NAC: Neural Action Codec for Vision-Language-Action Models
Pith reviewed 2026-06-26 13:58 UTC · model grok-4.3
The pith
Neural Action Codec adapts audio-style RVQGANs to tokenize robot actions with lower error and higher success than binning or prior VQ methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
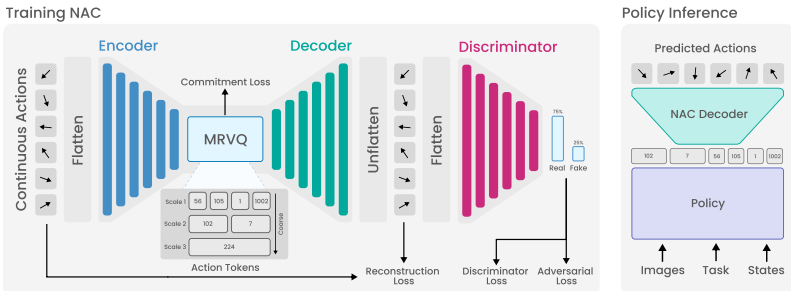
NAC treats short robot action trajectories as multi-channel 1D signals and compresses them with a multi-scale RVQGAN whose encoder-decoder pair is drawn from neural audio codecs. Time-domain plus non-mel spectral losses replace mel-spectrogram objectives; offset codebooks produce an ordered discrete token sequence; a Vocos-style decoder with ISTFT head and adversarial discriminators reconstructs the original trajectory. The resulting tokenizer supplies VLAs with compact action sequences that support standard autoregressive decoding while preserving kinematic detail.
What carries the argument
Multi-scale RVQGAN with offset codebooks and ISTFT decoder, using time-domain and non-mel spectral losses to autoencode kinematic signals.
If this is right
- Standard autoregressive VLAs can operate over the short structured token sequences produced by NAC.
- The offset codebooks create a compact ordered token space without custom policy heads.
- The ISTFT decoder recovers smooth, detailed trajectories suitable for low-level control.
- NAC maintains or improves compression rates while raising downstream success on LIBERO-10, RoboMimic, and real tasks.
Where Pith is reading between the lines
- The same loss substitution may allow audio-codec backbones to tokenize other continuous control signals such as joint torques or force profiles.
- If the 1D-signal assumption holds for longer horizons, NAC-style tokenizers could reduce the sequence length needed for long-horizon planning.
- Offset codebooks might be reused across different robot morphologies to share a common discrete action vocabulary.
Load-bearing premise
Short robot action trajectories behave like multi-channel 1D signals whose high-fidelity reconstruction requires only time-domain and non-mel spectral losses without major architectural redesign.
What would settle it
A controlled comparison on held-out real-world manipulation tasks in which NAC produces higher action reconstruction error or lower policy success rates than binning or FAST at matched token rates would falsify the performance claim.
Figures



read the original abstract
Vision-language-action (VLA) models rely on discrete action tokenizers to bridge continuous robot control and autoregressive sequence modeling, yet existing tokenizers often trade off between compression, latency, and downstream performance. We revisit this design through the lens of neural audio codecs-convolutional encoder-decoder architectures with residual vector quantization that serve as the standard front end for audio foundation models. Motivated by their success, we introduce the Neural Action Codec (NAC), which treats short robot action trajectories as multi-channel 1D signals and compresses them using a multi-scale RVQGAN architecture. We observe that audio-specific mel-spectrogram objectives are ill-suited for kinematic signals; however, by replacing them with simple time-domain and non-mel spectral reconstruction losses, audio-codec-style models can autoencode actions with high fidelity without substantial architectural changes. NAC provides a compact, ordered token space via offset codebooks, enabling standard autoregressive policies to operate over short, structured sequences. Meanwhile, a Vocos-style decoder with an ISTFT head and adversarial discriminators recovers smooth, detailed trajectories. Across LIBERO-10, RoboMimic, and a suite of real-world manipulation tasks, NAC achieves lower reconstruction error and higher success rates than binning, FAST, and prior VQ-based tokenizers at comparable or better compression rates. These results demonstrate that repurposed neural audio codecs offer a strong, practical backbone for learned action tokenization in modern VLAs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Neural Action Codec (NAC), which adapts multi-scale RVQGAN-style neural audio codecs to discretize short robot action trajectories by treating them as multi-channel 1D signals. It replaces audio-specific mel-spectrogram objectives with time-domain and non-mel spectral reconstruction losses, uses offset codebooks for ordered tokens, and employs a Vocos-style decoder with ISTFT head and adversarial discriminators. The central empirical claim is that NAC yields lower reconstruction error and higher success rates than binning, FAST, and prior VQ-based tokenizers on LIBERO-10, RoboMimic, and real-world manipulation tasks at comparable or better compression rates.
Significance. If the reported results hold, the work shows that minimal modifications to established audio codec architectures can produce effective action tokenizers for VLAs, enabling standard autoregressive policies over compact structured sequences. It explicitly credits the multi-channel 1D treatment, replacement of mel losses, and use of offset codebooks plus ISTFT/adversarial components for high-fidelity recovery without substantial redesign.
major comments (2)
- [Abstract and §4] The central performance claim (lower reconstruction error and higher success rates across LIBERO-10, RoboMimic, and real tasks) is load-bearing for the contribution, yet the provided abstract supplies no quantitative tables, error bars, statistical tests, or ablation details on loss components or codebook scales; full verification of the empirical wins requires these in the results section.
- [§3.1] §3.1: The multi-channel 1D signal treatment and choice of simple time-domain plus non-mel spectral losses are presented as sufficient without major redesign, but the manuscript should include an ablation isolating the contribution of each loss term to reconstruction fidelity to confirm they suffice for kinematic signals.
minor comments (2)
- [§3.2] Provide explicit equations or pseudocode for the non-mel spectral reconstruction loss to support reproducibility.
- [§4.1] Clarify how compression rates are matched exactly across all baselines (binning, FAST, prior VQ) in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation of minor revision. The comments highlight opportunities to strengthen the empirical presentation, which we address point-by-point below with planned revisions.
read point-by-point responses
-
Referee: [Abstract and §4] The central performance claim (lower reconstruction error and higher success rates across LIBERO-10, RoboMimic, and real tasks) is load-bearing for the contribution, yet the provided abstract supplies no quantitative tables, error bars, statistical tests, or ablation details on loss components or codebook scales; full verification of the empirical wins requires these in the results section.
Authors: The results section (§4) already presents quantitative tables comparing reconstruction errors and task success rates for NAC against binning, FAST, and prior VQ tokenizers on LIBERO-10, RoboMimic, and real-world tasks at matched compression rates. To improve accessibility, we will revise the abstract to incorporate the key quantitative improvements (e.g., specific error reductions and success-rate gains) while respecting length constraints. We will also ensure error bars, confidence intervals, and any necessary statistical tests are included or added in the results tables. Ablation details on loss components and codebook scales will be expanded as part of the response to the second comment. revision: yes
-
Referee: [§3.1] §3.1: The multi-channel 1D signal treatment and choice of simple time-domain plus non-mel spectral losses are presented as sufficient without major redesign, but the manuscript should include an ablation isolating the contribution of each loss term to reconstruction fidelity to confirm they suffice for kinematic signals.
Authors: We agree that an explicit ablation isolating the individual contributions of the time-domain and non-mel spectral losses would provide stronger evidence that these terms suffice for kinematic signals without audio-specific mel objectives. In the revised manuscript we will add a dedicated ablation study (table or figure) quantifying reconstruction fidelity when each loss term is included or removed, confirming their combined effectiveness for action trajectories. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper frames NAC as an empirical architecture proposal that adapts existing RVQGAN-style audio codecs to multi-channel 1D action trajectories by swapping mel objectives for time-domain plus non-mel spectral losses. No equations, derivations, or predictions are presented that reduce to fitted parameters or self-citations by construction; the central claims rest on external benchmark comparisons (LIBERO-10, RoboMimic, real-world tasks) whose outcomes are not forced by the method definition itself. No load-bearing self-citation chains or uniqueness theorems appear in the abstract or described method.
Axiom & Free-Parameter Ledger
free parameters (1)
- RVQ codebook sizes and scales
axioms (1)
- domain assumption Action trajectories behave sufficiently like multi-channel 1D signals that audio-codec architectures transfer with only loss-function changes.
invented entities (1)
-
Neural Action Codec (NAC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zeghidour, A
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi. SoundStream: An end-to- end neural audio codec.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507, 2021
2021
-
[2]
A. Défossez, J. Copet, G. Synnaeve, and Y . Adi. High fidelity neural audio compression.Trans- actions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview. net/forum?id=ivCd8z8zR2. arXiv:2210.13438
Pith/arXiv arXiv 2023
- [3]
-
[4]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[5]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
2025
-
[6]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=ZMnD6QZAE6
2024
-
[7]
C. Liu, X. Han, J. Gao, Y . Zhao, H. Chen, and Y . Du. OAT: Ordered action tokenization.arXiv preprint arXiv:2602.04215, 2026
arXiv 2026
-
[8]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[9]
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. FAST: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[10]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, et al. MolmoAct: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025
Pith/arXiv arXiv 2025
-
[11]
D. Lee, C. Kim, S. Kim, M. Cho, and W.-S. Han. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11523–11532, 2022
2022
-
[12]
Borsos, R
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi, et al. AudioLM: A language modeling approach to audio generation.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2523– 2533, 2023
2023
-
[13]
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Li, et al. Neural codec language models are zero-shot text to speech synthesizers.arXiv preprint arXiv:2301.02111, 2023. 9
Pith/arXiv arXiv 2023
-
[14]
Cadene, S
R. Cadene, S. Alibert, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal, S. Palma, D. Aubakirova, M. Shukor, J. Moss, A. Soare, Q. Lhoest, Q. Gallouédec, and T. Wolf. Lerobot: An open-source library for end-to-end robot learning. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps: //o...
2026
-
[15]
Kaneko, K
T. Kaneko, K. Tanaka, H. Kameoka, and S. Seki. iSTFTNet: Fast and lightweight mel- spectrogram vocoder incorporating inverse short-time fourier transform. InICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6207–6211. IEEE, 2022
2022
-
[16]
S. S. Stevens, J. V olkmann, and E. B. Newman. A scale for the measurement of the psychological magnitude pitch.The journal of the acoustical society of america, 8(3):185–190, 1937
1937
-
[17]
Siuzdak, F
H. Siuzdak, F. Grötschla, and L. A. Lanzendörfer. SNAC: Multi-scale neural audio codec. InAudio Imagination: NeurIPS 2024 Workshop on AI-Driven Speech, Music, and Sound Generation, 2024. URLhttps://openreview.net/forum?id=PFBF5ctj4X
2024
-
[18]
D. Yang, J. Tian, X. Tan, R. Huang, S. Liu, X. Chang, J. Shi, S. Zhao, J. Bian, Z. Zhao, et al. UniAudio: An audio foundation model toward universal audio generation.arXiv preprint arXiv:2310.00704, 2023
arXiv 2023
-
[19]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alab- dulmohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Bošnjak, X. Chen, M. Minderer, P. V oigtlaender, I. Bica, I. Balazevic, J. Puigcerv...
Pith/arXiv arXiv 2024
-
[20]
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V . Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V . Kerkez, M. Khabsa, I. Kloumann, A. Koren...
Pith/arXiv arXiv 2023
-
[21]
H. Fang, J. Duan, D. Clay, S. Wang, S. Liu, W. Huang, X. Fan, W.-C. Tsai, S. Chen, Y . R. Wang, S. Xing, J. Cho, J. S. Park, A. Eftekhar, P. Sushko, K. Farley, A. Wadhwa, C. Harrison, W. Han, Y .-C. Lee, E. VanderBilt, R. Hendrix, S. Ellawela, L. Ngoo, J. Chai, Z. Ren, A. Farhadi, D. Fox, and R. Krishna. Molmoact2: Action reasoning models for real-world d...
Pith/arXiv arXiv 2026
-
[22]
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokin- sky, S. Cao, T. Charbonnier, V . Choudhary, F. Collins, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, M. Dhaka, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glos- sop, T. Godden, I. Goryachev, L. Groom, H. Habeeb, H. Hancock, K. Hausman, G. H...
Pith/arXiv arXiv 2026
-
[23]
Ahmed, T
N. Ahmed, T. Natarajan, and K. R. Rao. Discrete cosine transform.IEEE transactions on Computers, 100(1):90–93, 1974
1974
-
[24]
Sennrich, B
R. Sennrich, B. Haddow, and A. Birch. Neural machine translation of rare words with subword units. InProceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers), pages 1715–1725, 2016
2016
-
[25]
Y . Wang, H. Zhu, M. Liu, J. Yang, H.-S. Fang, and T. He. VQ-VLA: Improving vision-language- action models via scaling vector-quantized action tokenizers. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. arXiv:2507.01016
arXiv 2025
-
[26]
R. Gray. Vector quantization.IEEE Assp Magazine, 1(2):4–29, 1984
1984
-
[27]
Z. Dong, Y . Liu, S. Zhang, B. Ye, Y . Yuan, F. Ni, J. Gong, X. Qiu, H. Zhao, Y . Li, et al. ActionCodec: What makes for good action tokenizers.arXiv preprint arXiv:2602.15397, 2026
arXiv 2026
-
[28]
Y . Liu, S. Zhang, Z. Dong, B. Ye, T. Yuan, X. Yu, L. Yin, C. Lu, J. Shi, L. J.-T. Yu, L. Zheng, J. Gong, T. Jiang, X. Qiu, and H. Zhao. FASTer: Toward powerful and efficient autoregressive vision–language–action models with learnable action tokenizer and block-wise decoding. In The Fourteenth International Conference on Learning Representations, 2026. UR...
arXiv 2026
-
[29]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[30]
H. Zhao, O. Gallo, I. Frosio, and J. Kautz. Loss functions for image restoration with neural networks.IEEE Transactions on computational imaging, 3(1):47–57, 2016
2016
-
[31]
Rippel, M
O. Rippel, M. Gelbart, and R. Adams. Learning ordered representations with nested dropout. In International Conference on Machine Learning, pages 1746–1754. PMLR, 2014
2014
-
[32]
Darcet, M
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski. Vision transformers need registers. In International Conference on Learning Representations (ICLR), 2024
2024
-
[33]
H. Siuzdak. V ocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis.arXiv preprint arXiv:2306.00814, 2023
arXiv 2023
-
[34]
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch. Decision transformer: reinforcement learning via sequence modeling. InProceed- ings of the 35th International Conference on Neural Information Processing Systems, pages 15084–15097, 2021
2021
-
[35]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[36]
Torabi, G
F. Torabi, G. Warnell, and P. Stone. Behavioral cloning from observation. InProceedings of the 27th International Joint Conference on Artificial Intelligence, pages 4950–4957, 2018
2018
-
[37]
M. Tagliasacchi, Y . Li, K. Misiunas, and D. Roblek. SEANet: A Multi-Modal Speech En- hancement Network. InInterspeech 2020, pages 1126–1130, 2020. doi:10.21437/Interspeech. 2020-1563
-
[38]
J. Kong, J. Kim, and J. Bae. HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis. InAdvances in Neural Information Processing Systems, volume 33, pages 17022–17033, 2020. 11
2020
-
[39]
Kiranyaz, O
S. Kiranyaz, O. Avci, O. Abdeljaber, T. Ince, M. Gabbouj, and D. J. Inman. 1d convolutional neural networks and applications: A survey.Mechanical systems and signal processing, 151: 107398, 2021
2021
-
[40]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778, 2016
2016
-
[41]
D.-A. Clevert, T. Unterthiner, and S. Hochreiter. Fast and accurate deep network learning by exponential linear units (elus).arXiv preprint arXiv:1511.07289, 4(5):11, 2015
Pith/arXiv arXiv 2015
-
[42]
Salimans and D
T. Salimans and D. P. Kingma. Weight normalization: A simple reparameterization to accelerate training of deep neural networks.Advances in neural information processing systems, 29, 2016
2016
-
[43]
Isola, J.-Y
P. Isola, J.-Y . Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017
2017
-
[44]
MacQueen
J. MacQueen. Multivariate observations. InProceedings ofthe 5th Berkeley symposium on mathematical statisticsand probability, volume 1, pages 281–297. University of California press Oakland, CA, USA, 1967
1967
-
[45]
Van Den Oord, O
A. Van Den Oord, O. Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[46]
A. Roy, A. Vaswani, A. Neelakantan, and N. Parmar. Theory and experiments on vector quantized autoencoders.arXiv preprint arXiv:1805.11063, 2018
Pith/arXiv arXiv 2018
-
[47]
S. Targ, D. Almeida, and K. Lyman. Resnet in resnet: Generalizing residual architectures.arXiv preprint arXiv:1603.08029, 2016
Pith/arXiv arXiv 2016
-
[48]
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie. A convnet for the 2020s. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022
2022
-
[49]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[50]
W. Jang, D. Lim, J. Yoon, B. Kim, and J. Kim. UnivNet: A neural vocoder with multi- resolution spectrogram discriminators for high-fidelity waveform generation.arXiv preprint arXiv:2106.07889, 2021
arXiv 2021
-
[51]
J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y . Zhang, Y . Wang, R. Skerrv-Ryan, et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 4779–4783. IEEE, 2018
2018
-
[52]
Radford, K
A. Radford, K. Narasimhan, T. Salimans, I. Sutskever, et al. Improving language understanding by generative pre-training.Openai, 2018
2018
-
[53]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36: 44776–44791, 2023
2023
-
[54]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning, pages 1678–1690. PMLR, 2022
2022
-
[55]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025. arXiv:2303.04137. 12 Appendix A Method Details A.1 Autoregressive Policy Inference Algorithm 2Autoregressive NAC Policy Inference R...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.