcement Learning. InProceedings of the ACM Web Conference 2023. 1273–1282
2023
-
[35]
Sichun Luo, Bowei He, Haohan Zhao, Wei Shao, Yanlin Qi, Yinya Huang, Aojun Zhou, Yuxuan Yao, Zongpeng Li, Yuanzhang Xiao, et al. 2025. Recranker: Instruc- tion tuning large language model as ranker for top-k recommendation.ACM Transactions on Information Systems(2025), 1–31
2025
-
[36]
Sichun Luo, Yuxuan Yao, Bowei He, Yinya Huang, Aojun Zhou, Xinyi Zhang, Yuanzhang Xiao, Mingjie Zhan, and Linqi Song. 2024. Integrating large language models into recommendation via mutual augmentation and adaptive aggregation. arXiv preprint arXiv:2401.13870(2024)
arXiv 2024
-
[37]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel
-
[38]
InProceedings of the 38th international ACM SIGIR Conference on Research and Development in Information Retrieval
Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR Conference on Research and Development in Information Retrieval. 43–52
-
[39]
Pascal Mettes, Elise van der Pol, and Cees Snoek. 2019. Hyperspherical prototype networks. InProceedings of the 33rd International Conference on Neural Information Processing Systems. 1485–1495
2019
-
[40]
Niklas Muennighoff, SU Hongjin, Liang Wang, Nan Yang, Furu Wei, Tao Yu, Amanpreet Singh, and Douwe Kiela. 2024. Generative representational instruc- tion tuning. InICLR 2024 Workshop: How Far Are We From AGI
2024
-
[41]
Karl Pearson. 1901. LIII. On lines and planes of closest fit to systems of points in space.The London, Edinburgh, and Dublin philosophical magazine and journal of science(1901), 559–572
1901
-
[42]
Zexuan Qiu, Jieming Zhu, Yankai Chen, Guohao Cai, Weiwen Liu, Zhenhua Dong, and Irwin King. 2024. EASE: Learning lightweight semantic feature adapters from large language models for CTR prediction. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 4819–4827
2024
-
[43]
Zekai Qu, Ruobing Xie, Chaojun Xiao, Zhanhui Kang, and Xingwu Sun. 2024. The elephant in the room: rethinking the usage of pre-trained language model in sequential recommendation. InProceedings of the 18th ACM Conference on Recommender Systems. 53–62
2024
-
[44]
Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. Representation learning with large language models for recommendation. InProceedings of the ACM on Web Conference 2024. 3464– 3475
2024
-
[45]
Oscar Skean, Jhoan Keider Hoyos Osorio, Austin J Brockmeier, and Luis Gon- zalo Sanchez Giraldo. 2023. DiME: Maximizing mutual information by a difference of matrix-based entropies.arXiv preprint arXiv:2301.08164(2023)
arXiv 2023
-
[46]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[47]
InProceedings of the 28th ACM International Conference on Information and Knowledge Management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM International Conference on Information and Knowledge Management. 1441–1450
-
[48]
Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommenda- tion via convolutional sequence embedding. InProceedings of the eleventh ACM International Conference on Web Search and Data Mining. 565–573. WWW ’26, April 13–17, 2026, Dubai, United Arab Emirates Yifan Li et al
2018
-
[49]
Yixuan Tang and Yi Yang. 2024. Pooling and attention: What are effective designs for llm-based embedding models?arXiv preprint arXiv:2409.02727(2024)
arXiv 2024
-
[50]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
Pith/arXiv arXiv 2023
-
[51]
Tongzhou Wang and Phillip Isola. 2020. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InProceedings of the 37th International Conference on Machine Learning. 9929–9939
2020
-
[52]
Youlin Wu, Yuanyuan Sun, Xiaokun Zhang, Haoxi Zhan, Bo Xu, Liang Yang, and Hongfei Lin. 2025. IP2: Entity-Guided Interest Probing for Personalized News Recommendation. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 187–196
2025
-
[53]
Jiacheng Xu and Greg Durrett. 2018. Spherical latent spaces for stable variational autoencoders. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 4503–4513
2018
-
[54]
Wujiang Xu, Qitian Wu, Runzhong Wang, Mingming Ha, Qiongxu Ma, Linxun Chen, Bing Han, and Junchi Yan. 2024. Rethinking cross-domain sequential recommendation under open-world assumptions. InProceedings of the ACM on Web Conference 2024. 3173–3184
2024
-
[55]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
Pith/arXiv arXiv 2024
-
[56]
Zhengyi Yang, Jiancan Wu, Zhicai Wang, Xiang Wang, Yancheng Yuan, and Xiangnan He. 2023. Generate what you prefer: Reshaping sequential recommen- dation via guided diffusion.Advances in Neural Information Processing Systems 36 (2023), 24247–24261
2023
-
[57]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, et al . 2024. Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations. InProceedings of the 41st International Conference on Machine Learning. 58484– 58509
2024
-
[58]
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Shen Li, Yanli Zhao, Yuchen Hao, Yantao Yao, Ellie Dingqiao Wen, et al. 2024. Wukong: towards a scaling law for large-scale recommendation. InProceedings of the 41st International Conference on Machine Learning. 59421–59434
2024
-
[59]
Xinni Zhang, Yankai Chen, Chenhao Ma, Yixiang Fang, and Irwin King. 2024. Influential exemplar replay for incremental learning in recommender systems. InThirty-Eighth AAAI Conference on Artificial Intelligence. 9368–9376
2024
-
[60]
Xiaokun Zhang, Bo Xu, Chenliang Li, Bowei He, Hongfei Lin, Chen Ma, and Fenglong Ma. 2025. A survey on side information-driven session-based recom- mendation: from a data-centric perspective.IEEE Transactions on Knowledge and Data Engineering(2025), 1–20
2025
-
[61]
Xiaokun Zhang, Bo Xu, Fenglong Ma, Chenliang Li, Liang Yang, and Hongfei Lin. 2023. Beyond co-occurrence: Multi-modal session-based recommendation. IEEE Transactions on Knowledge and Data Engineering(2023), 1450–1462
2023
-
[62]
Xiangyu Zhao, Maolin Wang, Xinjian Zhao, Jiansheng Li, Shucheng Zhou, Dawei Yin, Qing Li, Jiliang Tang, and Ruocheng Guo. 2023. Embedding in recommender systems: A survey.arXiv preprint arXiv:2310.18608(2023)
arXiv 2023
-
[63]
cute chin strap
Kun Zhou, Hui Yu, Wayne Xin Zhao, and Ji-Rong Wen. 2022. Filter-enhanced MLP is all you need for sequential recommendation. InProceedings of the ACM Web Conference 2022. 2388–2399. A Case Study To illustrate the differences in archetype generation across different large language models, we present a case study analyzing outputs fromLlama 2-7B-ChatandQwen ...
2022
-
[64]
Parents or caregivers of young children (ages 0–5): The product’s focus on providing protection from the sun and its cute design make it an ideal choice for parents who want to keep their little ones safe while also dressing them in style
-
[65]
Outdoor enthusiasts: People who enjoy spending time outdoors, such as hikers, bicyclists, or beachgoers, may appreciate the hat’s ability to provide reliable sun protection without sacrificing style
-
[66]
Fashion-conscious individuals: Although the hat is primarily marketed towards parents and caregivers, anyone looking for stylish headwear that also offers excellent sun protection could find this product appealing
-
[67]
Individuals living in sunny climates: Residents of areas with high levels of UV radiation may prioritize sun protection when selecting clothing and accessories, making the Zutano Baby UPF 30+ Sun Protection Hat an attractive option
-
[68]
Active people: This group includes athletes, fitness enthusiasts, or those who engage in activities like running, playing sports, or doing yoga, where they need to protect themselves from the sun during exercise
-
[69]
Travelers: Whether visiting tropical destinations or enjoying summer vacation at home, travelers might seek out a practical yet stylish sun hat for their adventures
-
[70]
In such cases, the breathable cotton material of this hat may offer relief and peace of mind
Those with sensitive skin: Some individuals may have skin sensitivity or allergies that make wearing certain fabrics uncomfortable or irritating. In such cases, the breathable cotton material of this hat may offer relief and peace of mind
-
[71]
Gift buyers: With its affordability, versatility, and cute design, this hat could become a popular gift item for friends, family members, or colleagues with young children
-
[72]
Educators or daycare providers: Teachers, nannies, or other professionals responsible for supervising young children throughout the day may appreciate the convenience and effectiveness of this sun hat
-
[73]
Photographers or influencers: Professionals working in creative fields where visual appearance matters may admire the Zutano Baby. ## Generated Archetype Text (Qwen 2.5-7B-Instruct) ## The Zutano Baby UPF 30+ Sun Protection Hat appears to be a fashionable and practical accessory designed specifically for infants and young children. Based on its attributes...
-
[74]
Parents who are concerned about sun protection for their children would find this hat beneficial
**Parents and Guardians**: This is the primary target audience as the hat is designed for babies and young children. Parents who are concerned about sun protection for their children would find this hat beneficial
-
[75]
**Grandparents**: Grandparents often play a significant role in caring for grandchildren and may appreciate the sun protection features of this hat
-
[76]
**Outdoor Enthusiasts**: Families who frequently engage in outdoor activities such as picnics, beach trips, or park visits would value a hat that keeps their children shaded and protected from the sun
-
[77]
**Health-Conscious Individuals**: People who prioritize health and well-being might choose this hat to ensure their children receive adequate sun protection during outdoor activities
-
[78]
**Style-Conscious Parents**: The wide-brim design and cute chin ties suggest that the hat is also stylish, which could appeal to parents who want both functionality and fashion for their children’s accessories. Given the high star rating (5 stars) and the specific mention of UPF 30+ sun protection, the hat is clearly designed with safety and comfort in mi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.