Extracting Small Translation Specialists from LLMs by Aggressively Pruning Experts
Pith reviewed 2026-06-29 12:45 UTC · model grok-4.3
The pith
Mixture-of-experts LLMs yield compact translation specialists by pruning up to 90 percent of experts with little quality loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
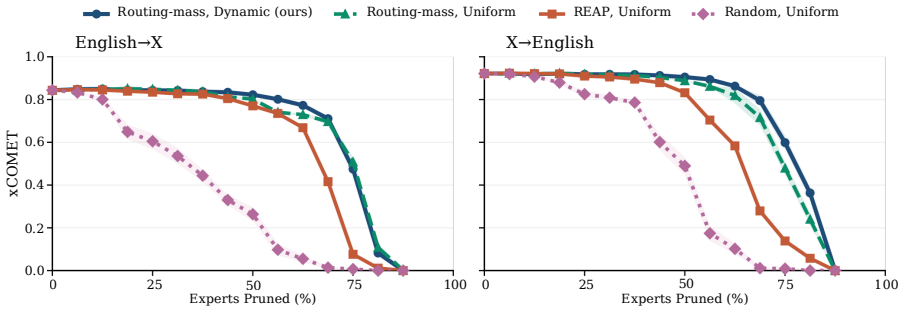
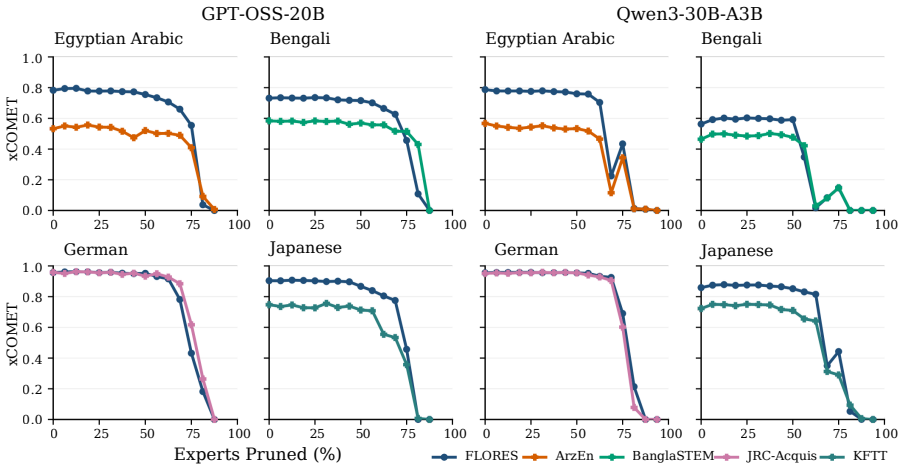
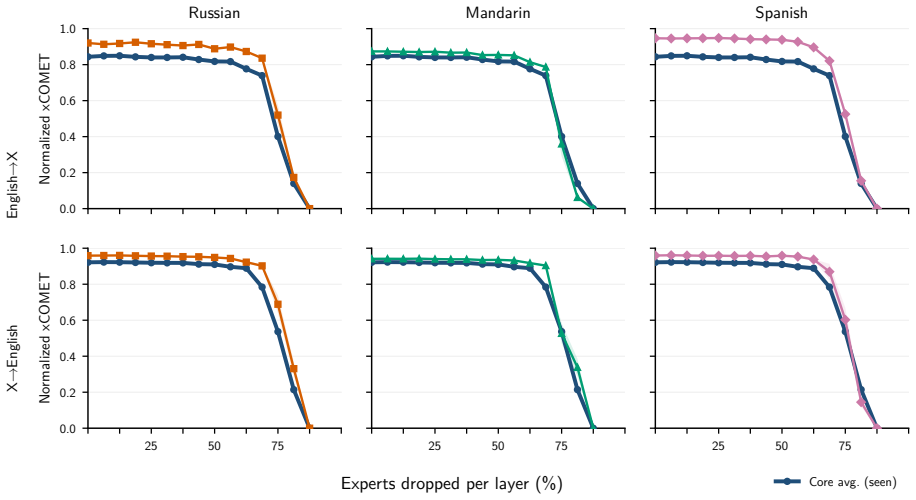
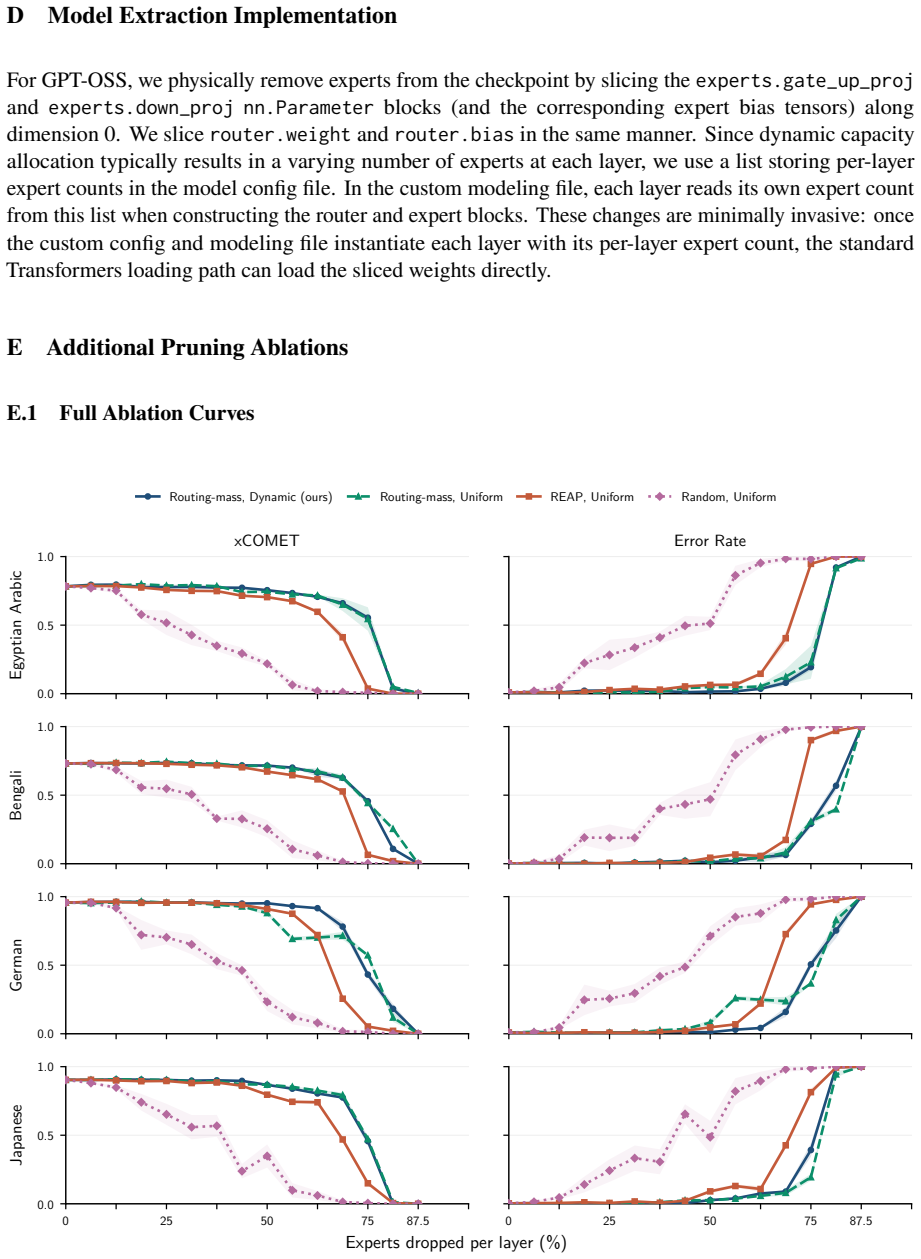
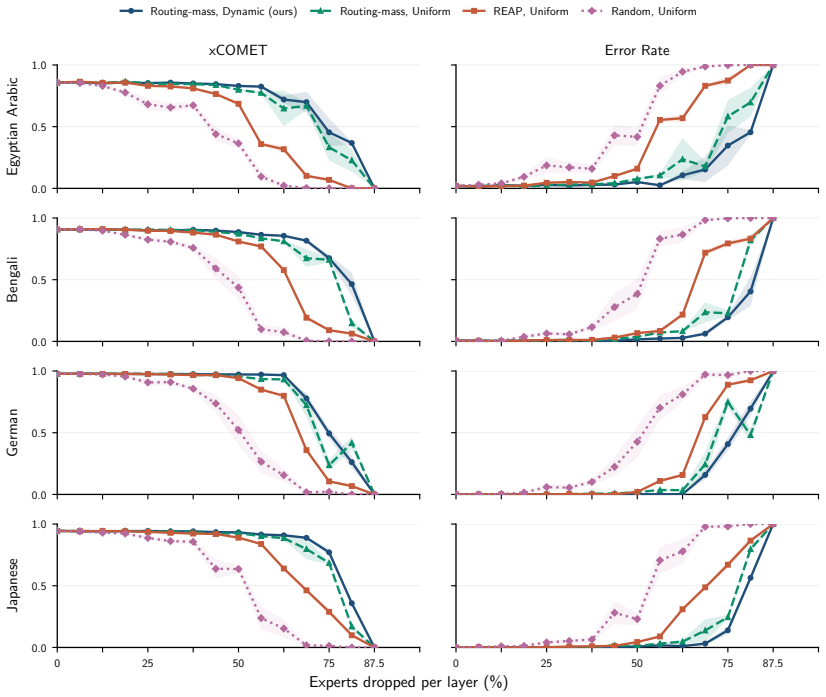
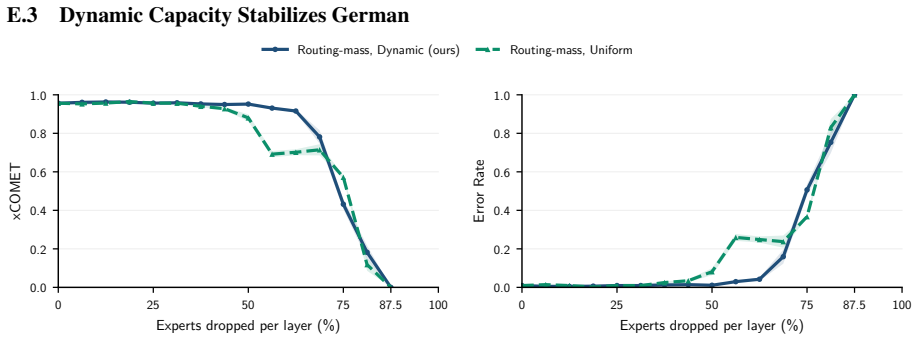
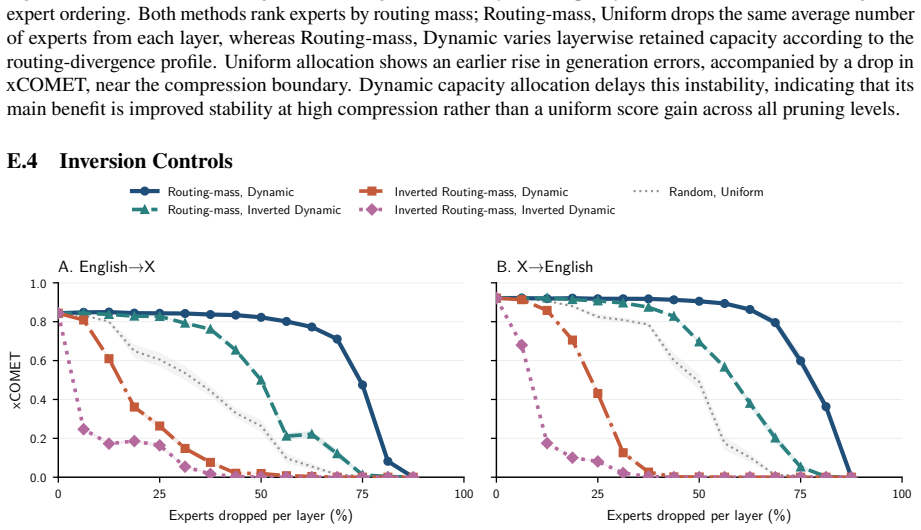
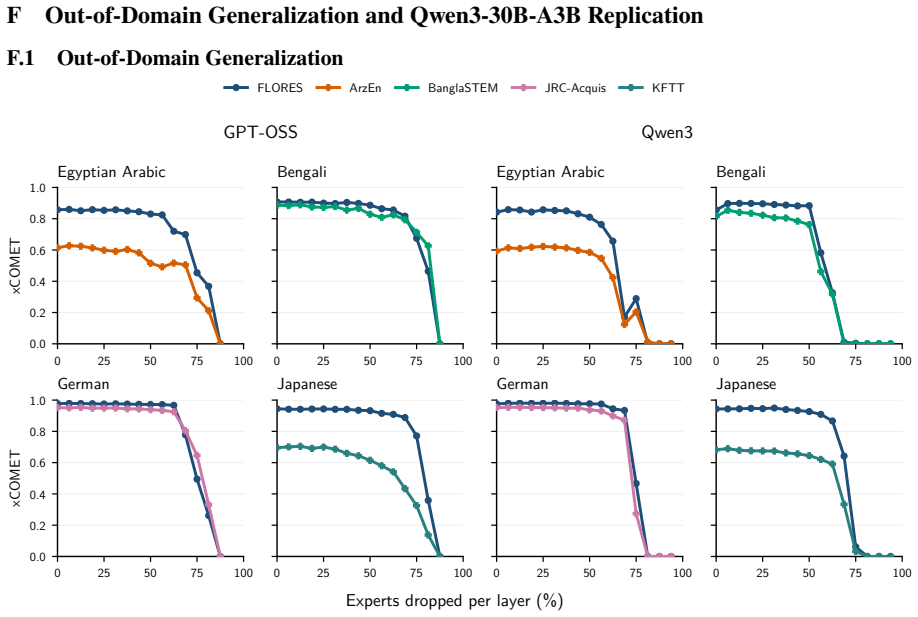
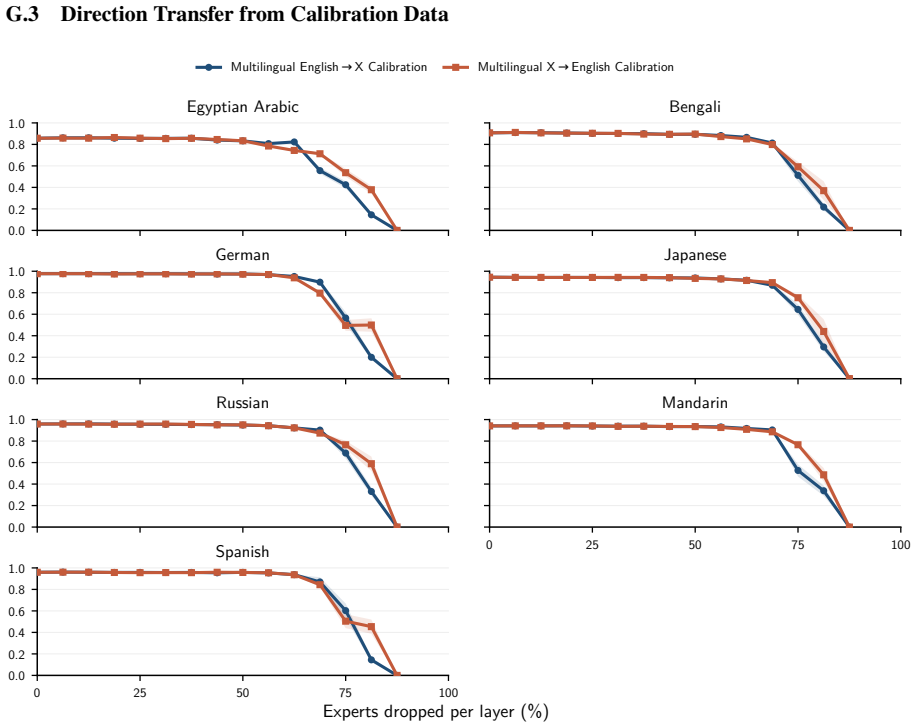
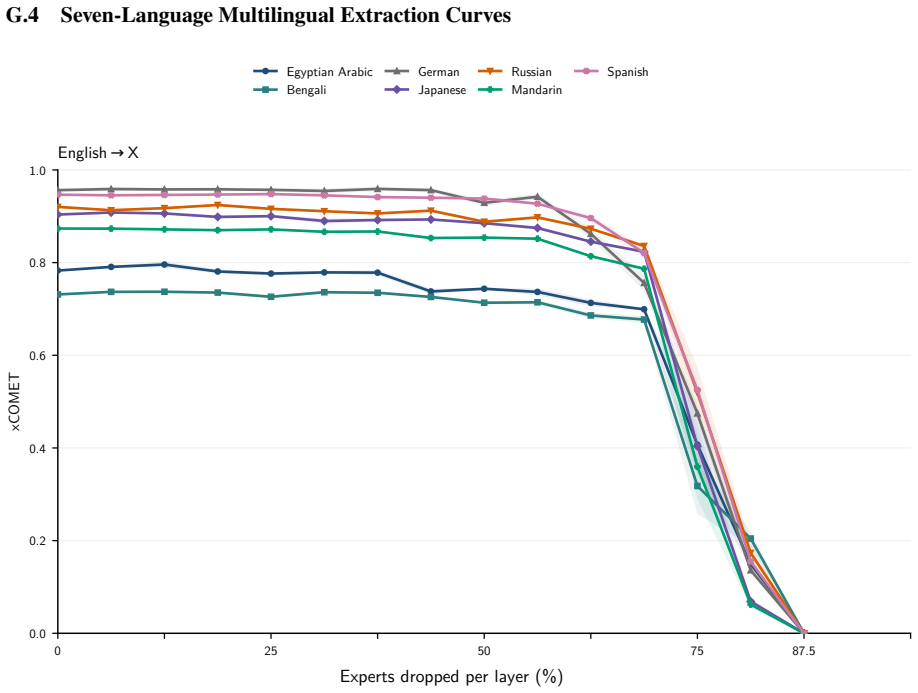
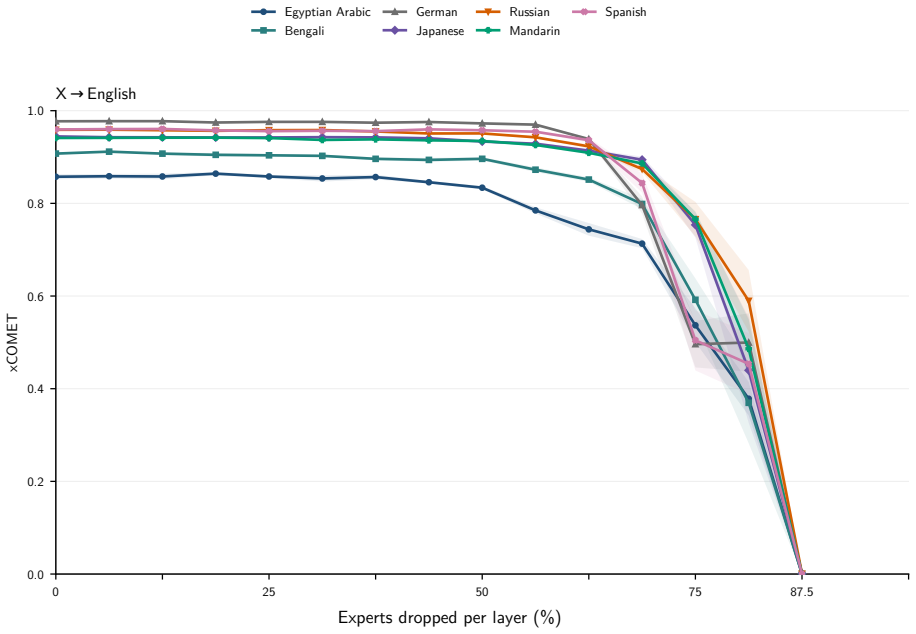
The central claim is that expert specialization and the separability of multilingual capabilities let us identify experts irrelevant to translation and prune them from mixture-of-experts LLMs. Without retraining, 50 percent of experts can be removed with negligible degradation and 70 percent with only minor losses. A very short supervised fine-tuning step recovers baseline performance after pruning 75 percent of experts, and in some settings nearly 90 percent can be removed while keeping reasonable translation quality. The result is that translation requires only a fraction of the model, enabling substantial compression of the MoE blocks that hold over 90 percent of the parameters.
What carries the argument
The pruning procedure that locates translation-irrelevant experts through their specialization patterns and removes them from the mixture-of-experts layers.
If this is right
- Half the experts can be pruned with no retraining and negligible degradation in translation quality.
- Seventy percent pruning produces only minor losses without retraining.
- A brief supervised fine-tuning step recovers full baseline performance after 75 percent of experts are removed.
- In some settings nearly 90 percent of experts can be pruned while translation quality remains reasonable.
Where Pith is reading between the lines
- The same identification step could be applied to isolate specialists for other tasks such as code generation or summarization.
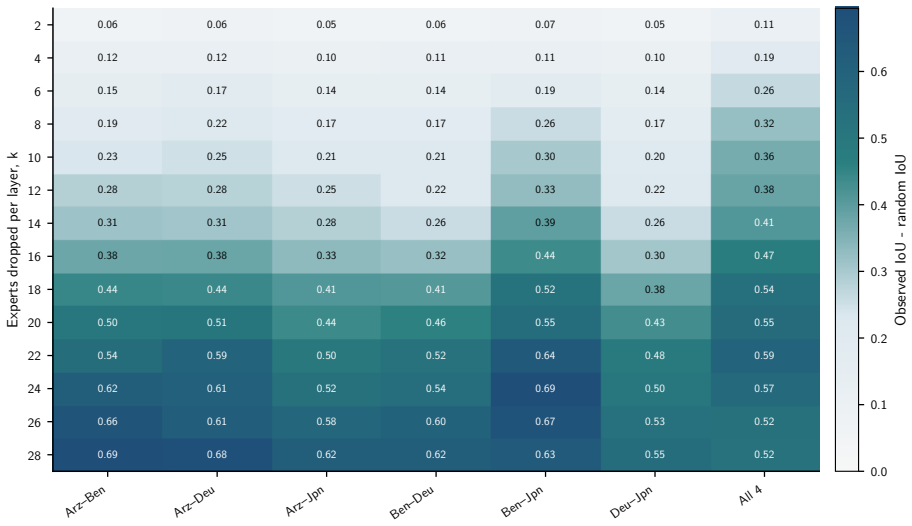
- The separability observed here implies that multilingual performance is concentrated in a small subset of experts rather than distributed evenly.
- Models could be pretrained with explicit task routing to make such aggressive pruning even more reliable in the future.
- Deployment of translation systems could move to much smaller hardware once the irrelevant experts are stripped out.
Load-bearing premise
Experts are specialized enough that some can be identified as irrelevant to translation and removed without degrading quality.
What would settle it
A large drop in translation accuracy across multiple language pairs after the identified experts are pruned, even following the short fine-tuning step.
Figures









read the original abstract
Modern large language models (LLMs) achieve state-of-the-art machine translation performance, but they do so as broad generalists largely trained for many tasks and capabilities unrelated to translation. Thus, they are heavily overparameterized for this task, resulting in excessive memory and compute requirements. In this paper, we present a method for aggressively pruning experts from modern mixture-of-experts LLMs while incurring negligible degradation in translation quality. Our approach exploits expert specialization and the separability of multilingual capabilities in LLMs to identify experts irrelevant to translation. And because of the modular nature of MoEs, these can be easily pruned without any training. Without retraining, we are able to prune half of all experts with negligible degradation and 70% with only minor losses. With a very short SFT, we prune 75% of experts while recovering baseline performance, and in some settings remove nearly 90% while maintaining reasonable translation quality. Overall, our results show that translation requires only a fraction of the LLM, enabling substantial compression of the MoE blocks that contain over 90% of parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that modern MoE LLMs are overparameterized for machine translation and presents a pruning method that exploits expert specialization and separability of multilingual capabilities to identify and remove translation-irrelevant experts. Without retraining, half the experts can be pruned with negligible degradation and 70% with only minor losses; a short SFT allows 75% pruning while recovering baseline performance and up to nearly 90% in some settings while maintaining reasonable quality. The results indicate that translation requires only a small fraction of the parameters in the MoE blocks.
Significance. If the empirical outcomes are reproducible, the work shows that task-specific capabilities in large MoE models can be isolated to a small expert subset, enabling substantial compression without full retraining. The modular pruning approach without training is a clear strength, as is the demonstration that high pruning ratios are achievable while preserving translation quality. This has direct implications for efficient deployment of specialized MoE models.
major comments (2)
- [Abstract] Abstract: the central quantitative claims (pruning 50% of experts with negligible degradation, 70% with minor losses, 75% with short SFT recovering baseline) are reported without any description of the expert identification procedure, the specific MoE models used as baselines, the translation datasets, or statistical measures such as error bars, rendering the soundness of the separability assumption and the pruning results impossible to evaluate.
- [Method] Method section (implied by the pruning procedure): the assumption that expert specialization permits reliable identification of translation-irrelevant experts is presented as the enabling mechanism, yet no concrete algorithm, scoring function, or validation experiment for this identification step is supplied; this is load-bearing for all reported pruning ratios.
minor comments (1)
- Add a dedicated reproducibility subsection or appendix listing all models, datasets, pruning thresholds, and evaluation metrics so that the reported compression ratios can be independently verified.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We agree that additional details are needed for reproducibility and evaluation, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claims (pruning 50% of experts with negligible degradation, 70% with minor losses, 75% with short SFT recovering baseline) are reported without any description of the expert identification procedure, the specific MoE models used as baselines, the translation datasets, or statistical measures such as error bars, rendering the soundness of the separability assumption and the pruning results impossible to evaluate.
Authors: We agree that the abstract, in its current form, is too high-level to allow full evaluation of the claims. In the revised manuscript we will expand the abstract to include a concise description of the expert identification procedure, name the specific MoE models used, reference the translation datasets, and note that results are reported with statistical measures such as error bars across multiple runs. revision: yes
-
Referee: [Method] Method section (implied by the pruning procedure): the assumption that expert specialization permits reliable identification of translation-irrelevant experts is presented as the enabling mechanism, yet no concrete algorithm, scoring function, or validation experiment for this identification step is supplied; this is load-bearing for all reported pruning ratios.
Authors: We acknowledge that the manuscript does not supply a concrete algorithm, scoring function, or validation experiments for identifying translation-irrelevant experts. We will revise the method section to provide a detailed description of the algorithm, the exact scoring function employed, and dedicated validation experiments that demonstrate the separability assumption and the reliability of the identification step. revision: yes
Circularity Check
No significant circularity; empirical results are self-contained
full rationale
The paper describes an empirical pruning procedure on MoE LLMs that identifies translation-irrelevant experts via observed specialization and separability, then reports direct experimental outcomes (pruning ratios and quality metrics) without equations, fitted parameters, or derivations that reduce to inputs by construction. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps; the separability premise is presented as an observed property of the evaluated models rather than a derived or self-referential claim. The central results therefore stand as independent experimental findings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mixture-of-experts LLMs contain experts with task-specific specialization that can be identified and removed for a target task such as translation.
Forward citations
Cited by 1 Pith paper
-
How Modular Is a Frontier Mixture-of-Experts? A Pre-registered Causal Test in Which Apparent Expert Modularity Mostly Dissolves
Pre-registered ablation tests on Command A+ reveal that only one of six expert families (Arabic) shows clean selective modularity; all others fail selectivity or are measurement-dependent.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the Sixth Conference on Machine Translation, pages 775–780, Online
Efficient machine translation with model prun- ing and quantization. InProceedings of the Sixth Conference on Machine Translation, pages 775–780, Online. Association for Computational Linguistics. MaximilianaBehnkeandKennethHeafield.2021. Prun- ing neural machine translation for speed using group lasso. InProceedings of the Sixth Conference on Machine Tra...
2021
-
[2]
InFindings of the Association for Computational Linguistics: NAACL 2024, pages 287–301, Mexico City, Mexico
Examining modularity in multilingual LMs via language-specialized subnetworks. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 287–301, Mexico City, Mexico. Association for Computational Linguistics. Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. GPT3.int8(): 8-bit matrix mul- tiplication for transform...
2024
-
[3]
Translategemma technical report.Preprint, arXiv:2601.09012. Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. 2021. Pruning neural networks at initialization: Why are we missing the mark? InInternational Conference on Learning Representations. Marco Gaido, Roman Grundkiewicz, Thamme Gowda, and Matteo Negri. 2025. Findings of th...
-
[4]
Shwai He, Daize Dong, Liang Ding, and Ang Li
Banglastem: A parallel corpus for techni- cal domain bangla-english translation.Preprint, arXiv:2511.03498. Shwai He, Daize Dong, Liang Ding, and Ang Li. 2025. Towards efficient mixture of experts: A holistic study ofcompressiontechniques.TransactionsonMachine Learning Research. Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distillingtheknowledgein...
-
[5]
gpt-oss-120b & gpt-oss-20b Model Card
Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 6159–6172, Bangkok, Thailand. Association for Computational Linguistics. Yasmin Moslem, Muhammad Hazim Al Farouq, and John ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Transactions of the Association for Computational Linguistics, 13:73–95
Salutetheclassic: Revisitingchallengesofma- chine translation in the age of large language models. Transactions of the Association for Computational Linguistics, 13:73–95. David Ponce, Harritxu Gete, and Thierry Etchegoyhen
-
[7]
No Language Left Behind: Scaling Human-Centered Machine Translation
Vicomtech@WMT 2025: Evolutionary model compression for machine translation. InProceedings of the Tenth Conference on Machine Translation, pages 1011–1021, Suzhou, China. Association for Computational Linguistics. ZihanQiu,ZeyuHuang,BoZheng,KaiyueWen,Zekun Wang, Rui Men, Ivan Titov, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2025. Demons in the detail: O...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.